






【python还能这么玩?!】截图后粘贴就是词云图,秒看懂密密麻麻的文字图片!
前言
暑假在家闲来无事,总想着搞个项目来练练手,一开始想到是想用spark做个实时处理的项目,就是实时对视频弹幕生成词云图,这样就可以实时掌握网友的高频评论词语,使用的语言是Scala,用到的组件有sparkstream、kafka、redis、hdfs等等,因为是练手的项目,所以能多用几个组件就多用几个,处理过程都已经写好了,就是弹幕要实时获取似乎不太好搞,但是在昨天看了一篇文章,文章里面讲的是如何从照片中识别出其中的文字并将识别出来的文字放入剪切板以便直接复制,于是我又突发奇想,想到一个更好玩的玩法,那就是将照片作为数据来源,然后生成照片里面的文字的词云图并放入剪切板,粘贴就直接是词云图,后面这个项目全都使用python实现,至于开头讲的那个项目之后做出来再来分享给大家。效果图
不知道这个项目有什么用?不知道这个项目是在干什么?看完下面这个例子你就知道了。
你是否觉得前言介绍文字太多不想看?如果有这种感觉的话,那你就来对了。
下面直接来效果图:
我们将前言一大段文字截图下来:
然后使用快捷键,然后粘贴照片:

怎么样,是不是一眼就大致知道前言写了什么,这就是这个项目的目的!
看看动图效果
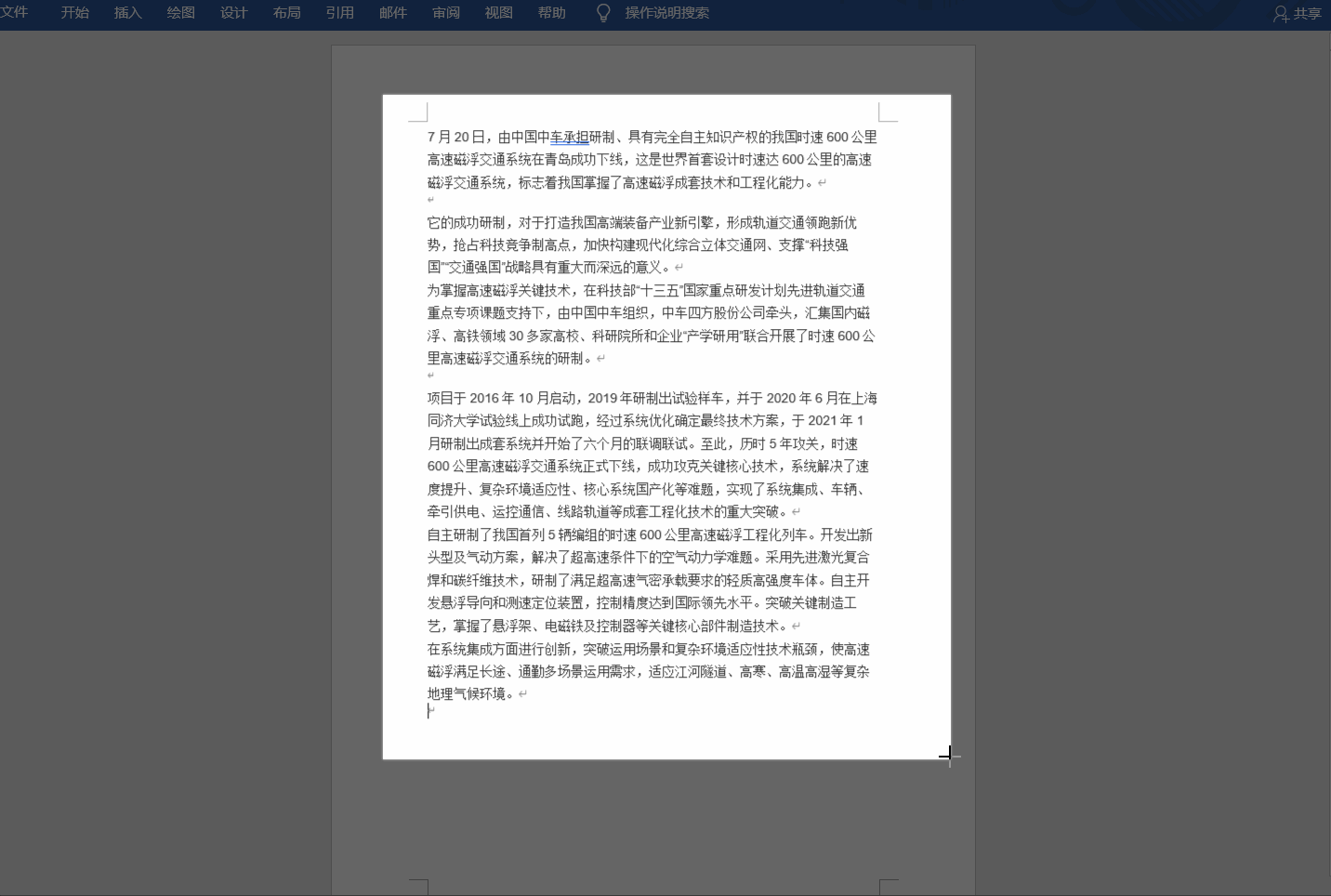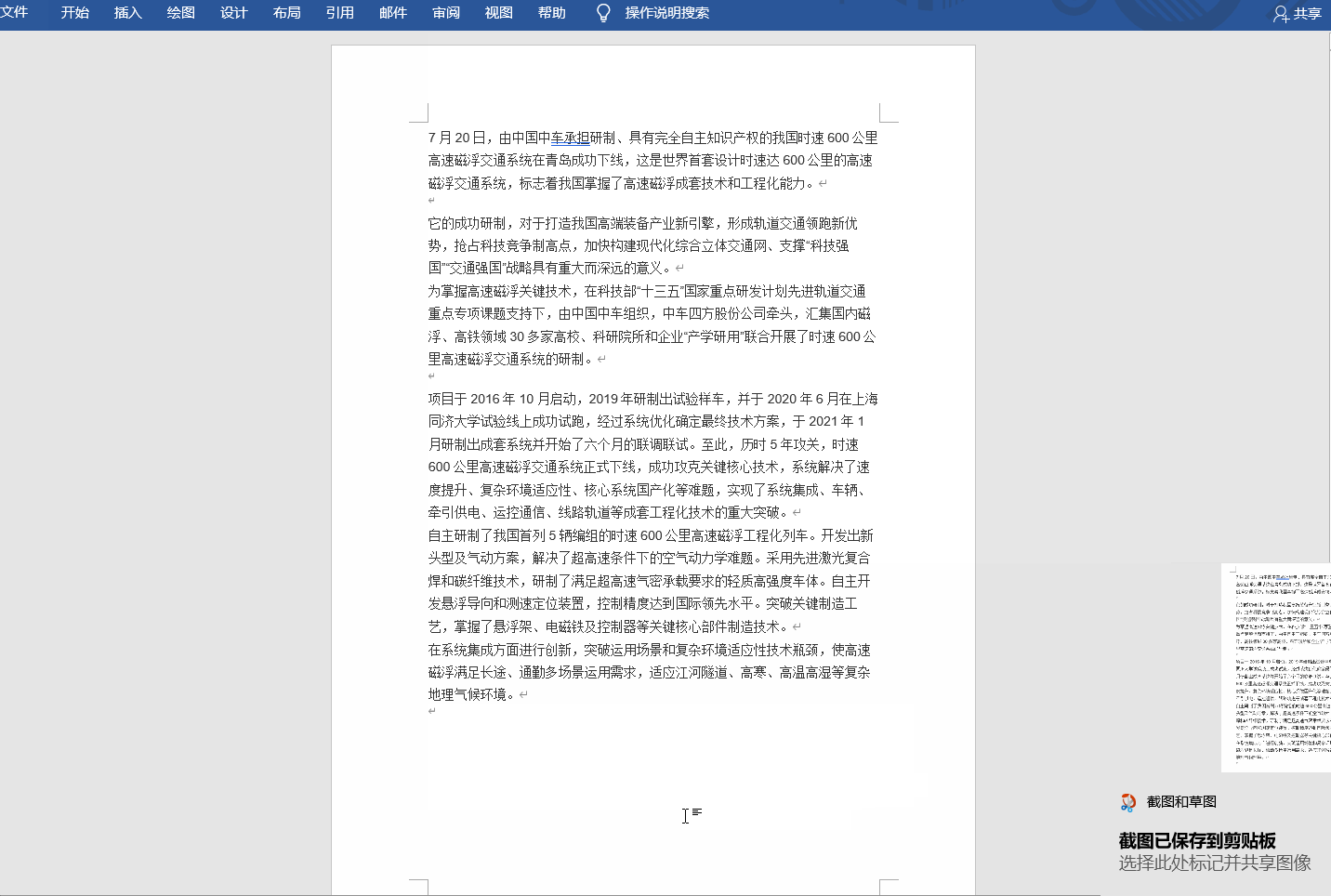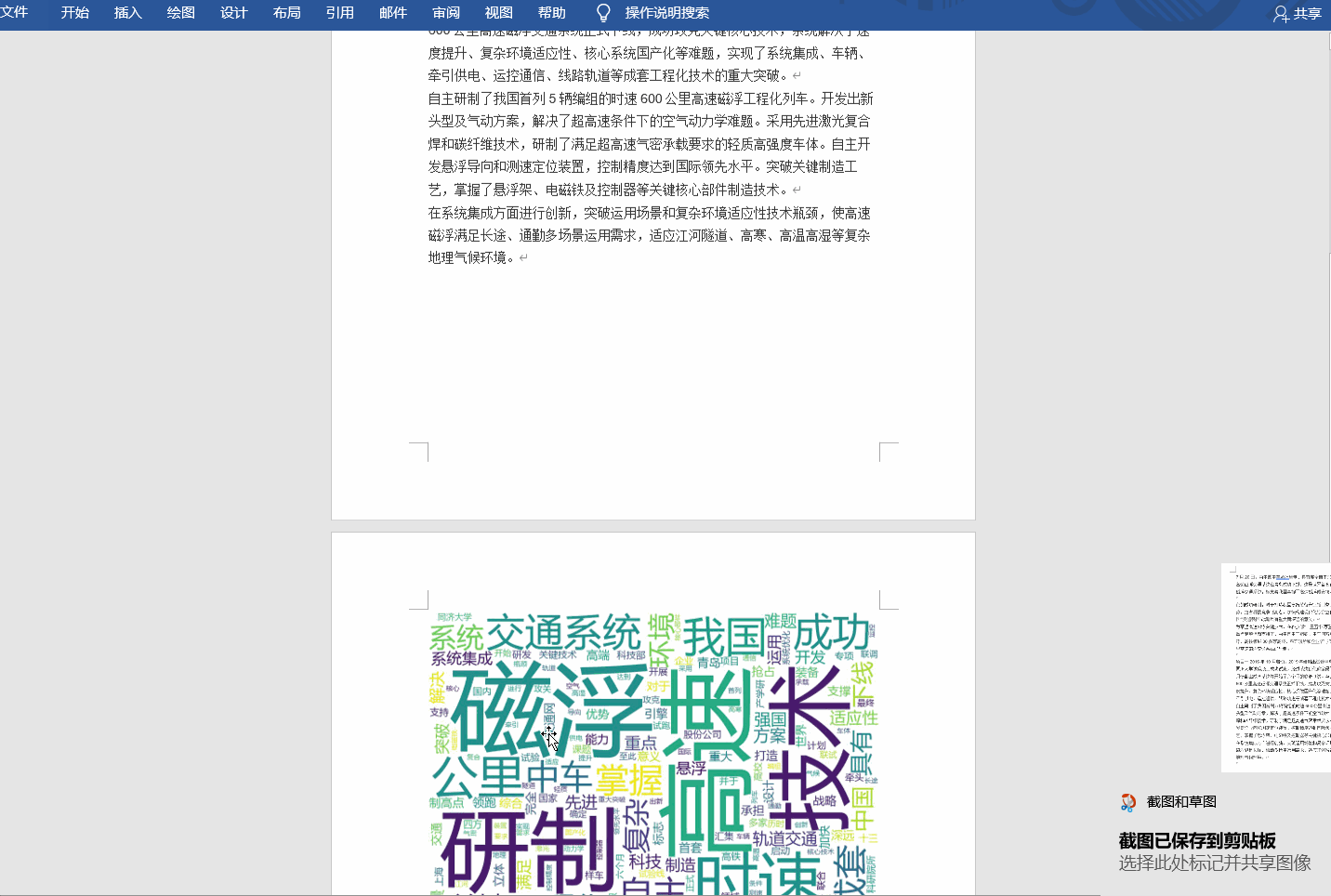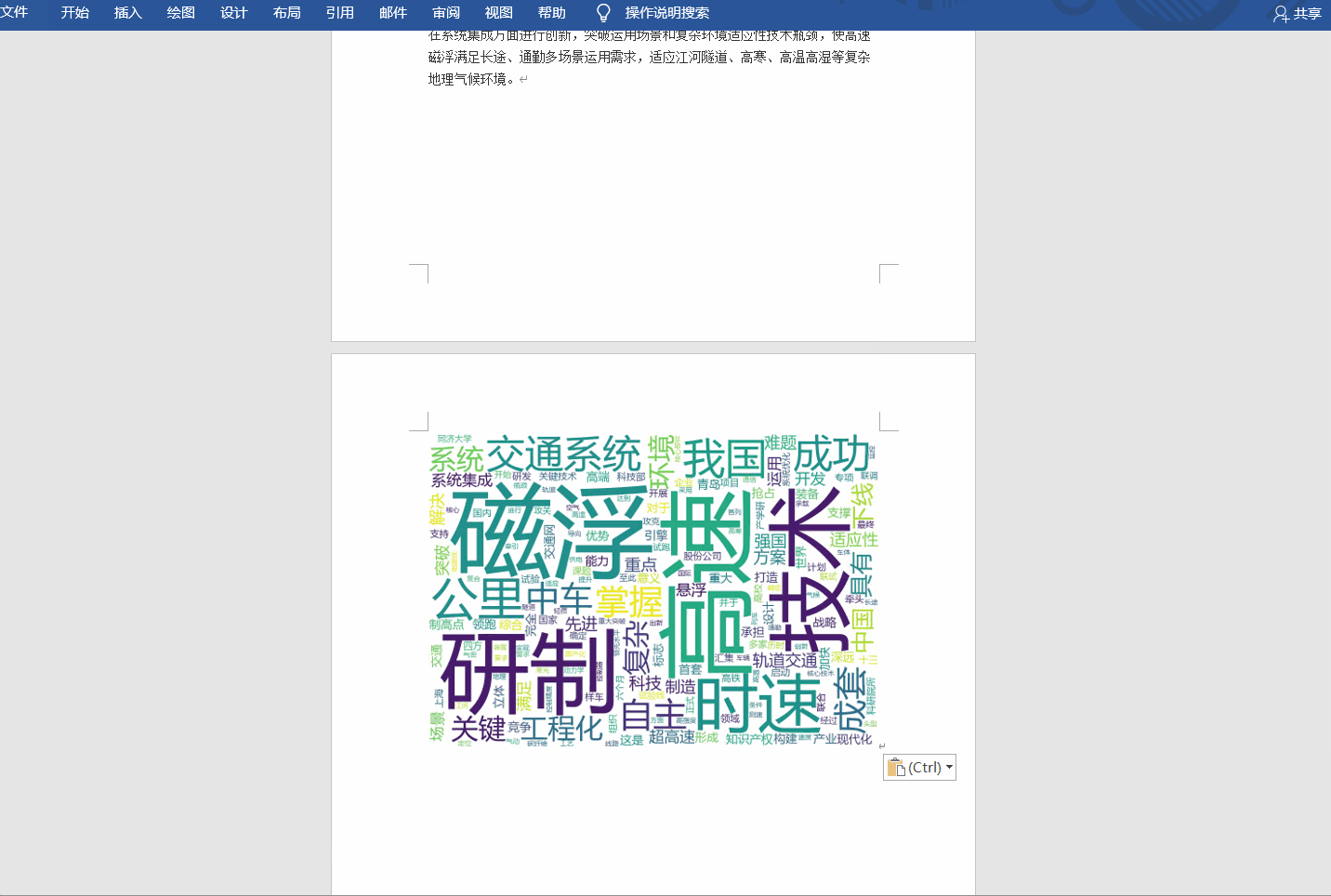
识别照片中的文字
这里直接调用了百度的api来实现,可以自行去创建一个文字识别应用以便调用。至于如何创建应用,可以参考文章最后的参考链接。
如何调用呢,首先pip install baidu_aip下载SDK,
def ocr_text(path):
"""
文字识别
:param path: 照片地址
:return: 识别出来的文字
"""
APP_ID = '你的 APP_ID'
API_KEY = '你的 API_KEY'
SECRET_KEY = '你的 SECRET_KEY'
# 建立连接
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
with open(path, 'rb') as f:
image = f.read()
# 调用百度API通用文字识别,提取图片中的内容
text = client.basicAccurate(image)
results = text["words_result"]
text = []
for result in results:
text.append(result["words"])
return "".join(text) # 拼接文字并返回
jieba切分文字
def fenci(data):
"""
精准切分文字
:param data: 识别出来的文字
:return: 词频字典
"""
wordList = jieba.lcut(data) # lcut是精准模式
counts = {} # 通过键值对的形式存储词语及其出现的次数
# 导入停用词
stopwords = [line.strip() for line in open("D:\stopwords.txt", encoding='UTF-8').readlines()]
for word in wordList:
# 去除数字
remove_digits = str.maketrans('', '', digits)
word = word.translate(remove_digits)
# 去除停用词以及单字词
if not (word.split()) in stopwords and len(word.strip()) > 1:
counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1
return counts
生成词云图
def wordcloud_image(wordDict, saveTime):
"""
制作词云图
:param wordDict: 词频字典
:param saveTime: 时间戳
:return: 词云图保存地址
"""
savePath = "D:\词云图\wordcloud_" + saveTime + ".jpg"
# 配置对象参数,可自行修改
w = wordcloud.WordCloud(width=1000, height=700, font_path="msyh.ttc", background_color="white")
# 加载词云文本
w.fit_words(wordDict)
# 输出词云文件
w.to_file(savePath)
return savePath
到此,主要功能其实已经可以实现出来了。
但是这一点都不完美!输入的文件路径得我们指定,输出路径也得我们指定,还得我们点运行才能生成,这么麻烦我要他干嘛。
所以,下面才是这篇文章的精华所在!
针对上面的三个问题,我们一一将其完善:
照片输入问题
读取剪切板里面的照片
def get_data():
"""
读取剪切板照片
:return: 照片保存地址,时间戳
"""
# 读取剪切板内容
im = ImageGrab.grabclipboard()
# 判断是否为照片
if isinstance(im, Image.Image):
saveTime = str(int(time.time())) # 路径加入时间戳以便区分
path = "D:\词云图\grab_"+saveTime+".jpg"
im.save(path) # 保存剪切板照片
return ocr_text(path), saveTime
return None
照片输出问题
照片放入剪切板
def send_msg_to_clip(type_data, msg):
"""
将词云图放入剪切板
:param type_data:
:param msg:
:return:
"""
win32clipboard.OpenClipboard()
win32clipboard.EmptyClipboard()
win32clipboard.SetClipboardData(type_data, msg)
win32clipboard.CloseClipboard()
def paste_img(file_img):
"""
读取词云图并转为二进制字符串
:param file_img:词云图地址
:return:
"""
image = Image.open(file_img)
output = BytesIO()
image.save(output, 'BMP')
data = output.getvalue()[14:]
output.close()
send_msg_to_clip(win32clipboard.CF_DIB, data)
程序运行问题
程序要显式运行,每次还只能运行一次,想想都觉得不完美,于是我们改成后台运行,并加入死循环。
新建OCR.bat
python OCR.py # 运行python程序
新建OCR.vbs
Set ws = CreateObject("Wscript.Shell")
ws.run "cmd /c OCR.bat",0 # 无窗口启动OCR.bat
如何调用程序生成词云图? 在这里我使用到了监听键盘,通过快捷键来执行程序
if __name__ == '__main__':
while True: # 死循环,使程序一直处于监听状态
keyboard.wait('shift + alt + e') # 可自定义快捷键
try:
data, saveTime = get_data()
counts = fenci(data)
imagepath = wordcloud_image(counts, saveTime)
paste_img(imagepath)
except:
pass
设置开机自启
首先我们按win+R,并输入shell:startup进入
接着我们将刚刚创建的OCR.py、OCR.bat、OCR.vbs这三个文件一并放入其中
最后重启电脑即可
使用
如何使用我们这个小组件呢?
首先,我们可以利用系统自带的截图shift + win + s进行截图,或者直接复制一张照片
接着通过我们上面定义的快捷键shift + alt + e来执行程序
最后,词云图已经在剪切板中了,我们将其粘贴到任意位置。
我们再来看看效果,这次我们从网上复制一片新闻稿,因为我觉得用这个方法来读新闻还是挺直观的。
截图

shift + alt + e
稍等一两秒
粘贴

效果还不错。
到此,才算完美的实现了全部内容。
参考文章
本文参考了以下文章:
https://blog.csdn.net/skylibiao/article/details/118718440
https://www.cnblogs.com/enumx/p/12359863.html
源码
想直接拿到源码就可以用的小伙伴,可以在评论区告诉我哦!
实现过程有什么问题或者有什么建议都可以给我留言哦!
还有,记得留下你的【点赞,收藏,关注】哦!
最后,祝大家学习顺利!















 1517
1517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









