







BeautifulSoup
2.6.1安装BeautifulSoup
概念:BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库,它能够通过转换器实现大家惯用的文档导航、查找、修改文档等功能。使用BeautifulSoup可以快速实现一个完整的爬虫应用程序。
由于BeautifulSoup并不是Python标准库,因此需要单独安装。本书推荐安装BeautifulSoup4(以下简称BS4)版本。如果使用Windows系统,大家可通过下载源码的方式安装,下载地址为https://pypi.python.org/pypi/beautifulsoup4/
,选择Download files下载后缀名为.tar.gz的文件并解压,使用命令行进入解压后的文件中,执行如下命令即可安装成功:
对于Mac系统,可以通过pip包管理器(一个Python包管理工具)来安装,首先需要通过命令安装该管理器,命令如下:
注意Mac系统中自带Python 2版本,当使用pip包管理器将BS4安装到Python 3下时,安装命令如下:
至此BS4库安装完成,下面讲解它的用法。
2.6.2 BeautifulSoup的使用
Beautiful Soup 4.4.0 文档

print(soup.prettify())里prettify把html转换成工整的样子。

下面通过一个示例示范BeautifulSoup的简单使用。现有一段格式不良好的HTML内容,需要用BeautifulSoup确定其格式。
首先导入BS4库,接着创建HTML代码的字符串,最后创建BeautifulSoup对象。以下字符串html_doc中是需要确定格式的HTML内容,使用BeautifulSoup处理的具体代码如下所示:
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup=BeautifulSoup(html_doc,'html.parser')
print(soup.prettify())
运行示例代码后,输出结果如下所示:
从上面的输出结果中可以看出,BeautifulSoup正确补全了缺失的标签并对该HMTL文档进行了格式化。
此外,通过文件也可以创建BeautifulSoup对象,将字符串html_doc中的内容保存为index.html文件,具体创建方法如下所示: 
BeautifulSoup将复杂HTML文档转换为一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment。

使用fing_all(),如果找到则以列表的形式返回



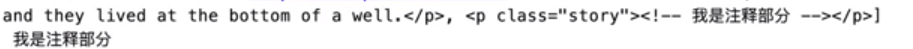



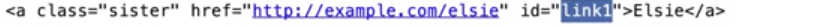
使用选择器查找




bs遍历文档树


父元素

本节讲解的BeautifulSoup()中统一使用了html解析器,即html. parser,这是Python自带的解析器。除此之外,还有常用的lxml解析器,该解析器需要通过pip命令安装,安装命令如下:
安装完成后,使用方法如BeautifulSoup(html_doc, ‘lxml’)。
本章小结
本章首先介绍了Cookie的概念以及在爬虫中的应用,以及Python中正则表达式的用法,接着介绍了网络爬虫所需掌握的Web基础知识,包括HTML标签、XPath、JSON数据格式等。最后重点介绍了BeautifulSoup库的使用方法,大家需重点掌握该库的用法。















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









