









正则表达式
学完爬虫了,也要期末考试了QAQ,趁着复习赶紧记一波笔记,都是重点QAQ,这大概就是没有好好听课的痛。
什么是正则表达式
简单来说,就是通配符,通过某些特定的字符组合组成一个规则字符,来对字符串达到过滤的效果。比如word中常见的 * 和 ?就是正则表达式的使用。项目中最常用的是读取某一个文件夹中的所有文档,比如读取某文件夹下的全部图片为:“\d.*?\.jpg”。可能没有基础的人对这里还不太懂,那最常见的正则表达式在日常中的用法为敏感词替换,比如 “ 我 * ” 或者“ 你个 * * ”
为什么要学正则表达式
那这里就得提一下爬虫的步骤:
- 确定目标网站
- 解析网站信息
- 爬取所需信息
- 数据处理/存储
但当我们请求到一个网页信息的时候…他往往是这样的

要在这样一个网站里一个一个的找到所需信息…着实有点费眼睛
那就需要一个文本过滤器来找到我们所需的信息,爬虫中必不可少的一个文本过滤器就是正则表达式。
正则表达式的匹配规则
| 模式 | 描述 |
|---|---|
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9] |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| […] | 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’ |
| [^…] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| * | 匹配0个或多个的表达式。 |
| + | 匹配1个或多个的表达式。 |
| ? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| {n} | 精确匹配n个前面表达式。 |
| {n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a|b | 匹配a或b |
| ( ) | 匹配括号内的表达式,也表示一个组 |
有了正则表达式的基本信息,但在爬虫中,需要使用re模块才能发挥出正则表达式的最佳效果。
re模块
re 是Python 内置的专门用于处理正则表达式的模块。
re.match
re.match 会从字符串的起始位置匹配一个模式(从头开始),如果不是起始位置匹配成功的话,match()就返回none。
他的匹配规则为:
re.match(pattern, string, flags=0)
#pattern 匹配规则变量形式,string 字符串,
search方法
search方法用于查找字符串的任何位置,仅返回一个结果。
match()方法是从字符串的开头开始匹配,如果开头不匹配就会失败,所以可以使用search方法,就不会报错了。

findall方法
findall用于查找整个字符串,返回所有的结果。
使用方法为
findall(string[,pos[,endpos]])
split方法
split可以将字符串分割后返回列表。使用方法如下:
split(string[,maxsplit])
sub方法
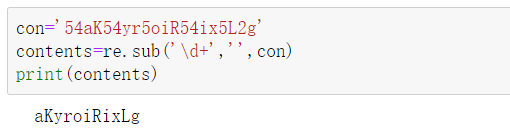
re.sub里的参数有三个,第一个:匹配规则;第二个:替换的内容;第三个:原字符串。常用于替换。
比如:想把所有数字都去掉。
中文(贪婪和非贪婪)
贪婪模式是尽可能多的匹配字符,非贪婪模式是尽可能匹配少的字符。
我们在做匹配的时候,字符串中间尽量使用非贪婪匹配,用. * ?代替 . * ,避免出现匹配结果缺失。
但是匹配结果出现在字符串结尾,.*?可能匹配不到任何内容。
一个完整的正则表达式匹配案例
以猫眼电影为例,网址: https://maoyan.com/board/4
import requests
url='https://maoyan.com/board/4?offset=0'
#设置本机的headers
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'}
res=requests.get(url,headers=headers) #请求
#print(res.status_code)
html=res.text
#导入re库进行解析
import re
pattern=re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?</dd>',re.S)
items=re.findall(pattern,html)
print(items)
#导入json以写入文件
import json
for item in items:
dict={}
dict['index']=item[0]
dict['image']=item[1]
dict['name']=item[2]
dict['star']=item[3].strip()
print(dict)
with open('result.txt','a',encoding='utf-8')as f:
f.write(json.dumps(dict,ensure_ascii=False)+'\n')
这便是使用正则表达式及re爬取一整页网页信息的方法。
小结
Python爬虫中经常会遇到反扒设置,有可能是在源码中对某些字符进行遮挡或是敏感词替换,这时候就会需要使用正则表达式来进行解析以爬取到正确的内容。
不过在日常爬虫的时候,用正则表达式就会有一点麻烦了,所以使用率不是很高,但又是爬虫中一项必不可少的技能,比正则表达式更简单的爬虫方法下篇见哦~















 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









