







 文章介绍了开源项目Fairlearn,它帮助数据科学家评估和改进AI系统的公平性。通过使用PyCharm和UCIadult数据集,展示了如何训练决策树模型并评估其公平性。文章进一步讨论了模型的性别预测差异,并使用Fairlearn的去偏方法,特别是指数梯度缓解技术,减少选择率的不公平性差异。
文章介绍了开源项目Fairlearn,它帮助数据科学家评估和改进AI系统的公平性。通过使用PyCharm和UCIadult数据集,展示了如何训练决策树模型并评估其公平性。文章进一步讨论了模型的性别预测差异,并使用Fairlearn的去偏方法,特别是指数梯度缓解技术,减少选择率的不公平性差异。
1、Fairlearn简介
- Fairlearn是一个开源的项目,旨在帮助数据科学家提高了 AI 系统的公平性。
- 作用:评定和改正人工智能技术系统软件的公平性。
- Fairlearn官网:Fairlearn
2、安装Fairlearn
- pip安装
-
pip install fairlearn - conda安装
-
conda install -c conda-forge fairlearn
3、使用示例
- 使用PyCharm建立一个新的项目。
3.1、导入数据集
- 使用UCI adult数据集,该数据集可以用于预测个人的年收入是否大于50K。
- 创建一个新的文件oldData.py。编写如下代码:
-
import pandas as pd # 数据分析库 from sklearn.datasets import fetch_openml # 数据集库 data = fetch_openml(data_id=1590, as_frame=True, parser='auto') # 获取openml上ID为1590的数据集,作为Pandas DataFrame格式 sex = data.data['sex'] # 将sex列分离出来 print(sex.value_counts()) # 统计sex列数量 # 以下语句后续训练模型时会用到 x = pd.get_dummies(data.data) # 对类别特征进行热编码处理 y_50k = (data.target == '>50K') * 1 # 将工资大于50k的设置为1,可单独print(data.target)进行查看 -
运行结果:
-

-
可以看出,UCI adult数据集是一个不平衡的数据集,男性样本数量是女性样本数量的两倍。
3.2、评估模型公平性
- Fairlearn提供了多个公平性指标,可以用来评估模型的公平性。
- 利用决策树,并使用之前的数据集训练出一个模拟模型,然后验证该模型的公平性。
- 创建一个新的文件oldFairness.py。编写如下代码:
-
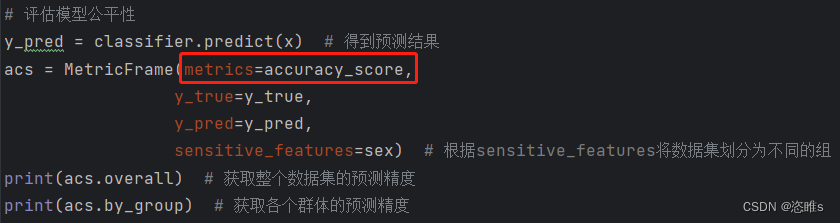
from fairlearn.metrics import MetricFrame # 评估模型公平性 from sklearn.metrics import accuracy_score # 计算精度 from sklearn.tree import DecisionTreeClassifier # 决策树 # 引入变量 from oldData import x, sex, y_true # 训练模型 classifier = DecisionTreeClassifier(min_samples_leaf=10, max_depth=4) # min_samples_leaf:叶子节点最小样本数,值越大,通常树的复杂度越低 # max_depth:树的最大深度,限制深度可以避免过拟合 classifier.fit(x, y_true) # 训练模型 # 评估模型公平性 y_pred = classifier.predict(x) # 得到预测结果 asc = MetricFrame(metrics=accuracy_score, y_true=y_true, y_pred=y_pred, sensitive_features=sex) # 根据sensitive_features将数据集划分为不同的组 print(acs.overall) # 获取整个数据集的预测精度 print(acs.by_group) # 获取各个群体的预测精度 - 运行结果:

- 该模型的总体预测精度为0.8443,女性预测精度为0.925148,男性预测精度为0.804288,男性和女性的预测精度误差超过了0.1。
- 上述代码中,我们使用的评估方法为accuracy_score(预测精度)。
- 也可以使用其他的评估方法,如:recall_rate(回召率)、selection_rate(选择率)等。
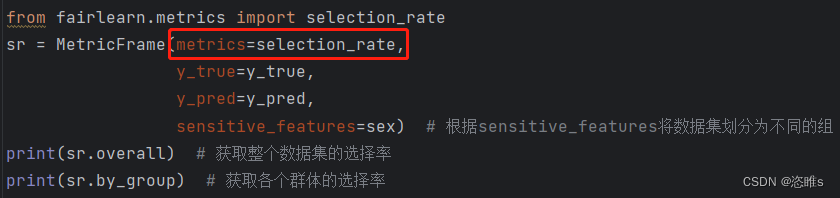
- 运行结果:

- 由此可见,男性群体和女性群体之间的选择率相差0.2以上。
3.3、绘制评估结果图
- 创建一个新的文件allBar.py。编写如下代码:
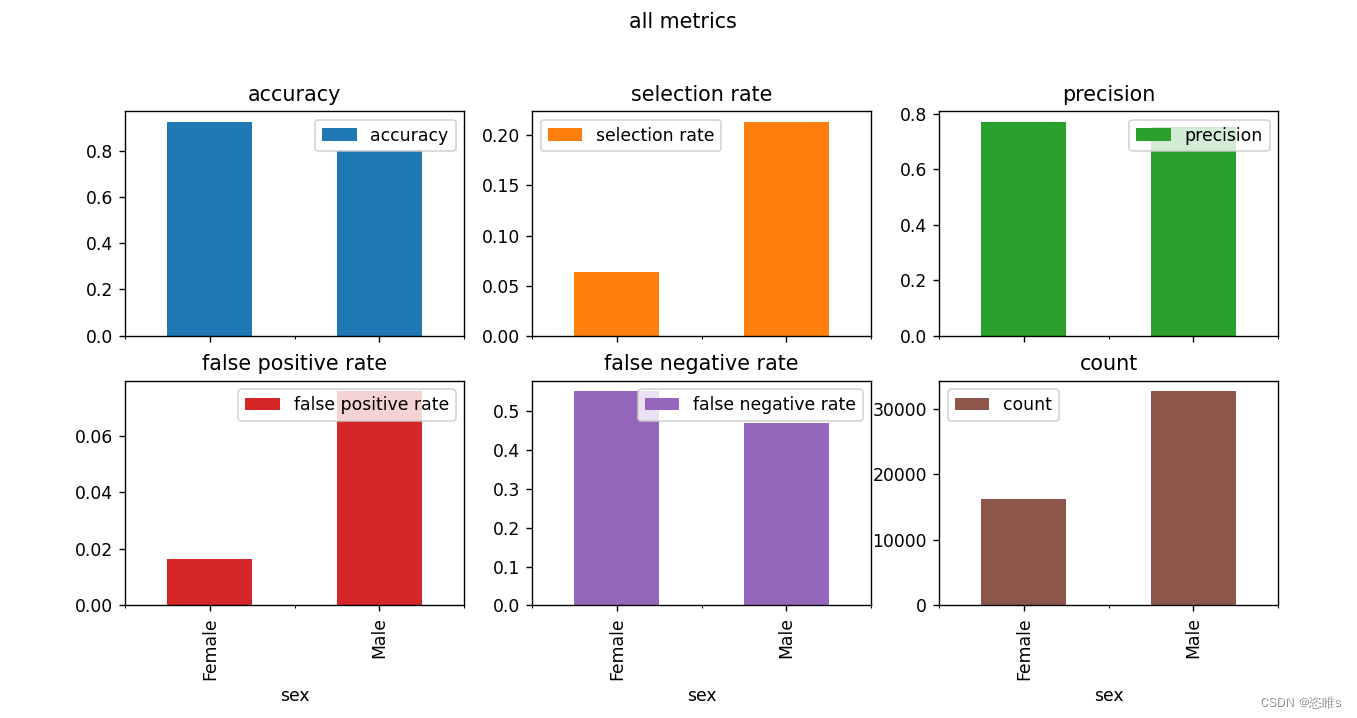
-
import matplotlib.pyplot as plt from fairlearn.metrics import MetricFrame from sklearn.metrics import accuracy_score from fairlearn.metrics import selection_rate from sklearn.metrics import precision_score from fairlearn.metrics import false_negative_rate from fairlearn.metrics import false_positive_rate from fairlearn.metrics import count # 引入之前的变量 from oldData import y_true, sex from oldFairness import y_pred metrics = { "accuracy": accuracy_score, # 精度 "selection rate": selection_rate, # 选择率 "precision": precision_score, # 真阳性/(真阳性+假阳性) "false positive rate": false_positive_rate, # 假阳性率 "false negative rate": false_negative_rate, # 假阴性率 "count": count # 统计各群体中样本的数量 } metric_frame = MetricFrame(metrics=metrics, y_true=y_true, y_pred=y_pred, sensitive_features=sex) metric_frame.by_group.plot.bar( subplots=True, layout=[3, 3], legend=True, figsize=[12, 8], title="all metrics" ) plt.show() # 强制显示图片 - 第一次运行报错,ImportError: matplotlib is required for plotting when the default backend "matplotlib" is selected,没有安装matplotlib。安装方法:
-
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple - 安装后运行依然没有图片显示,猜想是我的编译器的问题,解决方法:在pycharm中显示python画的图方法 - 编程之家 (jb51.cc)
- 但是我的pycharm中没有python science选项,原因是我使用的是PyCharm社区版(社区版没有可视化界面),卸载安装新的专业版。
- 重新运行,显示图片。
3.4、去偏
- 当我们发现模型存在偏见后,可以使用fairlearn中自带的去偏方法消除偏见。
- 例如,在上述的例子中,选择率与公平性高度相关,我们可以尝试使用相应的公平约束(人口平价)来缓解观察到的差异。使用的指数梯度缓解技术拟合以人口平价为目标的分类器,从而大大减少了选择率带来的偏见。
- 新建文件newFairness,编写如下代码:
-
import numpy as np from fairlearn.metrics import MetricFrame, selection_rate from fairlearn.reductions import ExponentiatedGradient, DemographicParity from sklearn.tree import DecisionTreeClassifier # 引入之前的变量 from oldData import x, y_true, sex # 训练模型 np.random.seed(0) # 设置随机数种子 constraint = DemographicParity() # 公平性约束为人口平价 classifier = DecisionTreeClassifier(min_samples_leaf=10, max_depth=4) mitigator = ExponentiatedGradient(classifier, constraint) # 指数梯度缓解技术 mitigator.fit(x, y_true, sensitive_features=sex) # 重新训练模型 # 评估模型 y_pred_mitigated = mitigator.predict(x) # 得到预测结果 sr_mitigated = MetricFrame( metrics=selection_rate, y_true=y_true, y_pred=y_pred_mitigated, sensitive_features=sex) # 根据 sensitive_features 将数据集划分为不同的组 print(sr_mitigated.overall) # 获取整个数据集的预测精度 print(sr_mitigated.by_group) # 获取各个群体的预测精度 - 运行结果:

- 由此可见,经过去偏后,男性群体和女性群体之间的选择率差异从0.2减到了0.02。


















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











