







目录
0 引言
如今,我们的日常生活中调度问题随处可见:摩天大楼里的电梯调度、超市收银处的调度现象、计算机里的进程调度和磁盘调度等等。而在不同的调度问题中,针对不同的优化目标,如果我们将问题抽象为一个数学问题,给出求解该问题的算法模型,我们就得到了不同的调度算法。
1 调度的相关概念回顾
1.1 调度与调度算法
调度是指将有限的资源按照时间最优分配给任务,包括资源分配与任务排序。而在操作系统中,调度算法就是根据系统的资源分配策略所规定的资源分配算法。不同的系统和系统目标通常有不同的调度算法。常见的调度算法有:先来先服务、短作业优先、轮转法等。目前存在的多种调度算法中,有的算法适用于作业调度,有的算法适用于进程调度,而有些调度算法两者均适用。
1.2 调度算法的要求
操作系统中的调度算法要求高资源利用率、高吞吐量、用户满意等。例如,批处理系统中要求增加系统吞吐量和提高系统资源的利用率;分时系统则要保证每个分时用户能容忍的响应时间;而实时系统要保证对随机发生的外部事件做出实时响应。对一个算法主要的评价因素有吞吐量(单位时间内CPU完成作业的数量)、CPU利用率、周转时间(评价批处理系统的性能指标)等。
1.3 常见调度算法
先来先服务(FCFS)
先来先服务是最简单的调度算法,按先后顺序进行调度。
轮转法(Round Robin)
轮转法是让每个进程在就绪队列中的等待时间与享受服务的时间成正比例。将系统中所有的就绪进程按照FCFS原则,排成一个队列。每次调度时将CPU分派给队首进程,让其执行一个时间片。时间片的长度从几ms到几百ms。在一个时间片结束时,发生时钟中断,切换到队列中的下一个任务,如此循环,直到队列中的进程执行完毕。
短作业优先
短作业优先将作业长度从短到长排列,并按照此顺序进行调度。
多级反馈队列算法
设置多个就绪队列,分别赋予不同的优先级,如逐级降低,队列一的优先级最高。每个队列执行时间片的长度也不同,规定优先级越低则时间片越长,如逐级加倍。新进程进入内存后,先投入队列一的末尾,按FCFS算法调度;若按队列一一个时间片未能执行完,则降低投入到队列二的末尾,同样按FCFS算法调度;如此下去,降低到最后的队列,则按“时间片轮转”算法调度直到完成。
2 简单调度案例
2.1 案例一
2.1.1 案例描述
单机调度问题:共有n个任务,每个任务的加工时间为pj ,从开始处理第一个任务开始,计算第j个任务完工时间为Cj ;计算所有任务的完工时间之和ΣCj ,比较不同算法的完工时间之和,使完工时间之和最小。
目标函数: min ΣCj
| 符号 | 描述 |
| pj | 任务j的加工时间 |
| Cj | 任务j的完工时间 |
| ΣCj | 任务的完工时间之和 |
表2.1-1 相关概念与符号
| j | 1 | 2 | 3 | 4 | 5 |
| pj | |||||
| ΣCj | |||||
表2.1-2 数据表格
2.1.2 算法设计
先来先服务法:

图2.1-1 main函数

图2.1-2 子程序random_1(生成随机任务)

图2.1-3 子程序answer (计算各个任务完工时间)
短作业优先:

图2.1-4 main函数

图2.1-5 子程序random_2(生成随机任务)

图2.1-6 子程序answer(计算各个任务的完工时间)


图2.1-7 子程序bubble_sort (将任务加工时间从小到大排序)
2.1.3 数据与结果分析
1)当任务量较少且单个任务时长较短时,会出现先来先服务与短作业优先结果相同的情况(如图2.1-8),此时选用先来先服务更优,其运算次数较少,算法简单。

图2.1-8 n=3,m=5时的raptor运行结果
(左列为短作业优先,右列为先来先服务。)
2)当任务总量逐渐增加,分别从单个任务完成时间和任务数量来讨论,有以下两种情况。
① 当单个任务时长较短时,任务量逐渐增加,可以看出先来先服务的结果始终大于短作业优先(如图2.1-9),此时选用短作业优先更优。

图2.1-9 m=3,n逐渐增加时的raptor运行结果
(左列为短作业优先,右列为先来先服务。)
② 当任务量较短时,单个任务时长逐渐增加,可以看出先来先服务的结果始终大于短作业优先(如图2.1-10),此时选用短作业优先更优。

图2.1-10 n=4,m逐渐增加时的raptor运行结果
(左列为短作业优先,右列为先来先服务。)
2.2 案例二
2.2.1 案例描述
单机调度问题:共有n个任务,每个任务的加工时间为pj ,给每个任务设置最终完成时间(工期)dj,从开始处理第一个任务开始,计算第j个任务完工时间为Cj ;计算任务的延迟Lj = Cj - dj ,比较不同算法的最大延迟时间,使最大延迟时间最小。
目标函数:min Lmax
| 符号 | 描述 |
| pj | 任务j的加工时间 |
| dj | 任务j的工期 |
| Cj | 任务j的完工时间 |
| Lj | 任务j的延迟 |
表2.2-1 相关概念与符号
| j | 1 | 2 | 3 | 4 | 5 |
| pj | |||||
| dj | |||||
| Cj | |||||
| Lj | |||||
| Lmax | |||||
表2.2-2数据表格
2.2.2 算法设计
先来先服务法

图2.2-1 main函数

图2.2-2 子程序random_(生成随机任务)

图2.2-3 子程序answer(计算各个任务的延迟时间)
短作业优先
① 按任务加工时间进行冒泡排序

图2.2-4 main函数


图2.2-5 子程序bubble_sort(将任务按加工时间从小到大排序)

图2.2-6 子程序random_ (生成随机任务)

图2.2-7 子程序answer
② 按任务完工时间进行冒泡排序(紧急程度)
将图2.2-5中冒泡排序最里层循环的条件改为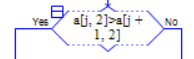 。
。
2.2.3 数据与结果分析
1)当任务量较少且单个任务时长较短时,会出现结果相同的情况(如图2.2-8中m=4时左列和右列),此时选用先来先服务更优,其运算次数较少,算法简单。

图2.2-8 n=3时的raptor运行结果
(左侧为先来先服务,中间为加工时间短优先,右侧为任务完成最终时间短优先。)
2)注意到当任务量较少,单个较短任务的最终完成时长极长时,会出现结果为0的情况(如图2.2-8中m=7时右列),此时应选用按任务完成最终时间短的优先。
3)若要求紧急任务先完成,则应选择选用按任务完成最终时间短的优先。

图2.2-9 n=10,m=10时的raptor运行结果
(左侧为先来先服务,中间为加工时间短优先,右侧为任务完成最终时间短优先。)
4)结合本次案例中的多组数据,发现按任务时间短优先并不能保证最大延迟时间最小,有时甚至不如先来先服务法(图2.2-9)。而按工期短(即任务完成最终时间短)优先的算法则可以达到目标函数最小值。显然当任务量逐渐增加,选用按工期短优先更优,尽管其运算次数较多,但能比其他算法更好地保证最大完工时间最小。
2.3 案例三
2.3.1 案例描述
单机调度问题:共有n个任务,每个任务的加工时间为pj ,给每个任务设置提交时间rj,只有提交时间过后才可以加工。每个任务有最终完成时间(工期)dj,从第一个任务开始加工开始,计算第j个任务完工时间为Cj ;计算任务的延迟Lj = Cj - dj ,比较不同算法的最大延迟时间之和,使最大延迟时间最小。
目标函数:min Lmax
| 符号 | 描述 |
| rj | 任务j的提交时间 |
| pj | 任务j的加工时间 |
| dj | 任务j的工期 |
| Cj | 任务j的完工时间 |
| Lj | 任务j的延迟 |
表2.3-1 相关概念与符号
| j | 1 | 2 | 3 | 4 | 5 |
| pj | |||||
| dj | |||||
| Cj | |||||
| Lj | |||||
| Lmax | |||||
表2.3-2 数据表格
2.3.2 算法设计
先来先服务法

图2.3-1 main函数

图2.3-2 子程序random_ (生成随机数)

图2.3-3 子程序answer(计算各个任务的延迟时间)
短作业优先
① 按任务加工时间进行冒泡排序

图2.3-4 main函数
(其中子程序random_和子程序answer同图2.3-2,图2.3-3)


图2.3-5 子程序bubble_sort(按任务加工时间从小到大排序)
② 按提交时间(准备时间)进行冒泡排序


图2.3-6 子程序bubble_sort(替换图2.3-5的冒泡排序,其他不变)
2.3.3 数据与结果分析
1)当任务量较少且单个任务时长较短时,会出现结果相同的情况(图2.3-7),此时选用先来先服务更优,其运算次数较少,算法简单。

图2.3-7 n=3,m=3时的raptor运行结果
(左侧为先来先服务,中间为按准备时间短优先,右侧为按任务加工时间短优先。)
2)当任务量逐渐增加,先来先服务和按加工时间短优先的结果始终大于按准备时间短优先的结果(图2.3-8),此时选用按准备时间短优先更优,尽管其运算次数较多,但能比先来先服务更好地保证最大完工时间最小。

图2.3-8 n=10,m=10时的raptor运行结果
(左侧为先来先服务,中间为按准备时间短优先,右侧为按任务加工时间短优先。)
2.3.4 算法补充
1. 除了按加工时间、准备时间进行排序外,还可以按工期从小到大排,当要求按紧急程度排序时,应使用按工期排序的算法。若出于综合性考虑,可按加工时间、准备时间、工期三者的权重和从小到大排,权重设置与实际情况相关。
2.除了在任务的数据生成一开始进行静态排序外,还可以进行动态排序。每当一个任务完成时,就将该时刻已经完成提交的任务按照进行加工时间长短从小到大排序,取队列最前的任务加工。理论上此法将比按准备时间短排序更优。
2.4 案例四
2.4.1 案例描述
双机调度问题:有a、b两台机,共有n个任务,每个任务的加工时间为pj ,从开始处理第一个任务开始,计算第j个任务完工时间为Cj ;比较得出各个任务的最大完工时间Cmax,比较各个算法的最大完工时间,使最大完工时间最小。
目标函数: min Cmax
| 符号 | 描述 |
| pj | 任务j的加工时间 |
| Cj | 任务j的完工时间 |
| Cmax | 最大完工时间 |
表2.4-1 相关概念与符号
| j | 1 | 2 | 3 | 4 | 5 |
| pj | |||||
| Cj | |||||
| Cmax |
表2.4-2数据表格
2.4.2 算法设计
先来先服务
注:将任务按生成顺序排序,a、b机分别取最前两个任务开始执行;每当其中一台机的任务完成时,在任务队列开头取第一个任务直至无任务可取。所有任务均完成时停止。

图2.4-1 main函数

图2.4-2 子程序random_(生成随机任务) 

图2.4-3 子程序answer
(求最大完工时间:只需比较a机与b机各自最后执行任务的完工时间大小即可得出所有任务中的最大完工时间)
短作业优先

图2.4-4 main函数

图2.4-5 子程序random_(生成随机任务)


图2.4-6 子程序bubble_sort(按任务加工时间从小到大排序)
(子程序answer与 图2.4-3 相同)
注:将任务按加工时间从长到短排序,a、b机分别取最前两个任务开始执行;每当其中一台机的任务完成时,在任务队列开头取第一个任务直至无任务可取。所有任务均完成时停止。
2.4.3 数据与结果分析
1)当任务量较少且单个任务时长较短时,会出现先来先服务与短作业优先结果相同的情况(如图2.4-7第二、第三组数据),此时选用先来先服务更优,其运算次数较少,算法简单。

图2.4-7 n=4,m=4与n=4,m=8时的raptor运行结果
(左侧为先来先服务,右侧为短作业优先。)
2)当各个任务时长的差距较大时,有时会出现某一台机最后一个任务很长,而另一台机空闲的情况,此时先来先服务的结果会比短作业优先更短。可见短作业优先在双机调度中不一定最优。

图2.4-8 n=15,m=10时的raptor运行结果
(左侧为先来先服务,右侧为短作业优先。)
3)当各个任务时长的差距较小时,某一台机最后一个任务很长,而另一台机空闲的情况较少出现,此时短作业优先更短(图2.4-9)。

图2.4-9 n=10,m=3时的raptor运行结果
(左侧为先来先服务,右侧为短作业优先。)
2.4.4 两种算法的比较
为了更充分地比较短作业优先和先来先服务算法在双机调度中的优劣,把两种算法放在同一个流程图中。

图2.4-10 子程序random_(生成随机任务)


图2.4-11 main函数

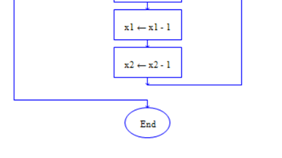
图2.4-12 子程序answer(计算最大完工时间)


图2.4-13 子程序bubble_sort(按任务加工时间从小到大排序)
结果分析:
(1)令m=3,n逐渐增加(任务时长的差距较小),令x=500
- 当任务量较少且为奇数时,由于会出现有一台机空闲时间较长的情况(如图2.4-14),先来先服务不仅算法简单,结果也更优,此时应选用先来先服务。
- 当任务量较少且为偶数时,由于一台机空闲时间较长的情况不再容易出现,先来先服务与短作业优先相差不大(如图2.4-15),但短作业优先体现出了优势。此时为了使计算次数更少,算法更加简单,应选用先来先服务;若严格要求使最大延迟最小,应选用短作业优先。


图2.4-14 m=3,n为奇数时的raptor运行结果(左)
图2.4-15 m=3,n为偶数时的raptor运行结果(右)
- 当任务数量增加,偶数个任务的两种算法的差距逐渐缩小,奇数个任务的差距逐渐增加。


图2.4-16 m=3,n逐渐增加时的raptor运行结果
(2)令m=10,n逐渐增加(任务时长的差距较大),令x=500
发现在任务时长的差距较大的情况出现较多时,短作业优先的平均值大于先来先服务,此时应采用先来先服务。


图2.4-17 m=10,n逐渐增加时的raptor运行结果
2.4.5 算法的改进
从结果看出无论是先来先服务还是短作业优先在双机调度中都显得不够优越,因此提出新的算法。
为避免出现一台机器长期空闲的情况,编写新的改进程序(图2.4-16)加入上面的综合程序中,在主程序开始处增加y3变量以及对新方法的调用(图2.4-17),末尾加上新方法结果平均值的输出。该方法将任务按长度进行冒泡排序,并将最短的任务分配给a机,最长的分配给b机,每当a机的任务完成时在按从小到大排列好的任务序列里取最前的一个任务,每当b机的任务完成时在序列里取最后的一个任务,直到所有任务完成。

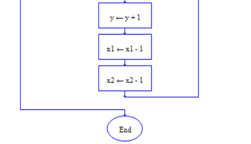
图2.4-18 子程序answer2



图2.4-19 main函数
结果分析:

图2.4-20 改进算法的运算结果
新算法比先来先服务和短作业优先都要好,偶尔会出现先来先服务更优的情况(如图2.4-20中n=11,m=10,x=100时),但两者相差极小,总体还是新法更优。
3 回顾与总结
3.1 四个简单调度案例模拟实验的结论
针对不同的案例,不同的目标函数,不同的算法有其各自的优越性,在实际调度问题中需要结合多方面因素考虑。
案例一的单机调度中,短作业优先能使最大完工时间最小。尽管当任务量较少且单个任务时长较短时,会出现先来先服务与短作业优先结果相同的情况,但这种情况的出现其实是因为任务量较少、任务时长较短时容易生成已经按照短作业优先排序的任务序列,因此,当任务量不确定,或任务时长可能极大也可能极小时,短作业优先更优。但若单机只偶尔处理任务量不大的几个小的任务时,先来先服务因其算法简单更优。
而在案例二中当任务量较少且单个任务时长较短时,会出现结果相同的情况,此时选用先来先服务更优,其运算次数较少,算法简单。同时按任务时间短优先并不能保证最大延迟时间最小,有时甚至不如先来先服务法。而按工期短(即任务完成最终时间短)优先的算法则可以达到目标函数最小值。显然当任务量逐渐增加,选用按工期短优先更优,尽管其运算次数较多,但能比其他算法更好地保证最大完工时间最小
在案例三,当任务量较少且单个任务时长较短时,选用先来先服务更优,其运算次数较少,算法简单。当任务量逐渐增加,先来先服务和按加工时间短优先的结果始终大于按准备时间短优先的结果,此时选用按准备时间短优先更优,尽管其运算次数较多,但能比先来先服务更好地保证最大完工时间最小。而除了按加工时间、准备时间进行冒泡排序外,还可以按工期从小到大排。当要求按紧急程度排序时,应使用按工期冒泡排序的算法。若出于综合性考虑,可按加工时间、准备时间、工期三者的权重和从小到大排,权重设置与实际情况相关。若想进一步使最大延迟最小,还可以进行动态排序。每当一个任务完成时,就将该时刻已经完成提交的任务按照进行加工时间长短从小到大排序,取队列最前的任务加工。理论上此法将比按准备时间短排序更优。
案例四中的简单双机调度模拟中单次实验中用先来先服务法无法控制,具有极强不确定性,不能保证最优。但从大量实验来看,由于存在某一台机最后一个任务很长,而另一台机空闲的情况,先来先服务总体更优。为此进一步改进算法,按长度进行冒泡排序,并将最短的任务分配给a机,最长的分配给b机,每当a机的任务完成时在按从小到大排列好的任务序列里取最前的一个任务,每当b机的任务完成时在序列里取最后一个任务,直到所有任务完成,此方法优于前两种。
3.2 几个常见调度算法的优劣
先来先服务
算法简单,在任务量小且长度较短时占优势。任务量增大,任务长度增加时无论是对完工时间之和、最大完工时间还是最大延迟具有极强不确定性,很难保证最优,但在双机调度求最大延迟中又有优势。
短作业优先
算法稍复杂,计算次数较多,时间较长。若在不同的目标函数中对排序对象进行变更,则改进后的短作业优先算法在长作业中通常比先来先服务更优。在双机调度中,让一机在排序后的队列最前取任务加工,另一机在队列最后取任务加工,能使最大完工时间最小。
3.3 模拟实验的改进建议
在进行上述模拟实验时,为了方便比较相同案例中同一组数据在多种算法下的结果,在所有的改进方案中加入子程序,将未改进方案中随机生成的数据手动输入新方案中。
相同数据在不同方案中比较时,由于第一个算法的数据是随机生成的,在第二个算法中为了比较手动输入数据非常麻烦,后面改为将不同的方案拆解成不同的子程序放入同一个程序中,实现同组数据多种方案可以直接调用,还避免了大量重复相同的子程序。
为使结论更有说服力,加入一个循环使其生成当任务个数为n,最大时长为m时的多组随机数,输出不同方案下不同的最终结果y1,y2,……yi(i为随机数的组数),通过程序计算各个y的差值,当随机数的组数极大时,可更好的看出哪个算法更优。















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









