import csv
import random
import time
import pandas as pd
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
class Spider(object):
def __init__(self):
pass
def get_data_and_save(self):
with open('data.csv', 'w', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(['日期', '质量等级', 'AQI指数', '当天AQI排名', 'PM2.5', 'PM10', 'So2', 'No2', 'Co', 'O3'])
years = [2020, 2021, 2022]
months = range(1, 13)
for year in years:
for month in months:
if month < 10:
url = f'http://tianqihoubao.com/aqi/beijing-{year}0{month}.html'
else:
url = f'http://tianqihoubao.com/aqi/beijing-{year}{month}.html'
res = requests.get(url).text
soup = BeautifulSoup(res, 'html.parser')
for attr in soup.find_all('tr')[1:]:
one_day_data = list()
for index in range(0, 10):
one_day_data.append(attr.find_all('td')[index].get_text().strip())
csv_writer.writerow(one_day_data)
time.sleep(2 + random.random())
print(year, month)
def drawing(self):
csv_df = pd.read_csv('data.csv', encoding='GBK')
csv_df['日期'] = pd.to_datetime(csv_df['日期'])
csv_df.index = csv_df['日期']
del csv_df['日期']
str_data = '2020-01-01'
end_data = '2020-01-31'
new_split_df = csv_df[str_data:end_data]
values_count = new_split_df['质量等级'].value_counts().items()
total = new_split_df['质量等级'].value_counts().tolist()
label = new_split_df['质量等级'].value_counts().index
explode = [0.01 for i in range(len(total))]
fig, axes = plt.subplots(3, 1, figsize=(10, 8))
# 画饼图
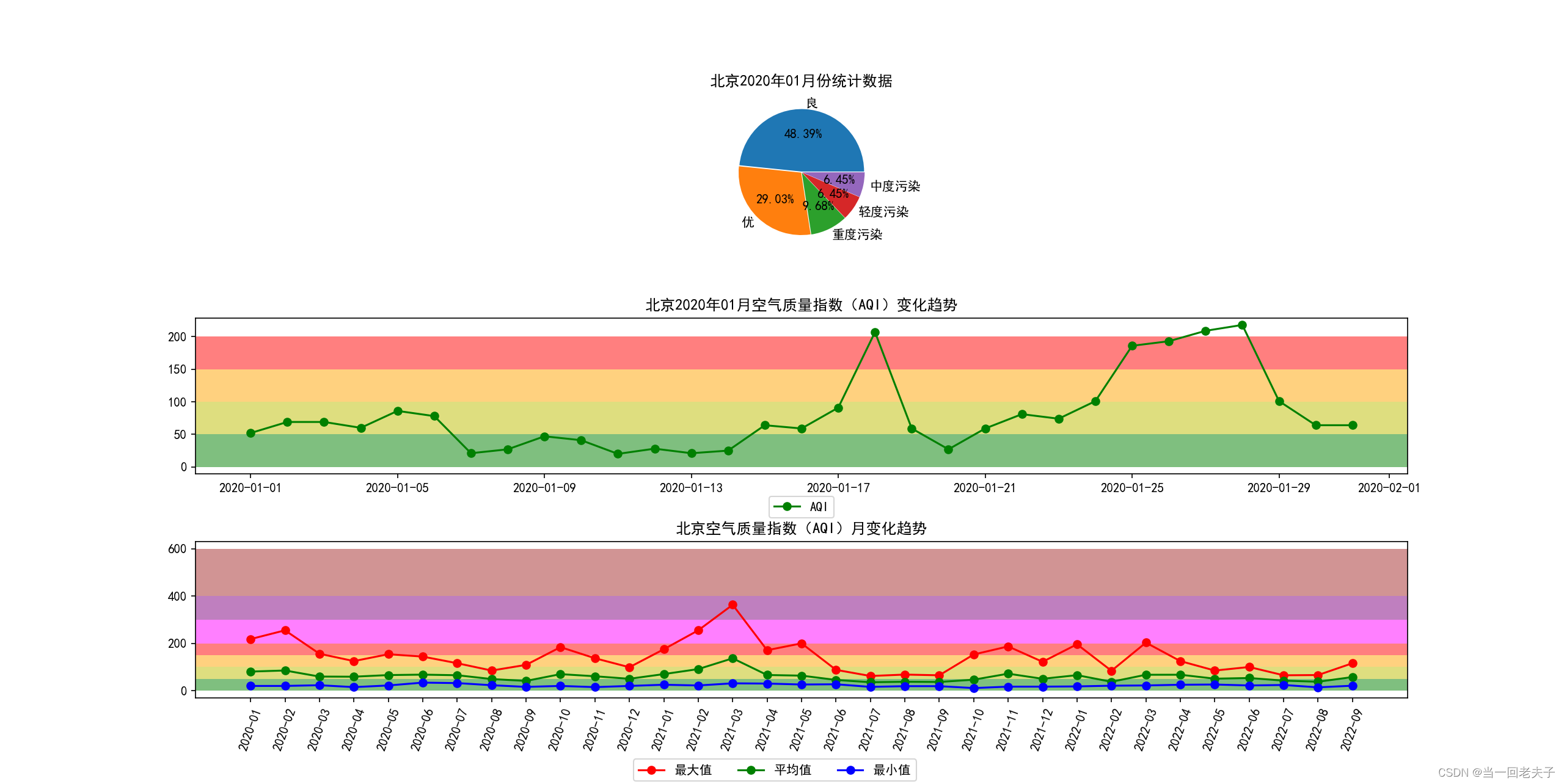
axes[0].pie(total, labels=label, autopct='%0.2f%%', explode=explode)
axes[0].set_title(f'北京{str_data.split("-")[0]}年{str_data.split("-")[1]}月份统计数据')
# 画折线图
axes[1].plot(new_split_df['AQI指数'], 'go-')
axes[1].axhspan(0, 50, facecolor='g', alpha=0.5)
axes[1].axhspan(50, 100, facecolor='y', alpha=0.5)
axes[1].axhspan(100, 150, facecolor='orange', alpha=0.5)
axes[1].axhspan(150, 200, facecolor='r', alpha=0.5)
axes[1].set_title(f'北京{str_data.split("-")[0]}年{str_data.split("-")[1]}月空气质量指数(AQI)变化趋势')
axes[1].legend(labels=('AQI',), loc='lower center', bbox_to_anchor=(0.5, -0.32))
# 画折线图
key = lambda x: f"{x.year}-{x.month}" if x.month >= 10 else f"{x.year}-0{x.month}"
AQI_max = csv_df.groupby(key)['AQI指数'].max()
AQI_ave = csv_df.groupby(key)['AQI指数'].mean()
AQI_min = csv_df.groupby(key)['AQI指数'].min()
axes[2].plot(AQI_max, 'go-', color='r')
axes[2].plot(AQI_ave, 'go-', color='g')
axes[2].plot(AQI_min, 'go-', color='b')
axes[2].axhspan(0, 50, facecolor='g', alpha=0.5)
axes[2].axhspan(50, 100, facecolor='y', alpha=0.5)
axes[2].axhspan(100, 150, facecolor='orange', alpha=0.5)
axes[2].axhspan(150, 200, facecolor='r', alpha=0.5)
axes[2].axhspan(200, 300, facecolor='magenta', alpha=0.5)
axes[2].axhspan(300, 400, facecolor='purple', alpha=0.5)
axes[2].axhspan(400, 600, facecolor='brown', alpha=0.5)
axes[2].legend(['最大值', '平均值', '最小值'], bbox_to_anchor=(0.6, -0.353), ncol=3)
plt.xticks(rotation=70)
plt.subplots_adjust(hspace=0.433, wspace=0.5)
axes[2].set_title(f'北京空气质量指数(AQI)月变化趋势')
plt.show()
if __name__ == '__main__':
spider = Spider()
# 获取数据,保存数据
spider.get_data_and_save()
# 画分析图
spider.drawing()
本案例只做教学用途,不可用于商业用途

























 1059
1059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











