







1、过期Key处理
Redis性能强,主要的原因就是基于内存存储。然而单节点的Redis其内存大小不宜过大,会影响持久化或主从同步性能。
当内存使用达到上限时,就无法存储更多数据了。为了解决这个问题,Redis提供了一些策略实现内存回收:内存过期策略
可以通过expire命令给Redis的key设置TTL,当key的TTL到期以后,再次访问返回的是nil,说明这个key已经不存在了,对应的内存也得到释放。从而起到内存回收的目的。
Redis本身是一个典型的key-value内存存储数据库,因此所有的key、value都保存在Dict结构中。redisDb就是Redis中的一个个数据库,一共有16个,每个redisDb中
*dict是Dict结构,存放的是所有的key和value*expires是Dict结构,存放的是每一个key,对应的TTL时间,只有设置了TTL的key,才会在*expire中存在
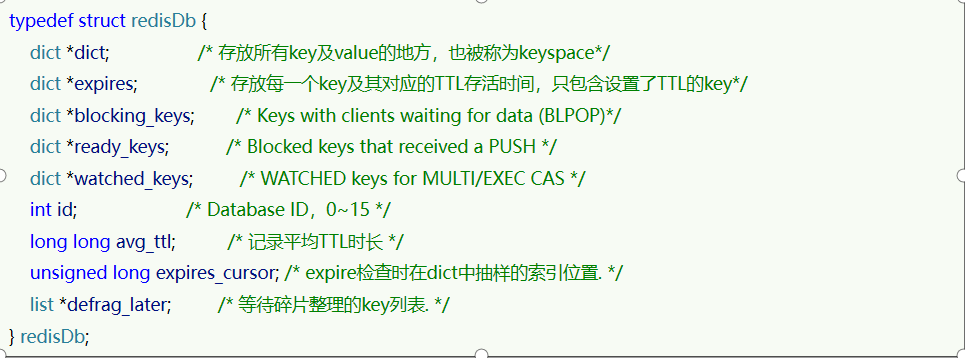
*dict是Dict结构,ht[0]存放的就是所有的key和value,不过这里的key和value都是redisObject,entry中存放的是key和value对应的redisObject的指针*expires是Dict结构,他的key存放的也是对应redisObject的指针,value存放的是这个key的过期时间,因此Redis就是通过这个过期时间判断key是否过期的
1.1 惰性删除
惰性删除是指并不是在TTL到期后就立刻删除,而是在访问一个key的时候,检查该key的存活时间,如果已经过期才执行删除。
从下边源码中可以看到,当Redis执行读或写操作时,首先会检查key是否过期,如果过期就先删除key

1.2 周期删除
周期删除是指通过一个定时任务,周期性的抽样部分过期的key,然后执行删除。
- Redis服务初始化函数
initServer()中设置定时任务,按照server.hz的频率来执行过期key清理,模式为SLOW- Redis的每个事件循环前会调用
beforeSleep()函数,执行过期key清理,模式为FAST
1.2.1 slow模式
-
initServer方法中,会创建定时器,关联回调函数serverCron,处理周期server.hz默认为10 -
serverCron方法中,会执行过期key的处理,然后返回1000/server.hz,默认是100,表示后边每100ms执行一次清理key的操作 -
databasesCron方法中,通过activeExpireCycle方法执行清理过期key的操作
1.2.2 fast模式
- 在每次调用
n = aeApiPoll()时,也就是执行epoll_wait操作之前,都会执行beforeSleep方法,这个方法内部,也会执行activeExpireCycle方法,不过此时是FAST模式

SLOW模式:
- 执行频率受
server.hz影响,默认为10,即每秒执行10次,每个执行周期100ms。 - 执行清理耗时不超过一次执行周期的25%,默认slow模式耗时不超过25ms
- 清理时,逐个遍历db,逐个遍历db中的bucket【即hash表中每个位置的链表】,抽取20个key判断是否过期
- 如果没达到时间上限(25ms)并且过期key比例大于10%,再进行一次抽样,否则结束
FAST模式规则
- 执行频率受
beforeSleep()调用频率影响,但两次FAST模式间隔不低于2ms - 执行清理耗时不超过1ms
- 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
- 如果没达到时间上限(1ms)并且过期key比例大于10%,再进行一次抽样,否则结束
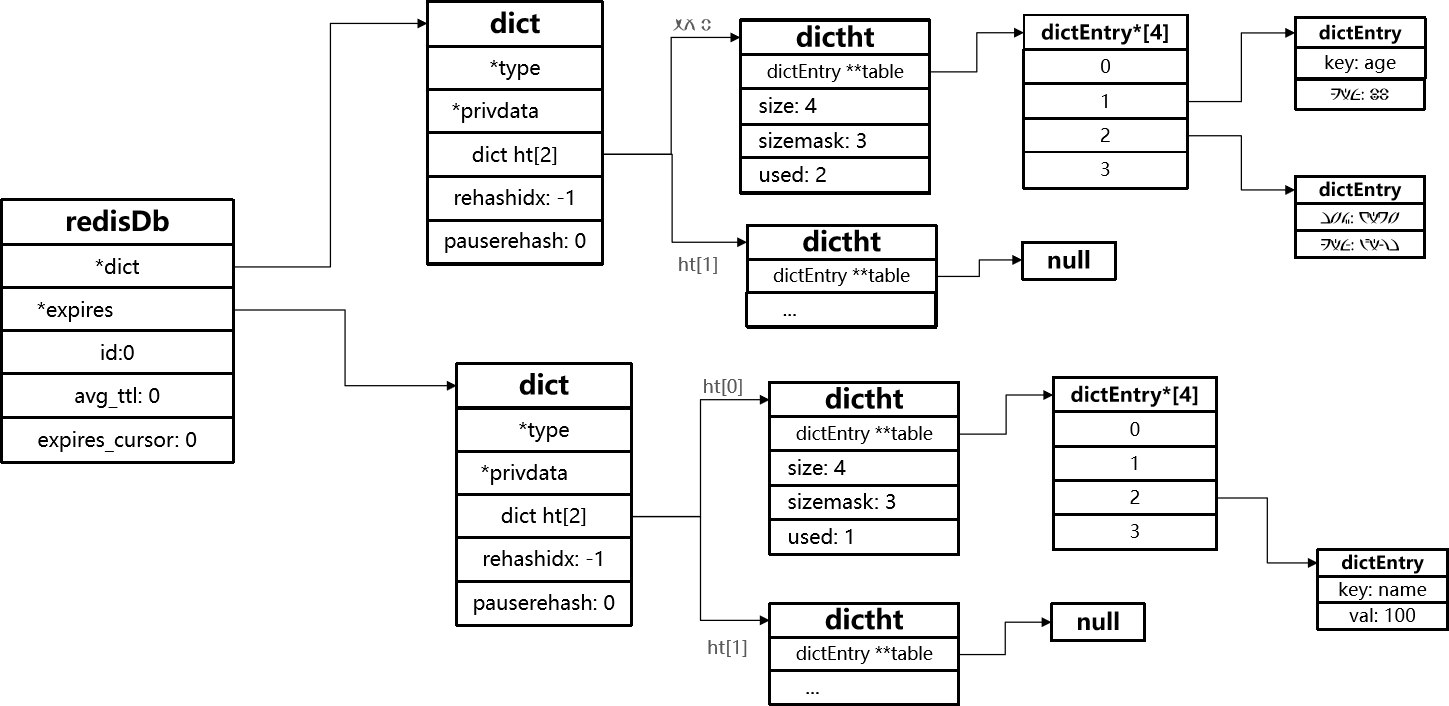
2、内存淘汰策略
就是当Redis内存使用达到设置的上限时,会主动挑选部分key进行删除以释放更多内存。
Redis会在处理客户端命令的方法processCommand()中尝试做内存淘汰
int out_of_memory = (performEvictions() == EVICT_FAIL) 这行代码首先通过performEvictions()执行内存淘汰,如果返回EVICT_FAIL说明内存淘汰失败,那么out_of_memory 就为1,后边就拒绝执行这条命令

淘汰策略
Redis支持8种不同策略来选择要删除的key
-
noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。 -
volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰 -
allkeys-random:对全体key ,随机进行淘汰。也就是直接从db->dict中随机挑选 -
volatile-random:对设置了TTL的key ,随机进行淘汰。也就是从db->expires中随机挑选。 -
allkeys-lru: 对全体key,基于LRU算法进行淘汰 -
volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰- LRU(Least Recently Used),最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
-
allkeys-lfu: 对全体key,基于LFU算法进行淘汰 -
volatile-lfu: 对设置了TTL的key,基于LFI算法进行淘汰- LFU(Least Frequently Used),最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
RedisObject中的lru字段,记录该对象最后一次被访问的时间,LFU也是复用的这个字段。
- 当使用LRU时,它保存的是上次访问的时间
- 使用LFU时,高16位以分钟为单位记录最近一次访问时间,低8位记录逻辑访问时间
LFU的访问次数称为逻辑访问次数,是因为并不是每次key被访问都计数,而是通过运算:
- 生成0~1之间的随机数R
- 计算
1 / (旧次数 * lfu_log_factor + 1),记录为P,lfu_log_factor默认为10 - 如果 R < P ,则计数器 + 1,且最大不超过255
- 访问次数会随时间衰减,距离上一次访问时间每隔
lfu_decay_time分钟【默认为1】,计数器 -1
typedef struct redisObject {
unsigned type:4; // 对象类型
unsigned encoding:4; // 编码类型
unsigned lru:LRU_BITS; /* LRU:以秒为单位记录最近一次访问时间,长度为24bit
* LFU:高16位以分钟为单位记录最近一次访问时间,低8位记录逻辑访问时间
*/
int refcount; // 引用计数,计数为0则可以回收
void *ptr; // 数据指针,指向真实数据
} robj;
执行流程
1、执行命令前先判断当前内存是否充足,如果充足就执行命令,然后退出,否则继续判断
2、判断当前策略是否是noeviction,即不淘汰任何key,如果是,那么直接退出,会报错,否则继续执行
3、判断当前是否是AllKeys模式,是的话就从db-dict中淘汰,否则从db->entries中淘汰
4、判断内存策略,如果是RANDOM,那么就随机选一个key删除,然后继续判断内存是否充足
5、如果是LRU、LFU、TTL的话,准备一个eviction_poll,从第一个数据库开始,随机挑选maxmemory_samples【默认为5】个key,基于不同的内存策略计算idleTime
TTL:idleTime = maxTTL - TTLLRU:idleTime = now - LRULFU:idleTime = 255 - LFU
6、判断这些key是否可以放入eviction_poll
- 如果
eviction_poll没满,就放进去 - 如果满了,就判断里边
idleTime最小的是否比当前要放进去的小,是的话,就将当前的key放进去,小的key出来,将eviction_poll中元素升序排序,然后继续遍历下一个数据库
7、取出eviction_poll中idleTime最大的key,将他删除,然后判断内存是否充足,充足的话就结束,否则继续删除















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









