







前言
循环神经网络(RNN)可以应用与时序问题中,例如在语言模型中,用户输入一句话,RNN就可以接着输下去,这可以看作是对用户输入的话之后要说什么的一种预测,那么用户所输入的话,是一个个有关联的字组成的。每个字的先后出现顺序都会决定这句话的意思,在这种问题下,我们可以用RNN来预测后面会输出什么样的话。
RNN思路分析
比方说,现在有一句话:“你好,世界”,这五个字(包括逗号)可以看作一个时序序列,我们RNN想要做一个什么事情呢,当用户输入“你”的时候,RNN可以输出“好”,同样的,当用户输入“好”的时候,RNN可以输出“,”,这是1-step的一种预测方式,也就是如下图所示这样的输出情况。

如果我们不考虑时序的问题,那么实际上就是一个字作为输入,一个字作为标签,那可以用最简单的MLP去实现这个预测模型,然而这就会忽略时序的问题。因为“你”和“好”之间是有关联的,因此当输入完“好”这个字的时候,输出的这个字符也需要考虑“你”的情况,单单用MLP的话,那就会失去时序信息,这就是RNN来解决的问题了,接下来给出一个RNN的模型。

在RNN中,加入了一个隐变量,这个隐变量不同于MLP中的隐藏层,这里的隐变量可以存储之前输入字符的信息,也就是当我们要输出下一个字符时,既要考虑当前字符,也要考虑存在隐变量中过往字符的信息。接下来简单讲一下图里的过程。
在刚开始的时候输入的值x0是“你”,对应的隐变量h0可以设为0,因为没有更往前的字符了,这里隐变量不需要存任何信息,输出O0也可以是空的。接下来要用x0的“你”来预测下一个字了,那么首先我们需要更新的是隐变量,隐变量需要存储的是过去的字信息以及当前你要预测的字的前一个字,这里隐变量h1就可以认为是要存储h0的信息以及x1“你”的信息,用公式可以这样表达h1=h0*Wh1h0+x0*Wh1x0+bh1。W就是权重,可以看到从h0到h1需要一个权重,从x0到h1也需要一个权重,他们的加权和加上偏移bh1就是h1的值了。那么这个h1实际上是存储了“你”之前的所有信息以及“你”的信息,接下来需要将隐变量h1映射到输出上,这里还是用一个权重和偏移来映射。即O1=h1*Wh1o1+bo1。这就是得到了我们的输出结果了。
再讲下一个,x1此时输入了一个“好”字,我们想得到输出这个字的后一个字,也就是输出O2。那么我们首先更新隐变量h2,这个h2应该包含h1的信息以及x1的信息,h1呢包含了”你“以及“你”之前的所有信息,也就是说h1包含了x1“好”字之前的所有信息了,再结合x1的这个“好”字,我们就可以更新h2了,用刚刚的加权和公式就可以获得,再通过一个加权和得到最终的输出O2,整体就是这样的一个流程。
我们来最后看一下推广后的公式:

这里沐神说的去掉隐藏状态间的更新,就回到了一个单层隐藏层的MLP了。
然后这里特别讲一下没有所谓的wh0h1哈,我只是想表达这个权重用在了隐藏状态0至隐藏状态1上,实际上整个RNN的参数只有5个whh,whx,bh,who,bo。
从零实现
接下来我们从零实现RNN,在实现过程中,我们来详细阐述中间的一些细节,RNN实际上就是一个应用于时间序列的模型,相比于简单的MLP,他用一个隐藏状态将过去时间的数据存储起来,让算法能够在得到当前的输入的前提下还能获得之前时间的数据,使模型能够综合考虑整个时间序列的所有信息得到最后的预测结果。
导包、导数据
%matplotlib inline
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
这里对变量挨个解释一下,首先介绍数据集,数据集其实就是一个txt格式的电子书,74页,30000+的单词书,170kb的大小,这里沐神将RNN运用在语言模型上,也就是通过前一句话预测后一句话吧,大概可以那么理解。
加载这本电子书要传2个变量,先看第二个num_steps,代表RNN输入的一条数据是多长,比如前面的例子中,“你好,世界”,那就是输入5个字,那么num_steps=5,这里的模型取值是35,相当于输入35个字符/单词。还有一个batch_size这个和之前的一样,每次训练传几句话嘛就是,每句话都是35个字符/单词。
通过这个加载电子书的函数可以得到两个变量,第一个变量就是个迭代器,迭代出来32个长度为35的句子,第二个vocab,就是vocabulary,字典,因为一个30000多单词的电子书,一定有很多个不同单词组成,这里通过代码看一下:
tokens = d2l.tokenize(d2l.read_time_machine())
# print(tokens,len(tokens),type(tokens))
# 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]
# print(corpus,len(corpus),type(corpus))
vocab = d2l.Vocab(corpus)
print("行数:",len(tokens))
print("总词元数:",len(corpus))
print("字典长度:",len(vocab))
print("字典中出现最频繁的十个词元:",vocab.token_freqs[:10])
print("字典前十个词元:",list(vocab.token_to_idx.items())[:10])
行数: 3221
总词元数: 32775
字典长度: 4580
字典中出现最频繁的十个词元: [('the', 2261), ('i', 1267), ('and', 1245), ('of', 1155), ('a', 816), ('to', 695), ('was', 552), ('in', 541), ('that', 443), ('my', 440)]
字典前十个词元: [('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4), ('a', 5), ('to', 6), ('was', 7), ('in', 8), ('that', 9)]
这里解释一下里面的变量,token是词元,这个词元是组成文本的基本单位,一个文档可以是一堆单词组成的,也可以说是26个英文字母组成的,这里默认情况下,词元是单词,tokens就是每一行文字中有多少词元,这里也就是每行有多少单词,corpus就是将这个文档每一行都首尾相接,整个文档有多少词元。从代码结果可以看出,这篇文档有3221行,总共有32775个单词组成,那么这32775个单词有不重复的单词4580个,这就是字典所做的工作,将4580个不重复的词元赋予编号,接下来看字典中出现频率最高的10个单词,以及字典编号前10个词元,这里是语料库中不存在或已删除的任何词元。
接下来回到RNN模型,这里我们词元的单位并不是单词,因为单词太多了,4580个,因此我们用字母作为单位,那么字典的长度其实是28,他们分别是26个英文字母以及和空字符串,具体看下面:
词元编号: [('<unk>', 0), (' ', 1), ('e', 2), ('t', 3), ('a', 4), ('i', 5), ('n', 6), ('o', 7), ('s', 8), ('h', 9), ('r', 10), ('d', 11), ('l', 12), ('m', 13), ('u', 14), ('c', 15), ('f', 16), ('w', 17), ('g', 18), ('y', 19), ('p', 20), ('b', 21), ('v', 22), ('k', 23), ('x', 24), ('z', 25), ('j', 26), ('q', 27)]
词元频率: [(' ', 29927), ('e', 17838), ('t', 13515), ('a', 11704), ('i', 10138), ('n', 9917), ('o', 9758), ('s', 8486), ('h', 8257), ('r', 7674), ('d', 6337), ('l', 6146), ('m', 4043), ('u', 3805), ('c', 3424), ('f', 3354), ('w', 3225), ('g', 3075), ('y', 2679), ('p', 2427), ('b', 1897), ('v', 1295), ('k', 1087), ('x', 236), ('z', 144), ('j', 97), ('q', 95)]
为什么要那么做呢,原来我们输入的可能是字母,现在输入的就是数字了,数字更容易被算法接受。
独热编码
我们在之前线性回归等例子里面讲过独热编码(one-hot),当时说我们的线性回归传入的都是数据,如果碰到传入的是字符串该怎么办,那么我们可以用独热编码将字符串转变成数字的办法解决,例如有个变量v,它的值只有True 和False,那么我们可以用两个变量a和b来代表这个v,当v=True时,a=1,b=0;当v=false时,a=0,b=1。基本上就是这样的思路,那么我们这里有个长度为28的字典,我们就可以用独热编码解决,原来一个输入是某个字母在vocab字典里对应的数字,独热编码后,这个输入就变成28个数字了,这28个数字,1个是1,其他都是0,为什么要那么做呢,我这里说一下我的理解,神经网络其实更希望有一些向量化的输入,这里1个1,27个0,代入神经网络肯定比一个具体的数更好,在做参数更新也有优势,在梯度下降过程中可能也更好收敛,比如原来一个数是18,这个18经过神经网络后的输出可能是个很奇怪的数字。
沐神是那么说的:每个词元都表示为一个数字索引, 将这些索引直接输入神经网络可能会使学习变得困难。 我们通常将每个词元表示为更具表现力的特征向量。
代码很简单,这一句话就行,这句话输出0和2的独热编码结果。独热编码的长度是len(vocab)=28。
F.one_hot(torch.tensor([0, 2]), len(vocab))
上面读取电子书那个函数可以返回一个train_iter的变量,这个变量就是RNN一次迭代的输入,这个输入的格式是一个二维矩阵(批量大小,时间步数),在我们讲的这个RNN模型中就是(3235)。
假如我们输入的是一个(25)的矩阵,也就是2条长度为5的语句,那么通过独热编码会变成如下:
X = torch.arange(10).reshape((2, 5))
F.one_hot(X.T, 28).shape
torch.Size([5, 2, 28])
为什么要转置,沐神说:我们经常转换输入的维度,以便获得形状为 (时间步数,批量大小,词表大小)的输出。 这将使我们能够更方便地通过最外层的维度, 一步一步地更新小批量数据的隐状态。
我说:比如这里他一句话是5个字符吧,我们的RNN模型实际上也是想输出同样长度的5个字符,这5个字符不是一下就能输出来的,输入一个字符,输出一个字符,最后拼接输出的字符成为完整的一句话吧,那么实际上代码内部可能是用了一种遍历的方法来挨个字的输出结果吧,那你当然要把5这个时间步数也就是一句话的字数放在最外层才好遍历吧,我是这样理解的,看接下来的代码应该能理解。
初始化模型参数
整个RNN有哪些模型参数,我们可以回到RNN思路分析中查看,就是权重和偏移了,接下来详细讲讲这些参数:
讲之前先要讲一下模型的输入维度,输出维度,隐藏状态维度:
输入维度是做过独热编码之后的,就是(时间步数,批量大小,词表大小),输出维度应该和输入维度一样,这样才能通过vocab查到输出的具体是哪个字母,接下来是隐藏状态:(时间步数,批量大小,隐藏状态单元数),隐藏状态单元数命名为num_hidden,这是一个超参数,相当于MLP中隐藏层神经元个数,也是个超参数吧,这里类似。
那么这个模型的参数如下:
W_xh:输入至下一个隐藏状态的权重
W_hh:当前隐藏状态到下一个隐藏状态的权重
b_h:更新下一个隐藏权重产生的偏置
W_xh和输入x点乘再加上W_hh和上个隐藏状态点乘再加上偏置,就得到了下一个隐藏状态值了。
W_hq:下一个隐藏状态值到输出的权重
b_q:下一个隐藏状态到输出产生的偏差
下一个隐藏状态到输出的映射就这样完成了,这个输出也就是下一个字母的预测结果吧
至于每个权重和偏移为什么是如下的维度,这个根据上面写的输入输出隐藏状态维度,也能推出的吧,输入维度:(时间步数,批量大小,词表大小),隐藏状态维度:(时间步数,批量大小,隐藏状态单元数),所有输入到下一个隐藏状态的权重W_xh维度(词表大小,隐藏状态单元数)。
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device) * 0.01
# 隐藏层参数
W_xh = normal((num_inputs, num_hiddens))
W_hh = normal((num_hiddens, num_hiddens))
b_h = torch.zeros(num_hiddens, device=device)
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
RNN定义
隐状态初始值
比如上面“你好,世界”那个例子,h0那个隐藏状态初始是没有意义的吧,因为前面没有任何信息,为了整个参数更新流畅,我们也给他一个值就是全0吧。
def init_rnn_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
RNN模型定义
这就是RNN的模型了,看这里就用到了循环遍历,用时间步来作为循环变量,循环遍历得到每次预测的字符,然后拼起来。这里使用了tanh激活函数,可以有效的控制隐藏状态的范围,便于梯度下降。
def rnn(inputs, state, params):
# inputs的形状:(时间步数量,批量大小,词表大小)
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
# X的形状:(批量大小,词表大小)
for X in inputs:
H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)
Y = torch.mm(H, W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
rnn模型最后输出的数据格式是(批量大小*时间步数量,词表大小),是将遍历得到的每个结果以第一维度上下拼接。
RNN类包装
这里简单讲一下__init__和__call__的区别,当我们实例化一个类的时候,会调用__init__,会把实例化调用函数时候输入进来的参数传给__init__。接下来当开始使用这个实例化的类的时候,就会调用__call__这个类,比如model=RNNModelScratch(1,2,3,4,5,6),这里就把1,2,3,4,5,6送进__init__函数里了,接下来model(X,state),就相当于把X,state传入__call__函数里面。我们一会详细说这个调用过程。
class RNNModelScratch: #@save
"""从零开始实现的循环神经网络模型"""
def __init__(self, vocab_size, num_hiddens, device,
get_params, init_state, forward_fn):
self.vocab_size, self.num_hiddens = vocab_size, num_hiddens
self.params = get_params(vocab_size, num_hiddens, device)
self.init_state, self.forward_fn = init_state, forward_fn
def __call__(self, X, state):
X = F.one_hot(X.T, self.vocab_size).type(torch.float32)
return self.forward_fn(X, state, self.params)
def begin_state(self, batch_size, device):
return self.init_state(batch_size, self.num_hiddens, device)
验证RNN类的输出
这里我们调用一下RNN类,顺便看一下代码内是怎么运转的。
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
init_rnn_state, rnn)
# print(net.params,len(net.params))
state = net.begin_state(X.shape[0], d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state)
Y.shape, new_state[0].shape
result:(torch.Size([10, 28]), torch.Size([2, 512]))
首先是实例化RNNModelScratch类,取名叫net,即调用该类中的构造函数__init__,将参数代入类中。self.vocab_size=len(vocab)=28;
self.num_hiddens=num_hiddens=512;
device=d2l.try_gpu;
self.params=get_params(28,512,d2l.try_gpu);
self.init_state=init_rnn_state;
self.forward_fn=rnn。
这句话self.params=get_params(28,512,d2l.try_gpu);使得实例化的net得到了权重偏移那些参数了,可以回看get_params这个函数,这个函数其实就是初始化这些参数,使得每个参数的均值等于0,方差为0.01。parma的形状:W_xh(28,512), W_hh(512,512), b_h(1 ,512), W_hq(512,28), b_q(1,28)。
接下来执行这行代码:state = net.begin_state(X.shape[0], d2l.try_gpu())
这行将会调用类中的begin_state方法,方法中的batch_size=X.shape[0]=2。接下来类中方法再调用self.init_state方法,即调用init_rnn_state(2,512,d2l.try_gpu),于是state得到2行512列全0矩阵。
接下来执行Y, new_state = net(X.to(d2l.try_gpu()), state),这句话相当于给net传参数,那么这就相当于调用类中的__call__方法了,call中的X接收到了X.to(d2l.try_gpu()),也就是X接收到了一个在gpu上的(2,5)的矩阵。接下来call这个函数就是做了个独热编码的操作,X就变成了(5,2,28)的形状了。
下一句:return self.forward_fn(X, state, self.params),因为self.forwrd_fn=rnn了,所以这行代码就相当于rnn(X,state,params)。到此开始运行rnn模型,rnn的三个参数,上面都已经介绍了,根据rnn函数的运算规则,得到的形状应该是(批量大小*时间步数量,词表大小)即(2 * 5,28),另一个输出H还是全0的state,维度也没有变化。
结果亦是如此,验证成功。
预测
这里先定义了预测函数。
def predict_ch8(prefix, num_preds, net, vocab, device): #@save
"""在prefix后面生成新字符"""
state = net.begin_state(batch_size=1, device=device) #1*512 0
outputs = [vocab[prefix[0]]]#t-3
get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1)) #[[3]]
for y in prefix[1:]: # 预热期 ime traveller
_, state = net(get_input(), state)
outputs.append(vocab[y])
for _ in range(num_preds): # 预测num_preds步
y, state = net(get_input(), state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])
predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu())
预测函数呢分为一个预热期和预测期,这个预热期仅仅是为了更新隐状态的,其实很好理解为什么要那么做,我们现在要预测time traveller 之后10个字符的内容,我们肯定是希望我们在预测的时候,state这个隐状态已经存储了time traveller 的所有信息了,再去预测后面的字符吧,我们肯定不希望我们拿个time traveller 最后的那个空格开始往后预测10个字符吧,那这样的结果肯定是不好的,因为你预测的第一个字符要作为你预测第二个字符的输入,对第二个字符的预测用到的隐状态存储的第一个字符信息甚至是错误的,那不就恶性循环了,错误的输入预测错误的输出。说了那么多,这个预热期没有什么太不好理解的,就是希望隐状态能够存住足够多的上文信息,才能更好预测下文。
代码逻辑其实写的挺好的,我这边解释一下,可以选择性的看:
整个predict_ch8要传入的参数分别是:要预测的前一句话,预测后面多少字符,训练好的网络,字典,硬件。
隐状态state首先初始化一个1 * 512 全0的矩阵
输出outputs首先初始是’time traveller ‘中的字符‘t’,并且用字典将它转成数值,大概是个3,上面查字典看
输入get_input是输出outputs的最后一个数,每次输入的都是输出中的最后一个字,这里的get_input=3
上面是给这个预测函数中的各变量初始化一下,接下来开始预热:
循环遍历除去第一个字符的所有字符,也就是‘ime traveller ’
_, state = net(get_input(), state),因为net会输出一个输出值和一个隐状态值,因为我们现在要将time traveller 放入net里面,目的只是希望跑完所有字符后,state能够存住time traveller 的所有信息,也就是说我们不关心net给的输出是什么,因为输出的标准答案我们是有的。time traveller 的输出就是ime traveller 。
如果初始的隐状态称为h0的话,那么这里更新后的隐状态h1就是通过x0和wx0h1的点乘得到的,因为h0是全0啊,他和他的权重点乘也没用,那么这里我们就更新得到了h1。
outputs.append(vocab[y]),接下来这句话将ime traveller 中的i,先转变成数值再送入outputs,这样下次循环new_inputs的值就变成i对应的数值了,接下来就是以此类推了,我们可以得到h2的隐状态,这个h2隐状态包含了h1和x1的信息,以此类推,我们最终可以通过这一个for循环得到一个state,一个包含了‘time traveller’的隐状态state,注意我这里最后没打空格哦!空格将作为后面正式预测的第一个输入字符。但我们的state足够强大,包含了time traveller。因此我们的下一个预测应该会有相对好的结果。
接下来一个循环就是正式的预测了,正式的预测将首先用“ ”来作为输入,预热得到的state作为初始隐状态。然后循环10次得到“ ”后的十个字符。
for _ in range(num_preds): # 预测num_preds步
y, state = net(get_input(), state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
我们仔细讲一下这个循环,第一次循环y可以得到" "作为输入的输出,以及一个包含"time traveller "的隐状态,然后第一次循环的这个输出y,了解了前面的RNN流程应该可以知道,其实这个y的输出应该是一个1*28的矩阵吧,因为我们刚开始用了一个独热编码嘛,那么这个输出其实也可以看作一个独热编码,我们找到这28个独热编码中的最大值对应的下标,然后把这个找到的下标加入进outputs里,我们每次循环都会输出一个下标,就是一个整型哈,把他们依次加入outputs就出来了“time traveller ”后的十个数字了。最后把这十个数字再用一次循环,用vocab将字典中对应的字符找出来,拼出来就是“time traveller ”后的十个字符了
这里注意一下,我们的第二次循环,输入的应该是第一次循环的输出结果,也就是输入的应该是“ ”的预测字符吧,这个之前代码都解释到了。
predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu())
result:'time traveller zgaseytirg'
这个预测结果肯定是不好的,因为我们的权重和偏移这些参数用的是初始值,我们没有用训练数据去更新这些参数,因此现在的结果就是完全基于初始权重和偏移决定的。
单次epoch训练
这里先封装一个单次epoch训练的函数,再写一个训练整体样本集的函数,让这个函数调用单次epoch函数。
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):
"""训练网络一个迭代周期(定义见第8章)"""
state, timer = None, d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失之和,词元数量
for X, Y in train_iter: #X 32*35 Y 32*35
if state is None or use_random_iter:
# 在第一次迭代或使用随机抽样时初始化state
state = net.begin_state(batch_size=X.shape[0], device=device)
else:
if isinstance(net, nn.Module) and not isinstance(state, tuple):
# state对于nn.GRU是个张量
state.detach_()
else:
# state对于nn.LSTM或对于我们从零开始实现的模型是个张量
for s in state:
s.detach_()
y = Y.T.reshape(-1)
X, y = X.to(device), y.to(device)
y_hat, state = net(X, state)
print(y_hat.shape,y.long().shape)
l = loss(y_hat, y.long()).mean()
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad()
l.backward()
grad_clipping(net, 1)
updater.step()
else:
l.backward()
grad_clipping(net, 1)
# 因为已经调用了mean函数
updater(batch_size=1)
metric.add(l * y.numel(), y.numel())
print(metric[0],metric[1])
return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
首先是通过train_iter每次获得的X和Y都是32个长度为35的字符串。train_iter是通过d2l.load_data_time_machine(batch_size, num_steps),这个加载电子书的方法是沐神写的,这个函数还有两个参数用的是默认值,分别是use_random_iter=False, max_tokens=10000,因为max_token限制在了10000,每一次迭代总共获取32 * 35=1120个字符,因此总共会有8次迭代,也就是train_iter会有8次循环。
因为这里用的是默认的使用顺序采样,顺序采样就是某一批次读取的第i个样本和下一批次读取的第i个样本,他们是连续的,随机采样就是不连续的。
在第一次迭代过程中,刚开始我们的state应该是要用初始化的隐状态,因此会先调用net.begin_state这个函数,那么当我们第二次迭代的时候,因为我们这里用的是顺序采样,因此第二次迭代的初始隐状态应该用第一次用下来的隐状态,而且第二次迭代我们只需要它的隐状态的值,不需要携带着的梯度信息,因此用一个detach分离出来,相当于第二次迭代用到的隐状态仅仅就是第一次迭代最后的隐状态值,梯度为0,第二次迭代的时候,我们重新去计算梯度,做梯度下降。这里用的是最简单RNN,所以每个时间步的隐状态只有一个,而后面的LSTM等模型,隐状态不止一个,因此它代码里面写了一个循环分离。那么当使用的不是顺序采样,而是随机采样的时候,每次迭代刚开始的时候,隐状态都应该是初始值,因为不知道前面字符串是什么,没有记录。
接下来y = Y.T.reshape(-1) ,是将原来的Y(32 * 35)变成(35 * 32),看前面的介绍应该知道,因为我们在对X做独热编码的时候,会将X转置,将时间步数量放在最外层方便循环,那么这里为了让y与RNN(X)得到的y_hat的形状匹配,因此对y也做了转置。因为用GPU训练,所以数据存放在device里。
y_hat, state = net(X, state),我们回想一下rnn那个模型,它用时间步作为循环变量,每个时间步经过RNN都可以或者(3228)的矩阵,32是批量,28是独热编码后的特征。最后用一个上下拼接的方法变成了(3532,28)的形状,并且记录了这一次迭代最后的state值,方便后面顺序采样下后续迭代使用。
l = loss(y_hat, y.long()).mean(),这里用了一个损失函数,这个损失函数用的是交叉熵损失函数,在分类问题中,交叉熵损失函数用的还是挺多的,而且神经网络的应用很大一部分都是分类问题,因此这里将交叉熵损失函数再细致的讲一下。之所以想再回忆这段知识是因为我看到这里的时候有个疑问,y_hat的形状是(35*32,28)=》(1120,28),y的形状是(35,32),通过y.long()变成了(1120),他们形状完全不匹配,如何做损失,那可能是回归问题看多了,以为损失函数都是均方差损失函数,均方差确实需要两边形状一样,对应的y与y_hat求差的平方,实则不然。虽然y_hat是(1120,28)但是每行的这28个数实际上是一种概率,我们最终其实是选择这28个数中最大的一个数的下标作为每行的结果。所以它其实也是(1120)的形状,简单来说就是选28个数的最大值的下标,但其实交叉熵损失函数会首先用一个softmax方法来对28个数字做处理,因为这28个数经过RNN的模型会变得千奇百怪,而我们其实更希望这28个数形成一种概率,这样就能变成选取一个概率最大的数。假如这28个数字叫xi,那么softmat(xi)=exi/(所有exi求和),softmax之后,他们就变成了概率,而且ex的函数是一个递增的函数,在x=0后极速递增,那也准确的表达了这28个数中越大的数被选择的概率也越大。现在28个数都有一个概率了,然后去对应真实的y值是多少,比如y值是3,那我们就去找数组下标是3的那个数,然后看它的概率,这就是我们RNN模型预测y=3的概率了吧,那么这个概率值还不能作为损失值,我们需要将这个概率求对数并且求反,也就是loss=-ln(p),假设这个p是刚刚得到的概率,因为-ln§的函数在p(0,1)的区间是极速递减的,p=0时,loss正无穷,p=1时,loss=0,那么很合理了,选定这个值的概率是100%,损失为0,概率越小,损失越大。这样就可以得到1120个字符的损失了。然后求这1120个损失的均值。
接下来是梯度更新了,后面if语句是判断用的是沐神写的优化方法还是pytorch自带的优化方法,这里用的是沐神写的用else里的语句。
l.backward(),就是求梯度了,这里我们要更新的是参数是3个权重和2个偏移,所以主要就是想获得这五个参数的梯度,他们的梯度要通过对损失函数链式求导,因为loss函数只关乎一个输出y_hat和真实y值,所以要链式求导逐一找依赖关系来获得五个参数的梯度,从而用sgd的优化方法更新。
这里由于链式求导以及时间步数长的问题,会产生梯度爆炸,这里我直接展示沐神对产生的原因的描述。https://zh.d2l.ai/chapter_recurrent-neural-networks/bptt.html



产生梯度爆炸的解决方式是梯度裁剪。
def grad_clipping(net, theta): #@save
"""裁剪梯度"""
if isinstance(net, nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
解释一下这里的方法,每次迭代获得五个参数,每个参数的形状不同,每个参数的梯度的形状和参数的形状是一样的。对每个参数内的所有梯度值求一个平方和,然后把五个参数各自的平方和相加求和,最后对这个求和值开根号,得到一个norm值。如果这个norm值大于给的超参数θ,那么说明这五个参数算是产生了梯度爆炸的现象。
这个时候需要把每个参数里面的梯度都乘上(θ/norm),目的就是让梯度的绝对值小一些,不要过大。norm值小于θ,那梯度不用裁剪。
grad_clipping(net, 1),在单次epoch训练的函数里,执行这句话就是当θ取1时,做梯度裁剪。
updater.step(),这个就是梯度更新了。这里updater会用sgd方法,sgd也就是梯度下降的方法。
具体来说,就是更新后的参数=旧的参数-(学习率 * 梯度)。这里说一下我的一些想法。
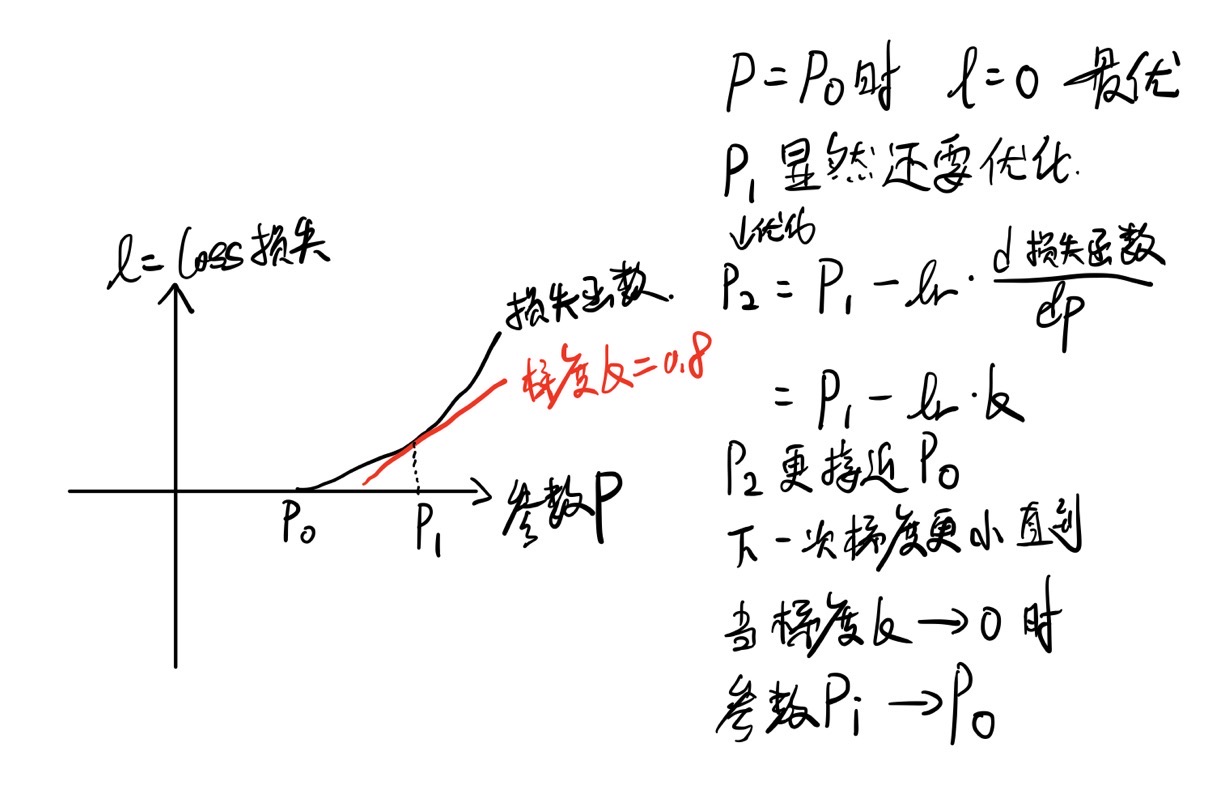
我们知道损失函数是一个关于真实y值和预测y值的函数,这个预测y值依赖于五个参数值,所以总的来说,损失函数可以由五个参数值决定,那么我们说一种理想化的情况,损失值和参数的关系见左上图,p0就是使得损失为0的最优参数值,也是我们希望得到的参数值,假如我们初始的参数值是p1,那么我们通过求梯度,可以得到损失函数在p1处的梯度为0.8,这个0.8表示了最优参数距离现在这个参数的方向。我们用这个公式:更新后的参数=旧的参数-(学习率 * 梯度),得到p2=p1-lr * 0.8,这个p2会更接近最优参数,我们循环这一过程,直至梯度趋近0,梯度=0,就相当于我们图上那根红线和x轴平行了吧,就算是找到了最优解,或者说局部最优解。那么当我们陷入局部最优解的情况,我认为因为我们用了多批数据,每批数据的损失函数其实都是有所不同的,在前n批数据中,损失值无法下降,参数可能一直在一个局部最优解附件,那么当n+1这批数据训练的时候,发现这个参数并不在它这批损失函数的最优解,那它就可以通过梯度下降来更新参数,这个更新后的参数,如果被第n+2批数据也认可是较优的解,那就说明打破了这个瓶颈吧,如果第n+2批数据不认可,可能梯度要变负的了,然后参数又回到了第n批数据的情况,反正那么多批数据,要是最终损失值和参数值就是陷入了最优解,那更换一些超参数值吧,或者换优化方法,基本上在大批数据的情况下,损失值还是能降下来的,大不了过拟合哈哈。
metric.add(l * y.numel(), y.numel())
这句话用metric记录了两个数据,第一个数据是平均损失值 * y中内含的字符数量=总损失值,第二个数据就是 y中的字符数量。
return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
这个单次epoch的训练函数最终返回两个数据,一个是perplex困惑度,是一种评价预测好坏的标准。我们看一下这个公式:e平均损失。原来我们都是用损失值来作为标准的吧,这里因为是一个分类问题,每个预测字符都有28种可选的选项,前面说过损失值用的是交叉熵损失函数,公式是-ln(p),当选择某个字符的概率是100%的时候,损失值就是0,概率越小,损失越大,这个还不够形象,我们对这个损失值求个指数,发现当概率是100%的时候,这个困惑度啊e0=1了,什么意思呢,这是我RNN对于这个预测结果只有一个可选项吗,只有1个可选择答案了,哎呀我不困惑了,那么如果概率是0.5,损失是0.69,那么困惑度就是1.99,有1.99个可选项,有一点困惑,概率是0.2呢,损失是1.6,困惑度是4.95,哎呀头大了!这就是困惑度这个指标的好处。
训练函数
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,
use_random_iter=False):
"""训练模型(定义见第8章)"""
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
# 初始化
if isinstance(net, nn.Module):
updater = torch.optim.SGD(net.parameters(), lr)
else:
updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)
predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)
# 训练和预测
for epoch in range(num_epochs):
print("epoch:",epoch)
ppl, speed = train_epoch_ch8(
net, train_iter, loss, updater, device, use_random_iter)
if (epoch + 1) % 10 == 0:
print(predict('time traveller'))
animator.add(epoch + 1, [ppl])
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
print(predict('time traveller'))
print(predict('traveller'))
到了这里就轻松了,定义损失函数为交叉熵损失函数,定义一个做图工具,如果优化器用的是nn包自带的,那就直接调sgd,这里用的是d2l的就用沐沐的。然后定义一个predict方法,这个方法用的是前面写的predict函数。接下来按epoch来训练,每十次报一下’time traveller’的预测结果,这里预测的是未来50步,50个字符,'time traveller’作为参数值传入prefix,prefix传入那个预测函数。顺便每十次报一下困惑度。最终答应500次迭代后的预测结果。完事。
最后的训练与预测
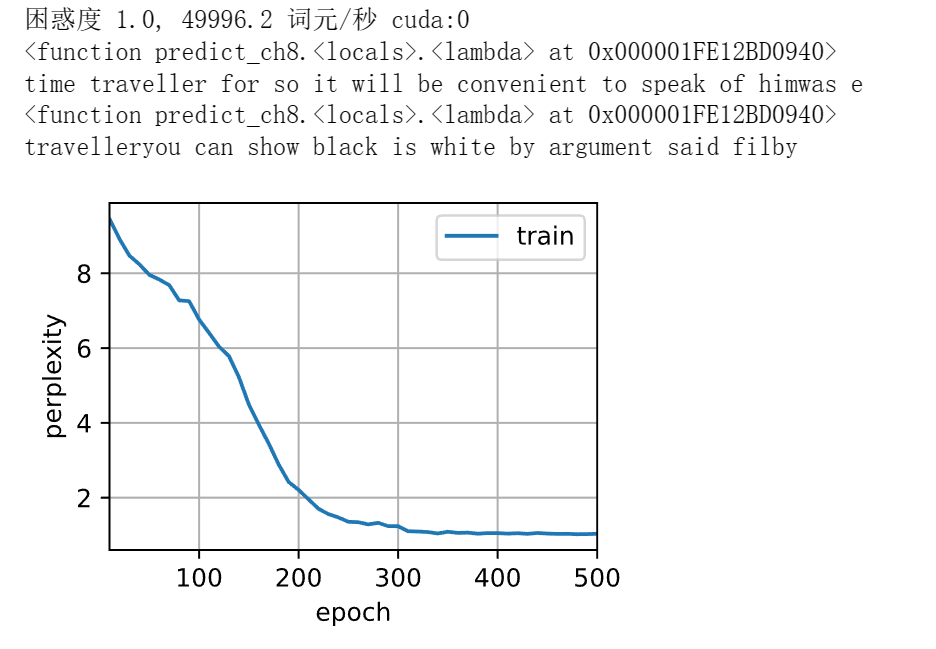
num_epochs, lr = 500, 1
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())
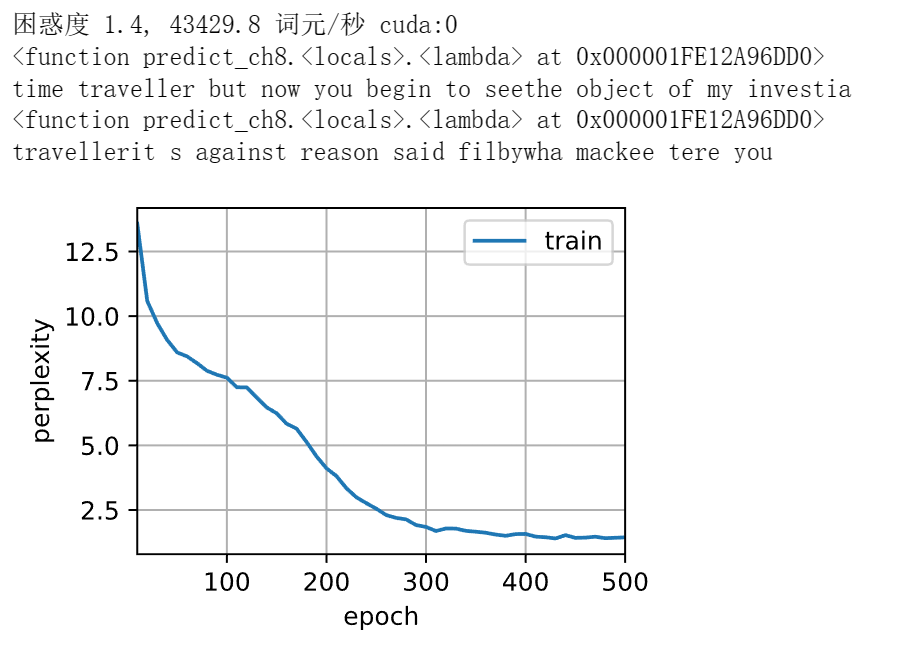
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
init_rnn_state, rnn)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),
use_random_iter=True)
总结
这篇文章对于前面学习的深度学习内容做了总结,很多过去内容的细节都详细的说了一下,算是对自己的知识做了一次回顾与补充。由于自己才疏学浅,相信有很多内容说的会有错误和不足,欢迎看到的小伙伴们补充与指正。















 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









