







线性回归解决连续值的回归预测;而逻辑回归解决离散值的分类预测;
算法推导
逻辑回归可以看作是两部分,以0、1分类问题说明;
-
线性回归部分
- 对于一个样本
x
i
x_i
xi,有n个特征
x
i
(
1
)
x_i^{(1)}
xi(1)、
x
i
(
2
)
x_i^{(2)}
xi(2)…
x
i
(
n
)
x_i^{(n)}
xi(n),每个特征有对应的权重
θ
(
j
)
\theta_{(j)}
θ(j),则该样本所有特征的线性加权求和为:
h
θ
(
x
i
)
=
∑
j
n
θ
j
x
i
(
j
)
+
θ
0
x
i
(
0
)
=
>
θ
T
x
i
;
其中
x
i
(
0
)
=
1
h_{\theta}(x_i) =\sum_j^n\theta_jx_i^{(j)} + \theta_0x_i^{(0)}=>\theta^Tx_i ; 其中x_i^{(0)}=1
hθ(xi)=j∑nθjxi(j)+θ0xi(0)=>θTxi;其中xi(0)=1
θ 为权重列向量, x i 为第 i 个样本的列向量 \theta为权重列向量,x_i为第i个样本的列向量 θ为权重列向量,xi为第i个样本的列向量
- 对于一个样本
x
i
x_i
xi,有n个特征
x
i
(
1
)
x_i^{(1)}
xi(1)、
x
i
(
2
)
x_i^{(2)}
xi(2)…
x
i
(
n
)
x_i^{(n)}
xi(n),每个特征有对应的权重
θ
(
j
)
\theta_{(j)}
θ(j),则该样本所有特征的线性加权求和为:
h
θ
(
x
i
)
=
∑
j
n
θ
j
x
i
(
j
)
+
θ
0
x
i
(
0
)
=
>
θ
T
x
i
;
其中
x
i
(
0
)
=
1
h_{\theta}(x_i) =\sum_j^n\theta_jx_i^{(j)} + \theta_0x_i^{(0)}=>\theta^Tx_i ; 其中x_i^{(0)}=1
hθ(xi)=j∑nθjxi(j)+θ0xi(0)=>θTxi;其中xi(0)=1
-
逻辑函数部分
- 回归拟合的值 h θ ( x i ) h_{\theta}(x_i) hθ(xi) 是一个连续值,需要转为 [ 0 , 1 ] [0, 1] [0,1]之间的概率;
- 逻辑函数 f ( x ) = 1 1 + e − x f(x) = \frac {1} {1+e^{-x}} f(x)=1+e−x1 将 h θ ( x i ) h_{\theta}(x_i) hθ(xi) 连续值经过该逻辑函数映射到0-1之间
-
由以上两部分,可以得到逻辑回归的预测函数: y p r e d ( x i ) = 1 1 + e − θ T x i y_{pred}(x_i) = \frac {1} {1+e^{-\theta^Tx_i}} ypred(xi)=1+e−θTxi1 这里的预测值在 0 − 1 0-1 0−1之间,可以表示样本 x i x_i xi属于某类别的概率;
-
概率的似然函数 f = ∏ i = 1 m y p r e d y t r u e ( 1 − y p r e d ) ( 1 − y t r u e ) f = \prod_{i=1}^my_{pred}^{y_{true}}(1-y_{pred})^{(1-y_{true})} f=i=1∏mypredytrue(1−ypred)(1−ytrue) 尽量让属于某类的概率最大,即极大似然估计求解;两边取对数,并乘以-1,得到损失函数: L = − ∑ i = 1 m ( y t r u e l o g ( y p r e d ) + ( 1 − y t r u e ) l o g ( 1 − y p r e d ) ) L = -\sum_{i=1}^m(y_{true}log(y_{pred}) + (1-y_{true})log(1-y_{pred})) L=−i=1∑m(ytruelog(ypred)+(1−ytrue)log(1−ypred))求该损失函数的最小值。
-
梯度下降法,优化损失函数,得到权重更新公式: θ j = θ j − α ∑ i = 1 m ( y ^ i − y i ) x i j \theta_j = \theta_j - \alpha\sum_{i=1}^m(\hat y_i - y_i)x_i^{j} θj=θj−αi=1∑m(y^i−yi)xij
表示为矩阵形式: θ = θ − α X T ( Y ^ − Y ) \theta = \theta - \alpha X^T(\hat Y - Y) θ=θ−αXT(Y^−Y)
手动实现逻辑回顾
pass
sklearn的逻辑回归
- 基于breast_cancer 数据集训练分类模型
- 绘制混淆矩阵
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, balanced_accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
data = load_breast_cancer()
# 获取数据、标签
x, y = data.data, data.target
print("data:", x.shape)
print("label:", y.shape)
# 数据分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# 训练
lg_model = LogisticRegression(penalty='l2')
lg_model.fit(x_train, y_train)
print("训练集准确率:", balanced_accuracy_score(y_train, lg_model.predict(x_train)))
print("测试集准确率:", balanced_accuracy_score(y_test, lg_model.predict(x_test)))
from matplotlib import pyplot as plt
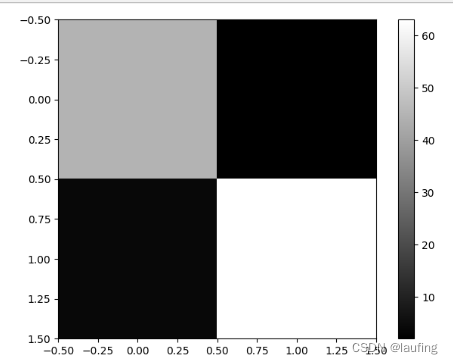
# 混淆矩阵
y_pred = lg_model.predict(x_test)
cm = confusion_matrix(y_test, y_pred)
plt.imshow(cm, cmap="gray")
plt.colorbar()
plt.show()
















 1776
1776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











