







本赛题是由科大讯飞xDatawhale联合举办
地址:https://challenge.xfyun.cn/topic/info?type=telecom-customer
适千里者,三月聚粮。
文章目录
提示:以下是本篇文章正文内容
一、赛题概要
1.赛题背景
随着市场饱和度的上升,电信运营商的竞争也越来越激烈,电信运营商亟待解决减少用户流失,延长用户生命周期的问题。对于客户流失率而言,每增加5%,利润就可能随之降低25%-85%。因此,如何减少电信用户流失的分析与预测至关重要。
鉴于此,运营商会经常设有客户服务部门,该部门的职能主要是做好客户流失分析,赢回高概率流失的客户,降低客户流失率。某电信机构的客户存在大量流失情况,导致该机构的用户量急速下降。面对如此头疼的问题,该机构将部分客户数据开放,诚邀大家帮助他们建立流失预测模型来预测可能流失的客户。
2.赛题任务
给定某电信机构实际业务中的相关客户信息,包含69个与客户相关的字段,其中“是否流失”字段表明客户会否会在观察日期后的两个月内流失。任务目标是通过训练集训练模型,来预测客户是否会流失,以此为依据开展工作,提高用户留存。
3.赛题数据
赛题数据由训练集和测试集组成,总数据量超过25w,包含69个特征字段。为了保证比赛的公平性,将会从中抽取15万条作为训练集,3万条作为测试集,同时会对部分字段信息进行脱敏。
特征字段
客户ID、地理区域、是否双频、是否翻新机、当前手机价格、手机网络功能、婚姻状况、家庭成人人数、信息库匹配、预计收入、信用卡指示器、当前设备使用天数、在职总月数、家庭中唯一订阅者的数量、家庭活跃用户数、… 、过去六个月的平均每月使用分钟数、过去六个月的平均每月通话次数、过去六个月的平均月费用、是否流失
4.评价指标
AUC评价指标(该指标常用于二分类的预测任务中)
from Sklearn.metrics import roc_auc_score
y_ture = [0 , 1 , 0 , 1 , 1 , 1 ]
y_pred = [0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 ]
score = roc_auc_score(y_true , y_pred)
5.分析
二、数据探索(EDA)
处于项目特点,我们这次选择使用 jupyter notebook 进行所有操作。
1.导入库
#导入库
import pandas as pd
import os
import gc
import lightgbm as lgb
import xgboost as xgb
from catboost import CatBoostRegressor
from hyperopt import hp, fmin, tpe
from sklearn.linear_model import SGDRegressor, LinearRegression, Ridge
from sklearn.preprocessing import MinMaxScaler
from gensim.models import Word2Vec
import math
import numpy as np
from numpy.random import RandomState
from tqdm import tqdm
from sklearn.model_selection import StratifiedKFold, KFold
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score, log_loss
import matplotlib.pyplot as plt
import time
import warnings
warnings.filterwarnings('ignore')
2.读取并查看数据
# 使用pandas库的.read_csv读取训练集与测试集数据
train_data = pd.read_csv('train.csv)
test_data = pd.read_csv('test.csv)
# 使用.head()查看数据前5行
train_data.head()
test_data.head()
结果:

# 使用.info()查看数据的信息
train_data.info()
test_data.info()
结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150000 entries, 0 to 149999
Data columns (total 69 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 客户ID 150000 non-null int64
1 地理区域 150000 non-null int64
2 是否双频 150000 non-null int64
3 是否翻新机 150000 non-null int64
4 当前手机价格 150000 non-null int64
5 手机网络功能 150000 non-null int64
6 婚姻状况 150000 non-null int64
7 家庭成人人数 150000 non-null int64
8 信息库匹配 150000 non-null int64
9 预计收入 150000 non-null int64
10 信用卡指示器 150000 non-null int64
11 当前设备使用天数 150000 non-null int64
12 在职总月数 150000 non-null int64
13 家庭中唯一订阅者的数量 150000 non-null int64
14 家庭活跃用户数 150000 non-null int64
15 新手机用户 150000 non-null int64
16 信用等级代码 150000 non-null int64
17 平均月费用 150000 non-null int64
18 每月平均使用分钟数 150000 non-null int64
19 平均超额使用分钟数 150000 non-null int64
20 平均超额费用 150000 non-null int64
21 平均语音费用 150000 non-null int64
22 数据超载的平均费用 150000 non-null int64
23 平均漫游呼叫数 150000 non-null int64
24 当月使用分钟数与前三个月平均值的百分比变化 150000 non-null int64
25 当月费用与前三个月平均值的百分比变化 150000 non-null int64
26 平均掉线语音呼叫数 150000 non-null int64
27 平均丢弃数据呼叫数 150000 non-null int64
28 平均占线语音呼叫数 150000 non-null int64
29 平均占线数据调用次数 150000 non-null int64
30 平均未接语音呼叫数 150000 non-null int64
31 未应答数据呼叫的平均次数 150000 non-null int64
32 尝试拨打的平均语音呼叫次数 150000 non-null int64
33 尝试数据调用的平均数 150000 non-null int64
34 平均接听语音电话数 150000 non-null int64
35 平均完成的语音呼叫数 150000 non-null int64
36 完成数据调用的平均数 150000 non-null int64
37 平均客户服务电话次数 150000 non-null int64
38 使用客户服务电话的平均分钟数 150000 non-null int64
39 一分钟内的平均呼入电话数 150000 non-null int64
40 平均三通电话数 150000 non-null int64
41 已完成语音通话的平均使用分钟数 150000 non-null int64
42 平均呼入和呼出高峰语音呼叫数 150000 non-null int64
43 平均峰值数据调用次数 150000 non-null int64
44 使用高峰语音通话的平均不完整分钟数 150000 non-null int64
45 平均非高峰语音呼叫数 150000 non-null int64
46 非高峰数据呼叫的平均数量 150000 non-null int64
47 平均掉线或占线呼叫数 150000 non-null int64
48 平均尝试调用次数 150000 non-null int64
49 平均已完成呼叫数 150000 non-null int64
50 平均呼叫转移呼叫数 150000 non-null int64
51 平均呼叫等待呼叫数 150000 non-null int64
52 账户消费限额 150000 non-null int64
53 客户生命周期内的总通话次数 150000 non-null int64
54 客户生命周期内的总使用分钟数 150000 non-null int64
55 客户生命周期内的总费用 150000 non-null int64
56 计费调整后的总费用 150000 non-null int64
57 计费调整后的总分钟数 150000 non-null int64
58 计费调整后的呼叫总数 150000 non-null int64
59 客户生命周期内平均月费用 150000 non-null int64
60 客户生命周期内的平均每月使用分钟数 150000 non-null int64
61 客户整个生命周期内的平均每月通话次数 150000 non-null int64
62 过去三个月的平均每月使用分钟数 150000 non-null int64
63 过去三个月的平均每月通话次数 150000 non-null int64
64 过去三个月的平均月费用 150000 non-null int64
65 过去六个月的平均每月使用分钟数 150000 non-null int64
66 过去六个月的平均每月通话次数 150000 non-null int64
67 过去六个月的平均月费用 150000 non-null int64
68 是否流失 150000 non-null int64
dtypes: int64(69)
memory usage: 79.0 MB
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 30000 entries, 0 to 29999
Data columns (total 68 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 客户ID 30000 non-null int64
1 地理区域 30000 non-null int64
2 是否双频 30000 non-null int64
3 是否翻新机 30000 non-null int64
4 当前手机价格 30000 non-null int64
5 手机网络功能 30000 non-null int64
6 婚姻状况 30000 non-null int64
7 家庭成人人数 30000 non-null int64
8 信息库匹配 30000 non-null int64
9 预计收入 30000 non-null int64
10 信用卡指示器 30000 non-null int64
11 当前设备使用天数 30000 non-null int64
12 在职总月数 30000 non-null int64
13 家庭中唯一订阅者的数量 30000 non-null int64
14 家庭活跃用户数 30000 non-null int64
15 新手机用户 30000 non-null int64
16 信用等级代码 30000 non-null int64
17 平均月费用 30000 non-null int64
18 每月平均使用分钟数 30000 non-null int64
19 平均超额使用分钟数 30000 non-null int64
20 平均超额费用 30000 non-null int64
21 平均语音费用 30000 non-null int64
22 数据超载的平均费用 30000 non-null int64
23 平均漫游呼叫数 30000 non-null int64
24 当月使用分钟数与前三个月平均值的百分比变化 30000 non-null int64
25 当月费用与前三个月平均值的百分比变化 30000 non-null int64
26 平均掉线语音呼叫数 30000 non-null int64
27 平均丢弃数据呼叫数 30000 non-null int64
28 平均占线语音呼叫数 30000 non-null int64
29 平均占线数据调用次数 30000 non-null int64
30 平均未接语音呼叫数 30000 non-null int64
31 未应答数据呼叫的平均次数 30000 non-null int64
32 尝试拨打的平均语音呼叫次数 30000 non-null int64
33 尝试数据调用的平均数 30000 non-null int64
34 平均接听语音电话数 30000 non-null int64
35 平均完成的语音呼叫数 30000 non-null int64
36 完成数据调用的平均数 30000 non-null int64
37 平均客户服务电话次数 30000 non-null int64
38 使用客户服务电话的平均分钟数 30000 non-null int64
39 一分钟内的平均呼入电话数 30000 non-null int64
40 平均三通电话数 30000 non-null int64
41 已完成语音通话的平均使用分钟数 30000 non-null int64
42 平均呼入和呼出高峰语音呼叫数 30000 non-null int64
43 平均峰值数据调用次数 30000 non-null int64
44 使用高峰语音通话的平均不完整分钟数 30000 non-null int64
45 平均非高峰语音呼叫数 30000 non-null int64
46 非高峰数据呼叫的平均数量 30000 non-null int64
47 平均掉线或占线呼叫数 30000 non-null int64
48 平均尝试调用次数 30000 non-null int64
49 平均已完成呼叫数 30000 non-null int64
50 平均呼叫转移呼叫数 30000 non-null int64
51 平均呼叫等待呼叫数 30000 non-null int64
52 账户消费限额 30000 non-null int64
53 客户生命周期内的总通话次数 30000 non-null int64
54 客户生命周期内的总使用分钟数 30000 non-null int64
55 客户生命周期内的总费用 30000 non-null int64
56 计费调整后的总费用 30000 non-null int64
57 计费调整后的总分钟数 30000 non-null int64
58 计费调整后的呼叫总数 30000 non-null int64
59 客户生命周期内平均月费用 30000 non-null int64
60 客户生命周期内的平均每月使用分钟数 30000 non-null int64
61 客户整个生命周期内的平均每月通话次数 30000 non-null int64
62 过去三个月的平均每月使用分钟数 30000 non-null int64
63 过去三个月的平均每月通话次数 30000 non-null int64
64 过去三个月的平均月费用 30000 non-null int64
65 过去六个月的平均每月使用分钟数 30000 non-null int64
66 过去六个月的平均每月通话次数 30000 non-null int64
67 过去六个月的平均月费用 30000 non-null int64
dtypes: int64(68)
memory usage: 15.6 MB
# 使用.describe()查看数据的描述性统计信息
train_data.describe()
结果
客户ID 地理区域 是否双频 是否翻新机 \
count 150000.000000 150000.000000 150000.000000 150000.000000
mean 74999.500000 8.060327 0.618253 -0.094287
std 43301.414527 5.065028 0.539597 0.292228
min 0.000000 -1.000000 -1.000000 -1.000000
25% 37499.750000 4.000000 0.000000 0.000000
50% 74999.500000 8.000000 1.000000 0.000000
75% 112499.250000 12.000000 1.000000 0.000000
max 149999.000000 18.000000 1.000000 0.000000
当前手机价格 手机网络功能 婚姻状况 家庭成人人数 \
count 150000.000000 150000.000000 150000.000000 150000.000000
mean 705.279413 0.286100 1.629427 1.582027
std 419.211310 0.587749 1.231911 1.714654
min -1.000000 -1.000000 -1.000000 -1.000000
25% 225.000000 0.000000 1.000000 0.000000
50% 699.000000 0.000000 1.000000 1.000000
75% 1049.000000 0.000000 3.000000 3.000000
max 3499.000000 2.000000 4.000000 6.000000
信息库匹配 预计收入 ... 客户生命周期内平均月费用 客户生命周期内的平均每月使用分钟数 \
count 150000.000000 150000.000000 ... 150000.000000 150000.000000
mean 0.136187 3.906173 ... 56.727240 479.829973
std 0.346488 3.156789 ... 34.368247 427.972362
min -1.000000 -1.000000 ... 0.000000 0.000000
25% 0.000000 1.000000 ... 35.000000 177.000000
50% 0.000000 5.000000 ... 49.000000 361.000000
75% 0.000000 6.000000 ... 68.000000 655.000000
max 1.000000 9.000000 ... 902.000000 7040.000000
客户整个生命周期内的平均每月通话次数 过去三个月的平均每月使用分钟数 过去三个月的平均每月通话次数 过去三个月的平均月费用 \
count 150000.000000 150000.000000 150000.000000 150000.000000
mean 171.989867 515.756253 179.328827 58.243247
std 163.881701 520.295608 187.742919 43.516844
min 0.000000 0.000000 0.000000 1.000000
25% 64.000000 154.000000 56.000000 33.000000
50% 127.000000 358.000000 126.000000 48.000000
75% 227.000000 708.000000 239.000000 69.000000
max 2716.000000 7716.000000 3261.000000 1593.000000
过去六个月的平均每月使用分钟数 过去六个月的平均每月通话次数 过去六个月的平均月费用 是否流失
count 150000.000000 150000.000000 150000.000000 150000.000000
mean 492.528440 172.607533 56.273753 0.500280
std 486.577663 178.694606 39.150687 0.500002
min -1.000000 -1.000000 -1.000000 0.000000
25% 150.000000 55.000000 34.000000 0.000000
50% 350.000000 123.000000 48.000000 1.000000
75% 681.000000 232.000000 68.000000 1.000000
max 7217.000000 2887.000000 866.000000 1.000000
[8 rows x 69 columns]
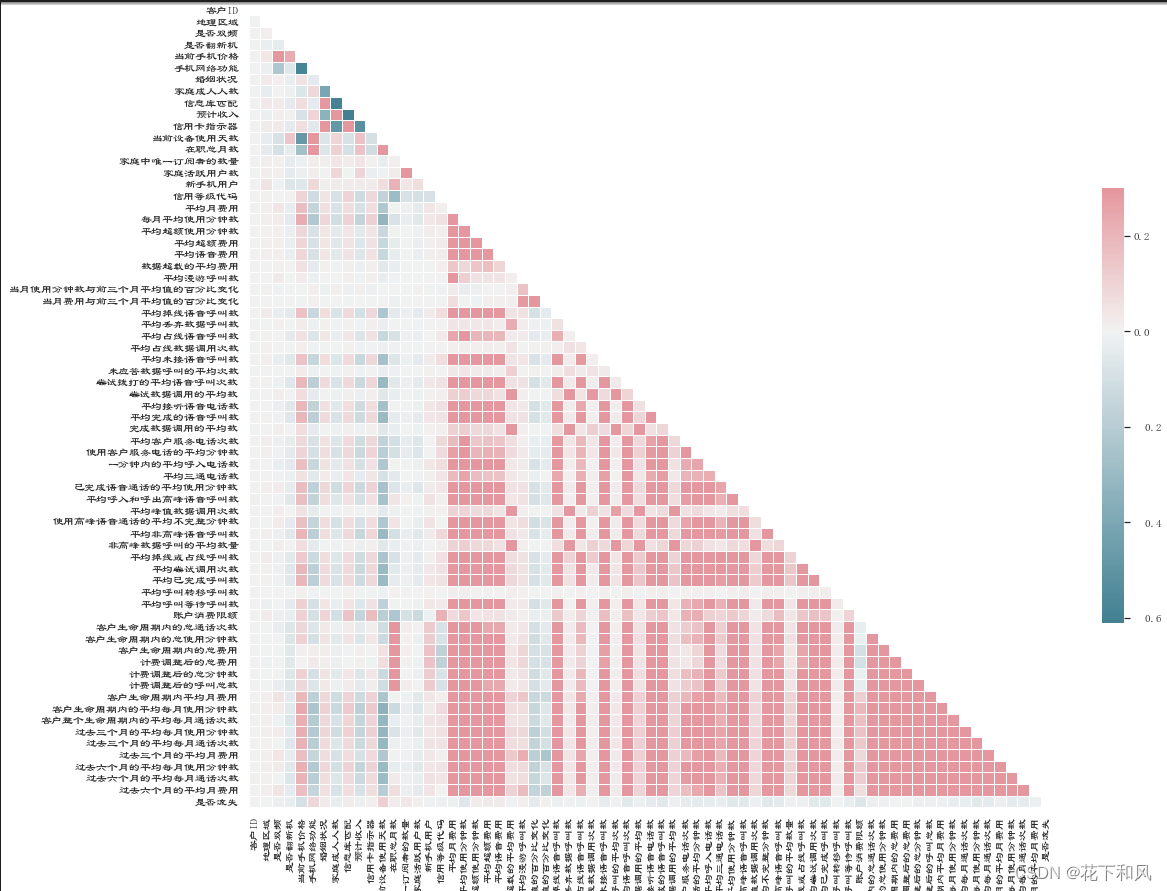
3.相关性分析
sns.set(style="white" , font='LiSu')
# 使用.corr(method='pearson')进行相关性分析,method= pearson,kendall,spearman 可对应三种方法,默认使用pearson
corr = train_data.corr()
# Generate a mask for the upper triangle
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# 设置图像大小
f, ax = plt.subplots(figsize=(18, 16))
# 创建调色板,设置热力图颜色
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# 使用上述设置和数据画热力图
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
# 展示
plt.show()
# 查看相关性系数
pd.set_option("display.max_columns", None)
pd.set_option( "display.max_rows" , None)
corr = train_data.corr()
print (corr)
# 重点查看其他字段与目标值之间得到相关性系数,并将这部分数据copy出来,并使用.sort_values进行降序排列
isOrNot_corr = corr['是否流失'].copy().sort_values(ascending=False)
print (isOrNot_corr)
结果
# 这里只展示目标值相关系数
是否流失 1.000000
当前设备使用天数 0.117242
手机网络功能 0.088076
家庭中唯一订阅者的数量 0.035298
婚姻状况 0.024911
平均语音费用 0.024728
平均超额费用 0.023879
信息库匹配 0.022176
在职总月数 0.021920
平均超额使用分钟数 0.019263
家庭活跃用户数 0.014626
信用卡指示器 0.013053
平均漫游呼叫数 0.011900
当月费用与前三个月平均值的百分比变化 0.006713
客户ID 0.001306
平均呼叫转移呼叫数 -0.003266
计费调整后的总费用 -0.003317
地理区域 -0.003459
客户生命周期内的总费用 -0.003480
平均占线数据调用次数 -0.005112
未应答数据呼叫的平均次数 -0.006067
数据超载的平均费用 -0.006451
新手机用户 -0.006805
平均丢弃数据呼叫数 -0.008222
客户生命周期内平均月费用 -0.010270
平均峰值数据调用次数 -0.011339
信用等级代码 -0.012046
非高峰数据呼叫的平均数量 -0.012354
平均占线语音呼叫数 -0.012965
完成数据调用的平均数 -0.013026
平均掉线语音呼叫数 -0.013157
过去六个月的平均月费用 -0.013646
过去三个月的平均月费用 -0.013932
尝试数据调用的平均数 -0.013940
平均月费用 -0.014820
客户生命周期内的总通话次数 -0.017114
计费调整后的呼叫总数 -0.017572
平均掉线或占线呼叫数 -0.017906
预计收入 -0.018576
客户生命周期内的总使用分钟数 -0.018654
计费调整后的总分钟数 -0.019213
是否双频 -0.019965
家庭成人人数 -0.024942
客户整个生命周期内的平均每月通话次数 -0.025390
平均三通电话数 -0.025761
客户生命周期内的平均每月使用分钟数 -0.026500
是否翻新机 -0.029043
平均呼叫等待呼叫数 -0.030874
一分钟内的平均呼入电话数 -0.033057
过去六个月的平均每月通话次数 -0.034927
平均未接语音呼叫数 -0.036626
平均客户服务电话次数 -0.037086
当月使用分钟数与前三个月平均值的百分比变化 -0.038794
使用客户服务电话的平均分钟数 -0.040060
过去六个月的平均每月使用分钟数 -0.040761
平均接听语音电话数 -0.041215
过去三个月的平均每月通话次数 -0.044770
平均非高峰语音呼叫数 -0.047101
尝试拨打的平均语音呼叫次数 -0.049644
平均尝试调用次数 -0.050090
平均呼入和呼出高峰语音呼叫数 -0.050286
使用高峰语音通话的平均不完整分钟数 -0.051437
过去三个月的平均每月使用分钟数 -0.051533
平均完成的语音呼叫数 -0.052980
平均已完成呼叫数 -0.053415
已完成语音通话的平均使用分钟数 -0.054818
每月平均使用分钟数 -0.060694
账户消费限额 -0.066694
当前手机价格 -0.101998
Name: 是否流失, dtype: float64
皮尔逊相关系数通常情况下通过以下取值范围判断变量的相关强度:
0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
与是否流失相关的字段:当前设备使用天数(0.117242)、手机网络功能(0.088076)、家庭中唯一订阅者的数量(0.035298),根据相关强度属于极弱相关或无相关。
三、构建模型
1.数据准备
代码如下:
# 将除客户ID与目标值的字段,作为特征值字段
features = [f for f in data.columns if f not in ['是否流失‘ , ’客户ID']]
# 去除缺失值
train = data[data['是否流失'].notnull()].reset_index(drop=True)
test = data[data['是否流失'].isnull()].reset_index(drop=True)
# 按照特征值字段设置训练集合测试集的特征值
x_train = train[features]
x_test = test[features]
# 设置训练集的目标值
y_train = train['是否流失']
2.构建模型
这里我们使用lgb、xgb、cat三个分类器进行模型训练
# 定义函数
def cv_model(clf , train_x , train_y , test_x , clf_name):
# 使用K折交叉验证(KFold),设定5折
folds = 5
seed = 2022
kf = KFold(n_splits=folds , shuffle=True , random_state=seed)
# 用零填充一个新数组
train = np.zeros(train_x.shape[0])
test = np.zeros(test_x.shape[0])
# 设定一个空的分数列表
cv_scores = []
# 使用enumerate枚举5折交叉验证,
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('*************************************第{}次验证*************************************'.format(str(i + 1)))
#
trn_x , trn_y , val_x , val_y = train_x.iloc[train_index] , train_y[train_index] ,
train_x.iloc[valid_index] , train_y[valid_index]
# 设定分类器
if clf_name == 'lgb' :
# 训练集
train_matrix = clf.Dataset(trn_x , label = trn_y)
# 验证集
valid_matrix = clf.Datasett(val_x , label = val_y)
# 参数设定
params = {
'boosting_type' = 'gbdt' ,
'objective' = 'binary' ,
'metric' = 'auc' ,
'min_child_weight' = 5 ,
'num_leaves' : 2 ** 5 ,
'lambda_12' : 10 ,
'features_fraction' : 0.7 ,
'bagging_fraction' : 0.7 ,
'bagging_freq' : 10 ,
'learning_rate' : 0.2 ,
'seed' : 2022 ,
'n_jobs' : -1
}
#
model = clf.train(params , train_matrix , 50000 , valid_sets = [train_matrix , valid_matrix] ,
catagorical_frature = [] , verbose_eval = 3000 , early_stopping_rounds = 200)
val_pred = model.predict(val_x , num_iteration = model.best_iteration)
test_pred = model.predict(test_x , num_iteration = model.best_iteration)
print(list(sorted(zip(features , model.features_importance("gain")) , key = lambda x : x[1] , reverse=True))[:20])
if clf_name == "xgb":
train_matrix = clf.DMatrix(trn_x , label=trn_y)
valid_matrix = clf.DMatrix(val_x , label=val_y)
test_matrix = clf.DMatrix(test_x)
params = {'booster': 'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'gamma': 1,
'min_child_weight': 1.5,
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.2,
'tree_method': 'exact',
'seed': 2020,
'nthread': 36,
"silent": True,
}
watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]
model = clf.train(params, train_matrix, num_boost_round=50000, evals=watchlist, verbose_eval=3000, early_stopping_rounds=200)
val_pred = model.predict(valid_matrix, ntree_limit=model.best_ntree_limit)
test_pred = model.predict(test_matrix , ntree_limit=model.best_ntree_limit)
if clf_name == "cat":
params = {'learning_rate': 0.2, 'depth': 5, 'l2_leaf_reg': 10, 'bootstrap_type': 'Bernoulli',
'od_type': 'Iter', 'od_wait': 50, 'random_seed': 11, 'allow_writing_files': False}
model = clf(iterations=20000, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
cat_features=[], use_best_model=True, verbose=3000)
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
train[valid_index] = val_pred
test = test_pred / kf.n_splits
cv_scores.append(roc_auc_score(val_y, val_pred))
print(cv_scores)
print("%s_scotrainre_list:" % clf_name, cv_scores)
print("%s_score_mean:" % clf_name, np.mean(cv_scores))
print("%s_score_std:" % clf_name, np.std(cv_scores))
return train, test
# 定义lgb模型
def lgb_model(x_train , y_train , x_test) :
# 调用设定的cv_model类
lgb_train , lgb_test = cv_model(lgb , x_train , y_train , x_test , 'lgb')
# 返回
return lgb_train , lgb_test
# 定义xgb模型
def xgb_model(x_train , y_train , x_test) :
# 调用设定的cv_model函数
xgb_train , xgb_test = cv_model(xgb , x_train , y_train , x_test , 'xgb')
# 返回
return xgb_train , xgb_test
# 定义cat模型
def cat_model(x_train , y_train , x_test) :
# 调用设定的cv_model类
cat_train , cat_test = cv_model(CatBoostRegressor , x_train , y_train , x_test , 'cat')
# 返回
return cat_train , cat_test
lgb_train , lgb_test = lgb_model(x_train , y_train , x_test)
3.储存数据
test['是否流失'] = lgb_test
test[['客户ID','是否流失']].to_csv('test_sub.csv', index=False)
4.上传结果查看分数
















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









