







目录
前言
这是系列的第一篇
1、Sentry 架构概述
1.1、Sentry 的权限模型
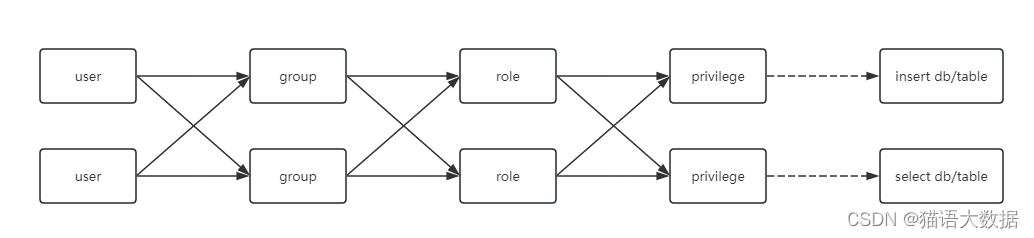
Sentry 是基于角色的权限模型,权限都挂在 role 上,一个 group 可以有多个 role,一个 user 可以有多个 group,也就是多对多对多对多~ 这部分就不展开细讲了,网上有很多具体的使用案例可以参考
1.2、Sentry 架构图
一图胜千言( ̄︶ ̄)↗ (应该没那么难看吧)

其中蓝色部分为 Sentry 的服务或者插件实现。
1.2、架构剖析
其实理解 Sentry 的架构和原理笔者认为就是三块儿,一块儿是 Sentry 怎么获取权限数据,第二块儿是 Sentry 是怎么处理数据的,第三块儿是 Sentry 怎么提供鉴权能力的。其中第二点,在本片中会涉及得少一点,因为笔者认为一上来就花很多精力细说 Sentry 内部的内容,其实是没有什么感觉的,反而不如先从 Sentry 进行交互的组件了解到 Sentry 做了哪些事情,然后带有目标性地去了解 Sentry 内部哪一部分是做什么事情的,会更符合笔者的思考方式一点。所以本篇和下一篇,对 Sentry 内部的实现细节都会一笔带过,在后续的篇章里再展开(或者说一篇太长了,写起来太累了哈哈哈哈哈哈狗😸)。
要说第一点,就得先聊一下 Hive 作为元数据管理角色的地位。哪怕是现在比较流行的数据湖的概念,如 Hudi、Paimon等,大部分的使用场景也是用的 Hive Metastore(以下简称 HMS)来进行元数据管理,而 Sentry 内置的同步元数据功能也是和 Hive 进行深度绑定的。所以其实 Sentry 做的事情就是把 Hive 管理的元数据信息,同步到自己的数据库进行管理,和其他相关的信息如用户、用户组、所拥有的权限等维护映射关系。
那另一块儿就是 Sentry 提供鉴权的能力。如前面所说,Sentry 已经有了自己的权限数据。然后 Sentry 就可以以接口地形式向外提供权限查询的能力。谁来查,当然就是上图的中各类组件的插件了。Sentry 通过提供各类插件,可插拔地对相关组件地权限进行管理。
2、Sentry 如何收集权限信息
权限信息的增删改,要么是通过 sql 赋权语句,要么是用过编码 API 的方式来进行管理,来源途径不重要,Sentry 总能够获取到权限数据。怎么办到的呢,在上图中可以看到,在 Hive 内部有 2 处 Sentry 的实现在被动向 Sentry 推送数据,还有一个 Sentry 内部的 HMSFollower 在主动拉数据。
2.1、HMSFollower
Sentry Server 启动时会启动一个 HMSFollower 主动和 HMS 进行交互
// SentryService
private void runServer() throws Exception {
startSentryStoreCleaner(conf);
startHMSFollower(conf);
...
}
这个 HMSFllower 可以简单理解成一个线程不断的请求 HMS 的 get_next_notification 接口,签名如下:
public NotificationEventResponse get_next_notification(NotificationEventRequest rqst) throws org.apache.thrift.TExcetion;
所以这个接口是本身 HMS 就提供好的,是提供给外部系统获取库表等变更信息。要把这一块儿说清楚,其实得先说一下 Hive 这块儿本身的设计。
都知道 Hive 的 Mysql 库里面存储了关于库表的信息,其实还有专门用来给 get_next_notification 准备的增量权限变更信息日志表。
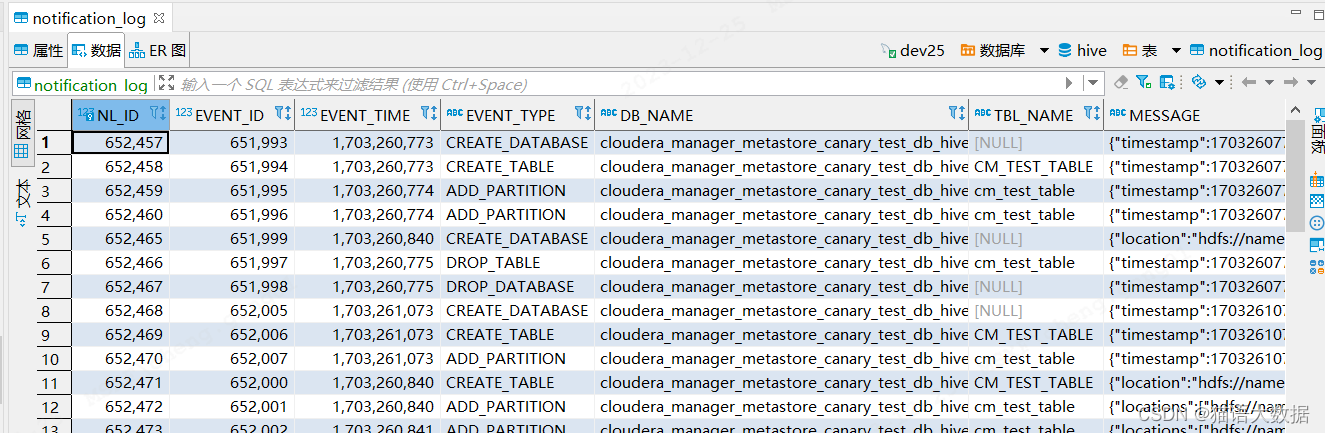
可以看到,这里面记录了增量的变更元数据,涉及的类型在 Hive EventType 定义中可见
public abstract class HCatEventMessage {
/**
* Enumeration of all supported types of Metastore operations.
*/
public static enum EventType {
CREATE_DATABASE(HCatConstants.HCAT_CREATE_DATABASE_EVENT),
DROP_DATABASE(HCatConstants.HCAT_DROP_DATABASE_EVENT),
CREATE_TABLE(HCatConstants.HCAT_CREATE_TABLE_EVENT),
DROP_TABLE(HCatConstants.HCAT_DROP_TABLE_EVENT),
ADD_PARTITION(HCatConstants.HCAT_ADD_PARTITION_EVENT),
DROP_PARTITION(HCatConstants.HCAT_DROP_PARTITION_EVENT),
ALTER_TABLE(HCatConstants.HCAT_ALTER_TABLE_EVENT),
ALTER_PARTITION(HCatConstants.HCAT_ALTER_PARTITION_EVENT),
INSERT(HCatConstants.HCAT_INSERT_EVENT),
CREATE_FUNCTION(HCatConstants.HCAT_CREATE_FUNCTION_EVENT),
DROP_FUNCTION(HCatConstants.HCAT_DROP_FUNCTION_EVENT),
CREATE_INDEX(HCatConstants.HCAT_CREATE_INDEX_EVENT),
DROP_INDEX(HCatConstants.HCAT_DROP_INDEX_EVENT),
ALTER_INDEX(HCatConstants.HCAT_ALTER_INDEX_EVENT);
...
而第二列的 eventId 就是关键,在 get_next_notification 的 NotificationEventRequest 中,就携带了上次同步的最大 eventId,HMS 只需要从数据库里查出比参数 eventId 大的变更事件日志就可以了,具体逻辑在 Hive ObjectStore 中可以看到,这里 Sentry 是使用了 Datanucleus 框架的 API。
public NotificationEventResponse getNextNotification(NotificationEventRequest rqst) {
boolean commited = false;
Query query = null;
NotificationEventResponse result = new NotificationEventResponse();
result.setEvents(new ArrayList<NotificationEvent>());
try {
openTransaction();
long lastEvent = rqst.getLastEvent();
query = pm.newQuery(MNotificationLog.class, "eventId > lastEvent"); // 就这里
query.declareParameters("java.lang.Long lastEvent");
query.setOrdering("eventId ascending");
Collection<MNotificationLog> events = (Collection) query.execute(lastEvent);
commited = commitTransaction();
if (events == null) {
return result;
}
Iterator<MNotificationLog> i = events.iterator();
int maxEvents = rqst.getMaxEvents() > 0 ? rqst.getMaxEvents() : Integer.MAX_VALUE;
int numEvents = 0;
while (i.hasNext() && numEvents++ < maxEvents) {
result.addToEvents(translateDbToThrift(i.next()));
}
return result;
}
...
然后 Sentry 接收到这些信息后解析后进行对应事件的处理,逻辑其实都比较简单。以一次 drop table 的事件为例,原先赋予在这张表上的角色权限,就得都删掉,因为表都不存在了,自然就不应该维护表的权限了。
2.2、SentryHiveAuthorizationTaskFactoryImply
然后我们再来聊一下这个 SentryHiveAuthorizationTaskFactoryImply,它其实是实现了 HiveAuthorizationTaskFactory 接口,取代了默认的 HiveAuthorizationTaskFactoryImply。从这个名字能看出来是一个工厂类,作用是在解析 sql 的时候,生成对应 sql 的 org.apache.hadoop.hive.ql.exec.Task。实际要起作用的,就是对赋权有关的语句进行拦截,然后通知 Sentry 执行对应的赋权操作。以一个赋权语句 grant xxx on xx.xx to role xx 为例,SentryHiveAuthorizationTaskFactoryImply 就会创建出 Task 的子类 SentryGrantRevokeTask,其实例对象在执行的时候,就会调 processGrantDDL,最终调到 Sentry 客户端的 alter_Sentry_role_grant_privilege 方法,签名如下:
public TAlterSentryRoleGrantPrivilegeResponse alter_Sentry_role_grant_privilege(TAlterSentryRoleGrantPrivilegeRequest request) throws org.apache.thrift.TException;
TAlterSentryRoleGrantPrivilegeRequest 里面包含了这条赋权的所有信息,那么 Sentry server收到消息后要做的事情也很简单,就是将角色和权限的映射关系持久化到数据库中,对应的表为 sentry_role_db_privilege_map 。
2.3、SentryMetaStorePostEventListener
我们知道,Hive 的 Server2 和 HMS 是可以独立部署的,如果有的消息直接走的 HMS,那么前面的 SentryHiveAuthorizationTaskFactoryImply 可能就捕获不到了,但是,无论怎么样,这些数据必然都会经过 HMS,所以只要在 HMS 这一层做了拦截,那肯定就会万无一失了,所以 SentryMetaStorePostEventListener 就是在做这样的事。
SentryMetaStorePostEventListener 是 Hive MetaStorePostEventListener 的子类,从名字可以看出来,是 HMS 本身基于监听器模式提供的扩展点。post 关键字说明了,在每一次 HMS 自己处理 event 之前,SentryMetaStorePostEventListener 就会先一步拦截执行相关操作,这部分的逻辑其实和上面的 SentryHiveAuthorizationTaskFactoryImply 类似,都是最终调到 Sentry 客户端对应事件的接口。
这里顺便提一嘴,这个拓展点可以做的事情有很多,比如元数据采集,就可以自定义一个 listener 来拦截。
3、Sentry 如何提供鉴权能力
接下来在下一篇博客中会选择几个比较典型的插件的实现,进行实现原理的剖析,就不放在一起了,不然篇幅过长(也许是害怕没墨汁了😼)。先简单聊一下实现原理和使用方式。
3.1、实现原理
首先必须得说,得益于各个数据组件自身的可插件设计,本身提供了各自的拓展点,才能让各类权限插件能一展身手,无侵入,可插拔式地管理好整个权限生态。
Sentry 本身提供了不少的组件插件,比如 Hive、HBase、Kafka、Solr、HDSF,虽然没有提供其他比较热门的框架比如 Spark、Presto 等,但其实都有对应的开源实现,也基本属于可以直接开箱即用。
Sentry 的插件入口,通常是实现了各个组件提供的接口类,各个组件会有一个默认实现,那 Sentry 通过自己的实现类,和 Sentry 服务进行通信,获取到插件正在进行的鉴权动作所需要的权限信息,就能实现鉴权。
3.2、使用方式
一般来讲,使用玩法通常都差不多,准备好插件包到类路径下,然后修改组件的配置项,把各自组件提供鉴权的拓展点的配置项改为 Sentry 插件里提供的类名,配置信息里还添加上 Sentry 服务的 ip 和端口。重启组件服务后,就会读取配置文件里面的全类名,通过反射的方式加载插件到内存中,按照实现逻辑提供鉴权服务。
Sentry 对外以 Thrift 的方式暴露接口,插件的 Sentry 客户端就能拿到权限数据。暗示一下这里就和后续会讲到的平滑迁移 Ranger 有关了。
拜拜ヾ(•ω•`)o~

















 6193
6193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











