







PREDATOR: Registration of 3D Point Clouds with Low Overlap 损失函数含代码理解

2021/10/24 损失函数部分整理完毕
2021/10/23 写完了Circle loss,有时间再写后面两个损失函数
主要讲解损失函数,个人理解,有错误欢迎指出~
不愧的oral,真的很🐂
=========================================================
PREDATOR使用了三个损失函数:Circle loss,Overlap loss 和 Matchability loss
Overlap loss,Matchability loss
Overlap loss 和 Matchability loss 的估计采用二进制分类。
我们将点云输入 model,得到输出 scores_overlap, scores_saliency。
直接看代码。
这一步是从correspondence中得到匹配点,比如 correspondence 中第n个元素是
[
q
,
p
]
[q, p]
[q,p],也就是点云
P
P
P 中的第
p
p
p 个点和点云
Q
Q
Q 的第
q
q
q 个点是对应的。
# correspondence [N,2]
src_idx = list(set(correspondence[:,0].int().tolist()))
tgt_idx = list(set(correspondence[:,1].int().tolist()))
这里 correspondence 是由 get_correspondences 函数得到,在tgt_pcd 中,以src_pcd中每个点为中心,查找指定半径(search_voxel_size)内的点,返回点的索引。
def get_correspondences(src_pcd, tgt_pcd, trans, search_voxel_size, K=None):
src_pcd.transform(trans)
pcd_tree = o3d.geometry.KDTreeFlann(tgt_pcd)
correspondences = []
for i, point in enumerate(src_pcd.points):
[count, idx, _] = pcd_tree.search_radius_vector_3d(point, search_voxel_size)
if K is not None:
idx = idx[:K]
for j in idx:
correspondences.append([i, j])
correspondences = np.array(correspondences)
correspondences = torch.from_numpy(correspondences)
return correspondences
overlap loss
# get BCE loss for overlap, here the ground truth label is obtained from correspondence information
src_gt = torch.zeros(src_pcd.size(0))
src_gt[src_idx]=1.
tgt_gt = torch.zeros(tgt_pcd.size(0))
tgt_gt[tgt_idx]=1.
gt_labels = torch.cat((src_gt, tgt_gt)).to(torch.device('cuda'))
class_loss, cls_precision, cls_recall = self.get_weighted_bce_loss(scores_overlap, gt_labels)
stats['overlap_loss'] = class_loss
stats['overlap_recall'] = cls_recall
stats['overlap_precision'] = cls_precision
现在来看 get_weighted_bce_loss 函数,输入是 scores 和 gt
def get_weighted_bce_loss(self, prediction, gt):
# 初始化 bce loss
loss = nn.BCELoss(reduction='none')
# 计算 bce loss
class_loss = loss(prediction, gt) # [N]
# 设置权重惩罚,为了平衡分类结果的占比
weights = torch.ones_like(gt)
w_negative = gt.sum()/gt.size(0)
w_positive = 1 - w_negative
weights[gt >= 0.5] = w_positive
weights[gt < 0.5] = w_negative
w_class_loss = torch.mean(weights * class_loss)
#######################################
# 得到分类准确率签 和 召回率
# 分类标签,四舍五入
predicted_labels = prediction.detach().cpu().round().numpy()
cls_precision, cls_recall, _, _ = precision_recall_fscore_support(gt.cpu().numpy(),predicted_labels, average='binary')
return w_class_loss, cls_precision, cls_recall
matchability loss
# 只关注重叠区域
src_feats_sel, src_pcd_sel = src_feats[src_idx], src_pcd[src_idx]
tgt_feats_sel, tgt_pcd_sel = tgt_feats[tgt_idx], tgt_pcd[tgt_idx]
# 计算分数,分数越高说明src_feats_sel中特征和tgt_feats_sel中的特征相似
scores = torch.matmul(src_feats_sel, tgt_feats_sel.transpose(0,1))
# 得到和src_feats_sel最相似的tgt_feats_sel
_, idx = scores.max(1)
# 由上步就可以计算两个特征相似点对之间的距离
distance_1 = torch.norm(src_pcd_sel - tgt_pcd_sel[idx], p=2, dim=1)
# 得到和tgt_feats_sel最相似的src_feats_sel
_, idx = scores.max(0)
distance_2 = torch.norm(tgt_pcd_sel - src_pcd_sel[idx], p=2, dim=1)
# 设置gt_labels, 距离<self.matchability_radius,gt_labels=1,反之为0
gt_labels = torch.cat(((distance_1<self.matchability_radius).float(), (distance_2<self.matchability_radius).float()))
src_saliency_scores = scores_saliency[:src_pcd.size(0)][src_idx]
tgt_saliency_scores = scores_saliency[src_pcd.size(0):][tgt_idx]
scores_saliency = torch.cat((src_saliency_scores, tgt_saliency_scores))
# 和 overlap loss 一样
class_loss, cls_precision, cls_recall = self.get_weighted_bce_loss(scores_saliency, gt_labels)
stats['saliency_loss'] = class_loss
stats['saliency_recall'] = cls_recall
stats['saliency_precision'] = cls_precision
Circle loss
原始定义
Circle loss 是基于一对相似性优化的深度特征学习方法,给定带有
K
K
K个类内相似性分数,
L
L
L个类间相似性分数,通过最大化类内相似性
S
p
S_p
Sp和最小化类间相似性
S
n
S_n
Sn,Circle loss 的原始定义如下:
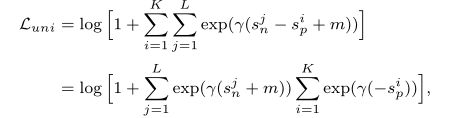
γ
\gamma
γ是尺度参数,
m
m
m 是优化的严格程度。
我们目标是让Circle loss减小:
- 最小化类内相似性(正样本):当 s n s_n sn 变小时, ∑ e x p ( γ ( s n + m ) ) \sum{exp(\gamma(s_n+m))} ∑exp(γ(sn+m)) 变小
- 最大化类间相似性(负样本):当 s p s_p sp 变大时, − s p -s_p −sp 变小, ∑ e x p ( γ ( − s p ) ) \sum{exp(\gamma(-s_p))} ∑exp(γ(−sp)) 变小
因此Circle loss变小,我们的优化目的达到。
PREDATOR中的Circle loss
现在说明PREDATOR中的Circle loss。
PREDATOR中的Circle loss 由两部分组成:
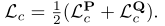
我们只其中介绍一个,另一个计算方法是一样的。
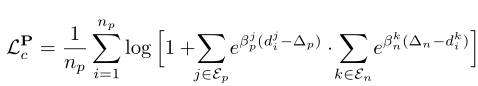
公式中第一部分
∑
e
β
(
d
−
Δ
p
)
\sum{e^{\beta(d-\Delta_p)}}
∑eβ(d−Δp) 表示类内相似性;第二部分
∑
e
β
(
Δ
n
−
d
)
\sum{e^{\beta(\Delta_n-d)}}
∑eβ(Δn−d) 表示类间相似性。
d i j = ∣ ∣ f p i − f q j ∣ ∣ 2 d^j_i=||f_{p_i}-f_{q_j}||_2 dij=∣∣fpi−fqj∣∣2 (欧氏距离)
β p j = γ ( d i j − Δ p ) \beta^j_p=\gamma(d^j_i-\Delta_p) βpj=γ(dij−Δp) (表示权重)
考虑由重叠部分的点云 P P P, Q Q Q,二者已经经过旋转矩阵对齐过。我们在点云 P P P 中提取点集 P p P_p Pp, P p P_p Pp 中的每一个点 p i p_i pi 在点云 Q Q Q 中至少能找到一个对应。公式中的 ε p ( p i ) \varepsilon_p(p_i) εp(pi) 定义为以 p i p_i pi 为中心, Q Q Q 到 p i p_i pi 的距离小于指定半径的点集。
代码
计算circle_loss比上面两个损失更为严格,设置的半径更小
#######################################
# 过滤一些correspondence 因为"overlap" and "correspondence"的半径不一样
# 计算两个点云对应点对之间的距离
c_dist = torch.norm(src_pcd[correspondence[:,0]] - tgt_pcd[correspondence[:,1]], dim = 1)
# 选择符合条件的对应点对
c_select = c_dist < self.pos_radius - 0.001
correspondence = correspondence[c_select]
# 如果更新的correspondence数量过多,就随机选择self.max_points个点对
if(correspondence.size(0) > self.max_points):
choice = np.random.permutation(correspondence.size(0))[:self.max_points]
correspondence = correspondence[choice]
src_idx = correspondence[:,0]
tgt_idx = correspondence[:,1]
src_pcd, tgt_pcd = src_pcd[src_idx], tgt_pcd[tgt_idx]
src_feats, tgt_feats = src_feats[src_idx], tgt_feats[tgt_idx]
#######################
# 计算距离 get L2 distance between source / target point cloud
coords_dist = torch.sqrt(square_distance(src_pcd[None,:,:], tgt_pcd[None,:,:]).squeeze(0))
feats_dist = torch.sqrt(square_distance(src_feats[None,:,:], tgt_feats[None,:,:],normalised=True)).squeeze(0)
##############################
# get FMR and circle loss
##############################
recall = self.get_recall(coords_dist, feats_dist)
circle_loss = self.get_circle_loss(coords_dist, feats_dist)
stats['circle_loss']= circle_loss
stats['recall']=recall
重点来看circle loss
circle_loss = self.get_circle_loss(coords_dist, feats_dist)
输入:coords_dist feats_dist
coords_dist 是点云
P
P
P,
Q
Q
Q之间的平方距离, 维度是 [N, M]
feats_dist 是点云
P
P
P 的特征和
Q
Q
Q 的特征之间的平方距离,维度是[N, M]
每一行表示 P 中的一个元素到 Q 中所有元素的距离
每一列则是表示 Q 中的一个元素到 P 中所有元素的距离
为了方便描述,我把属于类内相似性的点对、特征对记为positive,相反,记为negative。
首先确定每个点的 positive 和 negative
# 距离小于半径的属于 positive
pos_mask = coords_dist < self.pos_radius
# 距离大于半径的属于 negative
neg_mask = coords_dist > self.safe_radius
获得同时具有 positive 和 negative 的锚点
row_sel = ((pos_mask.sum(-1)>0) * (neg_mask.sum(-1)>0)).detach()
col_sel = ((pos_mask.sum(-2)>0) * (neg_mask.sum(-2)>0)).detach()
计算权重 β p j = γ ( d i j − Δ p ) \beta^j_p=\gamma(d^j_i-\Delta_p) βpj=γ(dij−Δp)
# feats_dist 中属于 negative 的减去 1e5,就变成了负值
pos_weight = feats_dist - 1e5 * (~pos_mask).float() # mask the non-positive
# self.pos_optimal 是一个经验值
pos_weight = (pos_weight - self.pos_optimal)
# 比较torch.zeros_like(pos_weight), pos_weight
# pos_weight 中的负数都为0,也就是 negative 的赋值为0,只留下了 positive
pos_weight = torch.max(torch.zeros_like(pos_weight), pos_weight).detach()
# 原理同上
neg_weight = feats_dist + 1e5 * (~neg_mask).float() # mask the non-negative
neg_weight = (self.neg_optimal - neg_weight) # mask the uninformative negative
neg_weight = torch.max(torch.zeros_like(neg_weight),neg_weight).detach()
计算类内相似性
∑
e
β
(
d
−
Δ
p
)
\sum{e^{\beta(d-\Delta_p)}}
∑eβ(d−Δp) 和类间相似性
∑
e
β
(
Δ
n
−
d
)
\sum{e^{\beta(\Delta_n-d)}}
∑eβ(Δn−d)
上面已经计算出
β
\beta
β : pos_weight, neg_weight
# 类内相似性
lse_pos_row = torch.logsumexp(self.log_scale * (feats_dist - self.pos_margin) * pos_weight,dim=-1)
lse_pos_col = torch.logsumexp(self.log_scale * (feats_dist - self.pos_margin) * pos_weight,dim=-2)
# 类间相似性
lse_neg_row = torch.logsumexp(self.log_scale * (self.neg_margin - feats_dist) * neg_weight,dim=-1)
lse_neg_col = torch.logsumexp(self.log_scale * (self.neg_margin - feats_dist) * neg_weight,dim=-2)
circle loss
# F.softplus(x) = log(1 + exp(x))
loss_row = F.softplus(lse_pos_row + lse_neg_row)/self.log_scale
loss_col = F.softplus(lse_pos_col + lse_neg_col)/self.log_scale
circle_loss = (loss_row[row_sel].mean() + loss_col[col_sel].mean()) / 2
return circle_loss
get_recall
召回率,没啥好说的。
def get_recall(self,coords_dist,feats_dist):
"""
Get feature match recall, divided by number of true inliers
"""
pos_mask = coords_dist < self.pos_radius
n_gt_pos = (pos_mask.sum(-1)>0).float().sum()+1e-12
_, sel_idx = torch.min(feats_dist, -1)
sel_dist = torch.gather(coords_dist,dim=-1,index=sel_idx[:,None])[pos_mask.sum(-1)>0]
n_pred_pos = (sel_dist < self.pos_radius).float().sum()
recall = n_pred_pos / n_gt_pos
return recall















 1998
1998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









