






1、聚类任务
在“无监督学习”中,训练样本的标记信息是为未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。常见的无监督学习任务有密度估计、异常检测,其中,研究最多,应用最广的是"聚类"。
聚类试图将数据集中的样本划分为若干个不相交的子集,每个子集称为一个簇。通过这样的划分,每个簇可能对应于一些潜在的概念,需说
聚类既能作为一个单独过程,用于寻找数据内存在的分布结构,也可作为分类等其他学习任务的前驱过程,例如,在一些商业应用中需对新用户的类型进行判别,但定义“用户类型”对商家来说却可能不太容易,此时往往可先对用户数据进行聚类,根据聚类结果将每个簇定义为一类,然后再基于这些类训练分类模型,用于判别新用户的类型。
基于不同的学习策略,人们设计出多种类型的聚类算法,再学习算法之前,去哦们五年先来了解一下聚类算法涉及的两个基本问题----性能度量和距离计算。
2、性能度量
聚类性能度量亦称聚类“有效性指标”,与监督学习中的性能度量作用相似,对聚类结果,我们需要通过某种性能度量来评估其好坏,另一方面,若明确了最终将要使用的性能度量,则可直接将其作为聚类过程的优化目标,从而更好地得到符合要求的聚类结果。
聚类是将样本集D划分为若干个互不相交的子集,即样本簇,那么,什么样的聚类结果比较好呢?直观上看,我们希望同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同。换言之,聚类结果的“簇内相似度”高且“簇间相似度”低。
聚类性能度量有两类,一类是将聚类结果与某个“参考模型”进行比较,称为“外部指标”;另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”。
对数据集 D = D= D={ x 1 , x 2 , … … , x m x_1,x_2,……,x_m x1,x2,……,xm},假定通过聚类给出的簇划分为 C = C= C={ C 1 , C 2 , … … , C k C_1,C_2,……,C_k C1,C2,……,Ck},参考模型给出的簇划分为 C ∗ = C^*= C∗={ C 1 ∗ , C 2 ∗ , … … , C k ∗ C_1^*,C_2^*,……,C_k^* C1∗,C2∗,……,Ck∗}。相应地,令 λ \lambda λ与 λ ∗ \lambda^* λ∗分别表示 C C C与 C ∗ C^* C∗的簇标记向量。令 a a a表示在 C C C中属于相同簇在 c ∗ c^* c∗中也属于相同簇的样本对的数目, b b b表示在 C C C中属于相同簇在 c ∗ c^* c∗中属于不同簇的样本对的数目, c c c表示在 C C C中属于不同簇在 c ∗ c^* c∗中属于相同簇的样本对的数目, d d d表示在 C C C中属于不同簇在 c ∗ c^* c∗中属于不同簇的样本对的数目
∙
\bullet
∙ Jaccard系数
J
C
=
a
a
+
b
+
c
JC=\frac{a}{a+b+c}
JC=a+b+ca
∙
\bullet
∙ FM指数
F
M
I
=
a
a
+
b
∗
a
a
+
c
FMI=\sqrt{\frac{a}{a+b}*\frac{a}{a+c}}
FMI=a+ba∗a+ca
∙
\bullet
∙ Rand指数
R
I
=
2
(
a
+
d
)
m
(
m
−
1
)
RI=\frac{2(a+d)}{m(m-1)}
RI=m(m−1)2(a+d)
显然,上述性能度量的结果值均在[0,1]区间,值越大越好。考虑聚类结果的簇划分
C
=
C=
C={
C
1
,
C
2
,
…
…
,
C
k
C_1,C_2,……,C_k
C1,C2,……,Ck},定义
a
v
g
(
C
)
=
2
∣
C
∣
(
∣
C
∣
−
1
)
∑
1
≤
i
<
j
≤
∣
C
∣
d
i
s
t
(
x
i
,
x
j
)
d
i
a
m
(
C
)
=
m
a
x
1
≤
i
<
j
≤
∣
C
∣
d
i
s
t
(
x
i
,
x
j
)
d
m
i
n
(
C
i
,
C
j
)
=
m
i
n
x
i
∈
C
i
,
x
j
∈
C
j
d
i
s
t
(
x
i
,
x
j
)
d
c
e
n
(
C
i
,
C
j
)
=
d
i
s
t
(
μ
i
,
μ
j
)
avg(C)=\frac{2}{|C|(|C|-1)}\sum_{1\leq i<j\leq|C|}dist(x_i,x_j)\\ diam(C)=max_{1\leq i<j\leq|C|}dist(x_i,x_j)\\ d_{min}(C_i,C_j)=min_{x_i\in C_i,x_j\in C_j}dist(x_i,x_j)\\ d_{cen}(C_i,C_j)=dist(\mu_i,\mu_j)
avg(C)=∣C∣(∣C∣−1)21≤i<j≤∣C∣∑dist(xi,xj)diam(C)=max1≤i<j≤∣C∣dist(xi,xj)dmin(Ci,Cj)=minxi∈Ci,xj∈Cjdist(xi,xj)dcen(Ci,Cj)=dist(μi,μj)
其中,
μ
\mu
μ代表的是簇C的中心点
μ
=
1
∣
C
∣
∑
1
≤
i
≤
∣
C
∣
x
i
\mu=\frac{1}{|C|}\sum_{1\leq i\leq |C|}x_i
μ=∣C∣1∑1≤i≤∣C∣xi,可知
a
v
g
(
C
)
avg(C)
avg(C)对应的是簇c内样本间的平均距离,
d
i
a
m
(
c
)
diam(c)
diam(c)对应的是簇C内样本间的最远距离,
d
m
i
n
d_{min}
dmin对应的是簇
C
i
C_i
Ci与簇
C
j
C_j
Cj最近样本间的距离,
d
c
e
n
d_{cen}
dcen对应的是簇
C
i
C_i
Ci与簇
C
j
C_j
Cj中心点间的距离。
基于上述各式可推导出以下常用的性能度量内部指标:
∙
\bullet
∙ DB指数(简称DBI)
D
B
I
=
1
k
∑
i
=
1
k
m
a
x
j
≠
1
(
a
v
g
(
C
i
)
+
a
v
g
(
C
j
)
d
c
e
n
(
μ
i
,
μ
j
)
)
DBI=\frac{1}{k}\sum\limits_{i=1}^k\underset{j\neq1}{max}\Big(\frac{avg(C_i)+avg(C_j)}{d_{cen}(\mu_i,\mu_j)}\Big)
DBI=k1i=1∑kj=1max(dcen(μi,μj)avg(Ci)+avg(Cj))
∙
\bullet
∙ Dunn指数(简称DI)
D
I
=
m
i
n
1
≤
i
≤
k
(
m
i
n
j
≠
i
(
d
m
i
n
(
C
i
,
C
j
)
m
a
x
1
≤
l
≤
k
d
i
a
m
(
C
l
)
)
)
DI=\underset{1\leq i\leq k}{min}(\underset{j\neq i}{min}(\frac{d_{min}(C_i,C_j)}{max_{1\leq l\leq k}diam(C_l)}))
DI=1≤i≤kmin(j=imin(max1≤l≤kdiam(Cl)dmin(Ci,Cj)))我们希望簇内样本距离尽可能小,簇间距离尽可能大,显然,DBI的值越小越好,而DI则相反,值越大越好。
3、距离计算
当函数
d
i
s
t
(
.
,
.
)
dist(. , .)
dist(.,.)是一个距离度量时,需要满足以下基本性质:
非
负
性
:
d
i
s
t
(
x
i
,
x
j
)
≥
0
非负性:dist(x_i,x_j)\geq0
非负性:dist(xi,xj)≥0
同
一
性
:
d
i
s
t
(
x
i
,
x
j
)
=
0
,
当
且
仅
当
x
i
=
x
j
同一性:dist(x_i,x_j)=0,当且仅当x_i=x_j
同一性:dist(xi,xj)=0,当且仅当xi=xj
对
称
性
:
d
i
s
t
(
x
i
,
x
j
)
=
d
i
s
t
(
x
j
,
x
i
)
对称性:dist(x_i,x_j)=dist(x_j,x_i)
对称性:dist(xi,xj)=dist(xj,xi)
直
递
性
:
d
i
s
t
(
x
i
,
x
j
)
≤
d
i
s
t
(
x
i
,
x
k
)
+
d
i
s
t
(
x
k
,
x
j
)
直递性:dist(x_i,x_j)\leq dist(x_i,x_k)+dist(x_k,x_j)
直递性:dist(xi,xj)≤dist(xi,xk)+dist(xk,xj)
给定样本
x
i
=
(
x
i
1
,
x
i
2
,
…
…
,
x
i
n
)
,
x
j
=
(
x
j
1
,
x
j
2
,
…
…
,
x
j
n
)
x_i=(x_{i1},x_{i2},……,x_{in}),x_j=(x_{j1},x_{j2},……,x_{jn})
xi=(xi1,xi2,……,xin),xj=(xj1,xj2,……,xjn),它的“闵可夫斯基距离”定义为:
d
i
s
t
m
k
(
x
i
,
x
j
)
=
(
∑
u
=
1
n
∣
x
i
u
−
x
j
u
∣
p
)
1
p
dist_{mk}(x_i,x_j)=\Big(\sum\limits_{u=1}^{n}|x_{iu}-x_{ju}|^p\Big)^{\frac{1}{p}}
distmk(xi,xj)=(u=1∑n∣xiu−xju∣p)p1当p=2时,闵可夫斯基距离即为欧式距离
d
i
s
t
e
d
(
x
i
,
x
j
)
=
∣
∣
x
i
−
x
j
∣
∣
2
=
∑
u
=
1
n
∣
x
i
u
−
x
j
u
∣
2
dist_{ed}(x_i,x_j)=||x_i-x_j ||_2=\sqrt{\sum\limits_{u=1}^{n}|x_{iu}-x_{ju}|^2}
disted(xi,xj)=∣∣xi−xj∣∣2=u=1∑n∣xiu−xju∣2p=1时,闵可夫斯基距离即为曼哈顿距离
d
i
s
t
m
a
n
(
x
i
,
x
j
)
=
∣
∣
x
i
−
x
j
∣
∣
1
=
∑
u
=
1
n
∣
x
i
u
−
x
j
u
∣
dist_{man}(x_i,x_j)=||x_i-x_j ||_1=\sum\limits_{u=1}^{n}|x_{iu}-x_{ju}|
distman(xi,xj)=∣∣xi−xj∣∣1=u=1∑n∣xiu−xju∣我们常将属性划分为“连续属性”和“离散属性”。然而,在计算距离时,更为重要的是属性上是否定义了“序”关系。例如定义域为{1,2,3}的离散属性,我们可以直接在属性值上计算距离:1与2比较近,与3比较远,这样的属性称为有序属性;对不能直接在属性值上计算距离的离散属性,称为无序属性,比如颜色这个属性,假设有{红,黄,蓝},我们不能简单的转化为{1,2,3},因为原先的属性间没有明显的大小远近等“序”的关系。
对无序属性,可采用VDM(Value Difference Metric)距离,假设在属性
u
u
u上取值为
a
a
a的样本的个数为
m
u
,
a
m_{u,a}
mu,a,第
i
i
i个样本簇中在属性
u
u
u上取值为
a
a
a的样本的个数为
m
u
,
a
,
i
m_{u,a,i}
mu,a,i,样本簇数为
k
k
k,则属性
u
u
u上的两个离散值
a
a
a与
b
b
b之间的VDM距离为
V
D
M
p
(
a
,
b
)
=
∑
i
=
1
k
∣
m
u
,
a
,
i
m
u
,
a
−
m
u
,
b
,
i
m
u
,
b
∣
p
VDM_p(a,b)=\sum_{i=1}^k|\frac{m_{u,a,i}}{m_{u,a}}-\frac{m_{u,b,i}}{m_{u,b}}|^p
VDMp(a,b)=i=1∑k∣mu,amu,a,i−mu,bmu,b,i∣p
将闵可夫距离和VDM距离混合可处理混合属性,假设有
n
c
n_c
nc个有序属性,
n
−
n
c
n-n_c
n−nc个无序属性,则
M
i
n
k
o
v
D
M
p
(
x
i
,
x
j
)
=
(
∑
u
=
1
n
c
∣
x
i
u
−
x
j
u
∣
p
+
∑
u
=
n
c
+
1
n
V
D
M
p
(
x
i
u
,
x
j
u
)
)
MinkovDM_p(x_i,x_j)=\Big(\sum_{u=1}^{n_c}|x_{iu}-x_{ju}|^p+\sum_{u=n_c+1}^nVDM_p(x_{iu},x_{ju})\Big)
MinkovDMp(xi,xj)=(u=1∑nc∣xiu−xju∣p+u=nc+1∑nVDMp(xiu,xju))
当样本空间中不同属性的重要性不同时,可使用“加权距离”。比如加权闵可夫距离,设属性的权重为
w
i
w_i
wi,(
w
i
>
0
,
∑
i
=
1
n
w
i
=
1
w_i>0,\sum_{i=1}^nw_i=1
wi>0,∑i=1nwi=1):
d
i
s
t
w
m
k
(
x
i
,
x
j
)
=
(
w
1
∗
∣
x
i
1
−
x
j
1
∣
p
+
…
…
+
w
n
∣
x
i
n
−
x
j
n
∣
p
)
1
p
dist_{wmk}(x_i,x_j)=(w_1*|x_{i1}-x_{j1}|^p+……+w_n|x_{in}-x_{jn}|^p)^\frac{1}{p}
distwmk(xi,xj)=(w1∗∣xi1−xj1∣p+……+wn∣xin−xjn∣p)p1
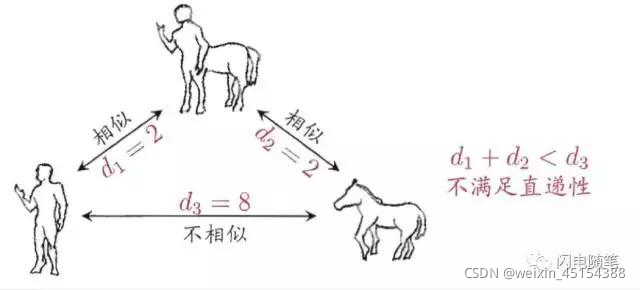
要注意的是,通常我们是基于某种形式的距离来定义"相似度度量",距离越大,相似度越小。然而,用于相似度度量的距离未必一定要满足距离度量的所有基本性质。比如“人”、“马”都与“人马”比较相似,距离比较小,但人和马是不相似的,距离很大。此时该距离不再满足直递性,这样的距离称为“非度量距离”。
4、原型聚类
原型聚类亦称“基于原型的聚类“, 此类算法假设聚类结构能够通过一组原型刻画,在现实聚类任务中极为常用。通常情况下,算法先对原型进行初始化,然后对原型进行迭代更新求解。采用不同的原型表示,不同的求解方法,将产生不同的算法。下面介绍几种著名的原型聚类算法。
4.1 k均值算法
给定样本集
D
=
D=
D={
x
1
,
x
2
,
…
…
,
x
m
x_1,x_2,……,x_m
x1,x2,……,xm},“k均值”算法针对聚类所得簇划分
C
=
C=
C={
C
1
,
C
2
,
…
…
,
C
k
C_1,C_2,……,C_k
C1,C2,……,Ck},假设
μ
i
\mu_i
μi是簇
c
i
c_i
ci的均值向量,
μ
i
=
1
C
i
∑
x
∈
C
i
x
\mu_i=\frac{1}{C_i}\sum_{x\in C_i}x
μi=Ci1∑x∈Cix,则它的平方误差为
E
=
∑
i
=
1
k
∑
x
∈
C
i
∣
∣
x
−
μ
i
∣
∣
2
2
E=\sum_{i=1}^{k}\sum_{x\in C_i}||x-\mu_i||_2^2
E=i=1∑kx∈Ci∑∣∣x−μi∣∣22
它刻画了簇内样本围绕簇均值向量的紧密程度,E值越小簇内样本相似度越高,因此,我们要想办法将上式最小化,为将其最小化,我们需要考察样本集D所有可能的簇划分。因此,k均值算法采用了贪心策略,通过迭代优化来近似求解上式。具体流程如下:

首先确定聚类簇数k,随机选择k个样本作为初始均值向量,计算样本
x
j
x_j
xj与均值向量之间的距离,将样本
x
j
x_j
xj划入相应的簇中,类似地,将数据集中所有样本划分到对应的簇,计算新划分后的簇的均值向量,更新均值向量后,不断重复上述过程,直至迭代产生的结果与上一轮形同,算法停止,得到最终的簇划分。
4.2 学习向量量化
与k均值算法类似,“学习向量量化(LVQ)”也是试图找出一组原型向量来刻画聚类结构,但与一般聚类算法不同的是,LVQ假设数据样本带有类别标记,在学习过程中利用样本的这些监督信息来辅助聚类。
给定样本集
D
=
D=
D={
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
…
,
(
x
m
,
y
m
)
(x_1,y_1),(x_2,y_2),……,(x_m,y_m)
(x1,y1),(x2,y2),……,(xm,ym)},每个样本
x
j
x_j
xj是由n个属性描述的特征向量
(
x
j
1
;
x
j
2
;
…
…
,
x
j
n
)
(x_{j1};x_{j2};……,x_{jn})
(xj1;xj2;……,xjn),
y
j
∈
y
y_j\in y
yj∈y是样本
x
j
x_j
xj的类别标记。LVQ的目标是学得一组n维原型向量{
p
1
,
p
2
,
…
…
,
p
q
p_1,p_2,……,p_q
p1,p2,……,pq},每个原型向量代表一个聚类簇,簇标记
t
i
∈
y
t_i\in y
ti∈y。
LVQ算法的具体过程如下图:

首先对原型向量进行初始化,假设有k个簇,第i个簇可从类别标记为 t i t_i ti的样本中随机选取一个作为它的原型向量。随机选取一个具有标记的训练样本 x j x_j xj,找出与其距离最近的原型向量 p i ∗ p_i^* pi∗,若两者的类别标记相同,则更新原型向量为 p ′ = p i ∗ + η ∗ ( x j − p i ∗ ) p^{'}=p_i^*+\eta*(x_j-p_i^*) p′=pi∗+η∗(xj−pi∗)更新后原型向量与样本之间的距离变为 ∣ ∣ p ′ − x j ∣ ∣ 2 = ( 1 − η ) ∗ ∣ ∣ p i ∗ − x j ∣ ∣ 2 ||p^{'}-x_j||_2=(1-\eta)*||p_i^*-x_j||_2 ∣∣p′−xj∣∣2=(1−η)∗∣∣pi∗−xj∣∣2可以发现,只要学习率 η ∈ ( 0 , 1 ) \eta\in(0,1) η∈(0,1),那么更新后原型向量就会更接近样本;当原型向量与样本的标记不同时更新原型向量为 p ′ = p i ∗ − η ∗ ( x j − p i ∗ ) p^{'}=p_i^*-\eta*(x_j-p_i^*) p′=pi∗−η∗(xj−pi∗)使原型向量远离样本,不断重复上述过程直到满足停止条件(原型向量更新很小或达到最大迭代次数),将结果返回。学得原型向量后即可对样本进行划分,将它划入距离最近的原型向量所代表的簇中,我们的任务就完成了。
4.3 高斯混合聚类
数据分布由k个高斯成分混合而成,与k均值,LVQ用原型向量来刻画聚类结构不同,高斯混合聚类采用概率模型来表达聚类原型。对n维样本空间中的随机向量
x
x
x,若
x
x
x服从高斯分布,其概率密度函数为
p
(
x
)
=
1
(
2
π
)
n
2
∣
∑
∣
1
2
e
−
1
2
(
x
−
μ
)
T
∑
−
1
(
x
−
μ
)
p(x)=\frac{1}{(2\pi)^{\frac{n}{2}}|\sum|^{\frac{1}{2}}}e^{-\frac{1}{2}(x-\mu)^T\sum^{-1}(x-\mu)}
p(x)=(2π)2n∣∑∣211e−21(x−μ)T∑−1(x−μ)其中
μ
\mu
μ是n维均值向量,
∑
\sum
∑是
n
∗
n
n*n
n∗n的协方差矩阵。可以看出,高斯分布由均值向量
μ
\mu
μ和协方差矩阵
∑
\sum
∑这两个参数确定。
将上式记为
p
(
x
∣
μ
,
∑
)
p(x|\mu,\sum)
p(x∣μ,∑),则高斯混合分布可定义为
p
M
(
x
)
=
∑
i
=
1
k
α
i
∗
p
(
x
∣
μ
i
,
∑
i
)
p_M(x)=\sum_{i=1}^{k}\alpha_i*p(x|\mu_i,\sum_i)
pM(x)=i=1∑kαi∗p(x∣μi,i∑)
可以看出,上式有k个成分,每个成分对应一个高斯分布。
假设样本的生成过程由高斯混合分布给出:首先,根据
α
1
,
α
2
,
…
…
,
α
k
\alpha_1,\alpha_2,……,\alpha_k
α1,α2,……,αk定义的先验分布选择高斯混合成分,其中
α
i
\alpha_i
αi为选择第i个混合成分的概率;然后,根据被选择的混合成分的概率密度函数进行采样,从而生成相应的样本。若训练集D={
x
1
,
x
2
,
…
…
,
x
m
x_1,x_2,……,x_m
x1,x2,……,xm}由上述过程生成,令随机变量
z
j
∈
z_j\in
zj∈{
1
,
2
,
…
…
,
k
1,2,……,k
1,2,……,k}表示生成样本
x
j
x_j
xj的高斯混合成分,其取值未知。显然,
z
j
z_j
zj的先验概率
p
(
z
j
=
i
)
=
α
i
p(z_j=i)=\alpha_i
p(zj=i)=αi,后验概率
P
M
(
z
j
=
i
∣
x
j
)
=
P
(
z
j
=
i
)
∗
P
M
(
x
j
∣
z
j
=
i
)
P
M
(
x
j
)
=
α
i
∗
P
(
x
j
∣
μ
i
,
∑
i
)
∑
l
=
1
k
α
l
∗
p
(
x
j
∣
μ
l
,
∑
l
)
P_M(z_j=i|x_j)=\frac{P(z_j=i)*P_M(x_j|z_j=i)}{P_M(x_j)}=\frac{\alpha_i*P(x_j|\mu_i,\sum_i)}{\sum\limits_{l=1}^k\alpha_l*p(x_j|\mu_l,\sum_l)}
PM(zj=i∣xj)=PM(xj)P(zj=i)∗PM(xj∣zj=i)=l=1∑kαl∗p(xj∣μl,∑l)αi∗P(xj∣μi,∑i)
P
M
(
z
j
=
i
∣
x
j
)
P_M(z_j=i|x_j)
PM(zj=i∣xj)给出了样本
x
j
x_j
xj由第i个高斯混合成分生成的后验概率,记为
γ
j
i
\gamma_{ji}
γji,当高斯混合分布已知时,高斯混合聚类将把样本集D划分为k个簇
C
=
C=
C={
C
1
,
C
2
,
…
…
,
C
k
C_1,C_2,……,C_k
C1,C2,……,Ck},每个样本
x
j
x_j
xj的簇标记
λ
j
\lambda_j
λj如下确定:
λ
j
=
a
r
g
max
i
∈
(
1
,
2
,
…
…
,
k
)
γ
j
i
\lambda_j=\underset{i\in(1,2,……,k)}{arg\max}\gamma_{ji}
λj=i∈(1,2,……,k)argmaxγji因此,从原型聚类的角度来看,高斯混合聚类是采用概率模型对原型进行刻画,簇划分则由原型对应后验概率确定。
模型参数
α
i
、
μ
i
、
∑
i
\alpha_i、\mu_i、\sum_i
αi、μi、∑i可以通过极大似然法来确定,给定样本集D,它的d对数似然估计可写为
L
L
(
D
)
=
l
n
(
∏
j
=
1
m
P
m
(
x
j
)
)
=
∑
j
=
1
m
l
n
(
∑
i
=
1
k
α
i
∗
p
(
x
j
∣
μ
i
,
∑
i
)
)
LL(D)=ln\Big(\prod_{j= 1}^{m}P_m(x_j)\Big)=\sum_{j=1}^{m}ln\Big(\sum_{i=1}^k\alpha_i*p(x_j|\mu_i,\sum_i)\Big)
LL(D)=ln(j=1∏mPm(xj))=j=1∑mln(i=1∑kαi∗p(xj∣μi,i∑))常用EM算法来对参数进行求解,将上式对
μ
i
\mu_i
μi求偏导为零,则
∑
j
=
1
m
α
i
∗
p
(
x
j
∣
μ
i
,
∑
i
)
∑
l
=
1
k
α
l
∗
p
(
x
j
∣
μ
l
,
∑
l
)
(
x
j
−
μ
i
)
=
∑
j
=
1
m
γ
j
i
(
x
j
−
μ
i
)
=
0
\sum_{j=1}^{m}\frac{\alpha_i*p(x_j|\mu_i,\sum_i)}{\sum_{l=1}^k\alpha_l*p(x_j|\mu_l,\sum_l)}(x_j-\mu_i)=\sum_{j=1}^m\gamma_{ji}(x_j-\mu_i)=0
j=1∑m∑l=1kαl∗p(xj∣μl,∑l)αi∗p(xj∣μi,∑i)(xj−μi)=j=1∑mγji(xj−μi)=0由上式可得出
μ
i
=
∑
j
=
1
m
γ
j
i
x
i
∑
j
=
1
m
γ
j
i
\mu_i=\frac{\sum\limits_{j=1}^m\gamma_{ji}x_i}{\sum\limits_{j=1}^m\gamma_{ji}}
μi=j=1∑mγjij=1∑mγjixi类似地,令
L
L
(
D
)
LL(D)
LL(D)对
∑
i
\sum_i
∑i求偏导为令可得
∑
i
=
∑
j
=
1
m
γ
j
i
(
x
j
−
μ
i
)
(
x
j
−
μ
i
)
T
∑
j
=
1
m
γ
j
i
\sum_i=\frac{\sum\limits_{j=1}^m\gamma_{ji}(x_j-\mu_i)(x_j-\mu_i)^T}{\sum_{j=1}^m\limits\gamma_{ji}}
i∑=j=1∑mγjij=1∑mγji(xj−μi)(xj−μi)T要想确定
α
i
\alpha_i
αi的值,除了最大化,还要满足
α
i
≥
0
,
∑
i
=
1
k
α
i
=
0
\alpha_i\geq0,\sum_{i=1}^k\alpha_i=0
αi≥0,∑i=1kαi=0。用拉格朗日法对其求解,令
L
L
(
D
)
+
λ
(
∑
i
=
1
k
α
i
−
1
)
LL(D)+\lambda(\sum_{i=1}^k\alpha_i-1)
LL(D)+λ(∑i=1kαi−1)对
α
i
\alpha_i
αi求偏导为零,得
∑
j
=
1
m
p
(
x
j
∣
μ
i
,
∑
i
)
∑
l
=
1
k
α
l
∗
p
(
x
j
∣
μ
l
,
∑
l
)
+
λ
=
0
\sum_{j=1}^{m}\frac{p(x_j|\mu_i,\sum_i)}{\sum_{l=1}^k\alpha_l*p(x_j|\mu_l,\sum_l)}+\lambda=0
j=1∑m∑l=1kαl∗p(xj∣μl,∑l)p(xj∣μi,∑i)+λ=0两边同乘
α
i
\alpha_i
αi,对所有有样本求和可得
λ
=
−
m
\lambda=-m
λ=−m,有
∑
j
=
1
m
γ
j
i
+
λ
α
i
=
0
\sum_{j=1}^{m}\gamma_{ji}+\lambda\alpha_i=0
j=1∑mγji+λαi=0因此,
α
i
=
1
m
∑
j
=
1
m
γ
j
i
\alpha_i=\frac{1}{m}\sum_{j=1}^m\gamma_{ji}
αi=m1j=1∑mγji
高斯混合聚类算法的过程如下:

先确定混合而成分的个数,初始化混合分布的模型参数,基于ENM算法不断对模型参数进行迭代更新直到满足停止条件,根据确定的高斯混合分布进行簇划分后返回最终结果。
5、密度聚类
密度聚类亦称“基于密度的聚类”,此类算法假设聚类结构能通过样本分布的紧密程度确定。通常情形下,密度聚类算法从样本密度的角度来考察样本之间的可能性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果。
DBSCAN是一种著名的密度聚类算法,它基于一组"邻域"参数来刻画样本分布的紧密程度。给定数据集
D
=
D=
D={
x
1
,
x
2
,
…
…
,
x
m
x_1,x_2,……,x_m
x1,x2,……,xm},定义下面几个概念:
∙
\bullet
∙
ϵ
\epsilon
ϵ-邻域 :对于样本
x
j
∈
D
x_j \in D
xj∈D,与样本之间的距离小于等于
ϵ
\epsilon
ϵ的样本的集合称为它的
ϵ
\epsilon
ϵ-邻域
N
ϵ
=
{
x
i
∈
D
∣
d
i
s
t
(
x
i
,
x
j
)
≤
ϵ
}
N_\epsilon = \{x_i \in D | dist(x_i,x_j) \leq \epsilon\}
Nϵ={xi∈D∣dist(xi,xj)≤ϵ}。
∙
\bullet
∙ 核心对象:若
x
j
x_j
xj的
ϵ
\epsilon
ϵ-邻域包含的样本数超过
M
i
n
P
t
s
MinPts
MinPts个,则
x
j
x_j
xj是一个核心对象。
∙
\bullet
∙ 密度直达:若
x
j
x_j
xj位于
x
i
x_i
xi的
ϵ
\epsilon
ϵ-邻域中,且
x
i
x_i
xi是核心对象,则称
x
j
x_j
xj由
x
i
x_i
xi密度直达。
∙
\bullet
∙ 密度可达:对
x
i
x_i
xi与
x
j
x_j
xj,若存在样本序列
p
1
,
p
2
,
…
…
,
p
n
p_1,p_2,……,p_n
p1,p2,……,pn,其中
p
1
=
x
i
,
p
n
=
x
j
p_1=x_i,p_n=x_j
p1=xi,pn=xj且
p
i
+
1
p_{i+1}
pi+1由
p
i
p_i
pi密度直达,则称
x
j
x_j
xj由
x
i
x_i
xi密度可达。
∙
\bullet
∙ 密度相连:对
x
i
x_i
xi与
x
j
x_j
xj,若存在
x
k
x_k
xk使得
x
i
x_i
xi与
x
j
x_j
xj均由
x
k
x_k
xk密度可达,则称
z
i
z_i
zi与
x
j
x_j
xj密度相连。
基于这些概念,DBSCAN将簇定义为:由密度可达关系导出的最大的密度相连样本集合。给定邻域参数,簇
C
⊆
D
C\subseteq D
C⊆D是满足以下性质的非空样本子集:
连
接
性
:
x
i
∈
C
,
x
j
∈
C
⇒
x
i
与
x
j
密
度
相
连
最
大
性
:
x
i
∈
C
,
x
j
由
x
i
密
度
可
达
⇒
x
j
∈
C
连接性:x_i\in C,x_j\in C\Rightarrow x_i与x_j密度相连\\最大性: x_i\in C,x_j由x_i密度可达\Rightarrow x_j\in C
连接性:xi∈C,xj∈C⇒xi与xj密度相连最大性:xi∈C,xj由xi密度可达⇒xj∈C
那么,如何从数据集D中找出满足以上性质的聚类簇呢?实际上,若x为核心对象,由x密度可达的所有样本组成的结合记为
X
=
X=
X={
x
′
∈
D
∣
x
′
由
x
密
度
可
达
x^{'}\in D|x^{'}由x密度可达
x′∈D∣x′由x密度可达},则不难证明X即为满足连接性与最大性的簇。
DBSCAN先任选数据集中的一个核心对象为“种子”,在由此出发确定相应的聚类簇。具体过程如下:
先根据给定的邻域参数
(
ϵ
,
M
i
n
P
t
s
)
(\epsilon,MinPts)
(ϵ,MinPts)找出所有核心对象,确定核心对象集
Ω
\Omega
Ω,然后随机选取一个核心对象找出由它密度可达的所有样本,这样我们就构成了第一个聚类簇。然后将聚类簇中包含的核心对象从
Ω
\Omega
Ω中去掉,再从更新后的
Ω
\Omega
Ω中随机选取种子来生成下一个聚类簇。上述过程不断重复,直到
Ω
\Omega
Ω为空。
6、层次聚类
层次聚类试图在不同层次对数据集进行划分, 从而形成树形的聚类结构。数据集的划分可采用“自底向上”的聚合策略,也可采用“自顶向下”的分拆策略。
AGNES是一种采用自底向上聚合策略的层次聚类算法,它先将数据集中的每一个样本看作一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个聚类簇进行合并,该过程不断重复,直至达到预设的聚类簇个数。关键在于如何计算聚类簇之间的距离,实际上,每个簇是一个样本集合,因此,只需采用关于集合的某种距离即可。例如,给定聚类簇
c
i
c_i
ci和
c
j
c_j
cj,可通过下面的式子来计算距离:
最
小
距
离
:
d
m
i
n
=
(
C
i
,
C
j
)
=
m
i
n
x
∈
C
i
,
z
∈
C
j
d
i
s
t
(
x
,
z
)
最
大
距
离
:
d
m
a
x
(
C
i
,
C
j
)
=
m
a
x
x
∈
C
i
,
z
∈
C
j
d
i
s
t
(
x
,
z
)
平
均
距
离
:
d
a
v
g
(
C
i
,
C
j
)
=
1
∣
C
i
∣
∣
C
j
∣
∑
x
∈
C
i
∑
z
∈
C
j
d
i
s
t
(
x
,
z
)
最小距离:d_{min}=(C_i,C_j)=\underset{x\in C_i,z\in C_j}{min}dist(x,z)\\ 最大距离:d_{max}(C_i,C_j)=\underset{x\in C_i,z\in C_j}{max}dist(x,z)\\ 平均距离:d_{avg}(C_i,C_j)=\frac{1}{|C_i||C_j|}\sum_{x\in C_i}\sum_{z\in C_j}dist(x,z)
最小距离:dmin=(Ci,Cj)=x∈Ci,z∈Cjmindist(x,z)最大距离:dmax(Ci,Cj)=x∈Ci,z∈Cjmaxdist(x,z)平均距离:davg(Ci,Cj)=∣Ci∣∣Cj∣1x∈Ci∑z∈Cj∑dist(x,z)
显然,最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定,而平均距离则由两个簇的所有样本共同决定。当聚类簇距离由
d
m
i
n
、
d
m
a
x
、
d
a
v
g
d_{min}、d_{max}、d_{avg}
dmin、dmax、davg计算时,AGNES算法相应地被称为"单链接"、“全连接”、或“均链接”算法
AGNES算法的具体流程如下:

先对仅含一个样本的初始聚类簇和相应的距离矩阵进行初始化,然后不断合并距离最近的聚类簇并对合并得到的聚类簇的距离矩阵进行更新,不断重复,直至达到预设的聚类簇数。














 2630
2630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









