









1、进程
操作系统作为硬件的使用层,提供使用硬件资源的能力,进程作为操作系统的使用层,提供使用操作系统抽象出的资源层的能力。
进程:是指计算机中已运行的程序。进程本身不是基本的运行单位,而是线程的容器。程序本身知识指令、数据及其组织形式的描述,进程才是程序(那些指令和数据)的真正运行实例。
Linux内核把进程叫做任务(task),进程的虚拟地址空间可分为用户虚拟地址空间和内核虚拟地址空间,所有进程共享内核虚拟地址空间,每个进程有独立的用户虚拟地址空间。
2、进程生命周期
Linux操作系统属于多任务操作系统,系统中的每个进程能够分时复用CPU时间片,通过有效的进程调度策略实现多任务并行执行。而进程被CPU调度运行,等待CPU资源分配以及等待外部事件时会属于不同的状态。进程状态如下:
创建状态:创建新进程;
就绪状态:进程获取可以运作所有资源及准备相关条件;
执行状态:进程正在CPU中执行操作;
阻塞状态:进程因等待某些资源而被跳出CPU;
终止状态:进程消亡。
Linux内核进程状态间关系如下:
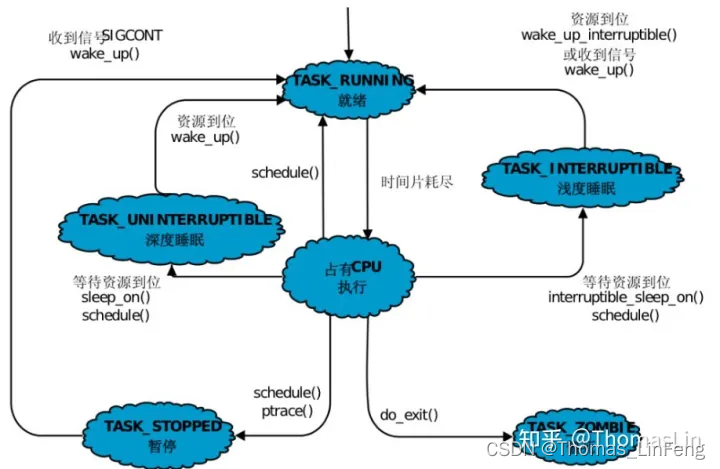
2.1 TASK_RUNNING(可运行状态或可就绪状态)
ps命令标记为R状态的进程,所谓运行态,是只要在运行队列中就叫运行态,代表我已经准备好了,可以随时被调度。
2.2 TASK_INTERRUPTIBLE(可中断睡眠状态,又叫浅睡眠状态)
PS命令标记为S状态的进程,浅度睡眠可以被唤醒或者kill
2.3 TASK_INTERRUPTIBLE (不可中断状态,又叫深度睡眠状态)
PS命令标记为D状态的进程,不能被中断以及kill。一般而言,当进程等待磁盘资源拷贝写入的过程,此时进程处于阻塞状态,这种状态的进程就是D状态(不可被中断),操作系统也不能杀掉该进程,只能等D状态自己醒过来。
2.4 TASK_STOPPED(终止状态)
进程被停止执行,当进程接收到SIGSTOP、SIGTTIN、SIGTSTP或SIGTTOU信号之后就会进入该状态
2.5 EXIT_ZOMBIE(僵尸状态)
PS命令标记为Z状态的进程,Z状态时一种已经死亡的状态,但是死了知乎,不要让操作系统释放它。那该状态存在的意义时什么呢?当一个Linux中的进程退出的时候,一般不会直接进入X状态(死亡,资源可以立马回收),而是进入Z状态,为什么呢?
因为进程被创建出来一定是有任务完成,当进程退出的时候,我们怎么知道进程把任务给我们完成了呢?秩序要把进程的执行结果告知给父进程或者操作系统。
子进程呢个推出,维持Z状态,就是为了让父进程或者操作系统来读取执行结果!父进程和操作系统通过进程等待来读取僵尸进程的信息
如果没有人回收子进程的僵尸,该状态会一直维护!该相关的资源(task_struct)不会被释放!会造成内存泄漏,因此一般必须要求父进程进行回收。
说到了僵尸进程,我们再谈谈与之相关的孤儿进程。
子进程先退出,而父进程一直存在,那如果父进程先退出,子进程一直存在,此时子进程的父进程已经被回收了,子进程没有了父进程,我们把这种子进程处于的状态叫做孤儿进程。
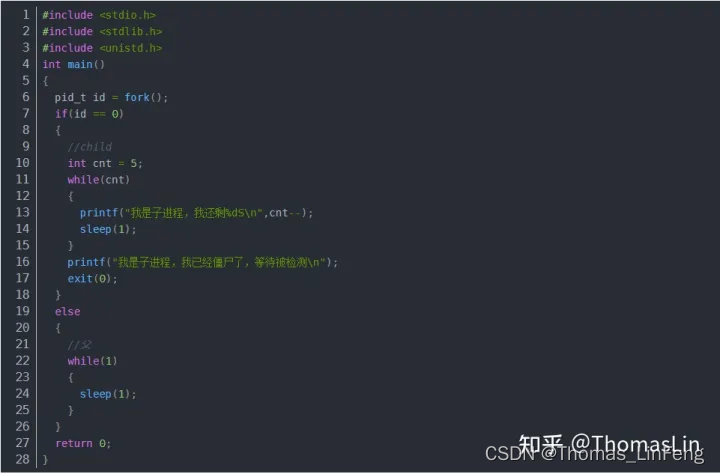
大约执行3秒过后,我们发现父进程不见了,之间子进程了,此时子进程就是孤儿进程,那么孤儿进程要被1号进程领养。这个1号进程就是操作系统。
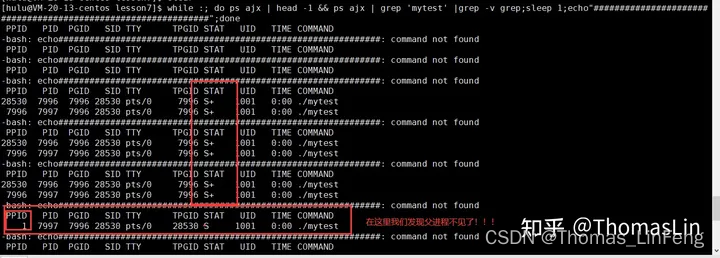
我们发现子进程状态原先是S+,而后面为什么变成了S呢?并且这段代码不能被ctrl +c强制终止了
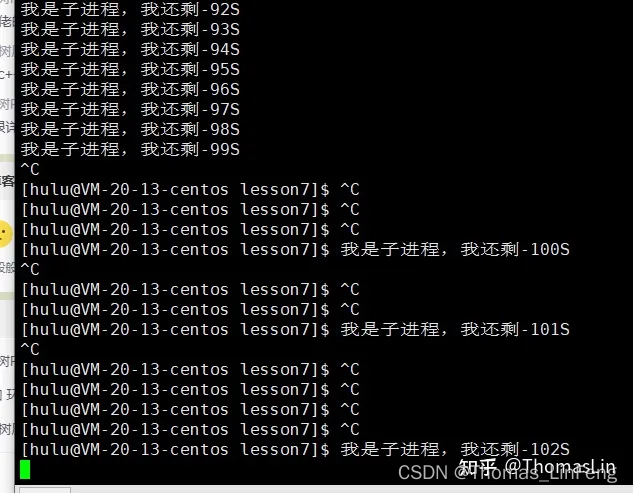
其中带+号表示这个进程是前台进程,而前台进程能够被ctrl C的,而不带+的被称为后台进程,我们要终止这个代码,输入kill -9 pid即可杀掉。
3、进程数据结构(task_struct)分析
进程是操作系统调度的一个实体,需要对进程所必须的资源做一个抽象化,此抽象化为进程控制块(PCB,Process Control Block),在Linux内核里面采用task_struct 结构体来描述进程控制块。Linux内核设计进程和程序的所以算法都围绕名为task_struct的数据结构而建立操作,具体结构体核心成员如下:
struct task_struct {
#ifdef CONFIG_THREAD_INFO_IN_TASK
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/
struct thread_info thread_info;
#endif
//进程的状态标志,是否可以执行
unsigned int __state;
#ifdef CONFIG_PREEMPT_RT
/* saved state for "spinlock sleepers" */
unsigned int saved_state;
#endif
/*
* This begins the randomizable portion of task_struct. Only
* scheduling-critical items should be added above here.
*/
randomized_struct_fields_start
void *stack; //指向内核栈
refcount_t usage;
/* 进程的标志,在调用fork()时给出 */
unsigned int flags;
unsigned int ptrace;
#ifdef CONFIG_SMP
int on_cpu;
struct __call_single_node wake_entry;
unsigned int wakee_flips;
unsigned long wakee_flip_decay_ts;
struct task_struct *last_wakee;
/*
* recent_used_cpu is initially set as the last CPU used by a task
* that wakes affine another task. Waker/wakee relationships can
* push tasks around a CPU where each wakeup moves to the next one.
* Tracking a recently used CPU allows a quick search for a recently
* used CPU that may be idle.
*/
int recent_used_cpu;
int wake_cpu;
#endif
int on_rq;
/* 下面这个是进程调度策略和优先级 */
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
const struct sched_class *sched_class;
#ifdef CONFIG_SCHED_CORE
struct rb_node core_node;
unsigned long core_cookie;
unsigned int core_occupation;
#endif
#ifdef CONFIG_CGROUP_SCHED
struct task_group *sched_task_group;
#endif
#ifdef CONFIG_UCLAMP_TASK
/*
* Clamp values requested for a scheduling entity.
* Must be updated with task_rq_lock() held.
*/
struct uclamp_se uclamp_req[UCLAMP_CNT];
/*
* Effective clamp values used for a scheduling entity.
* Must be updated with task_rq_lock() held.
*/
struct uclamp_se uclamp[UCLAMP_CNT];
#endif
struct sched_statistics stats;
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* List of struct preempt_notifier: */
struct hlist_head preempt_notifiers;
#endif
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
// 进程的调度策略,有三种,实时进程:SCHED_FIFO,SCHED_RR;分时进程:SCHED_OTHER;
unsigned int policy;
int nr_cpus_allowed;
// 此成员允许进程在那个 CPU 上运行
const cpumask_t *cpus_ptr;
cpumask_t *user_cpus_ptr;
cpumask_t cpus_mask;
void *migration_pending;
#ifdef CONFIG_SMP
unsigned short migration_disabled;
#endif
unsigned short migration_flags;
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting;
union rcu_special rcu_read_unlock_special;
struct list_head rcu_node_entry;
struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_PREEMPT_RCU */
#ifdef CONFIG_TASKS_RCU
unsigned long rcu_tasks_nvcsw;
u8 rcu_tasks_holdout;
u8 rcu_tasks_idx;
int rcu_tasks_idle_cpu;
struct list_head rcu_tasks_holdout_list;
#endif /* #ifdef CONFIG_TASKS_RCU */
#ifdef CONFIG_TASKS_TRACE_RCU
int trc_reader_nesting;
int trc_ipi_to_cpu;
union rcu_special trc_reader_special;
bool trc_reader_checked;
struct list_head trc_holdout_list;
#endif /* #ifdef CONFIG_TASKS_TRACE_RCU */
struct sched_info sched_info;
struct list_head tasks;
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
struct rb_node pushable_dl_tasks;
#endif
/*
这个指针指向内存描述符。进程:mm和active_mm指向同一个内存描述符。内核线程:mm是空指针
当内核线程运行时,active_mm指向从进程借用内存描述符
*/
struct mm_struct *mm;
struct mm_struct *active_mm;
/* Per-thread vma caching: */
struct vmacache vmacache;
#ifdef SPLIT_RSS_COUNTING
struct task_rss_stat rss_stat;
#endif
int exit_state;
int exit_code;
int exit_signal;
/* The signal sent when the parent dies: */
int pdeath_signal;
/* JOBCTL_*, siglock protected: */
unsigned long jobctl;
/* Used for emulating ABI behavior of previous Linux versions: */
unsigned int personality;
/* Scheduler bits, serialized by scheduler locks: */
unsigned sched_reset_on_fork:1;
unsigned sched_contributes_to_load:1;
unsigned sched_migrated:1;
#ifdef CONFIG_PSI
unsigned sched_psi_wake_requeue:1;
#endif
/* Force alignment to the next boundary: */
unsigned :0;
/* Unserialized, strictly 'current' */
/*
* This field must not be in the scheduler word above due to wakelist
* queueing no longer being serialized by p->on_cpu. However:
*
* p->XXX = X; ttwu()
* schedule() if (p->on_rq && ..) // false
* smp_mb__after_spinlock(); if (smp_load_acquire(&p->on_cpu) && //true
* deactivate_task() ttwu_queue_wakelist())
* p->on_rq = 0; p->sched_remote_wakeup = Y;
*
* guarantees all stores of 'current' are visible before
* ->sched_remote_wakeup gets used, so it can be in this word.
*/
unsigned sched_remote_wakeup:1;
/* Bit to tell LSMs we're in execve(): */
unsigned in_execve:1;
unsigned in_iowait:1;
#ifndef TIF_RESTORE_SIGMASK
unsigned restore_sigmask:1;
#endif
#ifdef CONFIG_MEMCG
unsigned in_user_fault:1;
#endif
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:1;
#endif
#ifdef CONFIG_CGROUPS
/* disallow userland-initiated cgroup migration */
unsigned no_cgroup_migration:1;
/* task is frozen/stopped (used by the cgroup freezer) */
unsigned frozen:1;
#endif
#ifdef CONFIG_BLK_CGROUP
unsigned use_memdelay:1;
#endif
#ifdef CONFIG_PSI
/* Stalled due to lack of memory */
unsigned in_memstall:1;
#endif
#ifdef CONFIG_PAGE_OWNER
/* Used by page_owner=on to detect recursion in page tracking. */
unsigned in_page_owner:1;
#endif
#ifdef CONFIG_EVENTFD
/* Recursion prevention for eventfd_signal() */
unsigned in_eventfd_signal:1;
#endif
#ifdef CONFIG_IOMMU_SVA
unsigned pasid_activated:1;
#endif
#ifdef CONFIG_CPU_SUP_INTEL
unsigned reported_split_lock:1;
#endif
unsigned long atomic_flags; /* Flags requiring atomic access. */
struct restart_block restart_block;
pid_t pid; //全局的进程号
pid_t tgid; //全局的线程组标识符
#ifdef CONFIG_STACKPROTECTOR
/* Canary value for the -fstack-protector GCC feature: */
unsigned long stack_canary;
#endif
/*
* Pointers to the (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
/* Real parent process: */
struct task_struct __rcu *real_parent; //指向真实的父进程
/* Recipient of SIGCHLD, wait4() reports: */
struct task_struct __rcu *parent; //指向父进程
/*
* Children/sibling form the list of natural children:
*/
struct list_head children;
struct list_head sibling;
struct task_struct *group_leader; //指向线程组的组长
/*
* 'ptraced' is the list of tasks this task is using ptrace() on.
*
* This includes both natural children and PTRACE_ATTACH targets.
* 'ptrace_entry' is this task's link on the p->parent->ptraced list.
*/
struct list_head ptraced;
struct list_head ptrace_entry;
/* PID/PID hash table linkage. */
struct pid *thread_pid;
struct hlist_node pid_links[PIDTYPE_MAX]; //进程号,进程组标识符和会话
struct list_head thread_group;
struct list_head thread_node;
struct completion *vfork_done;
/* CLONE_CHILD_SETTID: */
int __user *set_child_tid;
/* CLONE_CHILD_CLEARTID: */
int __user *clear_child_tid;
/* PF_KTHREAD | PF_IO_WORKER */
void *worker_private;
u64 utime;
u64 stime;
#ifdef CONFIG_ARCH_HAS_SCALED_CPUTIME
u64 utimescaled;
u64 stimescaled;
#endif
u64 gtime;
struct prev_cputime prev_cputime;
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
struct vtime vtime;
#endif
#ifdef CONFIG_NO_HZ_FULL
atomic_t tick_dep_mask;
#endif
/* Context switch counts: */
unsigned long nvcsw;
unsigned long nivcsw;
/* Monotonic time in nsecs: */
u64 start_time;
/* Boot based time in nsecs: */
u64 start_boottime;
/* MM fault and swap info: this can arguably be seen as either mm-specific or thread-specific: */
unsigned long min_flt;
unsigned long maj_flt;
/* Empty if CONFIG_POSIX_CPUTIMERS=n */
struct posix_cputimers posix_cputimers;
#ifdef CONFIG_POSIX_CPU_TIMERS_TASK_WORK
struct posix_cputimers_work posix_cputimers_work;
#endif
/* Process credentials: */
/* Tracer's credentials at attach: */
const struct cred __rcu *ptracer_cred;
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred; //此成员指向主体和真实客体证书
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred; //指向有效客体证书
#ifdef CONFIG_KEYS
/* Cached requested key. */
struct key *cached_requested_key;
#endif
/*
* executable name, excluding path.
*
* - normally initialized setup_new_exec()
* - access it with [gs]et_task_comm()
* - lock it with task_lock()
*/
char comm[TASK_COMM_LEN]; //进程名称
struct nameidata *nameidata;
//下面两个成员用于UNIX系统:信号量和共享内存
#ifdef CONFIG_SYSVIPC
struct sysv_sem sysvsem;
struct sysv_shm sysvshm;
#endif
#ifdef CONFIG_DETECT_HUNG_TASK
unsigned long last_switch_count;
unsigned long last_switch_time;
#endif
/* 此成员文件系统信息,主要是进程的根目录和当前工作目录 */
struct fs_struct *fs;
/* 打开文件表 */
struct files_struct *files;
#ifdef CONFIG_IO_URING
struct io_uring_task *io_uring;
#endif
/* 命名空间 */
struct nsproxy *nsproxy;
// 下面模块的成员主要用于信号处理
/* Signal handlers: */
struct signal_struct *signal;
struct sighand_struct __rcu *sighand;
sigset_t blocked;
sigset_t real_blocked;
/* Restored if set_restore_sigmask() was used: */
sigset_t saved_sigmask;
/* 进程是否还要待处理的信号 */
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
unsigned int sas_ss_flags;
struct callback_head *task_works;
#ifdef CONFIG_AUDIT
#ifdef CONFIG_AUDITSYSCALL
struct audit_context *audit_context;
#endif
kuid_t loginuid;
unsigned int sessionid;
#endif
struct seccomp seccomp;
struct syscall_user_dispatch syscall_dispatch;
/* Thread group tracking: */
u64 parent_exec_id;
u64 self_exec_id;
/* Protection against (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, mempolicy: */
spinlock_t alloc_lock;
/* Protection of the PI data structures: */
raw_spinlock_t pi_lock;
struct wake_q_node wake_q;
#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task: */
struct rb_root_cached pi_waiters;
/* Updated under owner's pi_lock and rq lock */
struct task_struct *pi_top_task;
/* Deadlock detection and priority inheritance handling: */
struct rt_mutex_waiter *pi_blocked_on;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
/* Mutex deadlock detection: */
struct mutex_waiter *blocked_on;
#endif
#ifdef CONFIG_DEBUG_ATOMIC_SLEEP
int non_block_count;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
struct irqtrace_events irqtrace;
unsigned int hardirq_threaded;
u64 hardirq_chain_key;
int softirqs_enabled;
int softirq_context;
int irq_config;
#endif
#ifdef CONFIG_PREEMPT_RT
int softirq_disable_cnt;
#endif
#ifdef CONFIG_LOCKDEP
# define MAX_LOCK_DEPTH 48UL
u64 curr_chain_key;
/* 锁深度 */
int lockdep_depth;
unsigned int lockdep_recursion;
struct held_lock held_locks[MAX_LOCK_DEPTH];
#endif
#if defined(CONFIG_UBSAN) && !defined(CONFIG_UBSAN_TRAP)
unsigned int in_ubsan;
#endif
/* Journalling filesystem info: */
void *journal_info;
/* Stacked block device info: */
struct bio_list *bio_list;
/* Stack plugging: */
struct blk_plug *plug;
/* VM state: */
struct reclaim_state *reclaim_state;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
#ifdef CONFIG_COMPACTION
struct capture_control *capture_control;
#endif
/* Ptrace state: */
unsigned long ptrace_message;
kernel_siginfo_t *last_siginfo;
struct task_io_accounting ioac;
#ifdef CONFIG_PSI
/* Pressure stall state */
unsigned int psi_flags;
#endif
#ifdef CONFIG_TASK_XACCT
/* Accumulated RSS usage: */
u64 acct_rss_mem1;
/* Accumulated virtual memory usage: */
u64 acct_vm_mem1;
/* stime + utime since last update: */
u64 acct_timexpd;
#endif
#ifdef CONFIG_CPUSETS
/* Protected by ->alloc_lock: */
nodemask_t mems_allowed;
/* Sequence number to catch updates: */
seqcount_spinlock_t mems_allowed_seq;
int cpuset_mem_spread_rotor;
int cpuset_slab_spread_rotor;
#endif
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock: */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock: */
struct list_head cg_list;
#endif
#ifdef CONFIG_X86_CPU_RESCTRL
u32 closid;
u32 rmid;
#endif
#ifdef CONFIG_FUTEX
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endif
struct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
struct mutex futex_exit_mutex;
unsigned int futex_state;
#endif
#ifdef CONFIG_PERF_EVENTS
struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts];
struct mutex perf_event_mutex;
struct list_head perf_event_list;
#endif
#ifdef CONFIG_DEBUG_PREEMPT
unsigned long preempt_disable_ip;
#endif
#ifdef CONFIG_NUMA
/* Protected by alloc_lock: */
struct mempolicy *mempolicy;
short il_prev;
short pref_node_fork;
#endif
#ifdef CONFIG_NUMA_BALANCING
int numa_scan_seq;
unsigned int numa_scan_period;
unsigned int numa_scan_period_max;
int numa_preferred_nid;
unsigned long numa_migrate_retry;
/* Migration stamp: */
u64 node_stamp;
u64 last_task_numa_placement;
u64 last_sum_exec_runtime;
struct callback_head numa_work;
/*
* This pointer is only modified for current in syscall and
* pagefault context (and for tasks being destroyed), so it can be read
* from any of the following contexts:
* - RCU read-side critical section
* - current->numa_group from everywhere
* - task's runqueue locked, task not running
*/
struct numa_group __rcu *numa_group;
/*
* numa_faults is an array split into four regions:
* faults_memory, faults_cpu, faults_memory_buffer, faults_cpu_buffer
* in this precise order.
*
* faults_memory: Exponential decaying average of faults on a per-node
* basis. Scheduling placement decisions are made based on these
* counts. The values remain static for the duration of a PTE scan.
* faults_cpu: Track the nodes the process was running on when a NUMA
* hinting fault was incurred.
* faults_memory_buffer and faults_cpu_buffer: Record faults per node
* during the current scan window. When the scan completes, the counts
* in faults_memory and faults_cpu decay and these values are copied.
*/
unsigned long *numa_faults;
unsigned long total_numa_faults;
/*
* numa_faults_locality tracks if faults recorded during the last
* scan window were remote/local or failed to migrate. The task scan
* period is adapted based on the locality of the faults with different
* weights depending on whether they were shared or private faults
*/
unsigned long numa_faults_locality[3];
unsigned long numa_pages_migrated;
#endif /* CONFIG_NUMA_BALANCING */
#ifdef CONFIG_RSEQ
struct rseq __user *rseq;
u32 rseq_sig;
/*
* RmW on rseq_event_mask must be performed atomically
* with respect to preemption.
*/
unsigned long rseq_event_mask;
#endif
struct tlbflush_unmap_batch tlb_ubc;
union {
refcount_t rcu_users;
struct rcu_head rcu;
};
/* Cache last used pipe for splice(): */
struct pipe_inode_info *splice_pipe;
struct page_frag task_frag;
#ifdef CONFIG_TASK_DELAY_ACCT
struct task_delay_info *delays;
#endif
#ifdef CONFIG_FAULT_INJECTION
int make_it_fail;
unsigned int fail_nth;
#endif
/*
* When (nr_dirtied >= nr_dirtied_pause), it's time to call
* balance_dirty_pages() for a dirty throttling pause:
*/
int nr_dirtied;
int nr_dirtied_pause;
/* Start of a write-and-pause period: */
unsigned long dirty_paused_when;
#ifdef CONFIG_LATENCYTOP
int latency_record_count;
struct latency_record latency_record[LT_SAVECOUNT];
#endif
/*
* Time slack values; these are used to round up poll() and
* select() etc timeout values. These are in nanoseconds.
*/
u64 timer_slack_ns;
u64 default_timer_slack_ns;
#if defined(CONFIG_KASAN_GENERIC) || defined(CONFIG_KASAN_SW_TAGS)
unsigned int kasan_depth;
#endif
#ifdef CONFIG_KCSAN
struct kcsan_ctx kcsan_ctx;
#ifdef CONFIG_TRACE_IRQFLAGS
struct irqtrace_events kcsan_save_irqtrace;
#endif
#ifdef CONFIG_KCSAN_WEAK_MEMORY
int kcsan_stack_depth;
#endif
#endif
#if IS_ENABLED(CONFIG_KUNIT)
struct kunit *kunit_test;
#endif
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored address in ret_stack: */
int curr_ret_stack;
int curr_ret_depth;
/* Stack of return addresses for return function tracing: */
struct ftrace_ret_stack *ret_stack;
/* Timestamp for last schedule: */
unsigned long long ftrace_timestamp;
/*
* Number of functions that haven't been traced
* because of depth overrun:
*/
atomic_t trace_overrun;
/* Pause tracing: */
atomic_t tracing_graph_pause;
#endif
#ifdef CONFIG_TRACING
/* State flags for use by tracers: */
unsigned long trace;
/* Bitmask and counter of trace recursion: */
unsigned long trace_recursion;
#endif /* CONFIG_TRACING */
#ifdef CONFIG_KCOV
/* See kernel/kcov.c for more details. */
/* Coverage collection mode enabled for this task (0 if disabled): */
unsigned int kcov_mode;
/* Size of the kcov_area: */
unsigned int kcov_size;
/* Buffer for coverage collection: */
void *kcov_area;
/* KCOV descriptor wired with this task or NULL: */
struct kcov *kcov;
/* KCOV common handle for remote coverage collection: */
u64 kcov_handle;
/* KCOV sequence number: */
int kcov_sequence;
/* Collect coverage from softirq context: */
unsigned int kcov_softirq;
#endif
#ifdef CONFIG_MEMCG
struct mem_cgroup *memcg_in_oom;
gfp_t memcg_oom_gfp_mask;
int memcg_oom_order;
/* Number of pages to reclaim on returning to userland: */
unsigned int memcg_nr_pages_over_high;
/* Used by memcontrol for targeted memcg charge: */
struct mem_cgroup *active_memcg;
#endif
#ifdef CONFIG_BLK_CGROUP
struct request_queue *throttle_queue;
#endif
#ifdef CONFIG_UPROBES
struct uprobe_task *utask;
#endif
#if defined(CONFIG_BCACHE) || defined(CONFIG_BCACHE_MODULE)
unsigned int sequential_io;
unsigned int sequential_io_avg;
#endif
struct kmap_ctrl kmap_ctrl;
#ifdef CONFIG_DEBUG_ATOMIC_SLEEP
unsigned long task_state_change;
# ifdef CONFIG_PREEMPT_RT
unsigned long saved_state_change;
# endif
#endif
int pagefault_disabled;
#ifdef CONFIG_MMU
struct task_struct *oom_reaper_list;
struct timer_list oom_reaper_timer;
#endif
#ifdef CONFIG_VMAP_STACK
struct vm_struct *stack_vm_area;
#endif
#ifdef CONFIG_THREAD_INFO_IN_TASK
/* A live task holds one reference: */
refcount_t stack_refcount;
#endif
#ifdef CONFIG_LIVEPATCH
int patch_state;
#endif
#ifdef CONFIG_SECURITY
/* Used by LSM modules for access restriction: */
void *security;
#endif
#ifdef CONFIG_BPF_SYSCALL
/* Used by BPF task local storage */
struct bpf_local_storage __rcu *bpf_storage;
/* Used for BPF run context */
struct bpf_run_ctx *bpf_ctx;
#endif
#ifdef CONFIG_GCC_PLUGIN_STACKLEAK
unsigned long lowest_stack;
unsigned long prev_lowest_stack;
#endif
#ifdef CONFIG_X86_MCE
void __user *mce_vaddr;
__u64 mce_kflags;
u64 mce_addr;
__u64 mce_ripv : 1,
mce_whole_page : 1,
__mce_reserved : 62;
struct callback_head mce_kill_me;
int mce_count;
#endif
#ifdef CONFIG_KRETPROBES
struct llist_head kretprobe_instances;
#endif
#ifdef CONFIG_RETHOOK
struct llist_head rethooks;
#endif
#ifdef CONFIG_ARCH_HAS_PARANOID_L1D_FLUSH
/*
* If L1D flush is supported on mm context switch
* then we use this callback head to queue kill work
* to kill tasks that are not running on SMT disabled
* cores
*/
struct callback_head l1d_flush_kill;
#endif
/*
* New fields for task_struct should be added above here, so that
* they are included in the randomized portion of task_struct.
*/
randomized_struct_fields_end
/* CPU-specific state of this task: */
struct thread_struct thread;
/*
* WARNING: on x86, 'thread_struct' contains a variable-sized
* structure. It *MUST* be at the end of 'task_struct'.
*
* Do not put anything below here!
*/
};
4、进程优先级/系统调用
4.1 进程优先级
限期进程的优先级比实时进程要高,实时进程的优先级比普通进程要高。
限期进程的优先级是-1;
实时进程的优先级1-99,优先级数值越大,表示优先级越高;
普通进程的静态优先级为:100-139,优先级数值越小,表示优先级越高,可通过修改nice值改变普通进程的优先级,优先级等于120加上nice值。

4.2 系统调用
当运行应用程序的时候,调用fork()/vfork()/clone()函数就是系统调用。系统调用就是应用程序如何进入内核空间执行任务,程序使用系统调用执行一系列操作:比如创建进程、文件IO等等。
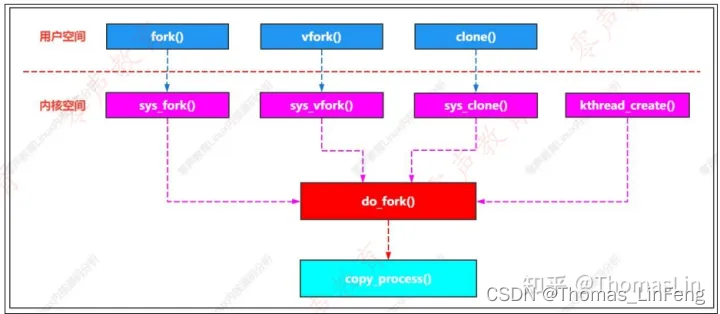
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
struct kernel_clone_args args = {
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
struct kernel_clone_args args = {
.flags = CLONE_VFORK | CLONE_VM,
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
}
#endif
pid_t kernel_clone(struct kernel_clone_args *args)
{
u64 clone_flags = args->flags;
struct completion vfork;
struct pid *pid;
struct task_struct *p;
int trace = 0;
pid_t nr;
/*
* For legacy clone() calls, CLONE_PIDFD uses the parent_tid argument_
* to return the pidfd. Hence, CLONE_PIDFD and CLONE_PARENT_SETTID are
* mutually exclusive. With clone3() CLONE_PIDFD has grown a separate
* field in struct clone_args and it still doesn't make sense to have
* them both point at the same memory location. Performing this check
* here has the advantage that we don't need to have a separate helper
* to check for legacy clone().
*/
if ((args->flags & CLONE_PIDFD) &&
(args->flags & CLONE_PARENT_SETTID) &&
(args->pidfd == args->parent_tid))
return -EINVAL;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if (args->exit_signal != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(NULL, trace, NUMA_NO_NODE, args);
add_latent_entropy();
if (IS_ERR(p))
return PTR_ERR(p);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, args->parent_tid);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
return nr;
}
4.3 内核线程
内核线程是直接由内核本身启动的进程。内核线程实际上是将内核函数委托给独立的进程,与系统中其他进程"并行"执行(实际上,也并行与内核自身的执行)。内核线程经常称之为(内核)守护进程。他们用于执行下列任务。
周期性的将修改的内存页与页来源块设备同步(例如,使用mmap的文件映射);
如果内存也很少使用,则写入交换区;
管理延时动作(deferred action);
实现文件系统的事务日志。
它是独立运行在内核空间的进程,与普通用户进程区别在于内核线程没有独立的进程地址空间。task_struct数据结构里面有一个成员指针mm设置为NULL,它只能运行在内核空间。
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)
{
struct kernel_clone_args args = {
.flags = ((lower_32_bits(flags) | CLONE_VM |
CLONE_UNTRACED) & ~CSIGNAL),
.exit_signal = (lower_32_bits(flags) & CSIGNAL),
.fn = fn,
.fn_arg = arg,
.kthread = 1,
};
return kernel_clone(&args);
}
4.4 退出进程
退出进程由两种方式:一种是调用exit()系统调用或者从某个程序主函数返回;另一个方式为被接收到杀死信号或者异常时被终止。
















 3151
3151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









