







本系列学习笔记使用《python3网络爬虫开发实战》第二版
该书项目地址:https://github.com/Python3WebSpider
崔庆才老师的个人网站:https://cuiqingcai.com
适千里者,三月聚粮。
文章目录
前言
在上一篇笔记【爬虫学习笔记】二、代理与代理池的使用中,我们学会了如何使用代理池,但笔者在记录学习使用过程中由于半路出家的原因,基础并不扎实,因此想要巩固几个在爬虫中常用的数据解析库的使用方法。在此之前,需要具备一些简单的html&css知识,了解web网页基础。本篇文章的内容相对简单,不必专门学习,随用随看可能会更加高效。
大约阅读时长为10分钟。
对于新手而言,可以收获:
- BS4 & Xpath & pyquery & parsel的基本用法
本案例对应的学习内容为《python3网络爬虫开发实战》第二版中第3章的内容
所有库的学习均使用此案例:
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
一、Beautiful Soup
1.创建Beautiful Soup对象
# 导入包
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc , 'html.parser')
关于解析器
这里的 html.parser 解析器是python内置的标准库,还有其他3中常用的主要解析器,对比如下:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库,执行速度适中,文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快,文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, [“lxml-xml”]),BeautifulSoup(markup, “xml”) | 速度快,唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性,以浏览器的方式解析文档,生成HTML5格式的文档 | 速度慢,不依赖外部扩展 |
Beautiful Soup将HTML文档转换成一个树状结构
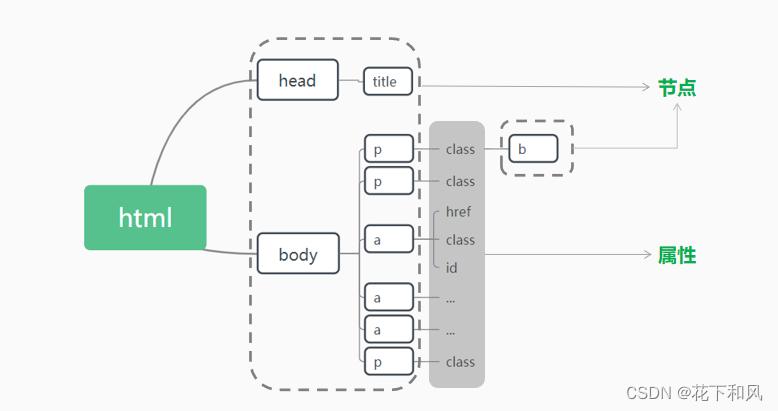
2.获取指定的内容
2.1 获取标签
# 获取标签
soup.title
soup.p
soup.a
返回结果
<title>The Dormouse's story</title>
<p class="title"><b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b></p>
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
这里注意,有很多个重复的标签p、a,但是只返回了第一个。
2.2 获取属性
1.获取所有的属性
# 使用.attrs取得所有属性
print(soup.p.attrs)
print(type(soup.p.attrs))
print(soup.a.attrs)
print(type(soup.a.attrs))
返回结果,可以看出来是字典
{'class': ['title']}
<class 'dict'>
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
<class 'dict'>
2.获取指定标签的属性的值
使用.get()方法与[ ]方法是一样的
#我们这里指定获取第一个a标签中的href属性的值,以及id属性的值
print(soup.a.get('href'))
print(soup.a['href'])
print(soup.a.get('id'))
print(soup.a['id'])
返回结果
http://example.com/elsie
http://example.com/elsie
link1
link1
3.有时一个属性会对应多个值
例如<p class="body strikeout"></p>'中,p标签的class属性,有两个值body和strikeout,那么通过上述方法获取值时会返回一个列表
css_soup = BeautifulSoup('<p class="body strikeout"></p>')
print(css_soup.p['class'])
print(type(css_soup.p['class']))
返回结果
['body', 'strikeout']
<class 'list'>
2.3 获取内容
使用.string与.text获取标签内部的内容
# 获取内容
print(soup.p.string)
print(soup.p.text)
print(soup.a.string)
print(soup.a.text)
返回结果
None
The Dormouse's story
Elsie
Elsie
2.4 获取注释
comment = soup.p.b.prettify()
print(comment)
返回结果
<b>
The Dormouse's story
<!--Hey, buddy. Want to buy a used parser?-->
</b>
在以上操作中,对于重复的标签p、a只返回了第一个,那么我们如何去筛选想要的那个“p”呢?
3.搜索文档树
3.1使用.find_all
#
print(soup.find_all('p'))
print('------------------------------------------')
# 根据属性定位标签的第一种写法
print(soup.find_all(id='link1'))
print('------------------------------------------')
# 根据属性定位标签的第二种写法
print(soup.find_all('a' , attrs={'class':"sister"}))
print('------------------------------------------')
# 也可写成:
print(soup.find_all('a' , class_='sister'))
返回结果
[<p class="title"><b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b></p>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>, <p class="story">...</p>]
------------------------------------------
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
------------------------------------------
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
------------------------------------------
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
3.2 CSS选择器.select
# 通过标签逐层查找
print(soup.select('body a'))
print(soup.select('body b'))
返回结果
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
[<b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b>]
# 使用 > 找到某个标签下的直接子标签
print(soup.select("head > title"))
print('----------------------------')
print(soup.select("p > a"))
print('----------------------------')
# 使用:nth-of-type()定位
print(soup.select("p > a:nth-of-type(2)"))
print('----------------------------')
print(soup.select("p > a:nth-of-type(3)"))
print('----------------------------')
# 使用“#”定位id
print(soup.select("p > #link1"))
print('----------------------------')
# 当没有对应的直接子标签时,返回空值
print(soup.select("body > a"))
返回结果
[<title>The Dormouse's story</title>]
----------------------------
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
----------------------------
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
----------------------------
[<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
----------------------------
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
----------------------------
[]
# 通过id查找
print(soup.select('#link1'))
print('----------------------------')
# 找到兄弟节点
print(soup.select('#link1~.sister'))
print('----------------------------')
# 通过类名查找
print(soup.select('.title'))
返回结果
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
----------------------------
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
----------------------------
[<p class="title"><b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b></p>]
参考资料:
官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/#
二、Xpath
1.选取节点的常用路径
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| 通配符 | 描述 | 举例 | 结果 |
|---|---|---|---|
| * | 匹配任何元素节点 | xpath(‘div/*’) | 获取div下的所有子节点 |
| @* | 匹配任何属性节点 | xpath('div[@*]) | 选取所有带属性的div节点 |
| node() | 匹配任何类型的节点 |
2.实例
2.1 实例的引入
# 导入包
from lxml import etree
# 使用HTML类,初始化一个Xpath对象,etree会自动修正html文本
html = etree.HTML(html_doc)
# 使用.tostring()可以输出修正后的代码
result = etree.tostring(html)
print(result)
print('------------------------------------------')
# 使用.decode()的方法解码成utf-8格式
print(result.decode('utf-8'))
2.2 选取节点
# 获取所有祖先节点
print(html.xpath('//a[2]/ancestor::*'))
print('------------------------------------------')
# 获取某个祖先节点
print(html.xpath('//a[2]/ancestor::body'))
print('------------------------------------------')
# 获取所有的属性值
print(html.xpath('//a[2]/attribute::*'))
print('------------------------------------------')
# 获取所有的直接子节点
print(html.xpath('//a[2]/child::*'))
print('------------------------------------------')
# 获取所有的子孙节点
print(html.xpath('//a[2]/descendant::*'))
print('------------------------------------------')
# 获取当前节点后的所有节点
print(html.xpath('//a[2]/following::*'))
print('------------------------------------------')
# 获取当前节点后的第二个节点
print(html.xpath('//a[2]/following::*[2]'))
print('------------------------------------------')
# 获取当前节点的所有同级节点
print(html.xpath('//a[2]/following-sibling::*'))
返回结果
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
----------------------------
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
----------------------------
[<p class="title"><b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b></p>]
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
[<b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b>]
[<title>The Dormouse's story</title>]
----------------------------
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
----------------------------
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
----------------------------
[<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
----------------------------
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
----------------------------
[]
b'<html><head><title>The Dormouse\'s story</title></head>\n<body>\n<p class="title"><b>The Dormouse\'s story<!--Hey, buddy. Want to buy a used parser?--></b></p>\n\n<p class="story">Once upon a time there were three little sisters; and their names were\n<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,\n<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and\n<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;\nand they lived at the bottom of a well.</p>\n\n\n<p class="story">...</p>\n</body></html>'
------------------------------------------
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
2.3 属性匹配与属性获取
# 节点的属性匹配
print(html.xpath('//a[@class="sister"]'))
print('------------------------------------------')
# 获取节点的属性的值
print(html.xpath('//a/@href'))
返回结果
这里需要注意用[ ]获取的是节点,第二个方法获取的是属性的值。
[<Element a at 0x1bdd6313dc0>, <Element a at 0x1bdd6313f00>, <Element a at 0x1bdd6313b40>]
------------------------------------------
['http://example.com/elsie', 'http://example.com/lacie', 'http://example.com/tillie']
2.4 多属性匹配
这里涉及到contains()方法,在某个节点的某个属性有多个值时,经常使用。给第一个参数传入属性名称,第二个参数传入属性值,例如contains(@class,"sister")。
# 获取a节点中同时满足class中包含sister并且id是link1的节点的内容
print(html.xpath('//a[contains(@class,"sister") and @id="link1"]/text()'))
返回结果
['Elsie']
2.5 按序选择
# 获取第二个a节点,返回其中内容
print(html.xpath('//a[2]/text()'))
print('------------------------------------------')
# 获取最后一个a节点,返回其中内容
print(html.xpath('//a[last()]/text()'))
print('------------------------------------------')
# 获取位置序号小于3的a节点,返回其中内容
print(html.xpath('//a[position()<3]/text()'))
print('------------------------------------------')
# 获取倒数第二个a节点,返回其中内容
print(html.xpath('//a[last()-1]/text()'))
返回结果
['Lacie']
------------------------------------------
['Tillie']
------------------------------------------
['Elsie', 'Lacie']
------------------------------------------
['Lacie']
2.6 节点轴选择
# 获取所有祖先节点
print(html.xpath('//a[2]/ancestor::*'))
print('------------------------------------------')
# 获取某个祖先节点
print(html.xpath('//a[2]/ancestor::body'))
print('------------------------------------------')
# 获取所有的属性值
print(html.xpath('//a[2]/attribute::*'))
print('------------------------------------------')
# 获取所有的直接子节点
print(html.xpath('//a[2]/child::*'))
print('------------------------------------------')
# 获取所有的子孙节点
print(html.xpath('//a[2]/descendant::*'))
print('------------------------------------------')
# 获取当前节点后的所有节点
print(html.xpath('//a[2]/following::*'))
print('------------------------------------------')
# 获取当前节点后的第二个节点
print(html.xpath('//a[2]/following::*[2]'))
print('------------------------------------------')
# 获取当前节点的所有同级节点
print(html.xpath('//a[2]/following-sibling::*'))
返回结果
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
----------------------------
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
----------------------------
[<p class="title"><b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b></p>]
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
[<b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b>]
[<title>The Dormouse's story</title>]
----------------------------
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
----------------------------
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
----------------------------
[<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
----------------------------
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
----------------------------
[]
b'<html><head><title>The Dormouse\'s story</title></head>\n<body>\n<p class="title"><b>The Dormouse\'s story<!--Hey, buddy. Want to buy a used parser?--></b></p>\n\n<p class="story">Once upon a time there were three little sisters; and their names were\n<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,\n<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and\n<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;\nand they lived at the bottom of a well.</p>\n\n\n<p class="story">...</p>\n</body></html>'
------------------------------------------
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
Collecting lxml
Using cached lxml-4.9.1-cp39-cp39-win_amd64.whl (3.6 MB)
Installing collected packages: lxml
Successfully installed lxml-4.9.1
[notice] A new release of pip available: 22.1.2 -> 22.2.1
[notice] To update, run: python.exe -m pip install --upgrade pip
Note: you may need to restart the kernel to use updated packages.
[<Element html at 0x1bdd4665f40>, <Element body at 0x1bdd4693140>, <Element p at 0x1bdd62aa780>]
------------------------------------------
[<Element body at 0x1bdd62aa780>]
------------------------------------------
['http://example.com/lacie', 'sister', 'link2']
------------------------------------------
[]
------------------------------------------
[]
------------------------------------------
[<Element a at 0x1bdd62da1c0>, <Element p at 0x1bdd62da240>]
------------------------------------------
[<Element p at 0x1bdd62da240>]
------------------------------------------
[<Element a at 0x1bdd62da1c0>]
更多的内容可以在W3C里继续学习,内容很多,这里只列了比较常用的。
参考资料:
官方文档:https://lxml.de/index.html#documentation
https://cuiqingcai.com/202231.html
https://www.w3school.com.cn/xpath/index.asp
推荐一个好用的插件:Xpath Helper
三、Pyquery
1.初始化
有三种初始化的方式,传入一段html代码,传入一个url,传入一个文件,如下
from pyquery import PyQuery as pq
doc = pq(html_doc)
doc_url = pq(url='https://cuiqingcai.com/')
doc_file = pq(filename = 'demo.html')
2.基本的选择器
2.1获取节点、文本、属性
节点中,可以传入属性等,进行筛选
# items = doc('a')
# 使用find方法查找子节点
print(doc.find('a'))
print('---------------------子节点---------------------')
print(doc('p').children())
print('-------------------直接父节点-----------------------')
print(doc('p').parent())
print('-------------------祖宗节点-----------------------')
print(doc('p').parents())
print('--------------------兄弟节点----------------------')
print(doc('a').siblings())
返回结果
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
---------------------子节点---------------------
<b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b><a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
-------------------直接父节点-----------------------
<body>
<p class="title"><b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
-------------------祖宗节点-----------------------
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html><body>
<p class="title"><b>The Dormouse's story<!--Hey, buddy. Want to buy a used parser?--></b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
--------------------兄弟节点----------------------
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
使用attr获取属性值,这两种写法一致。
print(doc('a').attr('href'))
print(doc('a').attr.href)
返回结果
http://example.com/elsie
http://example.com/elsie
2.2 遍历多个节点
遍历多个节点,获取文本信息,这里有两个方法text(),HTML(),发现返回结果一致。
a_items = doc('a').items()
for a_item in a_items :
print('---------------------text()---------------------')
print(a_item.text())
print('---------------------html()---------------------')
print(a_item.html())
返回结果
---------------------text()---------------------
Elsie
---------------------html()---------------------
Elsie
---------------------text()---------------------
Lacie
---------------------html()---------------------
Lacie
---------------------text()---------------------
Tillie
---------------------html()---------------------
Tillie
如果打印选取的多个节点的内部文本,那么,text()方法返回一个字符串,html()仅返回第一个的值。
# 如果直接打印多个
print(doc('a').text())
print('---------------------html()---------------------')
print(doc('a').html())
返回结果
Elsie Lacie Tillie
---------------------html()---------------------
Elsie
参考资料:
官方文档:https://pythonhosted.org/pyquery/
四、Parsel
Parsel库结合了css和xpath的优点,与后续即将学习的scrapy有些相像。
1.初始化
创建一个selector对象:
from parsel import Selector
seletor = Selector(text= html_doc)
之后可以使用css和xpath方法进行内容提取
# 使用css
items_css = seletor.css('.story')
print('------------------------------------------')
print(len(items_css) )
print('------------------------------------------')
print(type(items_css) )
print('------------------------------------------')
print(items_css)```
返回结果
```python
------------------------------------------
2
------------------------------------------
<class 'parsel.selector.SelectorList'>
------------------------------------------
[<Selector xpath="descendant-or-self::*[@class and contains(concat(' ', normalize-space(@class), ' '), ' story ')]" data='<p class="story">Once upon a time the...'>, <Selector xpath="descendant-or-self::*[@class and contains(concat(' ', normalize-space(@class), ' '), ' story ')]" data='<p class="story">...</p>'>]
# 使用xpath
items_xpath = seletor.xpath('//p[contains(@class,"story")]')
print('------------------------------------------')
print(len(items_xpath) )
print('------------------------------------------')
print(type(items_xpath) )
print('------------------------------------------')
print(items_xpath)
返回结果
------------------------------------------
2
------------------------------------------
<class 'parsel.selector.SelectorList'>
------------------------------------------
[<Selector xpath='//p[contains(@class,"story")]' data='<p class="story">Once upon a time the...'>, <Selector xpath='//p[contains(@class,"story")]' data='<p class="story">...</p>'>]
2.提取文本
这里可以看到,定位节点使用的是css,获取文本用的是xpath,
# 提取文本
items = seletor.css('.sister')
for item in items:
text = item.xpath('.//text()').get()
print(text)
返回结果
Elsie
Lacie
Tillie
使用get()可以获取第一个内容,但是使用getall()可以获取所有对象的文本
items_xpath = seletor.xpath('//a[contains(@class,"sister")]//text()')
print(items_xpath.get())
print('------------------------------------------')
print(items_xpath.getall())
返回结果
Elsie
------------------------------------------
['Elsie', 'Lacie', 'Tillie']
3.提取属性
attrs_css = seletor.css('.sister::attr(href)')
print(attrs_css.get())
print('------------------------------------------')
print(attrs_css.getall())
print('------------------------------------------')
返回结果
http://example.com/elsie
------------------------------------------
['http://example.com/elsie', 'http://example.com/lacie', 'http://example.com/tillie']
------------------------------------------
参考资料:
https://cuiqingcai.com/202232.html
官方文档:https://parsel.readthedocs.io/en/latest/index.html
总结
本节笔记记录了Beautiful Soup、XPath、pyquery、parsel网页解析库的基础使用,那么后续会继续学习数据的存储。
完整代码可在我的GitHub主页浏览,内容仅作学习使用,如有纰漏,请联系我,谢谢~















 2661
2661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









