







1.1分布式系统的驱动力和挑战
分布式系统:通过网络协调,完成一致任务的计算机。(分布式系统会让问题变得复杂,所以能单独计算机解决就不用分布式)
分布式的优点:
1.大量的并行运算能获得更高的计算机性能
2.提供更高的容错率,一台计算机的故障不会导致整个任务的瘫痪。
3.某些问题在空间上是分布的,例如不同位置人使用服务器进行通信,如此存在物理分离,需要一种协调的方法。
4.增强安全性。例如,不被信任的代码分计算机运行,再通过网络协议通信。
分布式的挑战:
1.系统中存在许多并发执行的部分,会带来许多并发程序和复杂交互的问题,以及时间依赖的问题(同步、异步)。使得分布式系统变难。
2.分布式系统有多个部分组成,例如:多台计算机可能存在部分工作、部分没有工作,或者网络不稳定等一系列难以预测的问题。
3.分布式的目的之一是得到更高的性能;例如将上千台计算机进行连接,但是千台计算机能达到多少是一个问题,因此也是需要谨慎设计。
1.2分布式系统的抽象和实现工具
分布式基础架构的类型主要是存储(最关注)、通信(网络)和计算。
构建分布式系统时出现的工具:
1. RPC (Remote Procedure Call)。模板是掩盖我们正在不可靠网络上通信的事实。
2.线程。可以利用多核心计算机,提供了一种结构化并发操作方式。
3.并发控制:锁。
1.3 可扩展性(Scalability)
重要话题:性能。
构建分布式系统的目标是提高性能。可扩展性指现在我用一台计算机解决了一些问题,当买了第二台,那么只需要一半的时间就可以解决这些问题。两台计算机构成的系统如果有两倍的性能,就是所言的可扩展性。
但是扩展性也是存在瓶颈的,可能在你拥有一定量的服务器之后,他们都在同一个数据库通信。那么数据库就可能形成瓶颈,增加再多的服务器都将无济于事。这时,就需要进行一些重构工作,如果只有一个数据库,可能还需要对数据库进行拆分,工作量巨大。
1.4 可用性(Availability)
共同的思想就是可用性(Availability; 容错特性是自我可恢复性(recoverability)。为了使系统因故障而停止响应,将其修复之后能正确运行,有一些工具可以进行辅助:
1.一个是非易失存储(non-volatile storage,类似于硬盘):对服务器进行备份,存放一些checkpoints和log,当系统恢复时能得到系 统最新的状态。
2.另一个重要工具是复制(replication),但是管理复制的多副本比较复杂。例如:副本总会意外的偏离同步状态,导致不再互为副本。
1.5 一致性(Consistency)
就如一个key-对应一个-value.一个分布式系统重由于复制或者缓存,数据会存在于多个副本,于是就有了多个不同版本的key-value对。假设服务器有两个副本,那么他们都有一个key-value表单,两个表单中key 1对应的值都是20。
某客户端发送一个put请求,将key 1对应的value改为21,但是因为一些原因只有服务器1接受到了请求那么就会导致,不同的get请求得到的值会不同。
为解决这个问题,提出了强一致性(获得的都是最近一次修改的值),但是却存在通信昂贵的问题。因为需要,同时对所有缓存都进行检索。所以弱一致性得到了人们的青睐,弱一致是指,不保证get请求可以得到最近一次完成的put请求写入的值。所以,人们常常会使用弱一致系统,你只需要更新最近的数据副本,并且只需要从最近的副本获取数据。在学术界和现实世界(工业界),有大量关于构建弱一致性保证的研究。所以,弱一致对于应用程序来说很有用,并且它可以用来获取高的性能。
1.6 MapReduce基本工作方式
MapReduce:抽象来看,MapReduce假设有一些输入,这些输入被分割成大量的不同的文件或者数据块。所以,我们假设现在有输入文件1,输入文件2和输入文件3,这些输入可能是从网上抓取的网页,更可能是包含了大量网页的文件。
Map函数以文件作为输入,文件又是整个输入数据的一部分。Map函数的输出是一个Key-value对的列表。例如一个简单的Mapreduce Job:单词计数器(统计每个单词出现的次数)。这个例子中map会输入K-V对,K为单词,V为数字。map函数将输出的K-V进行拆分,并进行输出。最终对所有输出的K-V进行技术,获得最终的输出。所以,假设输入文件1包含了单词a和单词b,Map函数的输出将会是key=a,value=1和key=b,value=1。第二个Map函数只从输入文件2看到了b,那么输出将会是key=b,value=1。第三个输入文件有一个a和一个c。

运行所有Map函数之后,会得到中间输出。然后运行Reduce函数。MapReduce框架会收集输出key为a的K-V对,然后将其交给Reduce函数。

然后会收集来自不同计算机上不同的Map函数所生成的b。再将其交给另一个Reduce函数,这个Reduce函数的入参是所有的key为b的key-value对。对c也是一样。所以,MapReduce框架会为所有Map函数输出的每一个key,调用一次Reduce函数。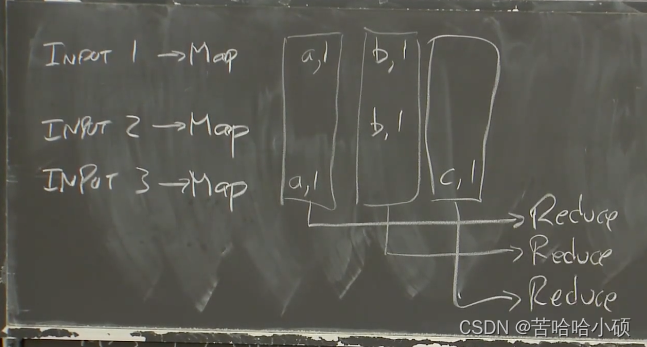
在我们这个简单的单词计数器的例子中,Reduce函数只需要统计传入参数的长度,甚至都不用查看传入参数的具体内容,因为每一个传入参数代表对单词加1,而我们只需要统计个数。最后,每个Reduce都输出与其关联的单词和这个单词的数量。所以第一个Reduce输出a=2,第二个Reduce输出b=2,第三个Reduce输出c=1。
注意:
-
Job。整个MapReduce计算称为Job。
-
Task。每一次MapReduce调用称为Task。
1.7 Map函数和Reduce函数
Map函数使用一个key和value作为参数,其中更关注的是value部分的内容。例如一个单词计数器,我们会将输入的文本拆分成单词,对每个单词都调用emit,emit会接收两个参数,一个是key一个是value。而这个Map函数不需要知道任何分布式相关的信息,不需要知道有多台计算机,不需要知道实际会通过网络来移动数据。这里非常直观。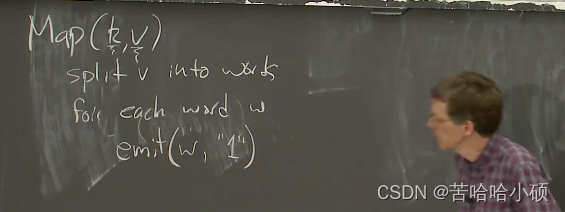
Reduce函数的入参是某个特定key的所有实例(Map输出中的key-value对中,出现了一次特定的key就可以算作一个实例)。Reduce函数也有一个属于自己的emit函数。这里的emit函数只会接受一个参数value,这个value会作为Reduce函数入参的key的最终输出。所以,对于单词计数器,我们会给emit传入数组的长度。这就是一个最简单的Reduce函数。并且Reduce也不需要知道任何有关容错或者其他有关分布式相关的信息。
1.8 学生提问
学生提问:可以将Reduce函数的输出再传递给Map函数吗?
答:可以进行这样的操作,且是一个极为常见的操作。例如,Google用来评价网页的重要性和影响力的PageRank算法,这些算法都是逐步向答案收敛。
学生提问:如果可以将Reduce的输出作为Map的输入,在生成Reduce函数的输出时需要有什么注意吗?
Robert教授:是的,你需要设置一些内容。比如你需要这么写Reduce函数,使其在某种程度上知道应该按照下一个MapReduce Job需要的格式生成数据。这里实际上带出了一些MapReduce框架的缺点。如果你的算法可以很简单的由Map函数、Map函数的中间输出以及Reduce函数来表达,那是极好的。MapReduce对于能够套用这种形式的算法是极好的。并且,Map函数必须是完全独立的,它们是一些只关心入参的函数。这里就有一些限制了。事实上,很多人想要的更长的运算流程,这涉及到不同的处理。使用MapReduce的话,你不得不将多个MapReduce Job拼装在一起。而在本课程后面会介绍的一些更高级的系统中,会让你指定完整的计算流程,然后这些系统会做优化。这些系统会发现所有你想完成的工作,然后有效的组织更复杂的计算。
学生提问:MapReduce框架更重要还是Map/Reduce函数更重要?
Robert教授:从程序员的角度来看,只需要关心Map函数和Reduce函数。从我们的角度来看,我们需要关心的是worker进程和worker服务器。这些是MapReduce框架的一部分,它们与其它很多组件一起调用了Map函数和Reduce函数。所以是的,从我们的角度来看,我们更关心框架是如何组成的。从程序员的角度来看,所有的分布式的内容都被剥离了
学生提问:当你调用emit时,数据会发生什么变化?emit函数在哪运行?
Robert教授:首先看,这些函数在哪运行。这里可以看MapReduce论文的图1。现实中,MapReduce运行在大量的服务器之上,我们称之为worker服务器或者worker。同时,也会有一个Master节点来组织整个计算过程。这里实际发生的是,Master服务器知道有多少输入文件,例如5000个输入文件,之后它将Map函数分发到不同的worker。所以,它会向worker服务器发送一条消息说,请对这个输入文件执行Map函数吧。之后,MapReduce框架中的worker进程会读取文件的内容,调用Map函数并将文件名和文件内容作为参数传给Map函数。worker进程还需要实现emit,这样,每次Map函数调用emit,worker进程就会将数据写入到本地磁盘的文件中。所以,Map函数中调用emit的效果是在worker的本地磁盘上创建文件,这些文件包含了当前worker的Map函数生成的所有的key和value。
所以,Map阶段结束时,我们看到的就是Map函数在worker上生成的一些文件。之后,MapReduce的worker会将这些数据移动到Reduce所需要的位置。对于一个典型的大型运算,Reduce的入参包含了所有Map函数对于特定key的输出。通常来说,每个Map函数都可能生成大量key。所以通常来说,在运行Reduce函数之前。运行在MapReduce的worker服务器上的进程需要与集群中每一个其他服务器交互来询问说,看,我需要对key=a运行Reduce,请看一下你本地磁盘中存储的Map函数的中间输出,找出所有key=a,并通过网络将它们发给我。所以,Reduce worker需要从每一个worker获取特定key的实例。这是通过由Master通知到Reduce worker的一条指令来触发。一旦worker收集完所有的数据,它会调用Reduce函数,Reduce函数运算完了会调用自己的emit,这个emit与Map函数中的emit不一样,它会将输出写入到一个Google使用的共享文件服务中。
有关输入和输出文件的存放位置,这是我之前没有提到的,它们都存放在文件中,但是因为我们想要灵活的在任意的worker上读取任意的数据,这意味着我们需要某种网络文件系统(network file system)来存放输入数据。所以实际上,MapReduce论文谈到了GFS(Google File System)。GFS是一个共享文件服务,并且它也运行在MapReduce的worker集群的物理服务器上。GFS会自动拆分你存储的任何大文件,并且以64MB的块存储在多个服务器之上。所以,如果你有了10TB的网页数据,你只需要将它们写入到GFS,甚至你写入的时候是作为一个大文件写入的,GFS会自动将这个大文件拆分成64MB的块,并将这些块平均的分布在所有的GFS服务器之上,而这是极好的,这正是我们所需要的。如果我们接下来想要对刚刚那10TB的网页数据运行MapReduce Job,数据已经均匀的分割存储在所有的服务器上了。如果我们有1000台服务器,我们会启动1000个Map worker,每个Map worker会读取1/1000输入数据。这些Map worker可以并行的从1000个GFS文件服务器读取数据,并获取巨大的读取吞吐量,也就是1000台服务器能提供的吞吐量。
学生提问:这里的箭头代表什么意思?
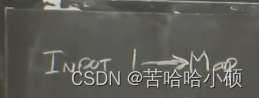
Robert教授:随着Google这些年对MapReduce系统的改进,答案也略有不同。通常情况下,如果我们在一个例如GFS的文件系统中存储大的文件,你的数据分散在大量服务器之上,你需要通过网络与这些服务器通信以获取你的数据。在这种情况下,这个箭头表示MapReduce的worker需要通过网络与存储了解输入文件的GFS服务器通信,并通过网络将数据读取到MapReduce的worker节点,进而将数据传递给Map函数。这是最常见的情况。并且这是MapReduce论文中介绍的工作方式。但是如果你这么做了,这里就有很多网络通信。 如果数据总共是10TB,那么相应的就需要在数据中心网络上移动10TB的数据。而数据中心网络通常是GB级别的带宽,所以移动10TB的数据需要大量的时间。在论文发表的2004年,MapReduce系统最大的限制瓶颈是网络吞吐。如果你读到了论文的评估部分,你会发现,当时运行在一个有数千台机器的网络上,每台计算机都接入到一个机架,机架上有以太网交换机,机架之间通过root交换机连接(最上面那个交换机)。
如果随机的选择MapReduce的worker服务器和GFS服务器,那么至少有一半的机会,它们之间的通信需要经过root交换机,而这个root交换机的吞吐量总是固定的。如果做一个除法,root交换机的总吞吐除以2000,那么每台机器只能分到50Mb/S的网络容量。这个网络容量相比磁盘或者CPU的速度来说,要小得多。所以,50Mb/S是一个巨大的限制。
在MapReduce论文中,讨论了大量的避免使用网络的技巧。其中一个是将GFS和MapReduce混合运行在一组服务器上。所以如果有1000台服务器,那么GFS和MapReduce都运行在那1000台服务器之上。当MapReduce的Master节点拆分Map任务并分包到不同的worker服务器上时,Master节点会找出输入文件具体存在哪台GFS服务器上,并把对应于那个输入文件的Map Task调度到同一台服务器上。所以,默认情况下,这里的箭头是指读取本地文件,而不会涉及网络。虽然由于故障,负载或者其他原因,不能总是让Map函数都读取本地文件,但是几乎所有的Map函数都会运行在存储了数据的相同机器上,并因此节省了大量的时间,否则通过网络来读取输入数据将会耗费大量的时间。
我之前提过,Map函数会将输出存储到机器的本地磁盘,所以存储Map函数的输出不需要网络通信,至少不需要实时的网络通信。但是,我们可以确定的是,为了收集所有特定key的输出,并将它们传递给某个机器的Reduce函数,还是需要网络通信。假设现在我们想要读取所有的相关数据,并通过网络将这些数据传递给单台机器,数据最开始在运行Map Task的机器上按照行存储(例如第一行代表第一个Map函数输出a=1,b=1),
而我们最终需要这些数据在运行Reduce函数的机器上按照列存储(例如,Reduce函数需要的是第一个Map函数的a=1和第三个Map函数的a=1)。
论文里称这种数据转换之为洗牌(shuffle)。所以,这里确实需要将每一份数据都通过网络从创建它的Map节点传输到需要它的Reduce节点。所以,这也是MapReduce中代价较大的一部分。
学生提问:是否可以通过Streaming的方式加速Reduce的读取?
Robert教授:你是对的。你可以设想一个不同的定义,其中Reduce通过streaming方式读取数据。我没有仔细想过这个方法,我也不知道这是否可行。作为一个程序接口,MapReduce的第一目标就是让人们能够简单的编程,人们不需要知道MapReduce里面发生了什么。对于一个streaming方式的Reduce函数,或许就没有之前的定义那么简单了。
不过或许可以这么做。实际上,很多现代的系统中,会按照streaming的方式处理数据,而不是像MapReduce那样通过批量的方式处理Reduce函数。在MapReduce中,需要一直要等到所有的数据都获取到了才会进行Reduce处理,所以这是一种批量处理。现代系统通常会使用streaming并且效率会高一些。
Streaming是一种分布式、实时计算框架,具有以下特点:实时响应、低延迟、数据不存储、先计算、连续查询、事件驱动。Streaming应用于实时分析、实时统计、实时推荐等场景。在FusionInsight中,Streaming作为一个实时的分布式实时计算框架,有广泛的应用。12
Streaming的基本概念包括Topology(实时应用程序)、Nimbus(资源分配和任务调度)、Supervisor(接受Nimbus分配的任务,启动和停止属于自己管理的worker进程)、Worker(Topology运行时的物理进程,每个Worker是一个JVM进程)、Spout(产生源数据流的组件)、Bolt(接受数据然后执行处理的组件)。
Streaming的处理原理是将要处理的元素看做一种流,流在管道中传输,并且可以在管道的节点上处理,包括过滤筛选、去重、排序、聚合等。元素流在管道中经过中间操作的处理,最后由最终操作得到前面处理的结果。
Streaming框架允许任何程序语言实现的程序在Hadoop MapReduce中使用,方便已有程序向Hadoop平台移植。用Java实现一个包装用户程序的MapReduce程序,该程序负责调用MapReduce Java接口获取key/value对输入,创建一个新的进程启动包装的用户程序,将数据通过管道传递给包装的用户程序处理,然后调用MapReduce Java接口将用户程序的输出切分成key/value对输出。
之前有人提过,想将Reduce的输出传给另一个MapReduce job,而这也是人们常做的事情。在一些场景中,Reduce的输出可能会非常巨大,或许你会认为用之前的方法,但是因为GFS会将数据做拆分,并且为了提高性能并保留容错性,数据会有2-3份副本。这意味着,不论你写什么,你总是需要通过网络将一份数据拷贝写到2-3台服务器上。所以,这里会有大量的网络通信。我认为Google几年前就不再使用MapReduce了,不过在那之前,现代的MapReduce已经不再尝试在GFS数据存储的服务器上运行Map函数了,它乐意从任何地方加载数据,因为网络已经足够快了。















 2868
2868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









