







爬虫的简介
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁,自动索引,模拟程序或者蠕虫.
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件,在现在这个大数据的时代,
可以帮我们获取更多过滤更多好的数据。
1.我们先导入pom依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.javaxl</groupId>
<artifactId>T226_jsoup</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>T226_jsoup</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- jdbc驱动包 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>
<!-- 添加Httpclient支持 -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
<!-- 添加jsoup支持 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.1</version>
</dependency>
<!-- 添加日志支持 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.16</version>
</dependency>
<!-- 添加ehcache支持 -->
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
<version>2.10.3</version>
</dependency>
<!-- 添加commons io支持 -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
</dependencies>
</project>
DownloadImg(爬取图片)
package com.javaxl.crawler;
import java.io.File;
import java.io.IOException;
import java.util.UUID;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.log4j.Logger;
import com.javaxl.util.DateUtil;
import com.javaxl.util.PropertiesUtil;
public class DownloadImg {
private static Logger logger = Logger.getLogger(DownloadImg.class);
private static String URL = "https://ss0.bdstatic.com/70cFvHSh_Q1YnxGkpoWK1HF6hhy/it/u=572675356,1342513304&fm=26&gp=0.jpg";
public static void main(String[] args) {
logger.info("开始爬取首页:" + URL);
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(URL);
RequestConfig config = RequestConfig.custom().setConnectTimeout(5000).setSocketTimeout(8000).build();
httpGet.setConfig(config);
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
if (response == null) {
logger.info("连接超时!!!");
} else {
HttpEntity entity = response.getEntity();
String imgPath = PropertiesUtil.getValue("blogImages");
String dateDir = DateUtil.getCurrentDatePath();
String uuid = UUID.randomUUID().toString();
String subfix = entity.getContentType().getValue().split("/")[1];
String localFile = imgPath+dateDir+"/"+uuid+"."+subfix;
// System.out.println(localFile);
FileUtils.copyInputStreamToFile(entity.getContent(), new File(localFile));
}
} catch (ClientProtocolException e) {
logger.error(URL+"-ClientProtocolException", e);
} catch (IOException e) {
logger.error(URL+"-IOException", e);
} catch (Exception e) {
logger.error(URL+"-Exception", e);
} finally {
try {
if (response != null) {
response.close();
}
if(httpClient != null) {
httpClient.close();
}
} catch (IOException e) {
logger.error(URL+"-IOException", e);
}
}
logger.info("结束首页爬取:" + URL);
}
}
存放图片的路径:
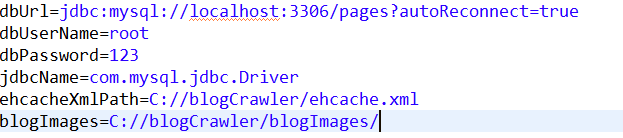
爬取的图片

BlogCrawlerStarter(爬取网站数据博客园)
package com.javaxl.crawler;
import java.io.File;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.UUID;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









