







Tensorflow学习十二—Batchnorm
一、什么是Batchnorm
首先翻译过来名称就是批量归一化,阅读原论文就是将每层先进行求数据均值再求数据方差,对数据进行标准化(个人认为称作正态化也可以)一般在分母加上一个极小值。训练参数γ,β,最后输出y通过γ与β的线性变换得到新的值,进行缩放和移动。简单来说就是将数据用标准的高斯分布进行数据归一化。

在原论文中复杂一点的说法:

复习:
标准正态分布的公式
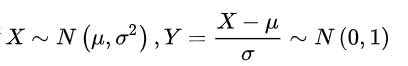
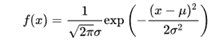
二、那么为什么要用到batchnorm呢?
正向传播中f2=f1(wT∗x+b),那么反向传播中,∂f2∂x=∂f2∂f1w反向传播式子中有w的存在,所以w的大小影响了梯度的消失和爆炸,batchnorm就是通过对每一层的输出规范为均值和方差一致的方法,消除了w带来的放大缩小的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输出从饱和区拉倒了非饱和区。
左图中可以看出w2变化区间很大,对于w2一个小量的变化就会导致loss变化会很大,梯度下降的过程就会变得复杂。

整体有了认识,我们切片两种方式进行说:梯度的消失和爆炸
首先什么是梯度消失,以sigmoid函数为例子,sigmoid函数使得输出在[0,1]之间。
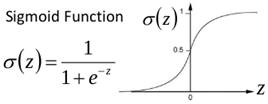
事实上x到了一定大小,经过sigmoid函数的输出范围就很小了,参考下图
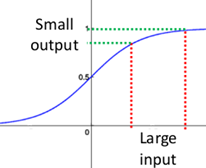
如果输入很大,其对应的斜率就很小,我们知道,其斜率(梯度)在反向传播中是权值学习速率。
所以就会出现如下的问题,在深度网络中,如果网络的激活输出很大,其梯度就很小,学习速率就很慢。
假设每层学习梯度都小于最大值0.25,网络有n层,因为链式求导的原因,第一层的梯度小于0.25的n次方,所以学习速率就慢,对于最后一层只需对自身求导1次,梯度就大,学习速率就快。这会造成的影响是在一个很大的深度网络中,浅层基本不学习,权值变化小,后面几层一直在学习,结果就是,后面几层基本可以表示整个网络,失去了深度的意义。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3482
3482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









