







1.缺失值处理
SparkSQL提供了DataFrameNaFunctions缺失值处理框架,使用Dataset的na函数来获取
(1)如何使用 SparkSQL 处理 null 和 NaN ?
首先要将数据读取出来, 此次使用的数据集直接存在 NaN, 在指定 Schema 后, 可直接被转为 Double.NaN
val schema = StructType(
List(
StructField("id", IntegerType),
StructField("year", IntegerType),
StructField("month", IntegerType),
StructField("day", IntegerType),
StructField("hour", IntegerType),
StructField("season", IntegerType),
StructField("pm", DoubleType)
)
)
val df = spark.read
.option("header", value = true)
.schema(schema)
.csv("dataset/beijingpm_with_nan.csv")
1.丢弃包含 null 和 NaN 的行
- 当某行数据所有值都是 null 或者 NaN 的时候丢弃此行
df.na.drop("all").show()
- 当某行中特定列所有值都是 null 或者 NaN 的时候丢弃此行
df.na.drop("all", List("pm", "id")).show()
- 当某行数据任意一个字段为 null 或者 NaN 的时候丢弃此行
df.na.drop().show()//这个和下面的指定any是等价的
df.na.drop("any").show()//any是一行数据只要有一个nan就丢弃
- 当某行中特定列任意一个字段为 null 或者 NaN 的时候丢弃此行
df.na.drop(List("pm", "id")).show()
df.na.drop("any", List("pm", "id")).show()
2.填充包含 null 和 NaN 的列
- 填充所有包含 null 和 NaN 的列
df.na.fill(0).show()
- 填充特定包含 null 和 NaN 的列
df.na.fill(0, List("pm")).show()
- 根据包含 null 和 NaN 的列的不同来填充
import scala.collection.JavaConverters._
df.na.fill(Map[String, Any]("pm" -> 0).asJava).show
(2)如何使用 SparkSQL 处理异常字符串 ?
- 读取数据集, 这次读取的是最原始的那个 PM 数据集
val df = spark.read
.option("header", value = true)
.csv("dataset/BeijingPM20100101_20151231.csv")
- 使用函数直接转换非法的字符串
df.select('No as "id", 'year, 'month, 'day, 'hour, 'season,
when('PM_Dongsi === "NA", 0) //字段下是NA的值,把NA转换为0
.otherwise('PM_Dongsi cast DoubleType)//如果是不是NA值,把正常值转为DoubleType类型
.as("pm"))
.show()
- 使用 where 直接过滤
df.select('No as "id", 'year, 'month, 'day, 'hour, 'season, 'PM_Dongsi)
.where('PM_Dongsi =!= "NA")
.show()
- 使用 DataFrameNaFunctions 替换, 但是这种方式被替换的值和新值必须是同类型
df.select('No as "id", 'year, 'month, 'day, 'hour, 'season, 'PM_Dongsi)
.na.replace("PM_Dongsi", Map("NA" -> "NaN"))
.show()
2.聚合操作
(1)groupBy
groupBy 算子会按照列将 Dataset 分组, 并返回一个 RelationalGroupedDataset 对象, 通过 RelationalGroupedDataset 可以对分组进行聚合
//创建sparksession
private val spark = SparkSession.builder()
.master("local[6]")
.appName("aggregation")
.getOrCreate()
import spark.implicits._
//读取数据
private val schema = StructType(
List(
StructField("id", IntegerType),
StructField("year", IntegerType),
StructField("month", IntegerType),
StructField("day", IntegerType),
StructField("hour", IntegerType),
StructField("season", IntegerType),
StructField("pm", DoubleType)
)
)
private val pmDF = spark.read
.schema(schema)
.option("header", value = true)
.csv("dataset/pm_without_null.csv")
//使用functions函数来完成聚合
import org.apache.spark.sql.functions._
val groupedDF: RelationalGroupedDataset = pmDF.groupBy('year)
groupedDF.agg(avg('pm) as "pm_avg")//聚合, 可以使用 sql.functions 中的函数来配合进行操作
.orderBy('pm_avg)
.show()
//5. 除了使用 functions 进行聚合, 还可以直接使用 RelationalGroupedDataset 的 API 进行聚合
groupedDF.avg("pm")
.orderBy('pm_avg)
.show()
groupedDF.max("pm")
.orderBy('pm_avg)
.show()
(2)使用groupBy实现多维度聚合
一个数据结果集,包含总计,小计(不同维度的聚合操作)
import org.apache.spark.sql.functions._
//不同年,不同来源PM值得总数
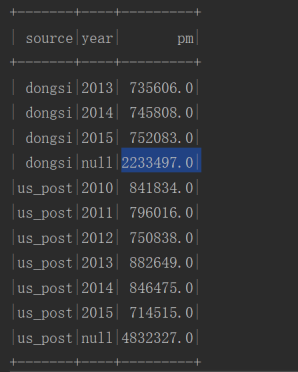
val groupPostAndYear = pmFinal.groupBy('source, 'year)
.agg(sum("pm") as "pm")//聚合, 可以使用 sql.functions 中的函数来配合进行操作
//按照不同数据源来统计PM值得总数
val groupPost = pmFinal.groupBy('source)
.agg(sum("pm") as "pm")//聚合, 可以使用 sql.functions 中的函数来配合进行操作
.select('source, lit(null) as "year", 'pm)//lit(null) 把null显示为一列
groupPostAndYear.union(groupPost) //将两个不同维度的结果集合并在一起
.sort('source, 'year asc_nulls_last, 'pm)
.show()
(2)rollup
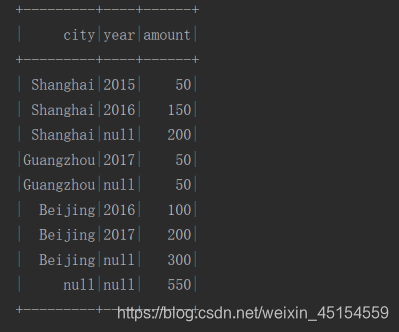
rollup 操作符其实就是 groupBy 的一个扩展, rollup 会对传入的列进行滚动 groupBy, groupBy 的次数为列数量 + 1, 最后一次是对整个数据集进行聚合
rollup(A,B) ==> group(A,null) + group(A,B) + group(null)
import org.apache.spark.sql.functions._
val sales = Seq(
("Beijing", 2016, 100),
("Beijing", 2017, 200),
("Shanghai", 2015, 50),
("Shanghai", 2016, 150),
("Guangzhou", 2017, 50)
).toDF("city", "year", "amount")
sales.rollup("city", "year")
.agg(sum("amount") as "amount")//聚合, 可以使用 sql.functions 中的函数来配合进行操作
.sort('city.desc_nulls_last, 'year.asc_nulls_last)
.show()
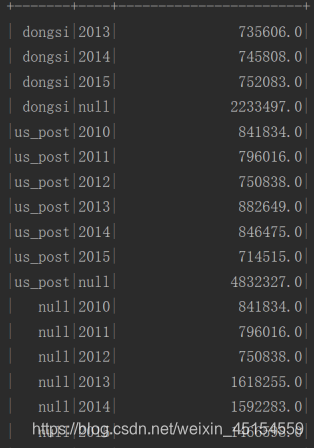
(3)cube
import org.apache.spark.sql.functions._
pmFinal.cube('source, 'year)
.agg(sum("pm") as "pm_total")
.sort('source.asc_nulls_last, 'year.asc_nulls_last)
.show()

(4)SparkSQL 中支持的 SQL 语句实现 cube 功能
pmFinal.createOrReplaceTempView("pm_final")//表名称
spark.sql(
"""
|select source, year, sum(pm)
|from pm_final
|group by source, year
|grouping sets((source, year), (source), (year), ())//实现cube功能,grouping sets等效于多个group by后数据做union合并操作,使用前必须先用group by拆分一下在用
|order by source asc nulls last, year asc nulls last
""".stripMargin)
.show()
3.连接操作
(1)使用场景
- 一种是把两张表在逻辑上连接起来, 一条语句中同时访问两张表
- 还有一种方式就是表连接自己, 一条语句也能访问自己中的多条数据
(2)无类型连接 join
表1.join(表2,表1.连接字段==表2.连接字段,连接类型)
(3)示例
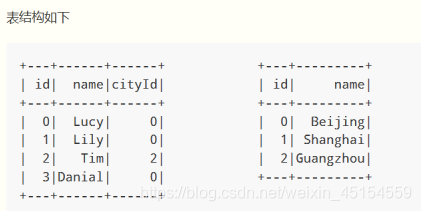
val person = Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 0))
.toDF("id", "name", "cityId")
val cities = Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou"))
.toDF("id", "name")
person.join(cities, person.col("cityId") === cities.col("id"))
.select(person.col("id"),
person.col("name"),
cities.col("name") as "city")
.show()

(3)连接类型 Join Types
1.交叉连接cross
交叉连接就是笛卡尔积, 就是两个表中所有的数据两两结对
交叉连接是一个非常重的操作, 在生产中, 尽量不要将两个大数据集交叉连接, 如果一定要交叉连接, 也需要在交叉连接后进行过滤, 优化器会进行优化
SQL 语句
select * from person cross join cities
Dataset 操作
person.crossJoin(cities)
.where(person.col("cityId") === cities.col("id"))
.show()
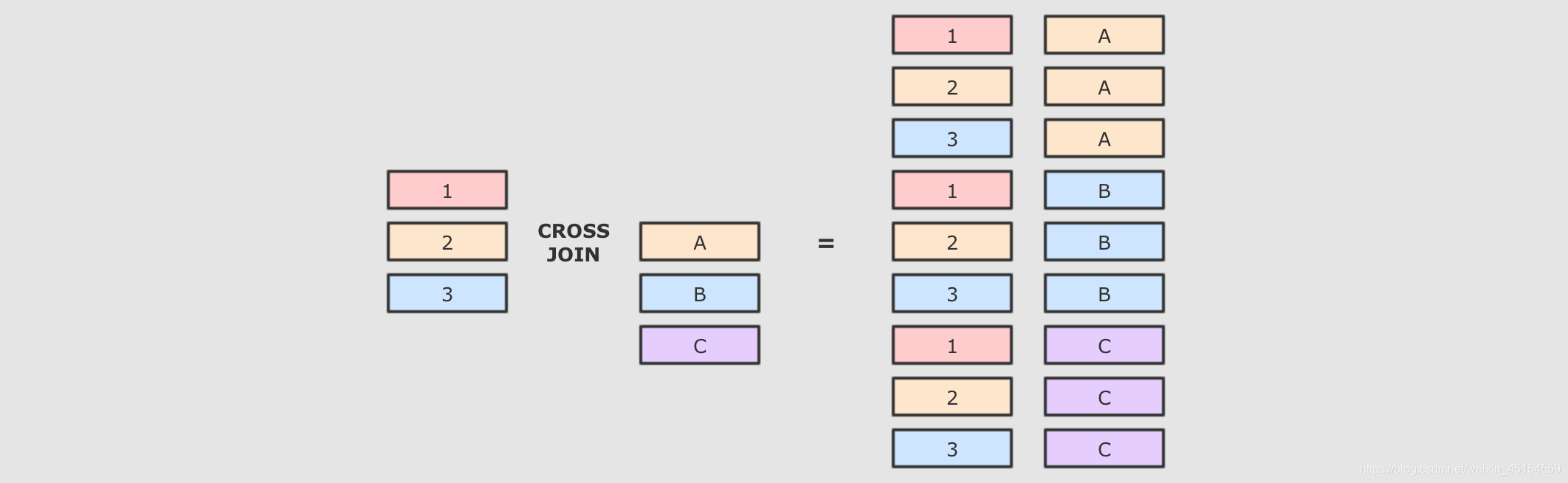
2.内连接inner
内连接就是按照条件找到两个数据集关联的数据, 并且在生成的结果集中只存在能关联到的数据
SQL 语句
select * from person inner join cities on person.cityId = cities.id
Dataset 操作
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "inner")
.show()

3.全外连接outer, full, fullouter
内连接和外连接的最大区别, 就是内连接的结果集中只有可以连接上的数据, 而外连接可以包含没有连接上的数据, 根据情况的不同, 外连接又可以分为很多种, 比如所有的没连接上的数据都放入结果集, 就叫做全外连接
SQL 语句
select * from person full outer join cities on person.cityId = cities.id
Dataset 操作
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "full") // "outer", "full", "full_outer"这三个都可以,都是全外连接
.show()

(4)左外连接
左外连接是全外连接的一个子集, 全外连接中包含左右两边数据集没有连接上的数据, 而左外连接只包含左边数据集中没有连接上的数据

SQL 语句
select * from person left join cities on person.cityId = cities.id
Dataset 操作
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "left")
.show()
(5)右外连接
右外连接和左外连接刚好相反, 左外是包含左侧未连接的数据, 和两个数据集中连接上的数据, 而右外是包含右侧未连接的数据, 和两个数据集中连接上的数据
SQL 语句
select * from person right join cities on person.cityId = cities.id
Dataset 操作
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "right") // rightouter, right
.show()

4.UDF
(1)UDF使用场景
UDF:User Defined Function,用户自定义函数。
我们在使用sparkSQL的sql语句对表进行操作时,想要对有些字段使用自己自定义的函数对指定的数据对象进行操作时,可以使用udf对自定义的函数进行注册,注册过后的函数就可以在saprkSQL的sql语句中使用.
(2)UDF用法
1.通过匿名函数注册UDF
下面的UDF的功能是计算某列的长度,该列的类型为String
org.apache.spark.sql
spark.udf.register("strLen", (str: String) => str.length())//这种的就属于匿名函数注册
spark.sql("select name,strLen(name) as name_len from user").show

2.通过实名函数注册UDF
实名函数的注册有点不同,要在后面加 _(注意前面有个空格)
定义一个实名函数,然后对其进行注册
/**
* 根据年龄大小返回是否成年 成年:true,未成年:false
*/
def isAdult(age: Int) = { //这种就属于实名函数
if (age < 18) {
false
} else {
true
}
}
org.apache.spark._
spark.udf.register("isAdult", isAdult _)
(3)示例
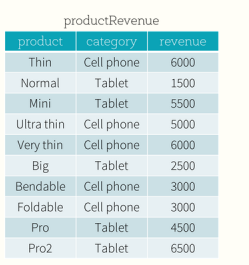
需求:revenue这一列是int类型,变为字符串型,例如:我要6000变为6k这样的字符串
import org.apache.spark._
val toStrUDF = udf(tostring _) // _表示其余的参数
//或者这样
spark.udf.register("toStrUDF",tostring _)//实名函数(有函数名称的定义def tostring)要加_ 匿名函数(无def 名称的这类)不加_
source.select('product,'category,toStrUDF('revenue))
.show()
def tostring(revenue:Int){
(revenue/1000)+"k"
}
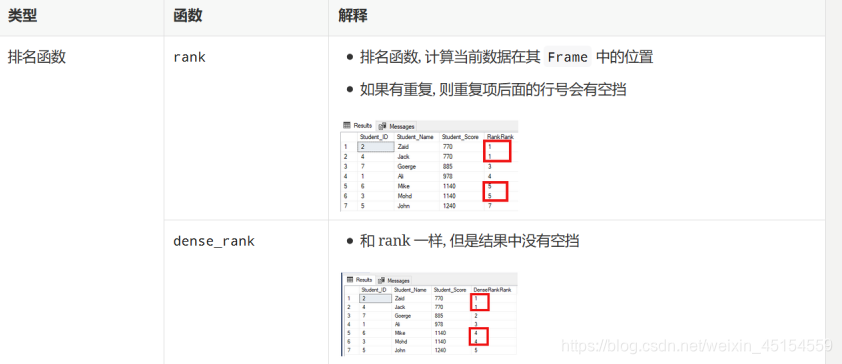
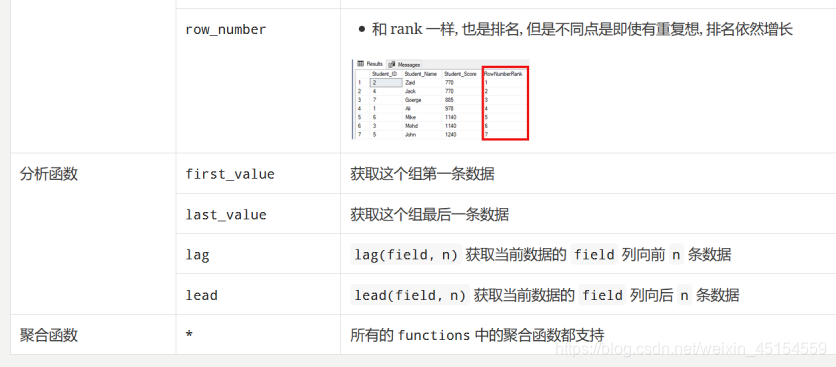
5.窗口函数
(1)窗口函数的使用场景
窗口函数分为两个部分:1.窗口定义部分2.函数部分
窗口函数和 GroupBy 最大的区别, 就是 GroupBy 的聚合对每一个组只有一个结果例如:source.groupBy('xxx).agg(sum('yyy))最后我们得到一个x组下y的累加值, 而窗口函数可以对每一条数据都有一个结果
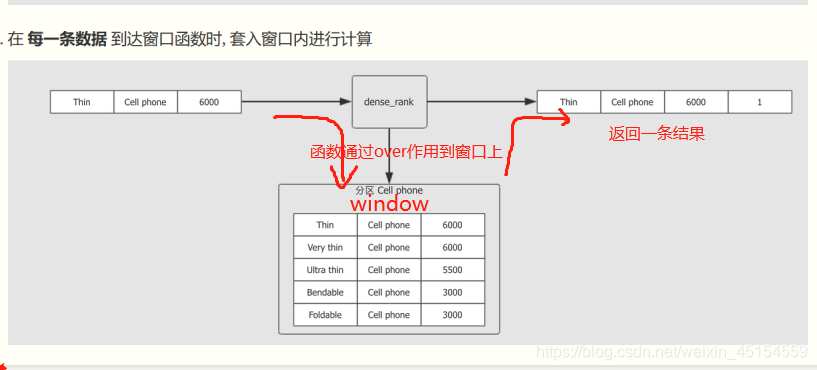

(2)示例
import org.apache.spark.sql.expressions.{Window, WindowSpec}
import org.apache.spark.sql.{Dataset, SaveMode, SparkSession}
import org.junit.Test
class WindowFunction {
@Test
def firstSecond(): Unit = {
val spark = SparkSession.builder()
.appName("window")
.master("local[6]")
.getOrCreate()
import spark.implicits._
val data = Seq(
("Thin", "Cell phone", 6000),
("Normal", "Tablet", 1500),
("Mini", "Tablet", 5500),
("Ultra thin", "Cell phone", 5000),
("Very thin", "Cell phone", 6000),
("Big", "Tablet", 2500),
("Bendable", "Cell phone", 3000),
("Foldable", "Cell phone", 3000),
("Pro", "Tablet", 4500),
("Pro2", "Tablet", 6500)
)
val source = data.toDF("product", "category", "revenue")
val window: WindowSpec = Window.partitionBy('category)//先进行分组,在降序排序
.orderBy('revenue.desc)
import org.apache.spark.sql.functions._
source.select('product, 'category, 'revenue, dense_rank() over window as "rank")//dense_rank生成
.where('rank <= 2)
.show()
}
}
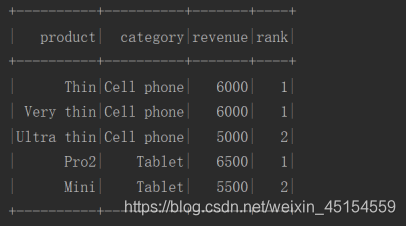
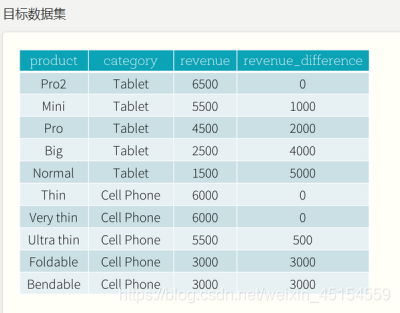
(3)示例2

//1.创建数据集
val spark = SparkSession.builder()
.appName("window")
.master("local[6]")
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val data = Seq(
("Thin", "Cell phone", 6000),
("Normal", "Tablet", 1500),
("Mini", "Tablet", 5500),
("Ultra thin", "Cell phone", 5500),
("Very thin", "Cell phone", 6000),
("Big", "Tablet", 2500),
("Bendable", "Cell phone", 3000),
("Foldable", "Cell phone", 3000),
("Pro", "Tablet", 4500),
("Pro2", "Tablet", 6500)
)
val source = data.toDF("product", "category", "revenue")
//创建窗口, 按照 revenue 分组, 并倒叙排列
val windowSpec = Window.partitionBy('category)
.orderBy('revenue.desc)
//应用窗口
source.select(
'product, 'category, 'revenue,
((max('revenue) over windowSpec) - 'revenue) as 'revenue_difference
).show()














 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









