







前言
我们在前面的博客中介绍了三种卷积神经网络:LeNet、AlexNet、VGG。
LeNet:两层(卷积+平均池化)+降维至MLP+softmax
AlexNet:两层(卷积+最大池化)+三层卷积+一层最大池化+降维至MLP+softmax
VGG:多个块叠加使用+降维至MLP+softmax,其中块的结构:一个或多个3*3的卷积+一个最大池化层
VGG无疑是其中表现最好的,然而它是用复杂度换来的,他们这三个模型的共同点是都在最后使用了MLP,我们来看一下这三个模型的复杂度,用卷积层后的第一个全连接层的参数表示复杂度:
LeNet:16 * 5 * 5 * 120 = 48k,这里简单解释一下,16是卷积的最后输出通道数,可以认为是卷积神经网络(不带后面MLP的)输出层的神经元个数,然而这个神经元是二维的,通过卷积以及池化的操作,每一个神经元的大小变成了5 * 5,如果要将他们降维成一维的话(此时一块二向箔的弟弟一向箔路过),那就会得到16 * 5 * 5的一维神经元,这将作为后面MLP的输入神经元,再看MLP的第一个隐藏层,神经元个数是120,因为输入层和隐藏层要全连接,因此就会有16 * 5 * 5 * 120那么多个权重了,这个复杂度可想而知。

AlexNet:256 * 5 * 5 * 4096=26M

VGG:51277*4096=102M

可以看到VGG虽然效果是最好的,但是它MLP中第一层的权重个数直接达到一个亿,这种计算所需时间可想而知,因此我们希望能够优化一下MLP模型降低一些模型复杂度,在2013年,NIN就由此诞生了。但这个模型实际上放到现在用的不多,但是它提出了一个1*1的卷积核思想还是有一定奠基作用的。
简介
上一章讲述了NIN的诞生原因,本文来讲一下NIN是如何解决MLP带来的高复杂度问题的。NIN提出了一种想法,就是直接舍弃MLP,在卷积中实现MLP的功能,MLP实际上就是想通过与权重相乘,来拟合最终的一个结果,那么卷积也可以做与权重相乘的操作,如何实现,就要提到刚刚说提的11卷积核了,将一个二维矩阵和一个11卷积核作互相关运算,不就实现了这一操作,通过一个图直观感受一下,我是感觉没用之前全连接那么可靠,但是全连接太费时费力费钱了,牺牲一点得到一点吧。
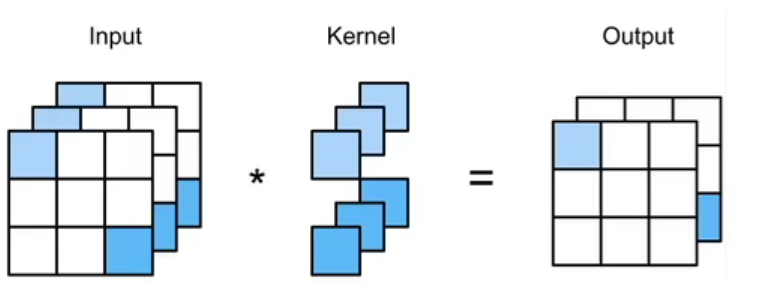
我们之前说卷积层中的互相关运算,就是把输入层的多个二维矩阵与多个卷积核作一个先乘后求和的操作对吧,之前我们也讲过,它就是个以二维矩阵为神经元的MLP神经网络罢了,图中实际上就是输入层是3个二维神经元,想输出2个二维神经元,我们忽略步幅填充那些操作,那么就需要两组权重来实现输入层到输出层的操作,之前卷积核是22及以上的时候,这样的互相关运算其实是一个学习图像特征的过程,那么当卷积核是11的时候,它实际上就是一个神经元权重的意思了,其实它这里用这样的方法可以省去最后的MLP操作。那么在这个之前,会先做一次正常的卷积操作,实现一下二维图像分辨率减小的操作,我们来整体看一下NIN:
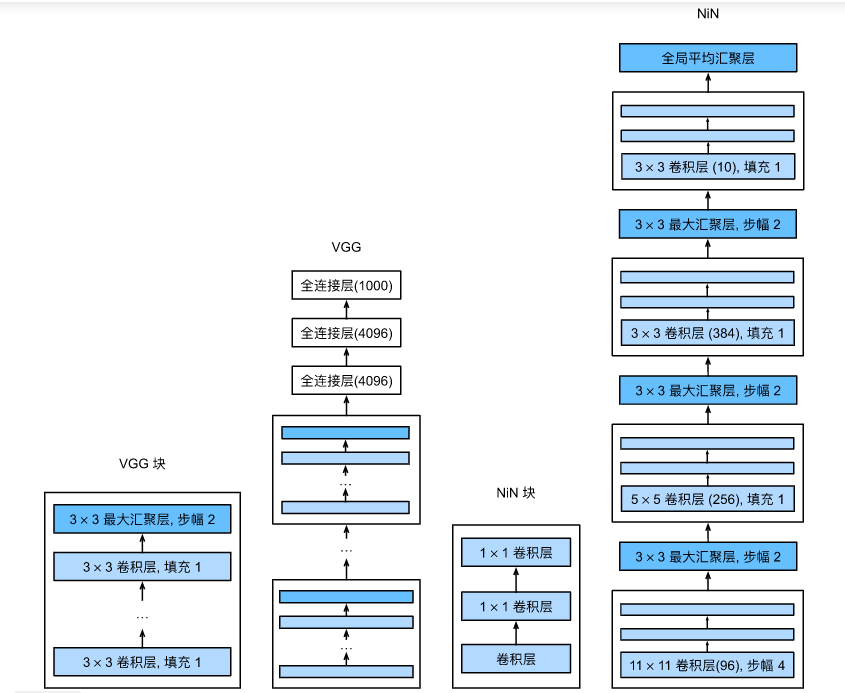
NIN其实也是一个块结构的卷积神经网络,NIN块中包含两样东西:一个是非11的卷积层,正常的互相关运算,另一个就是1*1的卷积层,目的可以看作是替代后面的MLP操作。一个NIN块后面加一个最大池化层,最后的最后加一个全局平均池化层,就搭建完了整个模型。
实现
NIN块的实现
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
#NIN块先是一个正常的卷积层
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
#接下来2层用了1*1的卷积核的卷积层
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
NIN模型的实现
其实NIN模型还是在GNN基础上改进的,他也用到了GNN使用过的dropout。不同的是最后,GNN以及其他算法都在最后在基于MLP的网络下用了一个softmax实现分类,而NIN不需要MLP,他是最后直接把卷积的输出通道定为10,其实也可以得到一个类似softmax的效果。
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())
查看模型
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
结果:
Sequential output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Sequential output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Sequential output shape: torch.Size([1, 384, 12, 12])
MaxPool2d output shape: torch.Size([1, 384, 5, 5])
Dropout output shape: torch.Size([1, 384, 5, 5])
Sequential output shape: torch.Size([1, 10, 5, 5])
AdaptiveAvgPool2d output shape: torch.Size([1, 10, 1, 1])
Flatten output shape: torch.Size([1, 10])
训练
不跑了,跑不出,没钱
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
小结
这个NIN吧,其实我感觉就是为了降低GNN复杂度而生的,但是它的准确率确实不高,远不及GNN,和之前的AlexNet相比也差不多,然后就是它的可解释性我感觉差点意思,所以他的实际问题的使用率不怎么高,就是大家不怎么用它解决实际问题,但它提出了1*1卷积核,对后面的模型有一定帮助。















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









