






部署Hdfs + Mapreduce分布式计算存储集群
一、环境
 hadoop版本>=2.7:要求Java 7(openjdk/oracle)
hadoop版本>=2.7:要求Java 7(openjdk/oracle)
hadoop版本<=2.6:要求Java 6(openjdk/oracle)
二、步骤
3.1 配置所有节点间的域名解析及创建用户(所有节点配置相同,在此列举master节点配置);
3.2 配置master节点远程管理slave节点;
3.3 在所有节点安装JDK环境(所有节点配置相同,在此列举master节点配置);
3.4 在所有节点安装Hadoop并简要配置(所有节点配置相同,在此列举master节点配置);
3.5 在master节点进行配置hadoop服务,并将配置文件复制到slave节点上;
3.6 在master节点初始化并且启动Hadoop进程;
3.7 验证slave节点的进程状态;
3.8 网页查看http://master:50070统计hdfs集群的信息;
3.9 Hdfs中数据的基本管理;
3.10 测试Mapreduce计算框架与Hdfs的协同工作;
3.11 网页方式查看ResourceManager进程的计算结果;
3.12 动态扩展HDFS内部datanode节点;
三、操作
3.1 配置所有节点间的域名解析及创建用户(所有节点配置相同,在此列举master节点配置);
[root@master ~]# hostnamectl set-hostname master
[root@master ~]# cat <<END >>/etc/hosts
192.168.100.101 master
192.168.100.102 slave1
192.168.100.103 slave2
END
[root@master ~]# useradd hadoop
[root@master ~]# echo "hadoop" |passwd --stdin hadoop
3.2 配置master节点远程管理slave节点;
[root@master ~]# su - hadoop
上一次登录:四 5月 31 01:54:26 CST 2018pts/0 上
[hadoop@master ~]$ ssh-keygen -t rsa
[hadoop@master ~]$ ssh-copy-id hadoop@192.168.100.101
[hadoop@master ~]$ ssh-copy-id hadoop@192.168.100.102
[hadoop@master ~]$ ssh-copy-id hadoop@192.168.100.103
[hadoop@master ~]$ ssh hadoop@master ##远程连接slave节点,进行确认key值文件,不然在启动hadoop时,会出现key的问题导致无法启动
[hadoop@master ~]$ ssh hadoop@slave1
[hadoop@master ~]$ ssh hadoop@slave2
3.3 在所有节点安装JDK环境(所有节点配置相同,在此列举master节点配置);
> [hadoop@master ~]$ exit [root@master ~]# tar zxvf
> jdk-8u171-linux-x64.tar.gz [root@master ~]# mv /root/jdk1.8.0_171/
> /usr/local/java/ [root@master ~]# ls /usr/local/java/ [root@master ~]#
> cat <<END >>/etc/profile JAVA_HOME=/usr/local/java/
> JRE_HOME=\$JAVA_HOME/jre
> CLASS_PATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar:\$JAVA_HOME/lib
> PATH=\$PATH:\$JAVA_HOME/bin:\$JRE_HOME/bin export JAVA_HOME JRE_HOME
> CLASS_PATH PATH END [root@master ~]# source /etc/profile [root@master
> ~]# java -version java version "1.8.0_171"
3.4 在所有节点安装Hadoop并简要配置(所有节点配置相同,在此列举master节点配置);
[root@master ~]# tar zxvf hadoop-2.7.6.tar.gz
[root@master ~]# mv /root/hadoop-2.7.6/ /usr/local/hadoop/
[root@master ~]# ls /usr/local/hadoop/
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[root@master ~]# cat <<END >>/etc/profile
export HADOOP_HOME=/usr/local/hadoop/
export PATH=\$PATH:\$HADOOP_HOME/bin
END
[root@master ~]# source /etc/profile
[root@master ~]# echo "export JAVA_HOME=/usr/local/java/" >>/usr/local/hadoop/etc/hadoop/hadoop-env.sh
##设置HDFS存储加载jdk的环境变量
[root@master ~]# echo "export JAVA_HOME=/usr/local/java/" >>/usr/local/hadoop/etc/hadoop/yarn-env.sh
##设置mapreduce的V2版本--YARN加载jdk的环境变量
[root@master ~]# mkdir /usr/local/hadoop/name/ ##存放namenode中元数据的位置
[root@master ~]# mkdir /usr/local/hadoop/data/ ##存放datanode中的数据目录,通常企业内部此目录是独立挂载的磁盘设备,作为hdfs的存储设备
[root@master ~]# mkdir /usr/local/hadoop/tmp/ ##存放用户临时文件
[root@master ~]# mkdir /usr/local/hadoop/var/ ##存放服务动态变化文件
[root@master ~]# chown hadoop /usr/local/hadoop/ -R
3.5 在master节点进行配置hadoop服务,并将配置文件复制到slave节点上;
[root@master ~]# su - hadoop
[hadoop@master ~]$ vi /usr/local/hadoop/etc/hadoop/core-site.xml ##指定名称节点namenode的相关配置(名称空间节点:管理元数据信息)
<configuration>
<property>
<name>hadoop.tmp.dir</name> ##临时目录在哪(name为名称)
<value>/usr/local/hadoop/tmp</value> ##绝对路径(value为值)自己创建
<description>Abase for other temporary directories.</description> ##(description为描述即解释)
</property>
<property>
<name>fs.default.name</name> ##名称空间节点的访问路径
<value>hdfs://master:9000</value> ##主机:端口
</property>
</configuration>
[hadoop@master ~]$ vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml ##指定hdfs存储的相关配置
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name> ##从名称空间节点的地址
<value>master:50090</value> ##位置(从名称空间节点的端口)
</property>
<property>
<name>dfs.name.dir</name> ##分布式名称的目录(自己创建)
<value>/usr/local/hadoop/name</value> ##位置
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description> ##把日志和名称空间的数据存放在这个目录里
</property>
<property>
<name>dfs.data.dir</name> ##数据存放位置
<value>/usr/local/hadoop/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name> ##每一个数据备份几份(复制几份)
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name> ##启用web页面
<value>true</value>
</property>
</configuration>
[hadoop@master ~]$ cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml ##修改mapreduce配置文件,将其改为YARN模型
[hadoop@master ~]$ vi /usr/local/hadoop/etc/hadoop/mapred-site.xml ##指定MapR的相关配置
<configuration>
<property>
<name>mapred.job.tracker</name> ##
<value>master:49001</value>
</property>
<property>
<name>mapred.local.dir</name> ##mapred的本地目录
<value>/usr/local/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name> ##mapred的计算框架
<value>yarn</value>
</property>
</configuration>
[hadoop@master ~]$ vi /usr/local/hadoop/etc/hadoop/slaves ##指定slave的名称
slave1
slave2
附:此文件明确指定DataNode节点,可以通过节点的添加和减少来满足整个hadoop群集的伸缩性,添加节点时,首先将新节点的配置保证与NameNode节点配置相同,在此文件指定新的DataNode节点名,重新启动NameNode便完成。但为保证原有DataNode节点与新添加DataNode节点的数据进行均衡存储,需要执行此命令进行重新平衡数据块的分布:/usr/local/hadoop/sbin/start-balancer.sh
[hadoop@master ~]$ vi /usr/local/hadoop/etc/hadoop/yarn-site.xml ##指定YARN的相关配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name> ##yarn的节点管理要用
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> ##
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name> ##资源
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name> ##资源管理器的调度器
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name> ##跟踪的地址
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name> ##管理地址
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name> ##webapp的端口
<value>master:8088</value>
</property>
</configuration>
复制配置文件:
[hadoop@master ~]$ scp -r /usr/local/hadoop/etc/hadoop/* hadoop@192.168.100.102:/usr/local/hadoop/etc/hadoop/
[hadoop@master ~]$ scp -r /usr/local/hadoop/etc/hadoop/* hadoop@192.168.100.103:/usr/local/hadoop/etc/hadoop/
另一个安装思路:
除创建用户外,以上所有步骤都在master完成,然后执行如下命令同步到其他节点:
[hadoop@master ~]$ for i in 102 103;do rsync -av /usr/local/ root@192.168.100.$i:/usr/local/;done
[hadoop@master ~]$ for i in 102 103;do rsync -av /etc/profile root@192.168.100.$i:/etc/profile;done
然后在xshell全部会话框中执行:source /etc/profile
如果需要添加新的服务器节点,也可以用不同的方式去扩展集群。
3.6 在master节点初始化并且启动Hadoop进程
[hadoop@master ~]$ /usr/local/hadoop/bin/hdfs namenode -format
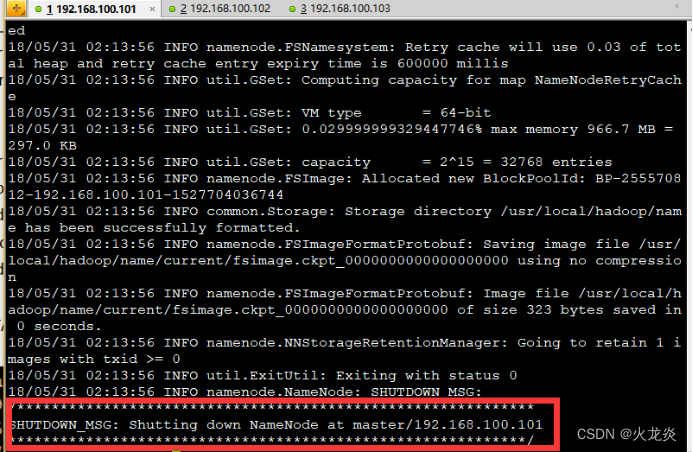
[hadoop@master ~]$ ls /usr/local/hadoop/name/ ##初始化所生成的名称节点文件,此文件是Secondary Namenode进程所备份namenode节点的内存中元数据产生的;
current
注:第一次执行格式化,提示信息如上图,如若第二次再次执行格式化,需要将namenode节点的/usr/local/hadoop/name/目录内容清空,并且将datanode节点的/usr/local/hadoop/data/目录清空,方可再次执行格式化,否则会造成namenode节点与datanode节点的数据版本ID不一致,导致启动服务失败;
[hadoop@master ~]$ /usr/local/hadoop/sbin/start-all.sh ##启动hadoop的所有进程
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-master.out
slave2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave2.out
slave1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave1.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-resourcemanager-master.out
slave2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave2.out
slave1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave1.out
注:/usr/local/hadoop/sbin/start-all.sh命令等于/usr/local/hadoop/sbin/start-dfs.sh加/usr/local/hadoop/sbin/start-yarn.sh,前者启动hdfs系统,后者启动mapreduce调度工具,关闭两进程的命令为/usr/local/hadoop/sbin/stop-all.sh
[hadoop@master ~]$ netstat -utpln
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 7266/java ##namenode进程的http端口
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN -
tcp 0 0 192.168.100.101:8088 0.0.0.0:* LISTEN 7623/java
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN -
tcp 0 0 192.168.100.101:8030 0.0.0.0:* LISTEN 7623/java
tcp 0 0 192.168.100.101:8032 0.0.0.0:* LISTEN 7623/java
tcp 0 0 192.168.100.101:8033 0.0.0.0:* LISTEN 7623/java
tcp 0 0 192.168.100.101:8035 0.0.0.0:* LISTEN 7623/java
tcp 0 0 192.168.100.101:9000 0.0.0.0:* LISTEN 7266/java ##客户端连接hdfs系统时用到的端口
tcp 0 0 192.168.100.101:50090 0.0.0.0:* LISTEN 7467/java ## secondary namenode进程的http端口
[hadoop@master ~]$ /usr/local/hadoop/bin/hdfs dfsadmin -report ##查看hadoop存储节点的状态信息
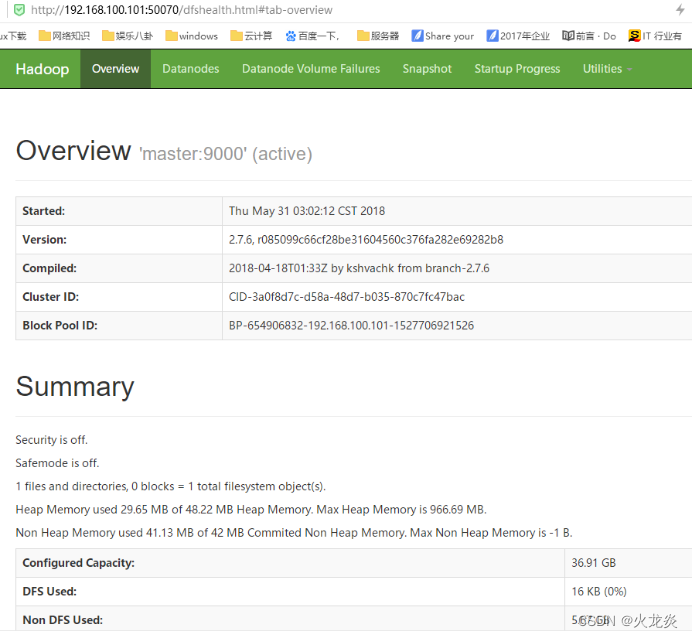
Configured Capacity: 39631978496 (36.91 GB)
Present Capacity: 33541480448 (31.24 GB)
DFS Remaining: 33541472256 (31.24 GB)
DFS Used: 8192 (8 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
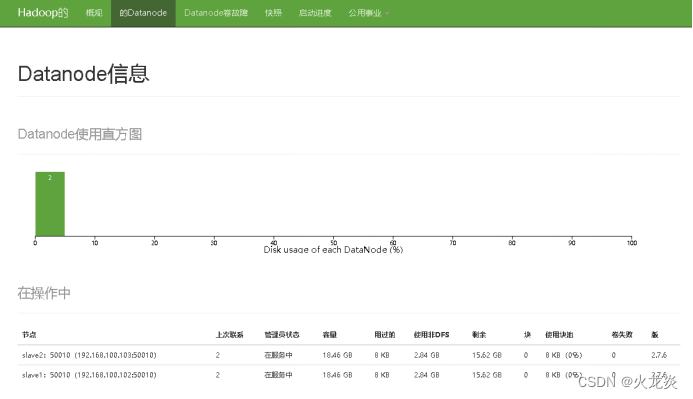
Live datanodes (2):
Name: 192.168.100.103:50010 (slave2)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: 19815989248 (18.46 GB)
DFS Used: 4096 (4 KB)
Non DFS Used: 3045191680 (2.84 GB)
DFS Remaining: 16770793472 (15.62 GB)
DFS Used%: 0.00%
DFS Remaining%: 84.63%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu May 31 03:03:09 CST 2018
Name: 192.168.100.102:50010 (slave1)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: 19815989248 (18.46 GB)
DFS Used: 4096 (4 KB)
Non DFS Used: 3045306368 (2.84 GB)
DFS Remaining: 16770678784 (15.62 GB)
DFS Used%: 0.00%
DFS Remaining%: 84.63%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu May 31 03:03:09 CST 2018
[hadoop@master ~]$ jps
7266 NameNode ##namenode节点主进程
7623 ResourceManager ##mapreduce管理进程
7467 SecondaryNameNode ##namenode的备份进程,避免namenode进程意外停止,客户端无法读写数据
7883 Jps

3.7 验证slave节点的进程状态;
[root@slave1 ~]$ su - hadoop
[hadoop@slave1 ~]$ netstat -utpln
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:13562 0.0.0.0:* LISTEN 3391/java
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 3274/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 3274/java
tcp 0 0 0.0.0.0:39938 0.0.0.0:* LISTEN 3391/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 3274/java
tcp 0 0 127.0.0.1:38373 0.0.0.0:* LISTEN 3274/java
tcp 0 0 0.0.0.0:8040 0.0.0.0:* LISTEN 3391/java
tcp 0 0 0.0.0.0:8042 0.0.0.0:* LISTEN 3391/java
[hadoop@slave1 ~]$ jps
3526 Jps
3274 DataNode
3391 NodeManager ##与namenode执行心跳信息的节点进程

3.8 网页查看http://master:50070统计hdfs集群的信息;
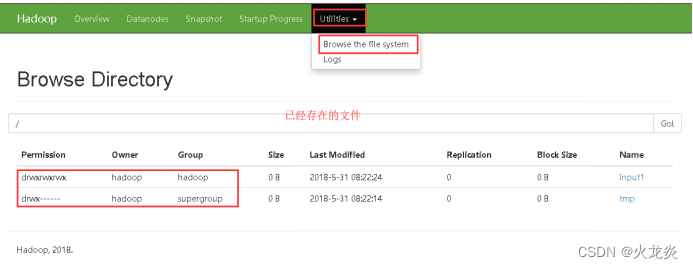

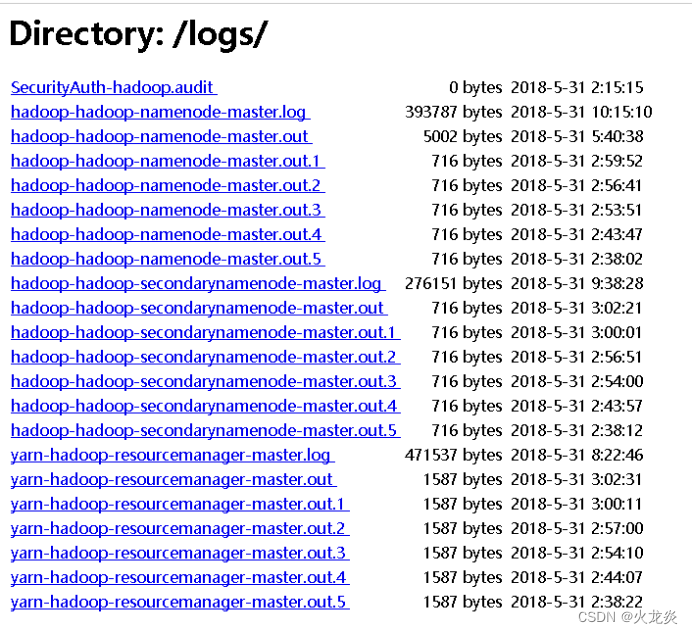
3.9 Hdfs中数据的基本管理;
> [hadoop@master ~]$ pwd /home/hadoop [hadoop@master ~]$ touch 1.file
> [hadoop@master ~]$ ls
> 1.file [hadoop@master ~]$ hadoop fs -ls file:///home/hadoop/ ##查看本地文件 [hadoop@master ~]$ hadoop fs -ls
> / ##查看hadoop文件 [hadoop@master ~]$ hadoop fs -mkdir /input1
> [hadoop@master ~]$ hadoop fs -put /home/hadoop/1.file
> /input1 ##上传本地文件 [hadoop@master ~]$ hadoop fs -ls /input1 Found 1
> items
> -rw-r--r-- 2 hadoop supergroup 0 2018-05-31 07:38 /input1/1.file [hadoop@master ~]$ hadoop fs -cat
> /input1/1.file ##查看hadoop文件内容 [hadoop@master ~]$ hadoop fs -cat
> file:///home/hadoop/1.file ##查看本地文件内容 [hadoop@master ~]$ hadoop fs
> -get /input1/1.file /tmp ##下载hadoop文件 [hadoop@master ~]$ ls /tmp/
> 1.file [hadoop@master ~]$ hadoop fs -mkdir /input2 [hadoop@master ~]$ hadoop fs -mv /input1/1.file /input2/1.txt [hadoop@master ~]$ hadoop
> fs -ls /input2 Found 1 items
> -rw-r--r-- 2 hadoop supergroup 0 2018-05-31 07:38 /input2/1.txt [hadoop@master ~]$ hadoop fs -cp /input2/1.txt
> /input2/2.txt [hadoop@master ~]$ hadoop fs -ls /input2 Found 2 items
> -rw-r--r-- 2 hadoop supergroup 0 2018-05-31 07:38 /input2/1.txt
> -rw-r--r-- 2 hadoop supergroup 0 2018-05-31 08:01 /input2/2.txt [hadoop@master ~]$ hadoop fs -rm
> /input2/2.txt ##删除单个文件 18/05/31 08:01:40 INFO fs.TrashPolicyDefault:
> Namenode trash configuration: Deletion interval = 0 minutes, Emptier
> interval = 0 minutes. Deleted /input2/2.txt [hadoop@master ~]$ hadoop
> fs -ls /input2 Found 1 items
> -rw-r--r-- 2 hadoop supergroup 0 2018-05-31 07:38 /input2/1.txt [hadoop@master ~]$ hadoop fs -rmr /input2/ ##递归删除目录
> rmr: DEPRECATED: Please use 'rm -r' instead. 18/05/31 08:06:23 INFO
> fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval
> = 0 minutes, Emptier interval = 0 minutes. Deleted /input2 [hadoop@master ~]$ hadoop fs -ls / Found 1 items drwxr-xr-x - hadoop
> supergroup 0 2018-05-31 07:58 /input1 [hadoop@master ~]$
> hadoop fs -test -e /input1/ ##查看文件或目录是否存在,存在返回值为0,不存在返回值为1
> [hadoop@master ~]$ echo $? 0 [hadoop@master ~]$ hadoop fs -test -e
> /input1/2.file [hadoop@master ~]$ echo $? 1 [hadoop@master ~]$ hadoop
> fs -du /input1 ##查看目录中文件的所有文件的大小 0 /input1/2.file._COPYING_
> [hadoop@master ~]$ hadoop fs -du -s /input1 ##查看目录本身的大小 0 /input1
> [hadoop@master ~]$ hadoop fs -expunge ##清空回收站 [hadoop@master ~]$
> hadoop fs -chmod 777 /input1 [hadoop@master ~]$ hadoop fs -chown
> hadoop:hadoop /input1 [hadoop@master ~]$ hadoop fs -ls / Found 1 items
> drwxrwxrwx - hadoop hadoop 0 2018-05-31 07:58 /input1
3.10 测试Mapreduce计算框架与Hdfs的协同工作;
[hadoop@master ~]$ hadoop fs -rmr /input1
[hadoop@master ~]$ hadoop fs -ls /
[hadoop@master ~]$ cat <<END >>/home/hadoop/1.txt ##编辑测试计算文件
hello
bye
head
foot tree tree
haha
END
[hadoop@master ~]$ hadoop fs -mkdir /input
[hadoop@master ~]$ hadoop fs -ls /input
[hadoop@master ~]$ hadoop fs -put /home/hadoop/1.txt /input ##上传测试文件到hdfs
[hadoop@master ~]$ hadoop fs -ls /input
Found 1 items
-rw-r--r-- 2 hadoop supergroup 37 2018-11-25 22:33 /input/1.txt
[hadoop@master ~]$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input/1.txt /output ##进行计算,将结果输出到hdfs://output
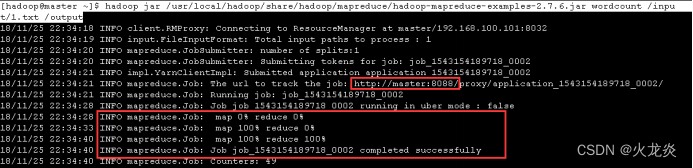

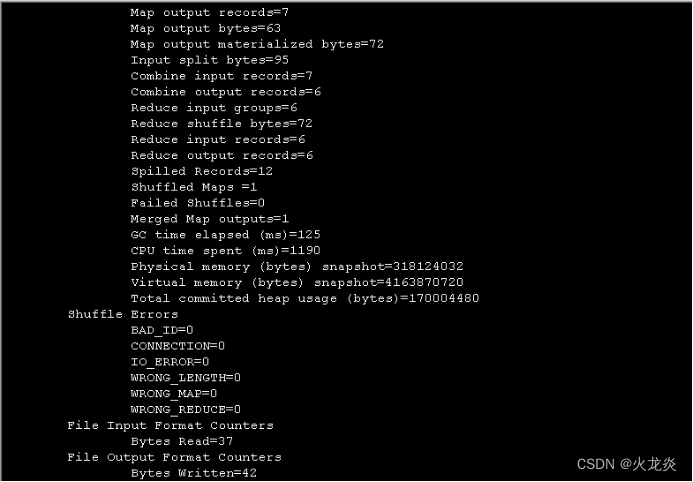
[hadoop@master ~]$ hadoop fs -ls /
Found 3 items
drwxr-xr-x - hadoop supergroup 0 2018-11-25 22:33 /input
drwxr-xr-x - hadoop supergroup 0 2018-11-25 22:34 /output
drwx------ - hadoop supergroup 0 2018-11-25 22:34 /tmp
[hadoop@master ~]$ hadoop fs -ls /output
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2018-11-25 22:34 /output/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 42 2018-11-25 22:34 /output/part-r-00000
[hadoop@master ~]$ hadoop fs -cat /output/part-r-00000
bye 1
foot 1
haha 1
head 1
hello 1
tree 2
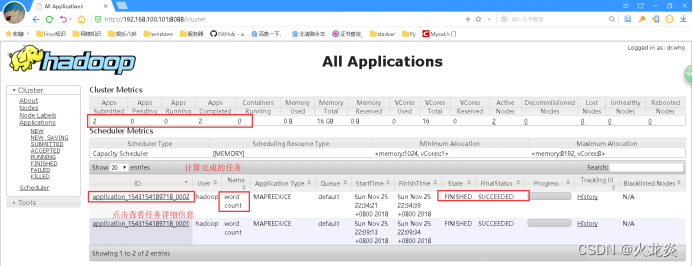
3.11 网页方式查看ResourceManager进程的计算结果;
http://192.168.100.101:8088 ##查看mapreduce计算程序的任务信息
3.12 动态扩展HDFS内部datanode节点;
新添节点环境:

快速扩容节点:
192.168.100.100:修改hosts
echo "192.168.100.104 slave3 slave3.linuxfan.cn" >>/etc/hosts
for i in 101 102 103 104;do rsync -av /etc/hosts root@192.168.100.$i:/etc/hosts;done
192.168.100.104:slave3创建用户同步jdk和hdoop
useradd hadoop
echo hadoop |passwd --stdin hadoop
rsync -av root@192.168.100.101:/usr/local/ /usr/local/ ##同步java和hodoop
rsync -av root@192.168.100.101:/etc/profile /etc/profile
source /etc/profile
192.168.100.101:master复制公钥、同步slaves、重启hadoop
ssh-copy-id hadoop@192.168.100.104 ##复制公钥
ssh hadoop@slave3
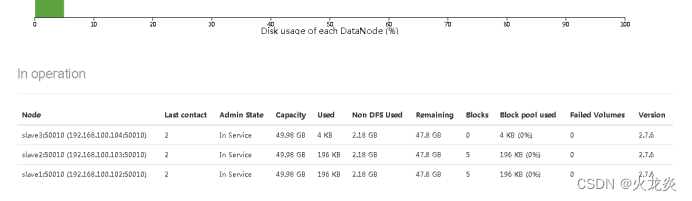
echo slave3 >>/usr/local/hadoop/etc/hadoop/slaves ##添加slave3为从节点
for i in 1 2 3 ;do rsync -av /usr/local/hadoop/etc/ hadoop@slave$i:/usr/local/hadoop/etc/; done ##同步所有配置
/usr/local/hadoop/sbin/stop-all.sh
/usr/local/hadoop/sbin/start-all.sh
web页面验证:
另外一种玩法:
1.配置所有节点环境:
[root@master ~]# cat <<END >>/etc/hosts
192.168.100.104 slave3
END
[root@slave1 ~]# cat <<END >>/etc/hosts
192.168.100.104 slave3
END
[root@slave2 ~]# cat <<END >>/etc/hosts
192.168.100.104 slave3
END
[root@slave3 ~]# cat <<END >>/etc/hosts
192.168.100.101 master
192.168.100.102 slave1
192.168.100.103 slave2
192.168.100.104 slave3
END
[root@slave3 ~]# useradd hadoop
[root@slave3 ~]# echo "hadoop" |passwd --stdin hadoop
2.slave3节点准备jdk环境:
> [root@slave3 ~]# tar zxvf jdk-8u171-linux-x64.tar.gz [root@slave3 ~]#
> mv /root/jdk1.8.0_171/ /usr/local/java/ [root@slave3 ~]# cat <<END
> >>/etc/profile JAVA_HOME=/usr/local/java/ JRE_HOME=\$JAVA_HOME/jre CLASS_PATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar:\$JAVA_HOME/lib
> PATH=\$PATH:\$JAVA_HOME/bin:\$JRE_HOME/bin export JAVA_HOME JRE_HOME
> CLASS_PATH PATH END [root@slave3 ~]# source /etc/profile [root@slave3
> ~]# java -version java version "1.8.0_171"
3.slave3节点安装hadoop程序:
[root@slave3 ~]# tar zxvf hadoop-2.7.6.tar.gz
[root@slave3 ~]# mv /root/hadoop-2.7.6/ /usr/local/hadoop/
[root@slave3 ~]# ls /usr/local/hadoop/
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[root@slave3 ~]# cat <<END >>/etc/profile
export HADOOP_HOME=/usr/local/hadoop/
export PATH=\$PATH:\$HADOOP_HOME/bin
END
[root@slave3 ~]# source /etc/profile
[root@slave3 ~]# echo "export JAVA_HOME=/usr/local/java/" >>/usr/local/hadoop/etc/hadoop/hadoop-env.sh
##设置HDFS存储加载jdk的环境变量
[root@slave3 ~]# echo "export JAVA_HOME=/usr/local/java/" >>/usr/local/hadoop/etc/hadoop/yarn-env.sh
##设置mapreduce的V2版本--YARN加载jdk的环境变量
[root@slave3 ~]# mkdir /usr/local/hadoop/name/ ##存放namenode中元数据的位置
[root@slave3 ~]# mkdir /usr/local/hadoop/data/ ##存放datanode中的数据目录,通常企业内部此目录是独立挂载的磁盘设备,作为hdfs的存储设备
[root@slave3 ~]# mkdir /usr/local/hadoop/tmp/ ##存放用户临时文件
[root@slave3 ~]# mkdir /usr/local/hadoop/var/ ##存放服务动态变化文件
[root@slave3 ~]# chown hadoop /usr/local/hadoop/ -R
4.配置master节点的集群更改:
[root@master ~]# su - hadoop
[hadoop@master ~]$ ssh-copy-id hadoop@192.168.100.104
[hadoop@master ~]$ ssh hadoop@slave3
[hadoop@master ~]$ /usr/local/hadoop/sbin/stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
master: stopping namenode
slave2: stopping datanode
slave1: stopping datanode
Stopping secondary namenodes [master]
master: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
slave2: stopping nodemanager
slave1: stopping nodemanager
slave2: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
slave1: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
no proxyserver to stop
[hadoop@master ~]$ jps
16243 Jps
[hadoop@master ~]$ echo 'slave3' >> /usr/local/hadoop/etc/hadoop/slaves
[hadoop@master ~]$ scp -r /usr/local/hadoop/etc/hadoop/slaves hadoop@slave1:/usr/local/hadoop/etc/hadoop/slaves
[hadoop@master ~]$ scp -r /usr/local/hadoop/etc/hadoop/slaves hadoop@slave2:/usr/local/hadoop/etc/hadoop/slaves
[hadoop@master ~]$ scp -r /usr/local/hadoop/etc/hadoop/* hadoop@slave3:/usr/local/hadoop/etc/hadoop/
5.启动进程测试,节点是否正常:
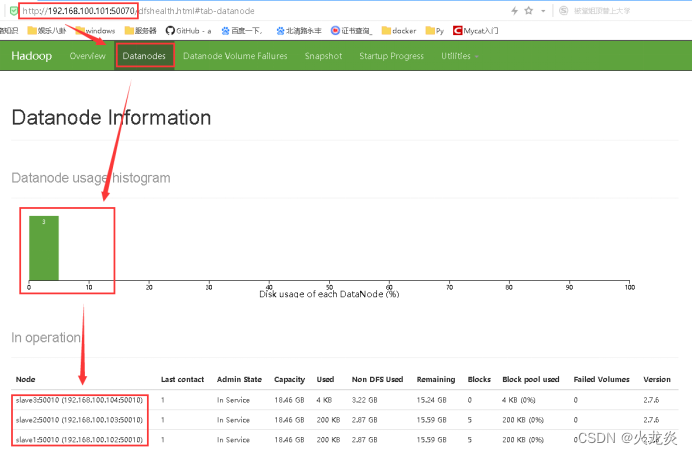
[hadoop@master ~]$ /usr/local/hadoop/sbin/start-all.sh




6.查看hdfs网页配置。验证节点添加情况:















 570
570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









