






背景
Scrape Center 平台是一个练习爬虫比较好的平台,碍于很多有些该平台资料讲解的不够清晰,特此整理;
可收获:1.找出spa9题目 eval混淆中,对获取目标数据有帮助的js代码;2.需要用的spa7 解题方法,在文章最后。
正文
网址: https://spa9.scrape.center/
反爬特点:NBA球星数据网站,数据纯前端渲染,Token 经过加密处理,JavaScript经过eval混淆,适合JavaScript逆向分析。
目标数据:已知球员文本信息,获取base64编码信息

网站分析
1.访问 调试 网站 https://spa9.scrape.center/ ,搜索,观察到重要信息都在这里
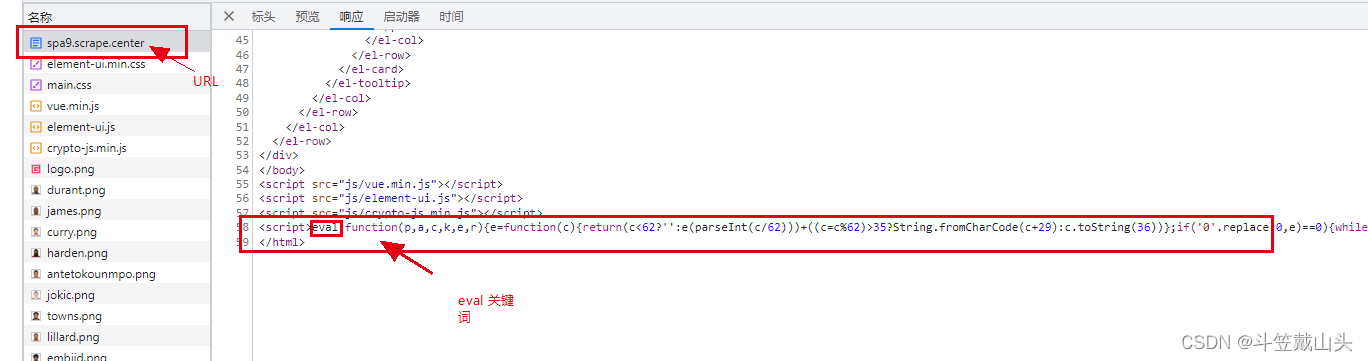
2.思考 eval里面的数据一定是个字符串;但是我们观察到的是js文件,所以可以尝试将eval里面的内容复制,在控制台打印一下;
上图是复制出来后的打印结果,报错 :Uncaught SyntaxError: Function statements require a function name,需要一个方法名;给此方法赋值为f后,再次运行,得到如下结果,是一个字符串;

去掉字符串后,放到js环境中进行
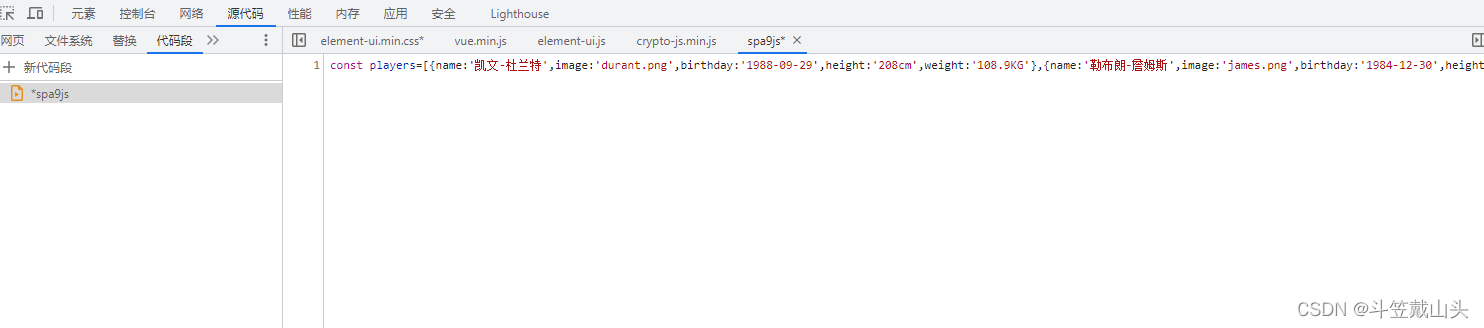
调整格式后如图:
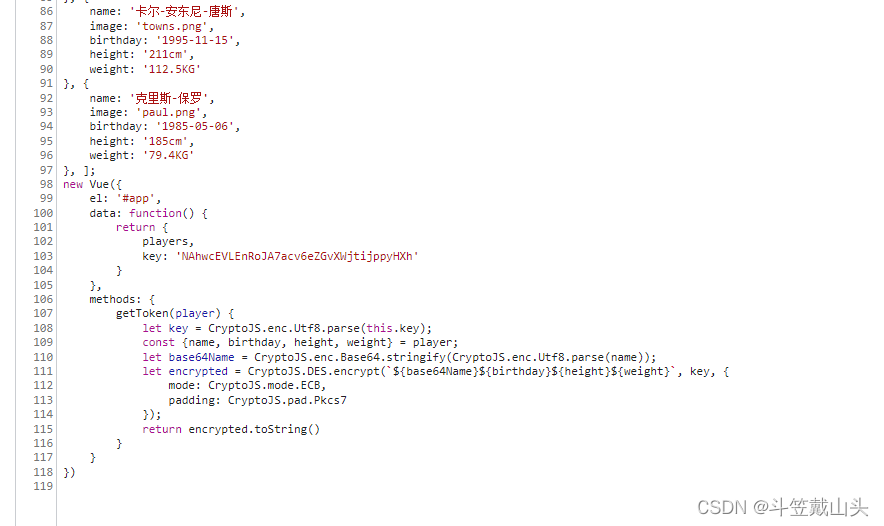
这便从eval中解放出来了关键代码。这个代码与spa7中的是一致的。
后续按照spa7中进行进行加密及转换城base64的格式的数据就可以了。
spa7中的解析 参考 崔大发表的文章
spa7token加密















 2298
2298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









