









Learning Structured Inference Neural Networks with Label Relations
主要内容:
场景的图像具有不同的对象和丰富的属性,可以进行不同层次的视觉分类。自然图像可以使用细粒度标签(描述主要组件)、粗粒度标签(描述高级抽象)或一组显示属性的标签来分配。这种在不同概念层上的分类可以用包含标签信息的标签图来建模。利用这一丰富的信息和一个先进的深度学习框架,并提出了一个通用的结构化模型,利用不同的标签关系来提高图像分类性能。
模型结构

方法:
利用标签关系来改进对分层视觉概念的推断。
大致思路:输入图片——CNN提取特征作为每层的输入特征——概念层从细粒度层堆叠到较粗粒度层(标签关系被定义为连续层之间的关系,并形成一个分层的图形),层间关系和层内关系都由RNN来捕捉
具体细节:
(1)第一层的输入 x t i x^i_t xti:CNN提取图片特征 I i I^i Ii 并将图片变为4096维的特征向量;
x t i = W t ⋅ C N N ( I i ) + b x , t x^i_t=W_t\cdot CNN(I^i)+b_x,_t xti=Wt⋅CNN(Ii)+bx,t
(2)自顶向下和自底向上的推理:
为了生成具体标签的概率在
x
t
i
x^i_t
xti上应用了一个简单的激活函数,将其变为
a
t
i
a^i_t
ati,那么信息传递过程可以表示为:
a t i = V t − 1 , t ⋅ a t − 1 i + H t ⋅ x t i + b a , t a^i_t=V_{t-1},_t\cdot a^i_{t -1}+H_t\cdot x^i_t+b_a,_t ati=Vt−1,t⋅at−1i+Ht⋅xti+ba,t
其中
V
t
−
1
,
t
V_{t-1,t}
Vt−1,t是自顶向下的层间参数,
H
t
H_t
Ht表示层内标签关系。与标准的RNN不同,标准RNN在每一步重复学习V和H,而模型中的
V
t
−
1
V_{t-1}
Vt−1和
H
t
H_t
Ht是每一时间步的V和H。
为了学习到这两个参数加入损失函数:
∑ i = 1 N ∑ t = 1 T ∑ y = 1 n t ( 1 ( y t i = y ) ⋅ l o g ( o ˊ ) ( a t i ) + 1 ( y t i ≠ y ) ⋅ l o g ( 1 − o ˊ ( ( a t i ) ) \boxed{\sum\limits_{i = 1}^{N}\sum\limits_{t = 1}^{T} \sum\limits_{y = 1}^{n_t}(1(y^i_t=y)\cdot log(ó)(a^i_t)+1(y^i_t\ne y)\cdot log(1-ó((a^i_t))} i=1∑Nt=1∑Ty=1∑nt(1(yti=y)⋅log(oˊ)(ati)+1(yti̸=y)⋅log(1−oˊ((ati))
(3)构建BINN:
a
→
t
i
=
V
→
t
−
1
,
t
⋅
a
→
t
−
1
i
+
H
→
t
⋅
x
t
i
+
b
→
t
\overrightarrow{a}^i_t= \overrightarrow {V}_{t-1,t}\cdot\overrightarrow{a}^i_{t-1}+\overrightarrow{H}_{t}\cdot x^i_t+\overrightarrow b_t
ati=Vt−1,t⋅at−1i+Ht⋅xti+bt
a
t
i
←
=
V
←
t
−
1
,
t
⋅
a
←
t
−
1
i
+
H
←
t
⋅
x
t
i
+
b
←
t
\overleftarrow{a^i_t}= \overleftarrow {V}_{t-1,t}\cdot\overleftarrow{a}^i_{t-1}+\overleftarrow{H}_{t}\cdot x^i_t+\overleftarrow b_t
ati=Vt−1,t⋅at−1i+Ht⋅xti+bt
a
t
i
=
U
→
t
⋅
a
→
t
i
+
U
←
t
⋅
a
←
t
i
+
b
a
,
t
{a^i_t}=\overrightarrow{U}_{t}\cdot \overrightarrow a^i_t+ \overleftarrow {U}_t\cdot\overleftarrow{a}^i_{t}+b_{a,t}
ati=Ut⋅ati+Ut⋅ati+ba,t
(4)为了避免参数太多,构建SINN:利用正相关和负相关的结构化标签关系作为先验知识,对模型进行了改进,如果两者之间没有语义关系将其设置为0
构建规则如下:

a
→
t
i
=
γ
(
V
+
→
t
−
1
,
t
⋅
a
→
t
−
1
i
)
+
γ
(
H
+
→
t
⋅
x
t
i
)
−
γ
(
V
−
→
t
−
1
,
t
⋅
a
→
t
−
1
i
)
−
γ
(
H
−
→
t
⋅
x
t
i
)
+
b
→
t
\overrightarrow{a}^i_t= \gamma(\overrightarrow {V^+}_{t-1,t}\cdot\overrightarrow{a}^i_{t-1})+\gamma(\overrightarrow{H^+}_{t}\cdot x^i_t)-\gamma(\overrightarrow {V^-}_{t-1,t}\cdot\overrightarrow{a}^i_{t-1})-\gamma(\overrightarrow{H^-}_{t}\cdot x^i_t)+\overrightarrow b_t
ati=γ(V+t−1,t⋅at−1i)+γ(H+t⋅xti)−γ(V−t−1,t⋅at−1i)−γ(H−t⋅xti)+bt
a
←
t
i
=
γ
(
V
+
←
t
−
1
,
t
⋅
a
←
t
−
1
i
)
+
γ
(
H
+
←
t
⋅
x
t
i
)
−
γ
(
V
−
←
t
−
1
,
t
⋅
a
←
t
−
1
i
)
−
γ
(
H
−
←
t
⋅
x
t
i
)
+
b
←
t
\overleftarrow{a}^i_t= \gamma(\overleftarrow {V^+}_{t-1,t}\cdot\overleftarrow{a}^i_{t-1})+\gamma(\overleftarrow{H^+}_{t}\cdot x^i_t)-\gamma(\overleftarrow {V^-}_{t-1,t}\cdot\overleftarrow{a}^i_{t-1})-\gamma(\overleftarrow{H^-}_{t}\cdot x^i_t)+\overleftarrow b_t
ati=γ(V+t−1,t⋅at−1i)+γ(H+t⋅xti)−γ(V−t−1,t⋅at−1i)−γ(H−t⋅xti)+bt
a
t
i
=
U
→
t
⋅
a
→
t
i
+
U
←
t
⋅
a
←
t
i
+
b
a
,
t
{a^i_t}=\overrightarrow{U}_{t}\cdot \overrightarrow a^i_t+ \overleftarrow {U}_t\cdot\overleftarrow{a}^i_{t}+b_{a,t}
ati=Ut⋅ati+Ut⋅ati+ba,t
(5)用部分观察预测可以改善另一概念层的结果:比如知道户外人造场地再预测棒球拍的概率就会更大一点。将预测标签转化为激活概率去改善目标概念层:
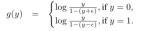
g
(
y
)
=
{
l
o
g
(
y
1
−
(
y
+
ε
)
,
i
f
y
=
0
;
l
o
g
(
y
1
−
(
y
−
ε
)
i
f
y
=
1
g(y)=\Big\{log (\dfrac{y}{1-(y+\varepsilon)},if \quad y=0\quad ;\quad log (\dfrac{y}{1-(y-\varepsilon)}if \quad y=1
g(y)={log(1−(y+ε)y,ify=0;log(1−(y−ε)yify=1
论文下载链接:https://arxiv.org/abs/1511.05616















 3000
3000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









