






 文章讲述了在使用MLP处理indianpines数据集时,学长代码中的两类性能评估方法——宏观平均值(MacroAverage)和加权平均值(WeightedAverage),以及它们在处理不平衡数据集时的不同影响。
文章讲述了在使用MLP处理indianpines数据集时,学长代码中的两类性能评估方法——宏观平均值(MacroAverage)和加权平均值(WeightedAverage),以及它们在处理不平衡数据集时的不同影响。
在做机器学习的作业,使用MLP分类indian pines数据集,两层隐藏层,大小都是1024,优化器Adam、激活函数ReLU、交叉熵损失、数据集划分4:1。
小组学长写的代码,实验结果如下:
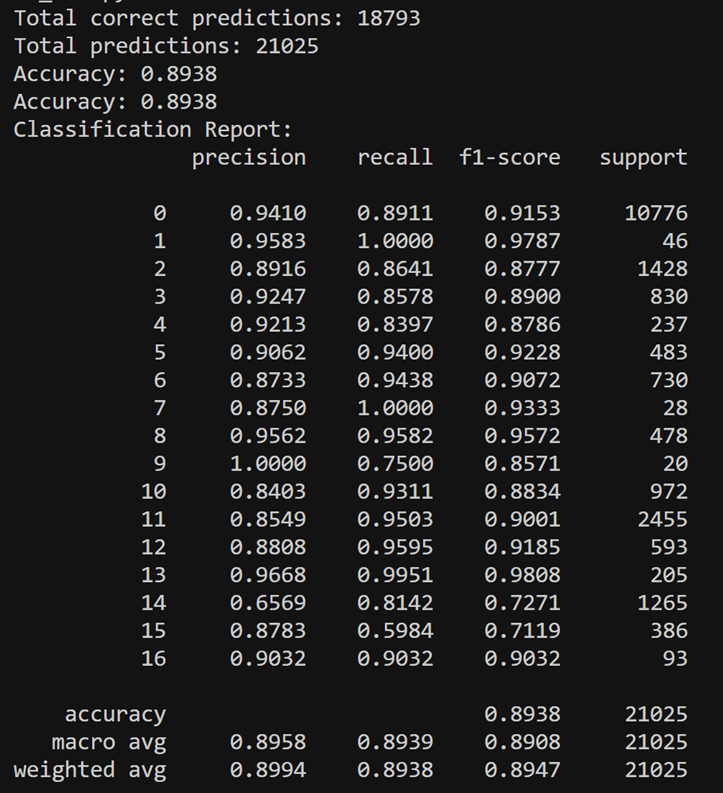
请教了最后两行指标的意思,记在这里:
- 宏观平均值Macro Average
计算每个类别指标的简单平均值,而不考虑每个类别的样本大小。对于精确度、召回率和F1分数,它首先分别计算每个类别的这些指标,然后计算所有类别指标的算术平均值。
宏观平均法赋予所有类别同等的重要性,这意味着每个类别都具有同等的权重。在不平衡的数据集中,宏平均可以为少数类赋予更多的权重,使其对模型在小类上的性能更敏感。 - 加权平均值Weighted Average
在计算加权平均值时,会考虑每个类别的样本量(即权重),并计算每个类别指标的加权平均值。具体来说,它会将每个类别的准确性、召回率和F1分数乘以其在数据集中的相对比例,然后将其相加。
加权平均为样本量较大的类别赋予更高的权重。在不平衡的数据集中,这意味着大多数类的性能将对总体平均度量产生更大的影响。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









