






 本文介绍了损失函数在深度神经网络训练中的重要性,通过最小二乘法和交叉熵的概念解释其原理。最小二乘法通过减小数据点与模型预测的差异来优化参数,而交叉熵则度量预测概率分布与真实标签的差距,常用于分类问题。
本文介绍了损失函数在深度神经网络训练中的重要性,通过最小二乘法和交叉熵的概念解释其原理。最小二乘法通过减小数据点与模型预测的差异来优化参数,而交叉熵则度量预测概率分布与真实标签的差距,常用于分类问题。
损失函数时如何设计出来的
损失函数是如何设计出来的
损失函数是我们训练深度神经网络模型所设计的。首先,我们要理解人脑就是一个巨大的神经网络模型,训练神经网络就是让我们训练的模型接近于我们的人脑,也就是模仿人脑。那么既然你是模仿人脑,那你的认知就必须和人脑一样。
打个比方,人看到一张猫的图片知道这是一只猫,那么训练的网络模型也必须和人脑的一样能够判断出来的这是只猫,所以训练神经网络就是要让神经网络模型的判断与人脑的判断尽可能地相似,也就是尽可能减少两者地差异,那么这个差异用一个函数来表示就是损失函数。一言以蔽之,损失函数就是表示训练的网络模型的预测结果与真实标签的差异的函数。要理解损失函数就要理解两个概念,一个是最小二乘法,另一个就是极大似然估计。
最小二乘法
最小二乘法(Least Squares Method)是一种常见的数学优化技术,用于在给定一组数据点的情况下,拟合一个数学模型来描述这些数据点的趋势。它的目标是通过最小化数据点与拟合模型之间的残差平方和,找到最优的模型参数。
在最小二乘法中,我们首先选择一个用于描述数据的数学模型,通常表示为一个函数,这个函数依赖于一些未知参数。然后,通过最小化实际数据点与模型预测值之间的差异,来估计这些未知参数的值,使得模型与数据点之间的误差尽可能地小。
最小二乘法总结成损失函数的公式十分简单就是:
loss
=
1
2
(
y
^
−
y
)
2
\operatorname{loss}_{}=\frac{1}{2}(\hat{y}-y)^2
loss=21(y^−y)2
这个公式很直观的表达了标签与实际预测值之间的损失,但是有些聪明的小伙伴可能要问了,既然是表达标签与实际的损失,为什么要加一个平方,直接求绝对值不就可以了吗?像这样
loss
=
∣
y
^
−
y
∣
\operatorname{loss}_{}=|\hat{y}-y|
loss=∣y^−y∣
首先说明下,这样肯定是不行的,因为我们在设计损失函数的时候,不仅要考虑到公式跟实际的意义结合,还要保证公式方便求导,上述的格式就不适合求导。最小二乘法公式中的2分之一也是可以在求导后消去。
交叉熵损失函数
交叉熵是信息论中的一个重要概念,主要用于度量两个概率分布间的差异性
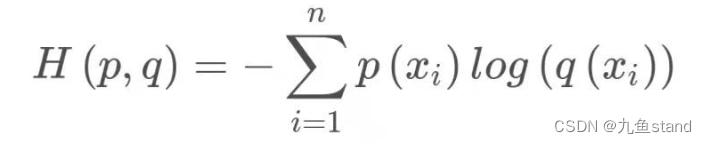
交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。
交叉熵在分类问题中常常与softmax是标配,softmax将输出的结果进行处理,使其多个分类的预测值和为1,再通过交叉熵来计算损失。















 1888
1888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









