






系列文章目录
一、概述
1. ES 的基本概念
-
索引
- 在使用传统的关系型数据库时,如果对数据有存取和更新操作,需要建立一个数据库,相应地,在ES中则需要建立索引。
-
文档
- 在使用传统的关系型数据库时,需要把数据分装成数据库中的一条记录,而在 ES 中对应的则是文档。
-
字段
- 一个文档可以包含一个或多个字段、每个字段都有一个类型与其对应。除了常用的数据类型(如字符串型、文本型和数值型)外,ES 还提供了多种数据类型,如数组类型、经纬度类型和IP地址类型等。
-
映射
- 建立索引时需要定义文档的数据结构,这种结构叫做映射。在映射中,文档的字段类型一旦设定后就不能更改。因为字段类型在定义后,ES 已经针对定义的类型建立了特定的索引结构,这种结构不能更改。
-
集群和节点
- 在分布式系统中,为了完成海量数据的存储、计算并提升系统的高可用性,需要多台计算机集成在一起协作,这种形式被称为集群。
-
分片
- 在分布式系统中,为了能存储和计算海量的数据,会先对数据进行切分,然后再将它们存储到多台计算机中。在ES中,一个分片对应的就是一个Lucene索引,每个分片可以设置多个福分片,这样当主分片所在的计算机因为发生故障而离线时,副分片会充当主分片继续服务。索引的分片个数只能设置一次,之后不能更改,在默认情况下,ES 的每个索引设置为5个分片。
-
副分片
- 为了提升系统索引数据的高可用性并减轻集群搜索的负载,可以启用分片的副本,该副本叫做副分片,而原有的分片叫作主分片。在默认情况下,ES 不会为索引的分片开启副分片,用户需要手动设置。
-
DSL
- ES使用DSL(Domain Specific Language,领域特定语言),来定义查询。ES 的DSL 采用JSON进行表达,相应地,ES 也将响应客户端请求的返回数据封装成了 JSON 形式。
2. ES 和关系型数据库的对比
- ES 属于非关系型数据库。
- 索引方式:关系型数据库的索引大多是 B-Tree 结构,而ES使用的是倒排索引。
- 事务支持:事务是关系型数据库的核心组成部分,而ES是不支持事务的。ES 更新文档时,先读取文档在进行修改,然后在为文档重新建立索引。ES使用乐观锁,每次更新增加当前文档的版本号。
- 数据的实时性:关系型数据库存储和查询数据基本上是实时的,即单条数据写入之后可以立即查询。为了提高数据写入的性能,ES 在内存和磁盘之间增加了一层系统缓存。ES 响应写入数据的请求后,会先将数据存储在内存中,此时该数据还不能被搜索到。内存中的数据每隔一段时间(默认1s)被刷新到系统缓存内,此时数据才能被搜索到。因此,ES 的数据写入不是实时的,而是准实时的。
二、环境准备
1. linux 下单机安装
-
解压压缩包
tar -zxvf [压缩包名称] -C [压缩后的包生成存放路径] -
由于 es 安全机制,无法使用root启动,需要添加用户
useradd [新添加的用户名] # 切换用户 su [新添加的用户名] -
新添加的用户权限不足,无法启动用户,切无法拥有修改文件的权限,需要添加权限。
chmod -R 755 /opt/elasticsearch-7.6.2 -
启动客户端
bin/elasticsearch -
启动成功后,如果出现本地却无法访问问题。修改 config/elasticsearch.yml 配置文件。

三、入门操作
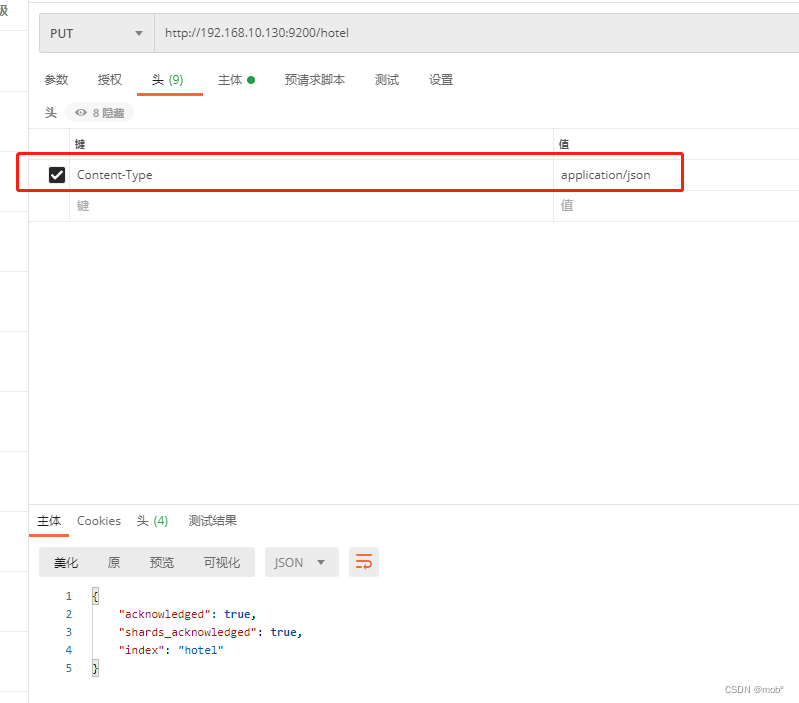
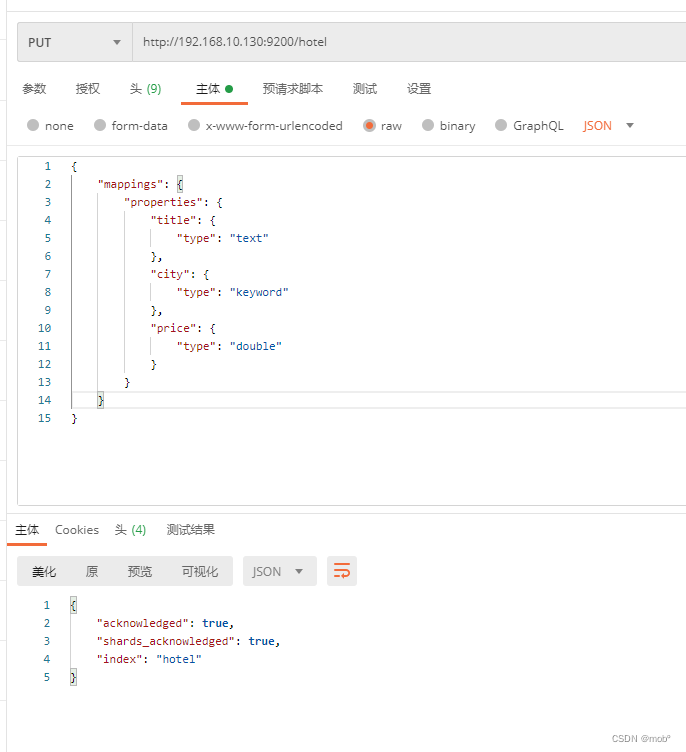
1. 创建索引
-
hotle:索引名称 -
properties:指定字段名称及其数据类型
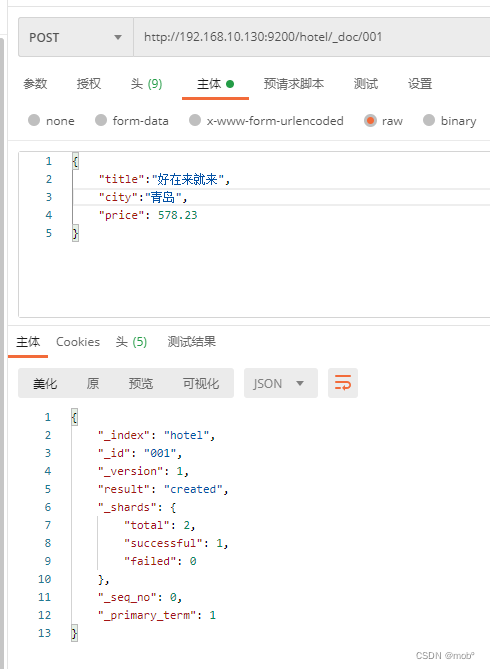
2. 写入文档
- 即向索引中填充数据
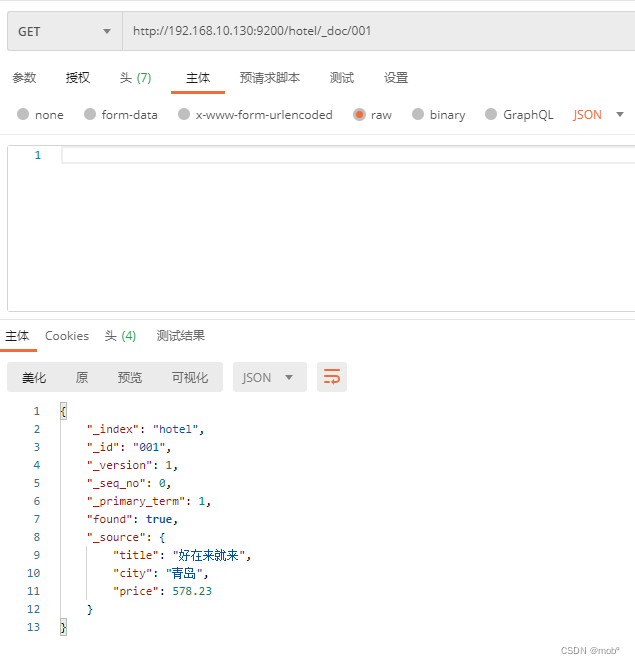
3. 根据id搜索文档
4. 根据一般字段搜索文档
- 在 ES 中进行搜索时需要用到query字句。
- _shards:命中的分片信息。
- total:命中的文档总数。
- max_score:命中文档中的最高分
- hits:命中文档集合的信息。
- _index:文档所在索引。
- _id:文档 ID。
- _score:文档分值。
- _source:文档内容。
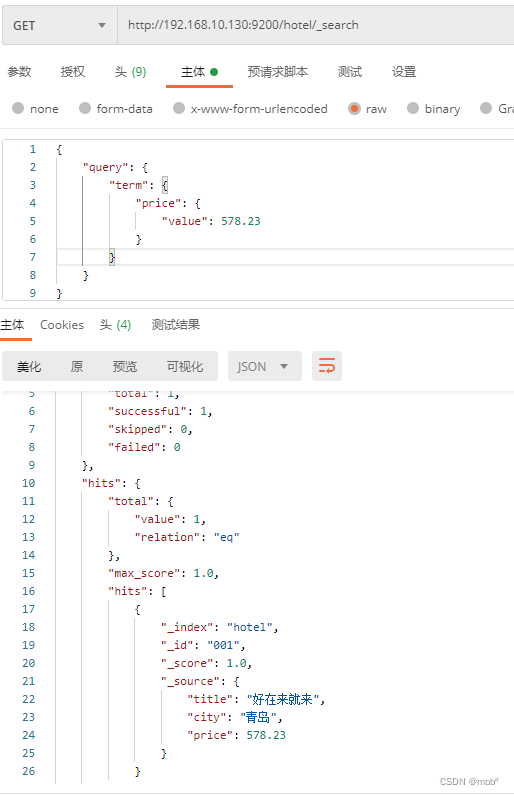
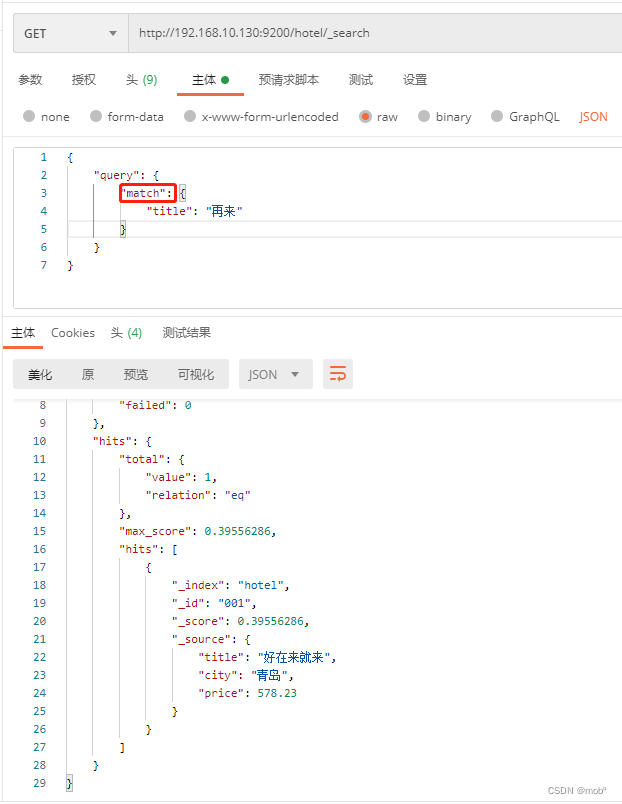
5. 根据文本字段搜索文档
- 前面的搜索,关系型数据库也能胜任,但是对文本进行模糊匹配并给出分数这一功能是搜索引擎所独有的。
- 使用
match搜索对某个字段进行模糊匹配。
四、ES 客户端实战
1. Spring Data Elasticsearch
-
添加依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> -
配置连接地址。ruls的值可以为多个协调点的服务器地址,中间用逗号隔开。
spring: elasticsearch: rest: uris: http://192.168.10.130:9200 username: root password: ****** -
分装实体类
- @Id:一个Spring Data Elasticsearch 的实体类定义必须定义一个被 @Id 修饰的字段,他是和索引中的_id相对应。对应文档_id 值。
- @Document(indexName = “hotel”) 对应索引的值
package com.study.elasticsearch.model.entity; import lombok.Data; import org.springframework.data.annotation.Id; import org.springframework.data.elasticsearch.annotations.Document; @Data @Document(indexName = "hotel") public class Hotel { @Id private int id; private String title; private String city; private String price; } -
定义接口,需继承 CrudRespository 接口。 Spring Data Elasticsearch 会自动根据方法名识别出方法的具体逻辑。
package com.study.elasticsearch.service; import com.study.elasticsearch.model.entity.Hotel; import org.springframework.data.repository.CrudRepository; import java.util.List; /** * * */ public interface EsRepositoryService extends CrudRepository<Hotel,String> { List<Hotel> findByTitleLike(String title); } -
定义服务类
package com.study.elasticsearch.service; import com.study.elasticsearch.model.entity.Hotel; import org.springframework.stereotype.Service; import javax.annotation.Resource; import java.util.List; @Service public class EsService { @Resource EsRepositoryService repositoryService; public List<Hotel> getHotelFromTitle(String keyword){ return repositoryService.findByTitleLike(keyword); } } -
Controller 类
package com.study.elasticsearch.controller; import com.study.elasticsearch.model.entity.Hotel; import com.study.elasticsearch.service.EsService; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import javax.annotation.Resource; import java.util.List; @RestController public class TestController { @Resource EsService esService; @RequestMapping(value = "/test") public String getRec(){ List<Hotel> hotelList = esService.getHotelFromTitle("再来"); if (hotelList.size() > 0){ return hotelList.toString(); }else { return "no data"; } } } -
测试
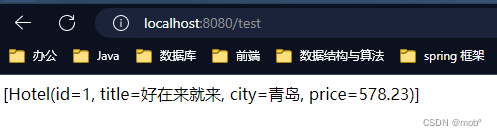
2. RestHighLivelClient
(1)不带验证的客户端
-
pom依赖:
<!--ES 客户端依赖--> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.6.2</version> </dependency> <!--ES 客户端依赖--> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>7.6.2</version> </dependency> -
yml文件(不带验证客户端 username 和 password 可不用写,用不上,待验证客户端需要填写)
elasticsearch: rest: # hosts 可设置多个地址,用逗号隔开 hosts: 192.168.10.130:9200 username: root password: Jj571376264 -
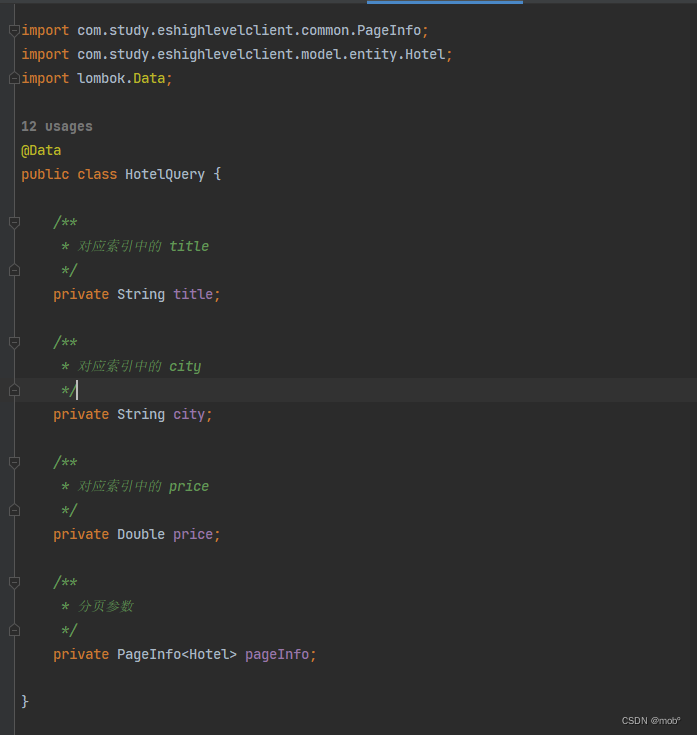
实体类
package com.study.elasticsearch.model.entity; import lombok.Data; @Data public class Hotel { /** * 文档 id */ private String id; /** * 对应索引名称 */ private String index; /** * 对应文档的房 */ private float score; /** * 对应索引中的 title */ private String title; /** * 对应索引中的 city */ private String city; /** * 对应索引中的 price */ private Double price; } -
生产 RestHighLevelClient 实例
package com.study.elasticsearch; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.stereotype.Component; import java.util.Arrays; import java.util.Objects; @Component public class component { @Value("${elasticsearch.rest.hosts}") private String hosts; @Bean public RestHighLevelClient initSimpleClient(){ //根据配置文件配置 HttpHost 数组 HttpHost[] httpHosts = Arrays.stream(hosts.split(",")).map( host -> { //分隔 ES 服务器的 IP 和端口 String[] hostParts = host.split(":"); String hostname = hostParts[0]; int port = Integer.parseInt(hostParts[1]); return new HttpHost(hostname, port, HttpHost.DEFAULT_SCHEME_NAME); }).toArray(HttpHost[]::new); //构建客户端 return new RestHighLevelClient(RestClient.builder(httpHosts)); } } -
创建 Service 。详细API 可查阅官方文档
package com.study.elasticsearch.service; import cn.hutool.core.util.StrUtil; import com.study.elasticsearch.model.entity.Hotel; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.index.query.QueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.rest.RestStatus; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.springframework.stereotype.Service; import org.springframework.util.StringUtils; import javax.annotation.Resource; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.Map; @Service public class EsService { @Resource RestHighLevelClient client; public List<Hotel> getHotelFromTitle(String keyword){ SearchRequest searchRequest = new SearchRequest("hotel"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //构建 query searchSourceBuilder.query(QueryBuilders.matchQuery("title",keyword)); searchRequest.source(searchSourceBuilder); List<Hotel> result = new ArrayList<>(); try { SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); RestStatus status = searchResponse.status(); if (status != RestStatus.OK){ return null; } SearchHits searchHits = searchResponse.getHits(); for (SearchHit searchHit : searchHits) { Hotel hotel = new Hotel(); hotel.setId(searchHit.getId()); hotel.setIndex(searchHit.getIndex()); hotel.setScore(searchHit.getScore()); Map<String, Object> dataMap = searchHit.getSourceAsMap(); hotel.setTitle(StrUtil.toString(dataMap.get("title"))); hotel.setCity(StrUtil.toString(dataMap.get("city"))); hotel.setPrice(Double.valueOf(StrUtil.toString(dataMap.get("price")))); result.add(hotel); } return result; } catch (IOException e) { throw new RuntimeException(e); } } } -
Controller 类
package com.study.elasticsearch.controller; import com.study.elasticsearch.model.entity.Hotel; import com.study.elasticsearch.service.EsService; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import javax.annotation.Resource; import java.util.List; @RestController public class TestController { @Resource EsService esService; @RequestMapping(value = "/test") public String getRec(){ List<Hotel> hotelList = esService.getHotelFromTitle("再来"); if (hotelList.size() > 0){ return hotelList.toString(); }else { return "no data"; } } } -
测试结果

(2)带验证的客户端
-
重写客户端
package com.study.elasticsearch; import org.apache.http.HttpHost; import org.apache.http.auth.AuthScope; import org.apache.http.auth.UsernamePasswordCredentials; import org.apache.http.impl.client.BasicCredentialsProvider; import org.apache.http.impl.nio.client.HttpAsyncClientBuilder; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestClientBuilder; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.stereotype.Component; import java.util.Arrays; @Component public class component { @Value("${elasticsearch.rest.hosts}") private String hosts; @Value("${elasticsearch.rest.username}") private String username; @Value("${elasticsearch.rest.password}") private String password; @Bean public RestHighLevelClient initSimpleClient(){ //根据配置文件配置 HttpHost 数组 HttpHost[] httpHosts = Arrays.stream(hosts.split(",")).map( host -> { //分隔 ES 服务器的 IP 和端口 String[] hostParts = host.split(":"); String hostname = hostParts[0]; int port = Integer.parseInt(hostParts[1]); return new HttpHost(hostname, port, HttpHost.DEFAULT_SCHEME_NAME); }).toArray(HttpHost[]::new); //生产凭证 BasicCredentialsProvider credentialsProvider = new BasicCredentialsProvider(); credentialsProvider.setCredentials( AuthScope.ANY, //明文凭证 new UsernamePasswordCredentials(username,password)); //返回带验证的客户端 return new RestHighLevelClient(RestClient.builder(httpHosts).setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() { @Override public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpAsyncClientBuilder) { httpAsyncClientBuilder.disableAuthCaching(); return httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider); } })); } } -
测试

3. JavaClient 客户端
- 在Elasticsearch7.15版本之后,Elasticsearch官方将它的高级客户端RestHighLevelClient标记为弃用状态。同时推出了全新的Java API客户端Elasticsearch Java API Client,该客户端也将在Elasticsearch8.0及以后版本中成为官方推荐使用的客户端。在Elasticsearch Java API Client 依賴中其实
-
pom
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.2.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.study</groupId> <artifactId>elasticsearch</artifactId> <version>0.0.1-SNAPSHOT</version> <name>elasticsearch</name> <description>elasticsearch</description> <properties> <java.version>1.8</java.version> <elasticsearch.version>8.1.0</elasticsearch.version> <jackson.version>2.11.1</jackson.version> <jakartajson.version>2.0.1</jakartajson.version> </properties> <dependencies> <dependency> <groupId>co.elastic.clients</groupId> <artifactId>elasticsearch-java</artifactId> <version>8.1.0</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.11.1</version> </dependency> <dependency> <groupId>jakarta.json</groupId> <artifactId>jakarta.json-api</artifactId> <version>2.0.1</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.8.10</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build> </project>-
这里依赖需要注意版本兼容问题。因为我们引入的是
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.2.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> -
这里面已经有了我们需要的es 和jakarta 对应的版本,我们需要在properties 里指定版本号。
<properties> <java.version>1.8</java.version> <elasticsearch.version>8.1.0</elasticsearch.version> <jackson.version>2.11.1</jackson.version> <jakartajson.version>2.0.1</jakartajson.version> </properties> -
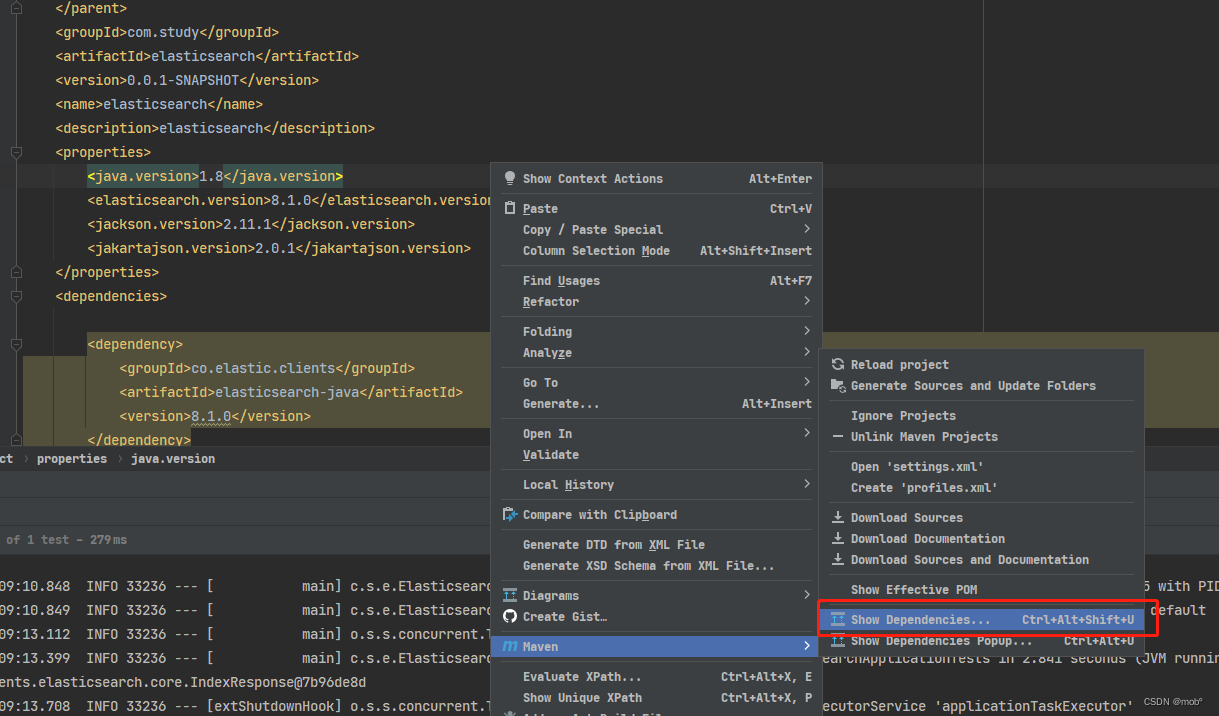
如果出现版本冲突可以通过查看 maven dependencies 来查看。
-
红线则是冲突的,可以双击查看。可以参考这里
-
-
yml 文件
## ES配置:@ConfigurationProperties(prefix = "elasticsearch") //配置的前缀 elasticsearch: # 多个IP逗号隔开 hosts: 192.168.10.132:9200 -
config配置客户端
package com.study.elasticsearch.config; import co.elastic.clients.elasticsearch.ElasticsearchAsyncClient; import co.elastic.clients.elasticsearch.ElasticsearchClient; import co.elastic.clients.json.jackson.JacksonJsonpMapper; import co.elastic.clients.transport.rest_client.RestClientTransport; import lombok.Setter; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.util.StringUtils; // 配置的前缀 @ConfigurationProperties(prefix = "elasticsearch") @Configuration public class EsConfig { /** * 多个IP逗号隔开 */ @Setter private String hosts; /** * 同步方式 * * @return */ @Bean public ElasticsearchClient elasticsearchClient() { HttpHost[] httpHosts = toHttpHost(); // Create the RestClient RestClient restClient = RestClient.builder(httpHosts).build(); // Create the transport with a Jackson mapper RestClientTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper()); // create the API client return new ElasticsearchClient(transport); } /** * 异步方式 * * @return */ @Bean public ElasticsearchAsyncClient elasticsearchAsyncClient() { HttpHost[] httpHosts = toHttpHost(); RestClient restClient = RestClient.builder(httpHosts).build(); RestClientTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper()); return new ElasticsearchAsyncClient(transport); } /** * 解析配置的字符串hosts,转为HttpHost对象数组 * * @return */ private HttpHost[] toHttpHost() { if (!StringUtils.hasLength(hosts)) { throw new RuntimeException("invalid elasticsearch configuration. elasticsearch.hosts不能为空!"); } // 多个IP逗号隔开 String[] hostArray = hosts.split(","); HttpHost[] httpHosts = new HttpHost[hostArray.length]; HttpHost httpHost; for (int i = 0; i < hostArray.length; i++) { String[] strings = hostArray[i].split(":"); httpHost = new HttpHost(strings[0], Integer.parseInt(strings[1]), "http"); httpHosts[i] = httpHost; } return httpHosts; } } -
service
package com.study.elasticsearch.service; import com.study.elasticsearch.model.VO.EsBaseResult; /** * * */ public interface EsRepositoryService { /** * 文档插入 单条 * @param indexName 索引名称 */ EsBaseResult saveSingleIndexDoc(String indexName) ; } -
实现类
package com.study.elasticsearch.service.impl; import co.elastic.clients.elasticsearch.ElasticsearchClient; import co.elastic.clients.elasticsearch.core.SearchResponse; import co.elastic.clients.elasticsearch.core.search.Hit; import com.study.elasticsearch.model.VO.EsBaseResult; import com.study.elasticsearch.model.entity.Hotel; import com.study.elasticsearch.service.EsRepositoryService; import org.springframework.stereotype.Service; import javax.annotation.Resource; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.Objects; @Service public class EsRepositoryServiceImpl implements EsRepositoryService { @Resource private ElasticsearchClient elasticsearchClient; @Override public EsBaseResult saveSingleIndexDoc(String indexName) { List<Hotel> hotels = new ArrayList<>(); try { SearchResponse<Hotel> hotel = elasticsearchClient.search(e -> e.index(indexName), Hotel.class); for (Hit<Hotel> hit : hotel.hits().hits()) { Hotel source = hit.source(); Objects.requireNonNull(source).setIndex(hit.index()); Objects.requireNonNull(source).setId(hit.id()); Objects.requireNonNull(source).setScore(hit.score()); hotels.add(source); } return EsBaseResult.builder().data(hotels.toString()).build(); } catch (IOException e) { throw new RuntimeException(e); } } } -
controller
package com.study.elasticsearch.controller; import cn.hutool.json.JSONObject; import com.study.elasticsearch.model.VO.EsBaseResult; import com.study.elasticsearch.service.EsRepositoryService; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import javax.annotation.Resource; @RestController public class TestController { @Resource EsRepositoryService esService; @RequestMapping(value = "/save") public EsBaseResult getRec(){ return esService.saveSingleIndexDoc("hotel"); } } -
测试

五、基础操作
1. 索引操作
1. 创建索引
- 在创建索引时,可以安装实际需求堆缩影进行主分片和副分片设置。假设 主分片:15,副分片:2。
PUT /${index_name}
{
"settings": {
"number_of_shards": 15,
"number_of_replicas": 2
},
"mappings": {
"properties": {
...
}
}
}
2. 删除索引
- DELETE / [index_name]
- index_name:索引名称
- 系统返回操作成功信息
{ "acknowledged":true }
3. 关闭索引
POST / [index_name] / _close- 在有些场景下,某个索引暂时不使用,但是后期可能又会使用,这里的使用值数据写入和数据搜索。这个索引在某一段时间内属于冷数据或者归档数据。此时就可以关闭索引,关闭后不能写入和搜索数据。
4. 打开索引
POST /hotel/_open
5. 索引别名
-
顾名思义,是
给一个或多个索引另外起一个名字,使索引别名和索引之间建立某种逻辑关系。 -
使用场景(1):
-
我们建立1、2、3 ,三个月的酒店入住数据,分别对应各三个索引。现在我们需要查询里面的数据,我们就需要分别从这三个索引(分别对应1、2、3,三个月数据)去查询数据,但是我们可以通过创建索引别名,给这三个索引创建同一个索引别名,从这个索引别名去查询数据,即可实现效果(ES 会将请求转发给三个索引);
POST /_aliases { "actions":[ { "add":{ "index":"january_log", "alias":"last_three_month" } }, { "add":{ "index":"february_log", "alias":"last_three_month" } }, { "add":{ "index":"march_log", "alias":"last_three_month" } } ] } -
但是向该索引别名插入数据时,会出现问题。不能够确认转发请求的对象,如果索引别名只对应一个索引,则没问题,否则报错。我们设置参数 is_write_index :true 来确认请求转发对象。
POST /_aliases { "actions":[ { "add":{ "index":"january_log", "alias":"last_three_month", "is_write_index":true } } ] }
-
-
使用场景(2): 创建索引后,有些参数是不可以修改的,比如主分片的个数。我们可以新建一个索引,设置成我们想要的分片数,然后和旧的索引起一样的索引别名。再删除旧的索引别名,就变相的完成了索引的分片参数的修改。
POST /_aliases { "actions":[ { "remove":{ "index":"hotel_1", //删除索引 hotel_1 的别名 hotel "alias":"hotel" } }, { "add":{ "index":"hotel_2", //增加索引 hotel_2 的别名hotel "alias":"hotel" } } ] }
2. 映射操作
- 在使用数据之前,需要构建数据的组织结构。在数据库里叫做表结构,在ES理叫做映射。
- 作为无模式搜索引擎,ES 在写入数据时猜测数据类型,从而自动创建映射。但有时ES创建的映射中的数据类型和目标类型可能不一致。当需要严格控制数据类型时,还是需要手动进行创建的。
1. 查看映射
-
GET /[index_name]/_mapping -
测试:GET/hotel/_mapping,返回结果:
{ "hotel":{ "mappings":{ "properties":{ "city":{ //定义字段类型为keyword "type":"keyword" }, "price":{ //定义字段类型为double "type":"double" }, "title":{ //定义字段类型为text "type":"text" } } } } }
2. 扩展映射
-
POST /hotel/_mapping -
映射中的字段类型时不可以修改的,但是字段可以扩展。
POST /hotel/_mapping { "properties": { "tag": { "type": "keyword" } } }
1. 基本数据类型
-
keyword:
keyword 类型时不进行切分的字符串类型。- 这里的"不进行切分"指的是:
在索引中,对keyword类型的数据不进行切分,直接构建倒排索引。在搜索时,对该类型的查询字符串不进行切分后的部分匹配。 - keyword 类型数据一般用于对文档的
过滤、排序和聚合。 - 在现实场景中,keyword 经常用语描述姓名、产品类型、用户ID、URL和状态码等。
- keyword类型数据一般用于比价字符串是否相等,不对数据进行匹配。因此一般查询这种类型的数据时使用term查询。比如有一条数据 user_name:张三,使用term搜索user_name:张三,可以命中数据,但是若使用match搜若user_name:张,则不会命中数据
- 这里的"不进行切分"指的是:
-
text:
是可以进行切分的字符串类型。- 这里的 “可切分” 指的是:在索引中,
可按照相应的切词算法对文本内容进行切分,然后构建倒排索引:在搜索时,对该类型的查询字符串按照用户的切词算法进行切分,然后对切分后的部分匹配打分。 - 列入,一个就点搜索项目,我们希望可以根据就点名称即 title 字段进行模糊匹配,因此可以设定 title 字段text 字段。
- 举个例子:
PUT /hotel/_doc/001 { "title":"文雅酒店" } //使用 term 进行搜索 GET /hotel/_search { "query": { "term": { "title": { "value": "文雅酒店" } } } } /** * 发现无法搜索到数据,因为 term 搜索英语搜索值和文档对应的字段是否完全相等,而对于 text 类型的数据,在建立索引时ES已经进行了 * 切分并建立倒排索引,因此使用 term 进行搜索没有数据。一般情况下,搜索 text 类型数据时应使用 match 搜索。 */ //使用 match 搜索,发现可以搜索到新添加的数据 GET /hotel/_search { "query": { "match": { "title": "文雅" } } }
- 这里的 “可切分” 指的是:在索引中,
-
数值类型
- ES 支持的数值类型有
:long、integer、short、byte、double、float、half_float、scaled_fload 和 unsigned_long等。 - 为节约存储空间并提升搜索和索引的效率,在实际应用中,在满足需求的情况下应尽可能选择范围小的数据类型,如年龄取值最大不超过200,因此可以选择 byte 类型即可。
- 数值类型的数据
也可用于对文档进行过滤、排序和聚合。 - 使用 term 进行范围搜索价格 350 ~ 400(包含350和400)
GET /hotel/_search { "query": { "range": { "parice": { "get": 350, "lte": 400 } } } }
- ES 支持的数值类型有
-
布尔类型:使用 boolean 定义。
- 用于业务中的二值表示,如商品是否售罄,房屋是否已租,酒店房间是否满房等。
- 写入或者查询该类型的数据时,其值可以
使用 true 或 false,或者使用字符串形式 "true" 和 "false"。 - 举个例子。
PUT /hotel { "mappings": { "properties": { "full_room": { "type": "boolean" } } } } // 使用term查询boolean类型的数据 GET /hotel/_search { "query": { "term": { "full_room": { "type": "true" } } } }
-
日期类型:
日期类型的名称为 data。-
ES 中存储的日期是标准的 UTC 格式。
PUT /hotel { "mappings": { "properties": { "create_time": { "type": "date" } } } } -
一般使用如下形式表示日期类型数据。
- 格式化的日期字符串。
- 毫秒级的长整型,表示从1970年1月1日0点到现在的毫秒数。
- 秒级别的整型,表示从1970年1月1日0点到现在的秒数。
-
日期类型的默认格式为 stric_data_optional||epoch_millis。
- stric_data_optional:支持 yyyy-MM-dd、yyyyMMdd、yyyyMMddHHmmss、yyyy-MM-ddTHH:mm:ss、yyyy-MM-ddTHH:mm:ss.SSS、yyyy-MM-ddTHH:mm:ss:SSSZ等格式。
- epoch_millis:从1970年1月1日0点到现在的毫秒数。
-
布置吃我们常用的 yyyy-MM-dd HH:mm:ss,在我们插入、查询数据使用该格式会报错,我们可以在创建映射时
指定日期字段的 format 属性为自定义格式。PUT /hotel { "mappings": { "properties": { "create_time": { "type": "date", "format":"yyyy-MM-dd HH:mm:ss" } } } }
-
2. 复杂的数据类型
-
数组类型
- ES 数组没有定义方式,使用方式即开箱即用,
无需事先声明,在写入时用括号 [] 括起来,由 ES 对该字段完成定义。 - 如果实现字段已经定义了数据类型,
在插入数组数据时,ES也会将数据转化为数组进行存储。比如 设置字段 字段 tay 类型为keyword,插入数据时(也可插入空数组,即值为 [] ):POST /hotel/_doc/001 { "tag": [ //写入字符串数组类型 "有车位", "免费WIFI" ] } - 数组类型的搜索方式
适用于元素类型的搜索方式。也就是说,数组元素类型(即定义的映射字段类型,比如keyword)使用什么搜索,数组字段就适用于什么数组。如上例中,keyword 就是用于 term 搜索。GET /hotel/_search { "query": { "term": { "tag": { "value": "有车位" } } } }
- ES 数组没有定义方式,使用方式即开箱即用,
-
对象类型
- 在实际业务中,
一个文档需要包含其他内部对象。 - 比如就点搜索中,用户希望酒店信息中包含评论数据,而评论数据也分好评数据和坏评数据。为了支持这种业务,ES中可以使用兑现类型。和数组类型一样,也
不需要事先定义,写入文档时自动识别并转化为对象类型。 - 添加一条数据:
PUT /hotel/_doc/001 { "comment_info": { //评论数据 "properties": { "favourable_comment": 199, //好评数据 "negative_comment": 68 //差评数据 } } } - 根据对象类型中的属性进行搜索时,可以直击用 ‘.’ 操作符进行指向。例如,搜索 hotel 索引中好评数大于200的文档。
GET /hotel/_search { "query": { "range": { "comment_info.properties.favourable_comment": { "gte": 200 } } } } - 当然,对象内部还可以在包括对象。
PUT /hotel/_doc/001 { "comment_info": { "properties": { "favourable_comment": 199, "nagative_comment": 68, "top3_favourable_comment": { //新增字段 "top1": { "content": "干净整洁的一家酒店", //增加的第一条评论数据 "score": 87 }, "top2": { //增加的第二条评论数据 "content": "服务周到,停止方便", "score": 89 }, "top3": { //增加的第三条评论数据 "content": "闹钟取静,环境优美", "score": 90 } } } } }
- 在实际业务中,
-
地理类型- 该类型需要在 mapping 中指定目标字段的数据类型为
geo_point类型。PUT /hotel { "mappings": { "properties": { "location": { "type": "geo_point" } } } } - 添加一条酒店文档
POST /hotel/_doc/001 { "loaction": { "lat": 40.012134, "lon": 116.497553 } }
- 该类型需要在 mapping 中指定目标字段的数据类型为
3. 动态映射
-
当字段没有定义时,ES 可以根据写入的数据自动定义该字段的类型,这种机制叫做动态映射。前面介绍中也用到过。 -
数组类型和对象类型,这两种类型都不需要用户提前定义,ES 将根据写入的数据自动创建 mapping 中对应的字段并指定类型。
-
对于
基本类型,如果字段没有定义类型,ES 在将数据存储到索引时会进行自动映射。映射表如下:JSON 类型 索引类型 null 不新增字段 true或false boolean integer long object object(对象) array 根据数组中的第一个非空值进行判断 string date、double、long、text,根据数据形式进行转换 -
一般情况下,使用基本数据类型时,最好先定义好类型。因为动态映射可能会和用户预期有偏差。
4. 多字段
-
针对同一个字段,有时需要不同的数据类型,通常表现在为了不同的目的以不同的索引类型来实现。
-
例如,在订单搜索中,即希望能够按照用户姓名进行搜索,也希望按照姓氏进行排序,可以在 mapping 定义中将姓名字段先后定义为 text 类型和 keyword 类型。其中 keyword 类型的字段为子字段,这样在 ES 在建立索引时会将姓名字段建立两份索引,即 text 类型的索引和keyword 类型的索引。索引定义如下:
PUT /hotel_order { "mappings": { "properties": { "order_id": { "type": "keyword" }, "user_name": { "type": "text", "fields": { //定义 user_name 多字段 "user_name_keyword": { //定义 user_name 字段的子字段 user_name_keyword,并定义其类型为 keyword "type": "keyword" } } } } } } -
在普通搜索中使用 user_name 字段
GET /hotel_order/_search { "query": { "match": { "user_name": "Jordan" } }, "sort": { "user_name.user_name_keyword": "asc" } }
3. 文档操作
- 使用 ES 构建搜索引擎时需要经常堆文档进行操作,除了简单的单文档操作,还需要进行批量操作。接下来除了会展示 ES 操作的命令外,还会展示这些命令在 javaClient 中的是如何使用的。
1. 单条写入文档
-
POST / [index_name] / _doc / [id]。id为ES中的稳定id,这种请求方式是用户自定义id值,不使用 ES 生产的id。也可不指定id,由ES自动生成。POST /hotel/_doc { "title": "好再来酒店", "city": "青岛", "price": 578.23 } -
使用 Java API client
- service
package com.study.elasticsearch.service; import co.elastic.clients.elasticsearch.core.IndexResponse; import java.io.IOException; public interface EsDocService { /** * 新增一个文档 * * @param indexName 索引名称 * @param indexId 索引id * @param doc 新增文档 * @return */ <T> IndexResponse saveDoc(String indexName, String indexId, T doc) throws IOException; } - 实现类
package com.study.elasticsearch.service.impl; import co.elastic.clients.elasticsearch.ElasticsearchAsyncClient; import co.elastic.clients.elasticsearch.ElasticsearchClient; import co.elastic.clients.elasticsearch.core.IndexResponse; import com.study.elasticsearch.service.EsDocService; import org.springframework.stereotype.Service; import javax.annotation.Resource; import java.io.IOException; @Service public class EsDocServiceImpl implements EsDocService { @Resource private ElasticsearchClient client; @Resource private ElasticsearchAsyncClient asyncClient; @Override public <T> IndexResponse saveDoc(String indexName, String indexId, T doc) throws IOException { IndexResponse indexResponse = client.index(idx -> idx.index(indexName).id(indexId).document(doc)); return indexResponse; } }
- service
2. 批量写入文档
-
ES 中批量写入文档请求的类型是 POST,形式如下。
POST /_bulk //批量请求 {"index":{"_index":"${index_name}"}} //指定批量写入的索引 {...} //该索引下的文档内容 {"index":{"_index":"${index_name}"}} //指定批量写入的索引 {...} //该索引下的文档内容 -
举个例子:
POST /[index_name]/_bulk {"index":{"_index":"hotel"}} {"title":"文雅酒店","city":"北京","price":556.00} {"index":{"_index":"hotel"}} {"title":"嘉怡假日就点","city":"北京","price":337.00} -
上述的 DSL 写入索引中的文档id是es自动生成的,如果需要指定id,需要在index后面拼接。如:{“index”:{“_index”:“hotel”,“_id”:“1001”}}
-
批量的提交内容可能很多,我们可能需要把这些内容放入文档中, 然后提交文档来批量写入。使用命令:
- curl -s -XPOST ‘127.0.0.1:9200/_bulk?preety’ --data-binary “@bulk_doc.json”
- bulk_doc.json 对应的文件名称。

-
对应的 JavaClient 代码操作。
-
service
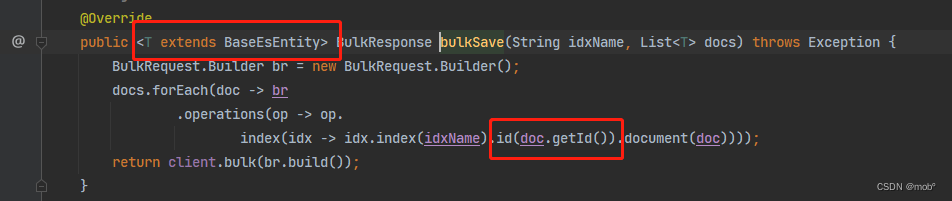
package com.study.elasticsearch.service; import co.elastic.clients.elasticsearch.core.BulkResponse; import co.elastic.clients.elasticsearch.core.IndexResponse; import java.io.IOException; import java.util.List; public interface EsDocService { /** * 新增一个文档 * * @param indexName 索引名称 * @param indexId 索引id * @param doc 新增文档 * @return */ <T> IndexResponse saveDoc(String indexName, String indexId, T doc) throws IOException; /** * 批量添加文档 (该方式适用于es自动生成文档的id方式,因为泛型文档无法获取里面属性,比如id) * * @param idxName 索引名称 * @param docs 文档集合 * @return * @param <T> 文档实体类 * @throws Exception */ <T> BulkResponse bulkSave(String idxName, List<T> docs) throws Exception; } -
实现类
package com.study.elasticsearch.service.impl; import co.elastic.clients.elasticsearch.ElasticsearchAsyncClient; import co.elastic.clients.elasticsearch.ElasticsearchClient; import co.elastic.clients.elasticsearch.core.BulkRequest; import co.elastic.clients.elasticsearch.core.BulkResponse; import co.elastic.clients.elasticsearch.core.IndexResponse; import com.study.elasticsearch.service.EsDocService; import org.springframework.stereotype.Service; import javax.annotation.Resource; import java.io.IOException; import java.util.List; @Service public class EsDocServiceImpl implements EsDocService { @Resource private ElasticsearchClient client; @Resource private ElasticsearchAsyncClient asyncClient; @Override public <T> IndexResponse saveDoc(String indexName, String indexId, T doc) throws IOException { IndexResponse indexResponse = client.index(idx -> idx.index(indexName).id(indexId).document(doc)); return indexResponse; } @Override public <T> BulkResponse bulkSave(String idxName, List<T> docs) throws Exception { BulkRequest.Builder br = new BulkRequest.Builder(); docs.forEach(doc -> br .operations(op -> op. index(idx -> idx.index(idxName).document(doc)))); return client.bulk(br.build()); } } -
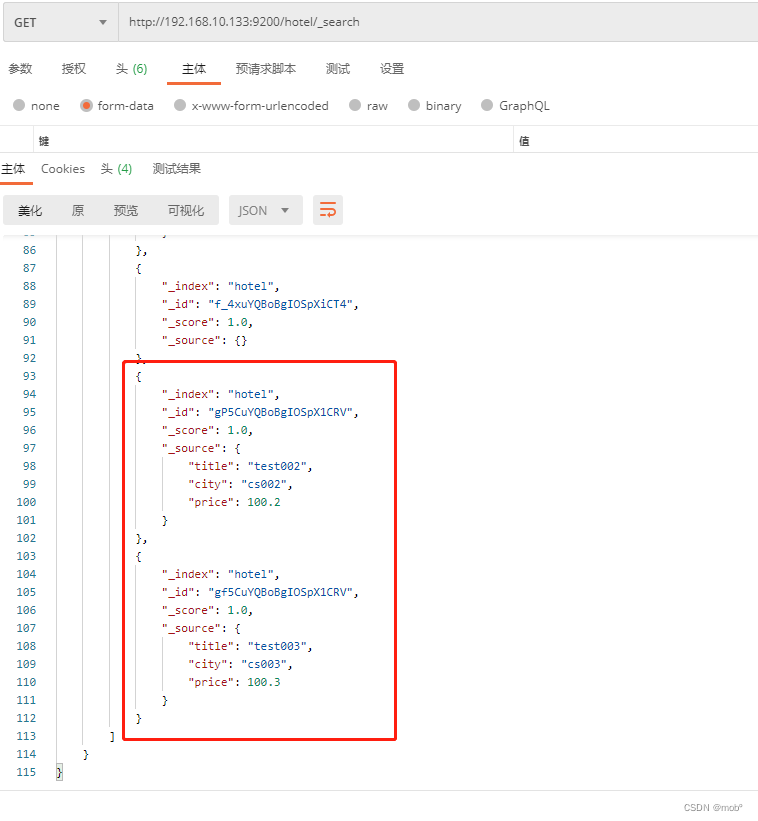
测试:
-
-
考虑到会根据id更新的情况,接口优化如下:
3. 更新单条文档
-
在 ES 中更新文档的请求类型是 POST ,形式如下:
POST /[index_name]/_update/[_id] -
举个例子:
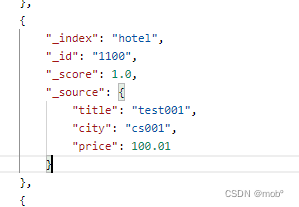
POST /hotel/_update/1100 { "title":"test05", "city":"cs005", "price":"659.45" } -
根据文档 id 搜索命令:GET /[index_name]/_doc/[id]
GET /hotel/_doc/1100 -
更新操作对应的 JavaClient 代码:
-
service
/** * 更新一个文档 * * @param idxName 索引名称 * @param data 更新文档 * @param <T> 文档类型 */ <T extends BaseEsEntity> void updateDoc(String idxName, T data) throws IOException; -
serviceImpl
@Override public <T extends BaseEsEntity> void updateDoc(String idxName, T data) throws IOException { client.update(e -> e.index(idxName).id(data.getId()).doc(data), data.getClass()); }
-
-
也可用 上文提到的新增 save 方法,但是要 文档id 不为空 且 已存在。
-
测试:
- 更新前:

- 更新后:

- 更新前:
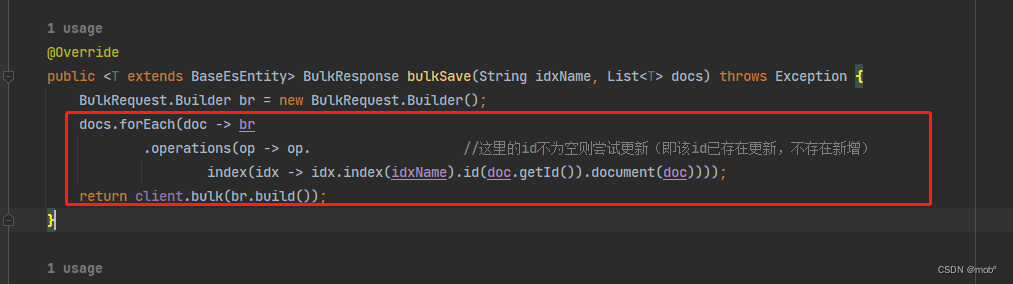
4. 批量更新文档
-
指令和批量写相似:区别在于这里的 文档 _id 为必填项。
POST /_bulk //批量请求 {"index":{"_index":"${index_name}","_id":"${id}"}} //指定批量写入的索引 {...} //该索引下的文档内容 {"index":{"_index":"${index_name}","_id":"${id}"}}} //指定批量写入的索引 {...} //该索引下的文档内容 -
对应客户端,代码和批量新增一致,只是更新的话 id 不为空且已存在。
5. 根据条件更新文档
- 使用 _upda_by_query 功能。
POST /[_index_name]/_update_by_query
{
"query":{ //更新文档的查询条件
...
},
"script":{ //条件更新的更新脚本
...
}
}
- 举个例子:
POST /[_index_name]/_update_by_query
{
"query":{ //更新文档的查询条件,城市为北京的文档
"term":{
"city":{
"value":"北京"
}
}
},
"script":{ //条件更新的更新脚本,将城市改为"上海"
"source":"ctx._source['city']='上海'",
"lang":"painless"
}
}
- 对应的 JavaClient 代码:
//todo
5. 删除单条文档
-
请求类型 DELETE
DELETE /[_index_name]/_doc/[id] -
举个例子:
DELETE /hotel/_doc/001

6. 批量删除文档
-
与批量写入和更新文档不同的是,批量删除文档不需要提供 JSON 数据。
POST /_bulk //批量删除文档,指定文档_id {"delete":{"_inde":"${index_name"},"_id":"${_id}"}} //批量删除文档,指定文档_id {"delete":{"_inde":"${index_name"},"_id":"${_id}"}} -
对应的 JavaClient 代码:
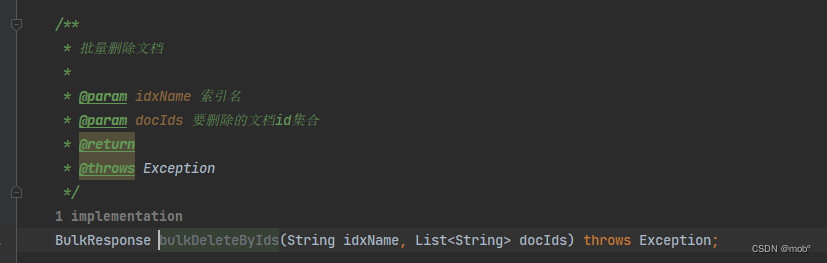

7. 根据条件删除文档
-
ES 提供了 _delete_by_query 功能。
POST /${index_name}/_delete_by_query { "query":{ ... } } -
举个例子:
POST /${index_name}/_delete_by_query { "query":{ "term":{ "city":{ "value":"北京" } } } } -
对应的 JavaClient 代码:
//todo
六、丰富的搜索功能
- 为优化搜索性能,需要指定一部分字段内容。为了更好地呈现呈现结果,需要用到结果计数和分页功能;当遇到性能瓶颈时,需要剖析搜索各个环节的耗时;面对不符合预期的搜索结果时,需要分析各个文档的评分细节。
- 后面的客户端操作会使用 elasticsearch high level client 客户端进行操作
1. 指定返回的字段
-
考虑到性能问题,需要对搜索结果进行"瘦身" ——指定返回的字段。
-
在 ES 中,通过 _source 字句可以设定返回结果的字段。_source 指向一个 JSON 数组,数组中的元素是希望返回的字段名称。
-
下面的 DSL 指定搜索结果只返回 title 和 city 字段。
GET /hotel/_search { "_source":["title","city"], //设定只返回 title 和 city 字段 "query":{ "term":{ "city":{ "value":"北京" } } } } -
客户端代码:
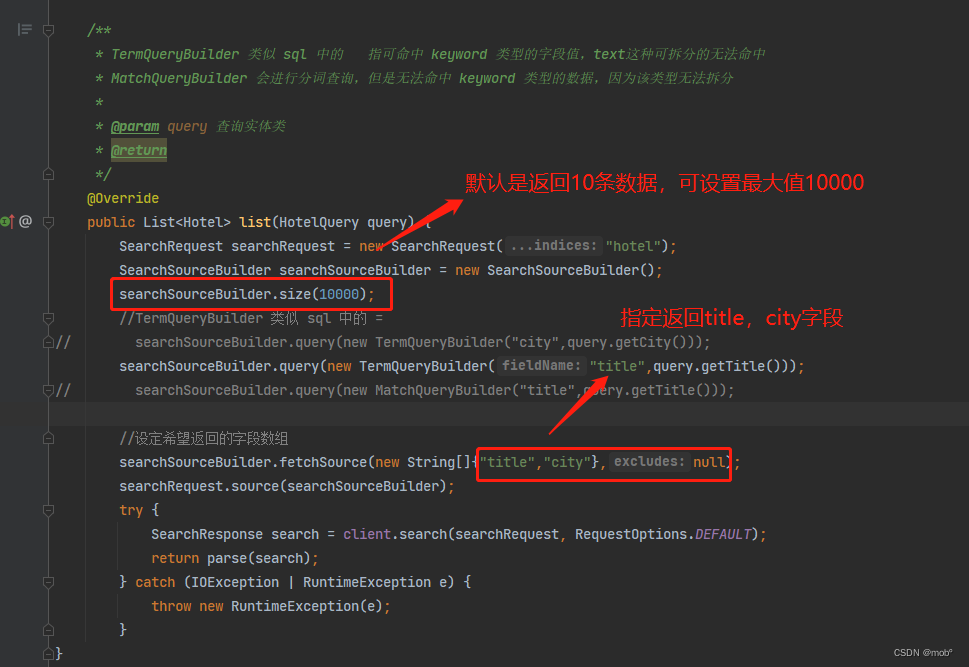
2. 结果计数
-
针对搜索结果进行计数。
-
DSL 语句如下
GET /hotel/_count { "query": { "term": { "city": { "value": "北京" } } } } -
客户端代码:
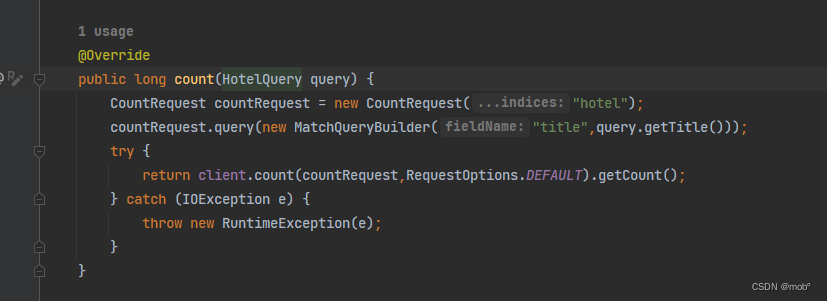
3. 结果分页
-
ES 默认返回前10个搜索匹配的文档,可以通过设置 from 和 size 来定义搜索的位置和每页显示的文档数量。
- from:查询结果的起始下标。
- size:从下标开始返回的文档个数。
-
DSL 语句:
GET /hotel/_search { "from": 0, "size": 20, "query": { "term": { "city": { "value": "北京" } } } } -
ES 最大可返回 10000 但是也可以修改。
PUT /hotel/_settings { "index":{ "max_result_window":20000 } } -
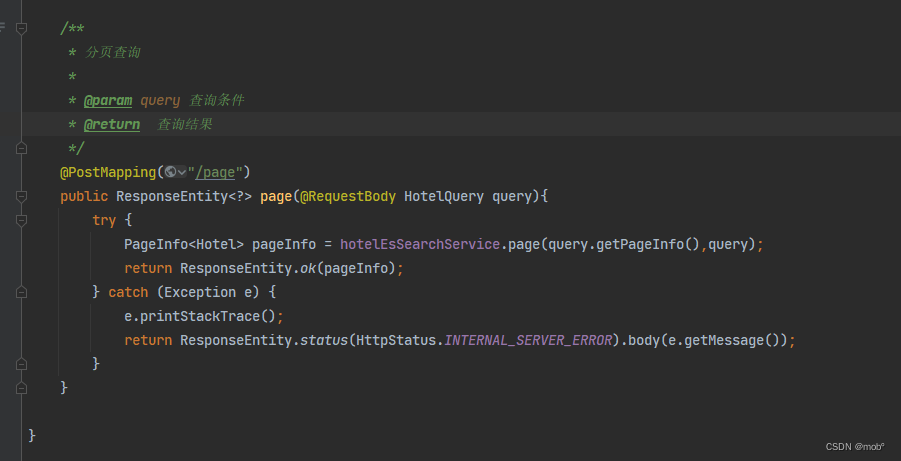
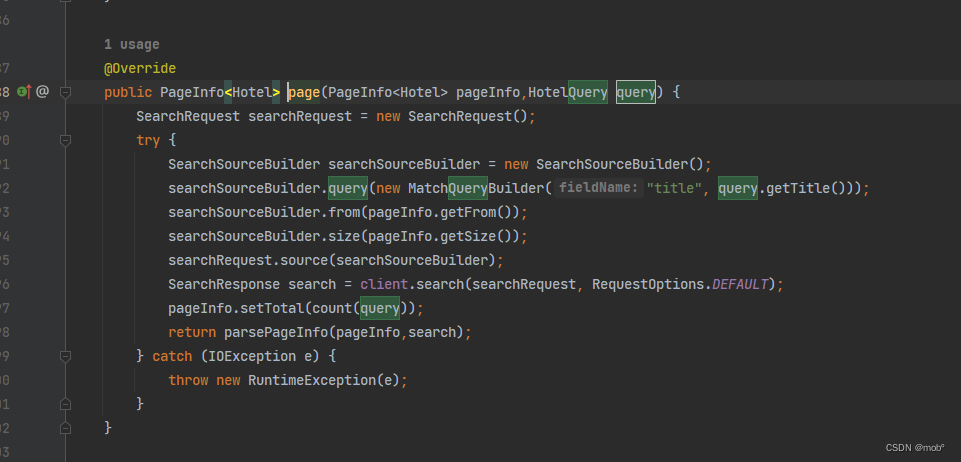
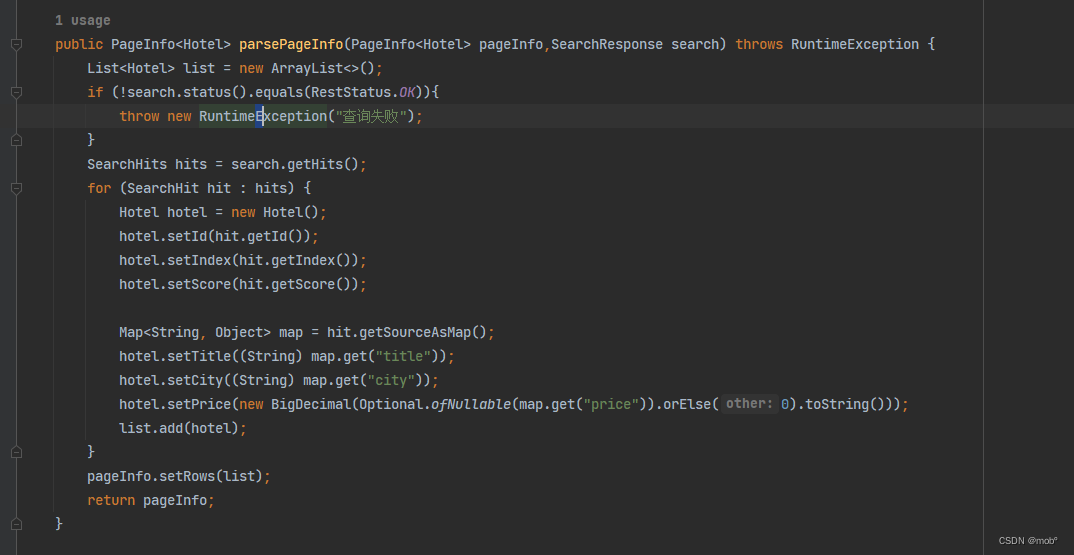
客户端代码:
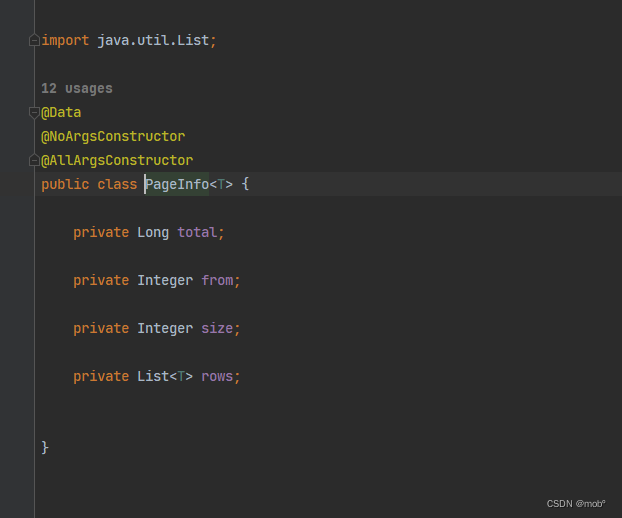
4. 查询性能分析
- 在使用 ES 搜索的过程中,有的搜索请求的响应可能比较慢,大部分是DSL的执行逻辑有问题。通过 ES 提供的 profile 功能,该功能能详细的列出搜索时每一个步骤的耗时,可以帮助我们对 DSL 的性能进行剖析。
- DSL 语句
GET /hotel/_search
{
"profile":"true", //打开性能剖析开关
"query":{
"match":{
"title":"金都"
}
}
}
- 建议使用 Kibana 提供的可视化工具,更加的直观。
5. 查询所有文档
-
DSL 语句:
GET /hotel/_search { "_source":[ //只返回title 和city字段 "title", "city" ], "query":{ "match_all":{ //查询所有文档 "boost":2 //设置所有分值为2.0 } } } -
Java 客户单:
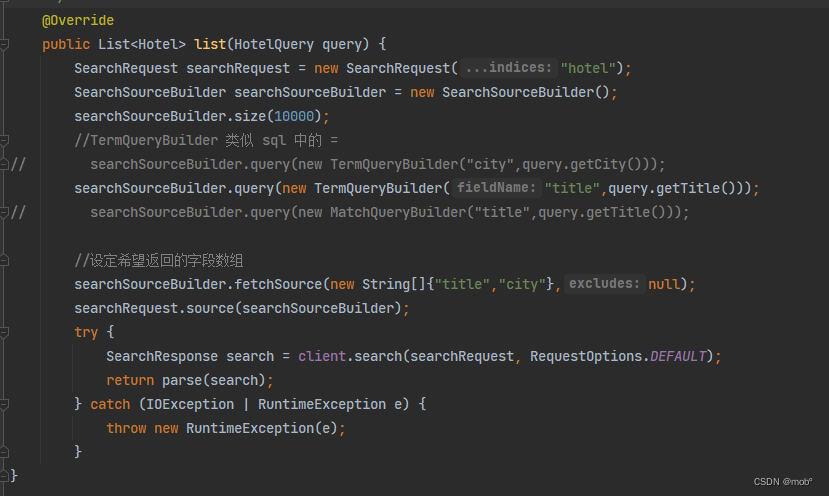
6. term 查询
-
term 查询是结构化精准查询的主要查询方式,用于查询待查字段和查询值是否
完全匹配。 -
DSL 语句如下:
GET /hotel/_search { "query"{ "term":{ "city":{ "value":"北京" } } } } -
需要注意的是日期类型字段的查询。参考上文。
-
Java 客户端中没有 日志类型的参数查询,该如何解决呢。可以使用日期类型字符串来解决,如下:
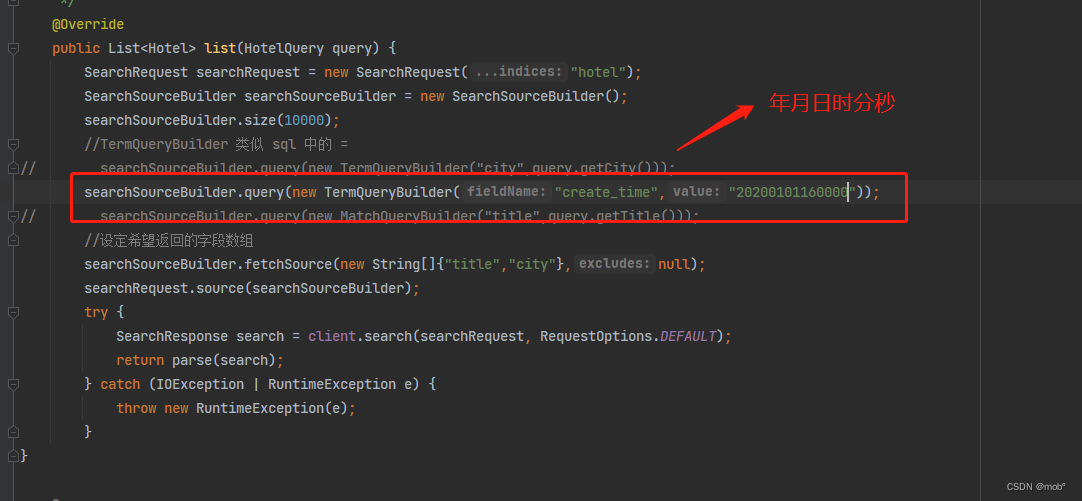
7. terms 查询
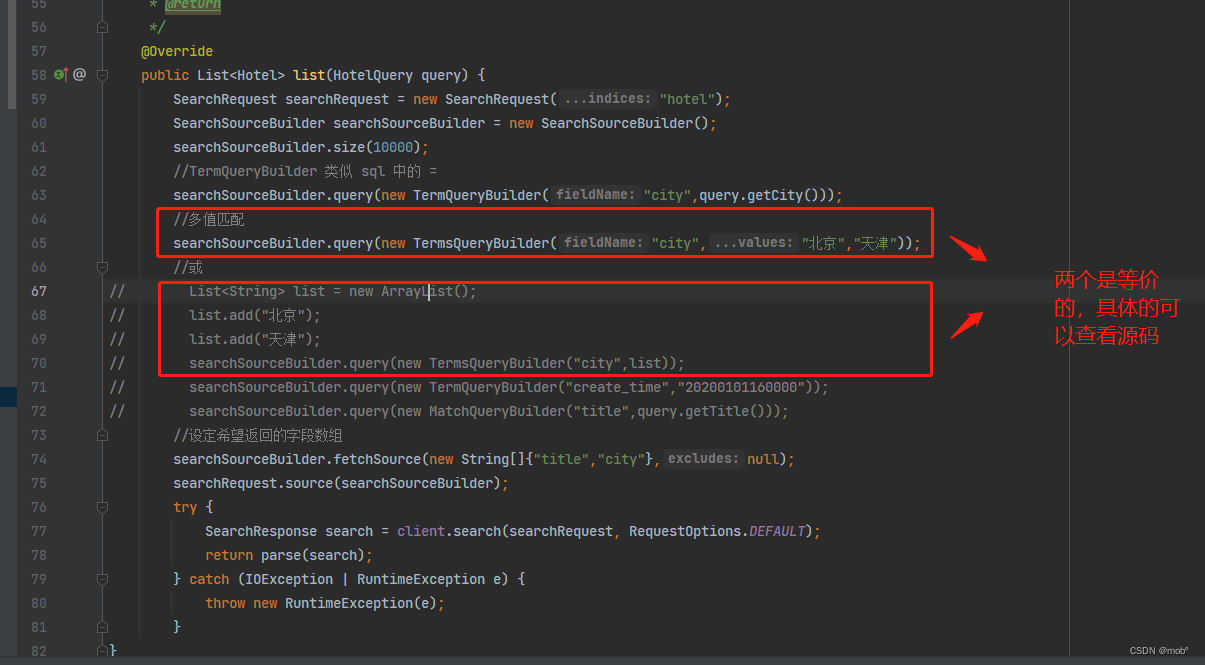
-
terms 是 term 的拓展形式。用于查询一个或多个值与待查字段是否完全匹配。
-
DSL 语句如下:
GET /hotel/_search { "query"{ "term":{ "city":{ "北京", "天津" } } } } -
Java 客户端代码:
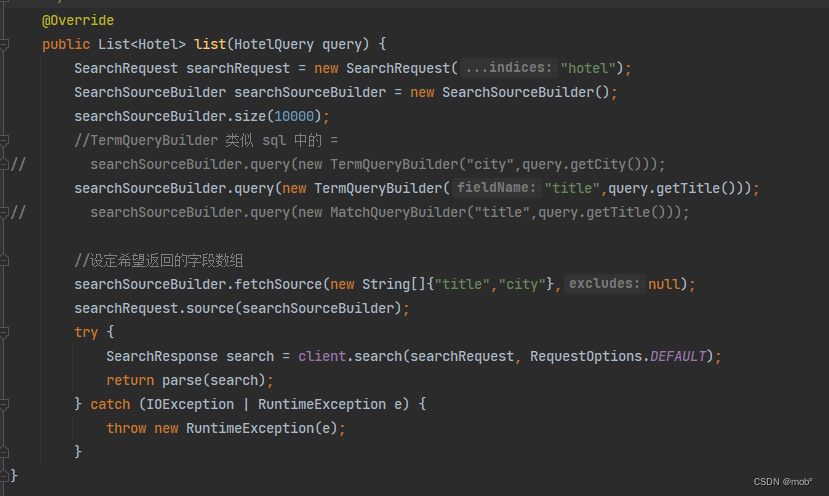
8. range 查询
-
用于范围查询。一般针对数值和日期类型做范围查询。
- gt:大于
- lt:小于
- gte:大于或等于
- lte:小于或等于
-
DSL 语句如下:
GET /hotel/_search { "query":{ "range"{ "price":{ "gte":300, "lte:500 } } } } -
Java 客户端如下:
9. exists 查询
-
在某些场景下,我们希望找到某个字段不为空的文档,可以使用 exists 查询。
-
字段不为空的情况有:
- 值存在且不为空。
- 值不是空数组。
- 值是数组,但不是null。
-
DSL 语句如下。
GET /hotel/_search { "query":{ "exists":{ "field": "price" } } } -
Java 客户端代码
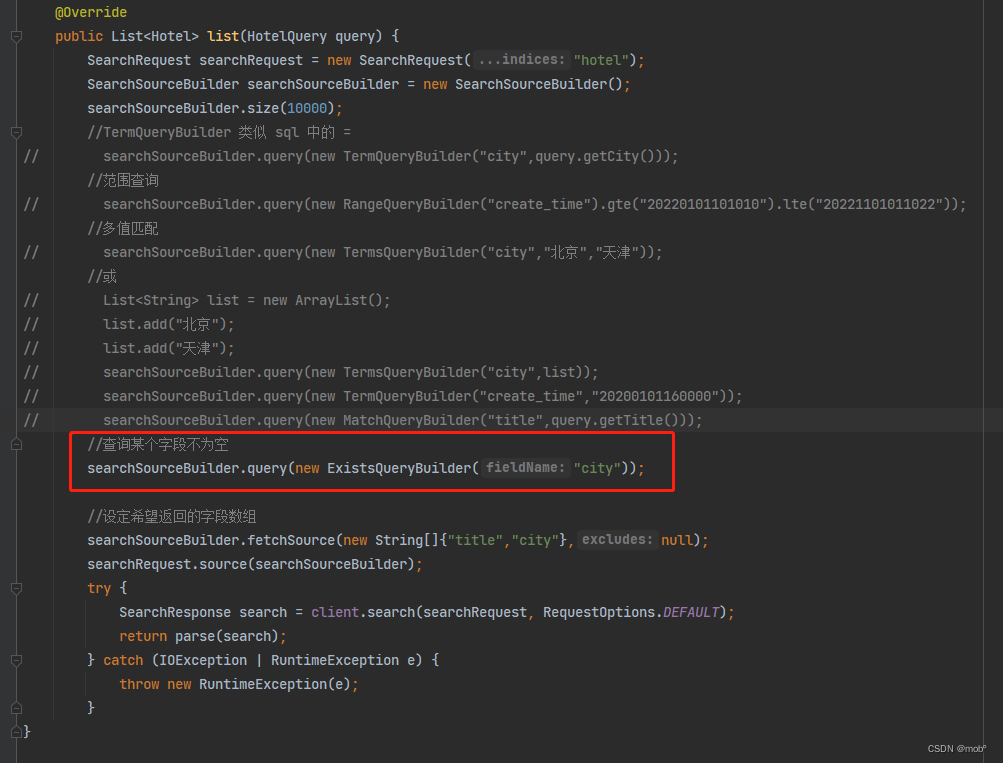
10. must 查询
-
相当于逻辑查询中的 “与” 查询。must 搜索包含一个数组,可以把其他的 term 级别的小哈讯以及布尔查询放入其中。
-
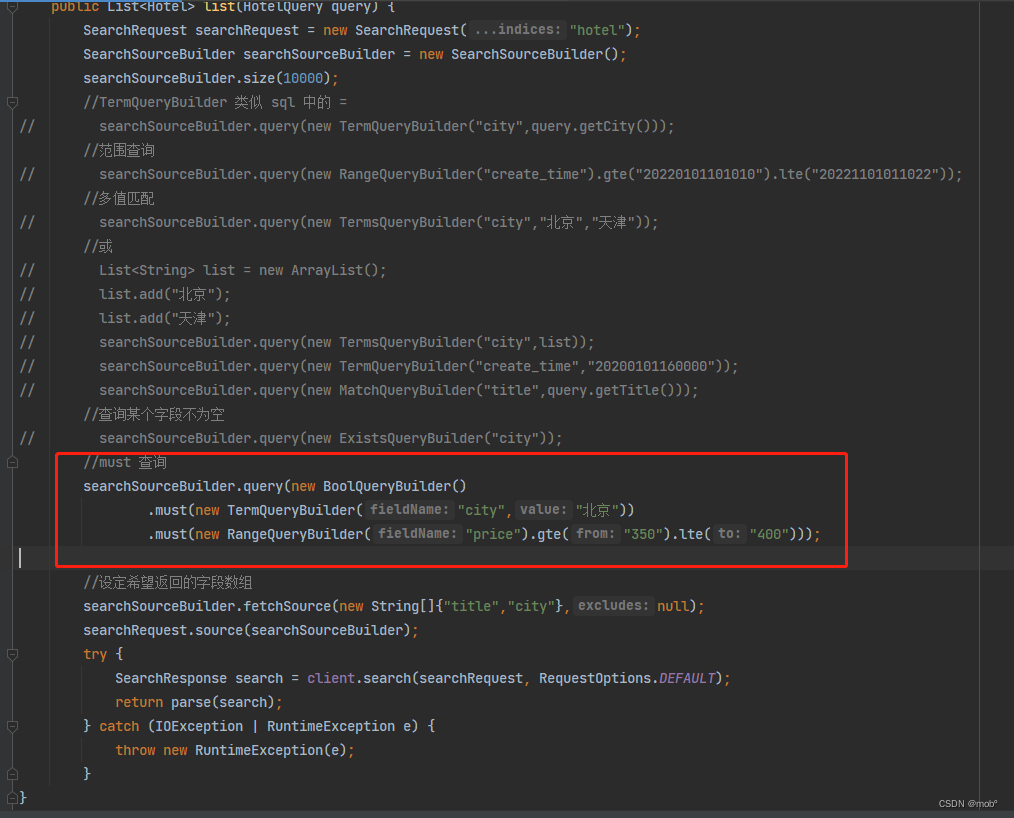
使用 must 查询城市为北京 且 价格在350~400之间的酒店。
GET /hotel/_search { "query": { "bool": { "must": [ //拼接多个查询,用 and 连接 { //第一个子查询: "term": { "city": { "value": "北京" } } }, { //第一个子查询: "range": { "price": { "gte": 350, "lte": 400 } } } ] } } } -
Java 客户端:
11. should 查询
-
should 包含一个数组,可以把其他的 term 级别的查询及布尔查询放入其中。
GET /hotel/_search { "query": { "bool": { "should": [ //拼接多个查询,用 or 连接 { //第一个子查询: "term": { "city": { "value": "北京" } } }, { //第一个子查询: "term": { "city": { "value": "天津" } } } ] } } } -
Java 客户端

12. must not 查询
-
表示 非。
-
使用 must not 查询城市即不为北京也不为天津的酒店。
GET /hotel/_search { "query": { "bool": { "must_not": [ //拼接多个查询,用 or 连接 { //第一个子查询: "term": { "city": { "value": "北京" } } }, { //第一个子查询: "term": { "city": { "value": "天津" } } } ] } } } -
Java 客户端

13. filter 查询
-
即过滤查询。其他布尔查询关注的是查询条件和文档的匹配程度,并按照匹配程度进行打分。而 filter 查询只关注的是查询条件和文档是否匹配,不进行相关的打分计算,但是会对部分匹配结果进行缓存。
-
DSL 语句如下:城市为北京,且未满房的酒店。
-
如果查询不需要打分,filter 查询更加高效。
GET /hotel/_search { "query": { "bool": { "filter": [ //拼接多个查询,用 or 连接 { //第一个子查询: "term": { "city": "北京" } }, { //第一个子查询:满房状态为否 "term": { "full_room": false } } ] } } } -
Java 客户端

14. Constant Score 查询
-
如果不想让检索词频率TF(Term Frequency)对搜索结果排序有影响,只想过滤某个文本字段是否包含某个词。可以使 Constant Score 包含起来。
-
比如查询字段 amenities 字段包含关键字 “停车场” 的酒店。
GET /hotel/_search { "_source":["amenities"], "query": { "constant_score":{ //满足条件即打分1 "match":{ "amenities":"停车场" //查询设施中包含”停车场“的文档 } } } } -
Java 客户端

15. match 查询
- 不同于结构化查询,全文搜索首先对查询词进行分析,然后根据查询词的分词结果构建查询。这里全文指的是数据类型 text 类型。
- 结构化搜索关注的是数据是否匹配,结构化搜索一般用于精准匹配。
- 全文搜索关注的是匹配的程度,而全文搜索用于部分匹配。
- 默认情况下,match 查询使用的是标准的分词器。该分词器比较适用于英文,如果是中文则按照字进行切分,所以默认的不太合适,需要使用对应的中文分词器。
- 需要注意的是,match 匹配中参数 operator ,默认是或(or),即进行分词查询时,用or连接。可以设置与(and):
GET /hotel/_search
{
"_source": [
"amenities"
],
"query": {
"match": {
"title": "金都",
"operator": "and"
}
}
}
- 也可是指匹配程度进行搜索。
GET /hotel/_search
{
"_source": [
"amenities"
],
"query": {
"match": {
"title": "金都",
"operator": "or",
"minimum_should_match":"80%" //设置最小匹配度为80%
}
}
}
- Java 客户端

16. multi_match 查询
-
在多个字段里查询关键字。
-
比如在 title 和 amenities 两个字段里同时搜索 “假日” 关键词。即 title = 假日 or amenities = 假日。
GET /hotel/_search { "_source":["titile","amenities"], "query":{ "multi_match":{ "query":"假日", "fields":[ "title", "amenities" ] } } } -
Java 客户端

17. match_phrase 查询
-
用于搜索确切的短语或邻近的词语。
-
假设在标题里搜索 “文雅酒店”,希望酒店标题中的“文雅”与“酒店”紧邻并且“文雅”在“酒店”前面,则使用 match_phrase 查询。
GET /hotel/_search { "query"{ "match_phrase":{ "title": "文雅酒店" } } } -
如果有文档title 为文雅精品酒店,则无法匹配,因为默认间隔阈值为1,文雅精品酒店中文雅和酒店差2。可以设置最大阈值
GET /hotel/_search { "query"{ "match_phrase":{ "title": { "query":"文雅酒店", "slop":2 } } } } -
Java 客户端

18. 地理位置查询
- 地理点(geo_point)字段类型查询方式有三种:
- geo_distance 查询:需要用户指定一个坐标点,在指定的距离该店的范围后,ES 即可查询到响应的文档。
- geo_bounding_box 查询:提供的是矩形内的搜索。需要用户给出左上角和右下角的顶点地理坐标。
- geo_polygon 查询:支持多边形内的文档搜索。
- 假设 北京天安门的经纬度为[116.4039,39.915142],以下使用 geo_distance 查询找到天安门 5KM 范围内的酒店。
GET /hotel/_search
{
"_source": [
"title",
"city",
"location"
],
"query": {
"geo_distance": {
"distance": "5KM", //设置距离范围为5KM
"location": { //设置中心点经纬度
"lat": "39.915142", //设置纬度
"lon": "116.4039" //设置经度
}
}
}
}
-
Java 客户端:

- geo_bounding_box :给其左上角经纬度:[116.457044,39.922821],右下角顶点的经纬度为:[116.479466,39.907104]。
{ "_source": [ "title", "city", "location" ], "query": { "geo_bounding_box": { "location": { "top_left": { "lat": "39.922821", "lon": "116.457044" }, "bottom_right": { "lat": "39.907104", "lon": "116.479466" } } } } } -
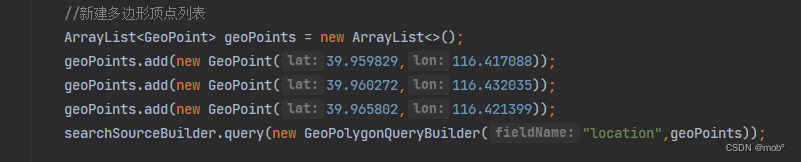
geo_polygon :比如求三角形内的文档,给出三个顶点经纬度:[116.417088,39.959829],[116.432035,39.960271],[116.421399,39.965802]
{ "_source": [ "title", "city", "location" ], "query": { "geo_polygon": { "location": { "points": [ { "lat": "39.959829", "lon": "116.417088" }, { "lat": "39.960272", "lon": "116.432035" }, { "lat": "39.965802", "lon": "116.421399" } ] } } } } -
Java 客户单:
19. 建议搜索
-
用户每输入一个字符,前端就需要向后端发送一次查询请求对匹配项进项查询,要求后端响应速度比较高。通过协助用户进行搜索,可以避免用户输入错误的关键字,引导用户使用更合适的关键词,提升用户的搜索体验和搜索效率。
-
ES 的 Completion Suggester 是比较合适的。为了使用 Completion Suggester ,其对应的字段类型需要定义为 completion 类型。
-
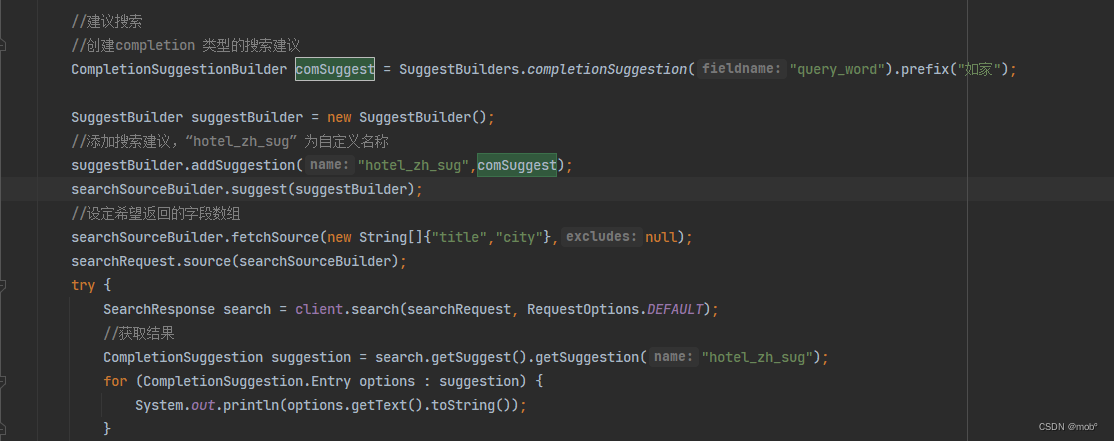
假设用户输入 “如家”关键词,需要 ES 给出前缀为该词的酒店查询词,DSL 语句如下:
GET /hotel/_search { "suggest": { "hotel_zh_sug": { //定义搜索建议名称 "prefix": "如家", //设置搜索建议的前缀 "completion": { //设置搜索建议对应的字段名称 "field": "query_word" } } } } -
返回结果也有所不同,不是分装在 hits 中,而是分装在 suggest 中。
-
Java 客户端
20. 按字段值排序
-
默认情况下,ES 堆搜索结果的相关性进行降序排序的,有时需要对某个字段进行升序或者降序排序。
-
ES 提供了 sort 子句可以堆数据进行排序。默认对字段进行升序排序的(即不设置了该字段排序但没设置升序还是降序)。
-
使用 sort 默认情况下是不进行打分的。
-
先按价格进行降序排序,在按口碑进行降序排序。
GET /hotel/_search { "source": [ "title", "price" ], "query": { "match": { "title": "金都" } }, "sort": [ { //按照价格降序排序 "price": { "order": "desc" }, "praise": { //按照口碑进行降序排序 "order": "desc" } } ] } -
Java 客户端
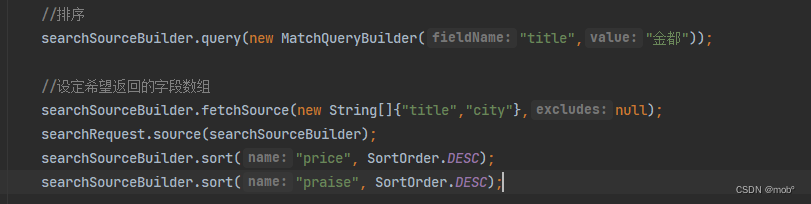
21. 按地理距离排序
-
按照文档坐标与指定坐标的距离对结果进行排序。
{ "source": [ "title", "price", "location" ], "query": { "geo_distance": { "distance": "5km", //设置地理位置为5km "location": { //设置中心点坐标 "lat": "39.915143", "lon": "116.4039" } } }, "sort": [ //设置排序逻辑 { "_geo_distance": { "lacation": { //设置排序的中心点坐标 "lat": "39.915143", "lon": "116.4039" }, "order": "asc", //按照距离由近到远 "unit": "km", //所使用的距离的计量单位 "distance_type": "plane" //排序所使用的距离计算算法 } } ] } -
Java

七、文本搜索
- 作为一款搜索引擎框架,文本搜索是核心功能。ES 在文本索引的建立和搜索依赖两大组件:
- Lucene :负责进行倒排索引的物理构建。
- 分析器:在建立倒排索引前和搜索前堆文本进行分词和语法处理。
1. 文本索引的建立过程
-
为了完成文本的快速搜索,ES 使用了一种称为 “倒排索引” 的数据结构。倒排索引中的所有词语存储在词典中,每个词语又指向包含它的文档信息列表。
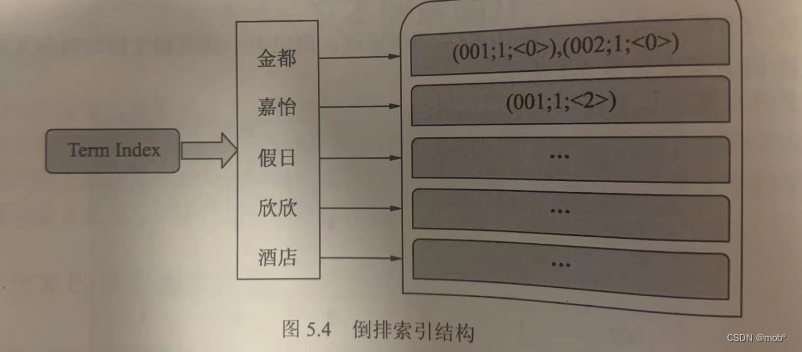
- 假设需要对下面两个酒店的信息进行倒排索引的创建。
- 文档 ID 为 001,酒店名称为 “金都嘉怡假日酒店”。
- 文档 ID 为002,酒店名称为“金都欣欣酒店”
-
首先,ES 将文档交给分析器进行处理,处理的过程中包括字符过滤、分词和分词过滤,最终的处理结果是文档内容被表示为一系列关键词信息的集合。关键词信息指关键词本身以及它在文档中的位置信息和词性信息,如下图所示:
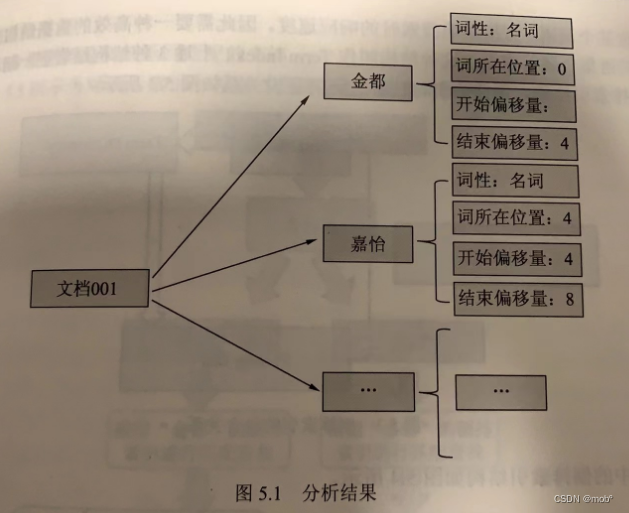
-
其次,ES 根据分析结果建立文档-词语矩阵,用以表示词语和文档的包含关系。
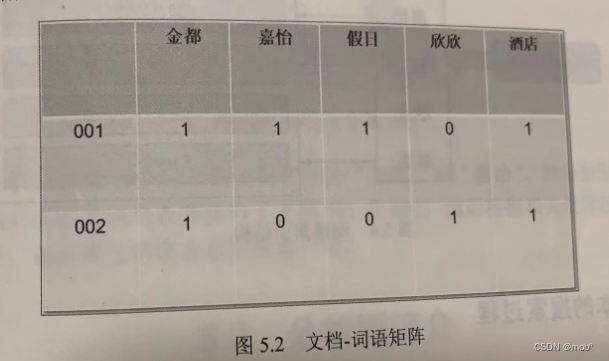
-
ES 会遍历文档-词语矩阵中的每一个词语,然后将包含该词语的文档信息与该词语建立一种映射关系。映射关系中的词语集合叫作 Term Dictionary,即“词典”。映射中的文档集合信息不仅包含文档ID,还包含词语在文档中的位置和词频信息,包含这些文档信息的结构叫作 Postion List。需要一种高效的数据结构堆映射关系中的词语集合进行索引,这种结构叫作 Term Index,上述三种结构结合在一起就成了 ES 的倒排索引。
-
倒排索引与三者之间的逻辑关系如图所示:
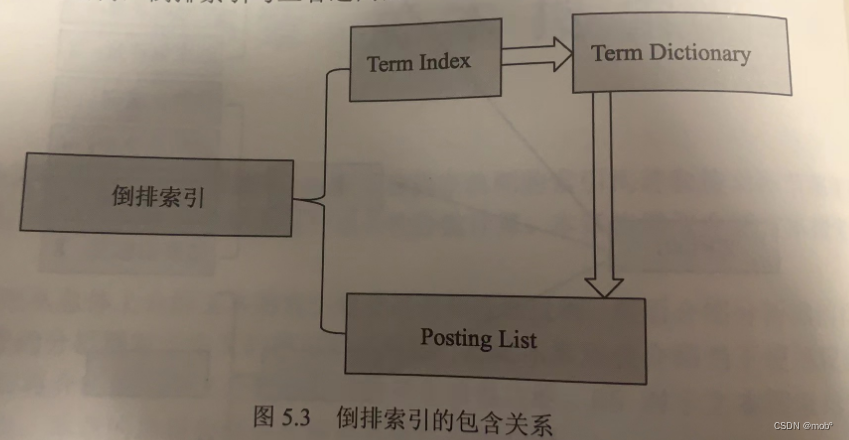
-
本例中的倒排序索引如图所示:
2. 文本的搜索过程
- 在 ES 中,一般使用 match 查询对文本字段进行搜索。match 查询过程一般分为如下几步:
- ES 将查询的字符串传入对应的分析器中,分析器的主要作用是对查询文本进行分词,并把分词后的每个词语变换为对应的底层 lucene term 查询。
- ES 用 term 查询在倒排索引中查找每个 term,然后获取一组包含该term的文档集合。
- ES 根据文本相关度对每个文档进行打分计算,打分完毕后,ES 吧文档按照相关性进行倒序排序。
- ES 根据得分高低返回匹配的文档。
- 如图所示为酒店索引中搜索“金都嘉怡”的查询流程。
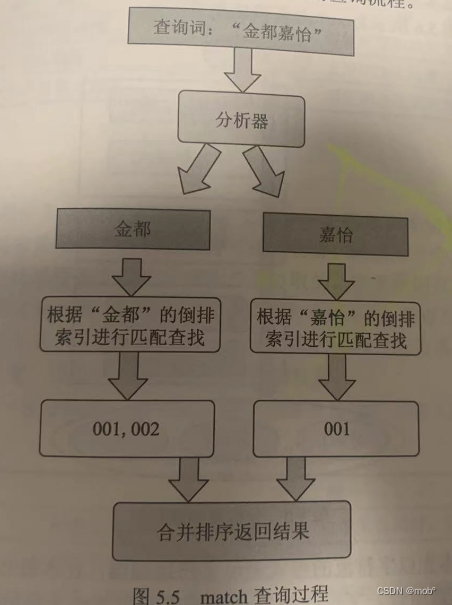
- ES 分析器先将查询词切分为“金都”和“嘉怡”,然后分别到倒排索引里查询两个词对应的文档列表并获得了文档001和002,然后根据相关性算法计算文档得分并进行排序,最后将文档集合返回给客户端。
3. 使用同义词
- 用户还可以通过 ES 中的分析器来使用同义词,有两种使用方式:
- 在建立索引时指定同义词并构建同义词的倒排索引。
- 在搜索时指定字段的 search_analyzer 查询分析器使用同义词。
1. 建立索引时使用同义词
-
在 ES 内置的分词过滤器中,有一种分词过滤器叫作 synonyms,它是一种支持用户自定义同义词的分词过滤器。以下是使用 IK 分析器和 synonyms 分词过滤器一起定义索引的DSL。
PUT /hotel { "settings": { "analysis": { "filter": { //定义分词过滤器 "ik_synonyms_filter": { "type": "synonym", "synonyms": [ //在分词过滤器中定义近义词 "北京,首都", "天津,天津卫", "假日,度假" ] } }, "analyzer": { //自定义分析器 "ik_analyzer_synonyms": { "tokenizer": "ik_max_word", //指定分词器 "filter": [ //指定分词过滤器 "lowercase", "ik_synonyms_filter" ] } } } }, "mapping": { "properties": { "title": { "type": "text", "analyzer": "ik_analyer_synonyms" //指定索引时使用自定义 的分析器 } } } } -
测试搜索:
GET /hotel/_search { "query":{ "match":{ "title":"首都度假" } } } -
返回结果
北京金都嘉怡酒店 //字段中的北京与查询词中首都匹配 文雅假日酒店 //字段中的度假与查询词中假日匹配
2.查询时使用同义词
-
在 ES 内置的分词过滤器中还有个分词过滤器叫作 synonym_graph,它是一种支持查询时用户自定义同义词的分词过滤器。以下是使用 IK 分析器和 synonym_graph 分词过滤器一起定义索引的 DSL:
PUT /hotel { "settings": { "analysis": { "filter": { //定义分词过滤器 "IK_synonyms_graph_filter": { "type": "synonym_graph", "synonyms": [ //在分词过滤器中定义近义词 "北京,首都", "天津,天津卫", "假日,度假" ] } }, "analyzer": { //自定义分析器 "ik_analyzer_synonyms_graph": { "tokenizer": "ik_max_word", //指定分词器 "filter": [ //指定分词过滤器 "lowercase", "ik_synonyms_graph_filter" ] } } } }, "mapping": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word", "search_analyzer":"ik_analyzer_synonyms_graph" //指定查询时使用自定义的分析器 } } } } -
搜索
GET /hotel/_sarch { "query"{ "match":{ "title":"首都度假" } } } -
返回结果
文雅假日酒店 北京金都嘉怡酒店 -
如果有更新同义词的需求,则只能使用查询时使用同义词的的这中方式。首先需要先关闭当前索引。
POST /hotel/_close -
添加一组近义词“精华,豪华”
PUT /hotel/_settings { "settings": { "analysis": { "filter": { //定义分词过滤器 "IK_synonyms_graph_filter": { "type": "synonym_graph", "synonyms": [ //在分词过滤器中定义近义词 "北京,首都", "天津,天津卫", "假日,度假", "精选,豪华" ] } }, "analyzer": { //自定义分析器 "ik_analyzer_synonyms_graph": { "tokenizer": "ik_max_word", //指定分词器 "filter": [ //指定分词过滤器 "lowercase", "ik_synonyms_graph_filter" ] } } } } } -
ES 支持用户将同义词放在文件中,文件的位置必须是在 ${ES_HOME}/config 目录及其子目录下,注意该文件必须存在于 ES 集群中的每一个节点上。在 ${ES_HOME}/config 目录下建立一个目录mydict,然后在该目录下创建名称为 synonyms.dict 的文件。然后在创建酒店索引时,在settings中制定同义词文件及其路径,DSL如下:
{ "settings": { "analysis": { "filter": { //定义分词过滤器 "IK_synonyms_graph_filter": { "type": "synonym_graph", "synonyms_path": "mydict/synonyms.dict" //指定同义词文件及其路径 } }, "analyzer": { //自定义分析器 "ik_analyzer_synonyms_graph": { "tokenizer": "ik_max_word", //指定分词器 "filter": [ //指定分词过滤器 "lowercase", "ik_synonyms_graph_filter" ] } } } }, "mapping": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_analyzer_synonyms_graph" //指定查询时使用自定义的分析器 } } } }
4. 拼音搜索
- 在 ES 中可以使用拼音分析器插件进行拼音搜索,插件的项目地址为github地址,该插件对较新的 ES 版本并不支持,需要用户自行进行安装编译。
1. 拼音分析器插件安装
-
拉取项目
git clone https://github.com/medcl/elasticsearch-analysis-pinyin.git -
修改该项目pom文件

-
使用 mvn 编译
mvn install -
会在 ${PROJECT_PATH}/target/release/目录下生产目标文件 elasticsearch-analysis-pinyin-7.10.2.zip。
-
在{ES_HOME}/plugins/目录下创建一个名称为 pinyin-analysis 的子目录,然后将上面的文件复制到该目录下。然后进行解压
2. 拼音分析器插件的使用
- 使用 pinyin 分析器对待测试文本进行分析,DSL如下
POST _analyze
{
"analyzer":"pinyin",
"text":"王府井"
}
-
测试发现 王府井 被切分成拼音 wang、fu、jing及首字母wfj。
-
也可将拼音分析器应用到索引的字段中。以下示例中将自定义的 ik_pinyin_analyzer 分析器设置为酒店索引中 title 字段的默认分析器。DSL 如下:
PUT /hotel { "settings": { "analysis": { "analyzer": { //自定义分析器 "ik_pinyin_analyzer": { "tokenizer": "ik_max_word", //设置分词器为 ik_max_word "filter": [ "pinyin_filter"//设置分词器过滤器为pinyin_filter ] } }, "filter": { //定义分词过滤器 "pinyin_filter": { "type": "pinyin", // 分装pinyin分词过滤器 "keep_first_letter": true, //设置保留拼音的首字母 "keep_full_pinyin": false, //设置保留拼音的全拼 "keep_none_chinese": true //设置不保留中文 } } } }, "mapping": { "properties": { "title": { "type": "text", "analyzer": "ik_pinyin_analyzer" //设置使用自定义分析器 } } } } -
搜索关键词 wy,目的是想搜索 “文雅”相关的酒店, DSL 如下
GET /hotel/_search { "query":{ "match":{ "title":"wy" } } } -
搜索结果有
文雅精选酒店 文雅假日酒店
5. 高亮显示搜索
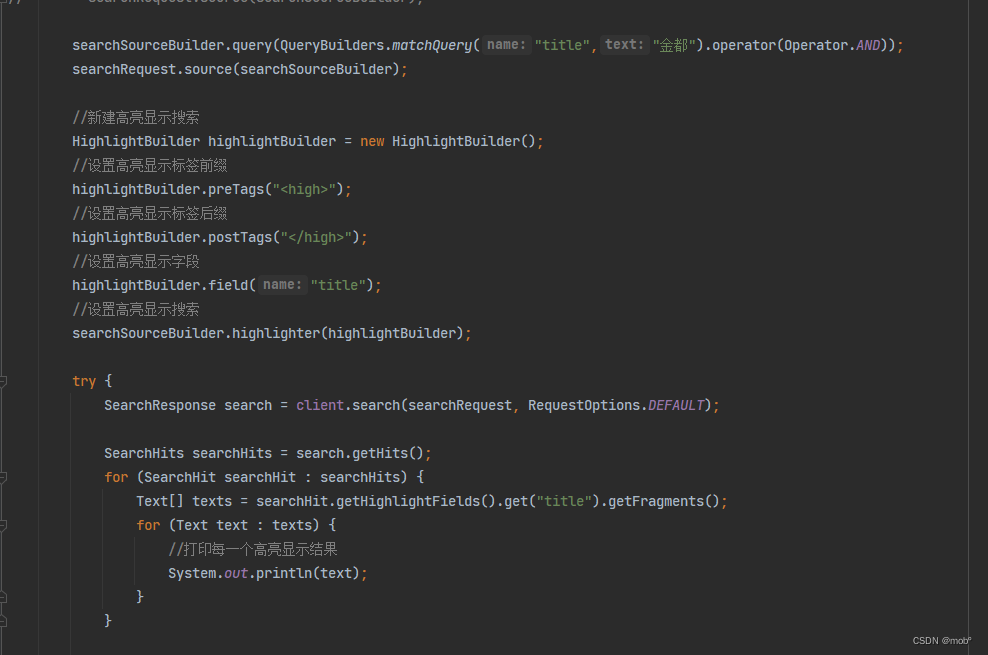
-
使用高亮搜索:
{ "query": { "match": { "title": "金都酒店" } }, "hightlight": { //设置高连搜索的字段 "fields": { "title": {} } } } -
搜索结果
... "highlight":{ "title":{ //使用默认的 HTML 标签 <em></em>标签匹配的词语 } } -
默认使用是< em>< /em>标签,可更改标签为 < high>< /high>
GET /hotel/_search { "query": { "match": { "title": "金都酒店" } }, "hightlight": { "fields": { "title": { //设置默认使用标签<high></high> 标记匹配词语 "pre_tags": "<high", "post_tags": "</high>" } } } } -
选择高亮显示搜索策略
-
plain:精准度比较高的策略,因此它必须将文档全部加载到内存中,并重新进行查询分析,因此在处理大量文档或者大文档是效率比较慢。
-
unified:Lucene Unified Highlighter 来实现,默认情况下,ES 高亮显示的是该策略。
-
fvh:基于向量的高亮搜索策略。更适合在文档中包含大字段的情况(一般超过1MB下使用)。
GET /hotel/_search { "query": { "match": { "title": "金都酒店" } }, "hightlight": { "fields": { "title": { "type": "plain" //设置使用plain匹配策略 } } } }
-
-
Java 客户单对应代码:
6. 拼音纠错
-
可以使用 ES 进行拼写纠错,首先需要搜集一段时间内用户搜索日志中有搜索结果的查询词,然后单独建立一个纠正词索引。当用户进行搜索时,如果在商品索引中没有匹配到结果,则在纠正词索引中进行匹配,如果有匹配结果则给出匹配词,并给出该匹配词对应的商品结果,如果没有匹配结果则告知用户没有搜索到商品。
-
在 ES 中进行纠错匹配是使用 fuzzy_match 搜索,该搜索使用编辑距离和倒排索引相结合的形式完成纠错,倒排索引前面已经介绍过了,什么叫编辑距离呢?词语A经过多次编辑后和词语B相等,编辑的词语就叫做编辑距离,可以这样定义一次编辑,替换一个字符,或删除一个字符,或插入一个字符,或交换两个字符的位置。
-
假设有词语A为“景王”,词语B为“王府井”,词语A进行如下编辑才能等于词语B。
- 将“景王”两个字符交换位置,变为“王景”。
- 在“王景”中间添加“府”,变成“王府景”。
- 将“王府景”中的“景”替换为“井”。
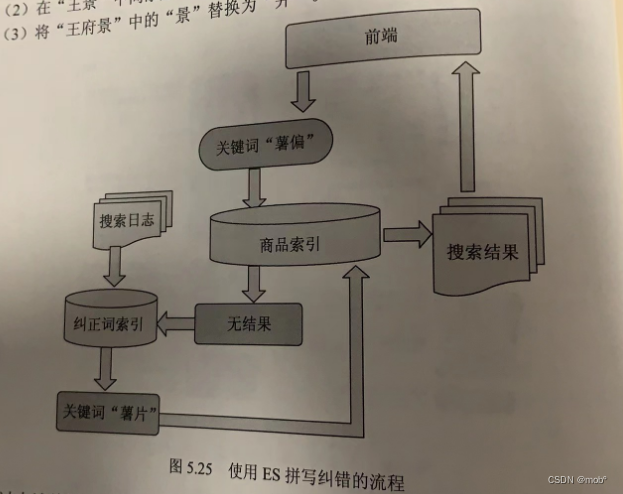
-
经过上述编辑,A和B相等,那么词语A和词语B编辑距离为3。一般情况下,绝大数距离不超过2。
PUT /error_correct { "mappings": { "properties": { "hot_word": { //设置hot_word的类型为text,并指定分析器为ik_max_word "type": "text", "analyzer": "ik_max_word" } } } } -
搜索“王府景”时,指定编辑距离为1的搜索纠错的DSL。
GET /error_correct/_search { "query": { "match": { "hot_word": { "query": "王府景", "operator": "and", "fuzziness": 1 //指定编辑距离为1 } } } } -
搜索结果下
王府景 王府井 成府路 -
因为成府路被切分成 成、府、路,而王府景被切分成王府、景,王府和府编辑距离为1.所以匹配到了。
八、搜索排序
1. 查询时 boost 参数的设置
-
在 ES 中可以通过查询的boost 值对某个查询设定其权重。默认情况下 boost 值为1。但是,设置为2,不到表匹配的文档评分是原来的两倍,而是代表匹配该查询的文档得分相对于其他文档得分被提升了。
-
boost 值的设置只限定在 term 查询和类 match 查询中,其他类型的查询不能使用 boots 设置。当值在 0~1 时表示对权重起负向作用,当该值大于1时表示对权重起正向作用。
-
查询标题中包含 “金都” 或者 “文雅” 的酒店文档的 DSL。
GET /hotel/_search { "query": { "bool": { "should": [ { "match": { "title": { "query": "金都" } } }, { "match": { "title": { "query": "文雅" } } } ] } } } -
默认各个子查询的 boost 值为1,也就是说两个 match 查询是平等的。如果我们想匹配 “金都” 的这些文档排序分值高点,可以设定其 boost 值高一点。
GET /hotel/_search { "query": { "bool": { "should": [ { "match": { "title": { "query": "金都", "boost": 2 } } }, { "match": { "title": { "query": "文雅" } } } ] } } } -
Java 客户单对应代码:
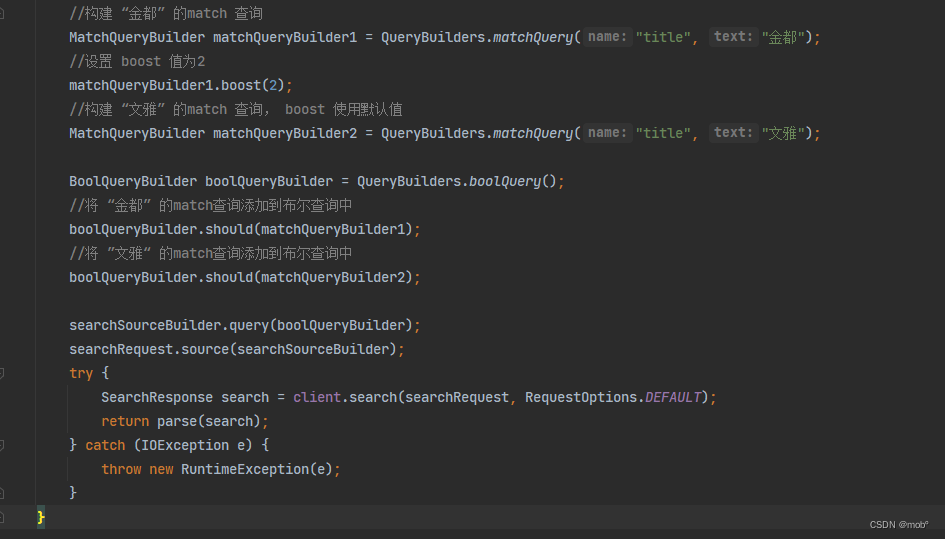
2. boosting 查询
-
虽然使用 boost 值可以对查询的权重进行调整,但是仅限于 term 查询的和类 match 查询,有时需要调整更多类型的查询,如搜索酒店时,需要将放假低于 200 的酒店权重降低,此时可能需要用到 range 查询,但是 range 查询不能使用 boost 参数,这时可以使用 ES 的 boosting 查询进行分装。
-
ES 的 boosting 查询分为两部分:一部分是 positive 查询,代表正向查询,另一部分是 negative 查询,代表负向查询。negative_boost 参数设置负向查询的权重系数,该值范围为 0~1,最终文档得分:正向匹配值 + 负向匹配值 * negative_boost。
-
对房价低于200元的酒店进行降权处理 DSL:
GET /hotel/_search { "query": { "boosting": { "positive": { "match": { "title": { "query": "金都" } } }, "negative": { //设置负面查询 "range": { "price": { "ite": 200 } } }, "negative_boost": 0.2 //设置降低的权重值 } } } -
在以上查询中,使用布尔查询将 “房价低于200”和 “满房状态“ 的酒店分装到了一个布尔查询中然后放入 negative 查询中:
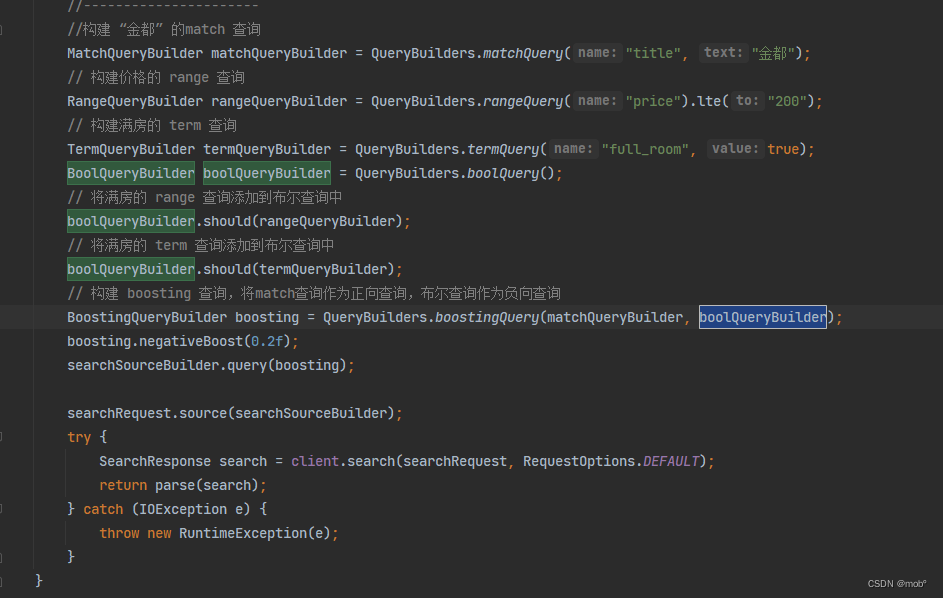
GET /hotel/_search { "query": { "boosting": { "positive": { "match": { "title": { "query": "金都" } } }, "negative": { //扩展 negative 查询,增加更多条件 "bool": { "should": [ { "range": { "price": { "lte": 200 } } }, { "term": { "full_room": { "value": "true" } } } ] } }, "negative_boost": 0.2 //设置降低的权重值 } } } -
Java 客户单对应代码:
九、聚合
- 当用户使用搜索引擎完成搜索之后,在展示结果中需要进一步的筛选,而筛选的维度需要根据当前的搜索结果进行汇总,这就用到了聚合技术。
- ES 支持丰富的集合操作,不仅可以使用聚合功能对文档进行技术,还可以计算文档平均值、最大值和最小值等。ES 还提供了桶聚合的功能,以便于对多维度数据进行聚合。
1.聚合指标
-
时用 avg 字句进行平均值的聚合时。如果我们不需要返回具体的文档信息,可以将返回的文档个数设置为0。这样既可以让结果看起来更整洁,有可以提高查询速度。DSL 如下:
GET /hotel/_search { "size": 0, "aggs": { "my_agg": { // 聚合名称 "avg": { "field": "price" //计算文档的平均价格 } } } } -
返回结果如下:索引中5个文档全部命中。my_agg 是聚合的名称,value值对应具体聚合结果,即酒店的平均价格。
{ ... "hits": { "total": { "value": 5, "relation": "eq" }, "max_score": null, "hits": [] }, "aggregations": { "my_agg": { "value": 514 } } } -
与平均值类似、最大值、最小值以及加和值分别使用max、min和sum字句进行聚合,这里不在赘述。
-
平均值的Java客户端代码:
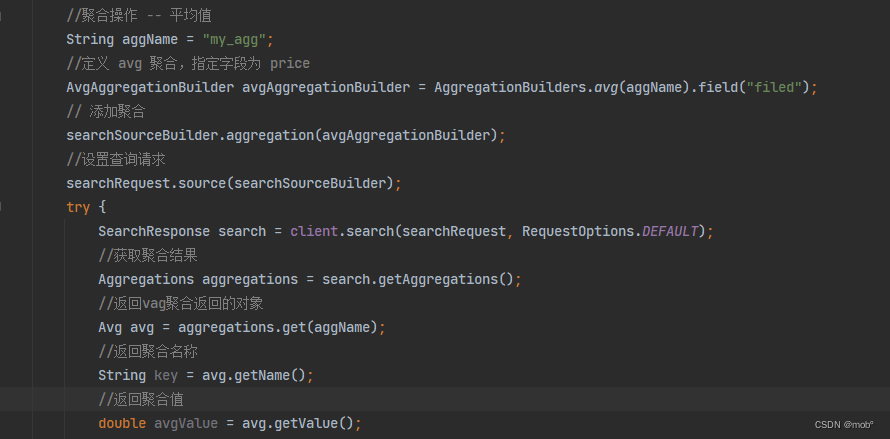
-
为了避免多次请求,ES 还提供了 stats 聚合。stats 聚合可以将对应字段的最大值、最小值、平均值及加和值一起计算并返回计算结果。DSL 如下:
GET /hotel/_search { "size": 0, "aggs": { "my_agg": { "stats": { "field": "price" } } } } -
查询结果如下:
{ ... "hits": { "total": { "value": 5, "relation": "eq" }, "max_score": null, "bits": [] }, "aggregations": { "my_agg": { "count": 4, //文档数量 "min": 200.0, //聚合的价格最小值 "max": 800.0, //聚合的价格最大值 "avg": 514.0, //聚合的价格平均值 "sum": 2056.0 //聚合的加和值 } } } -
对应的 Java客户端代码:
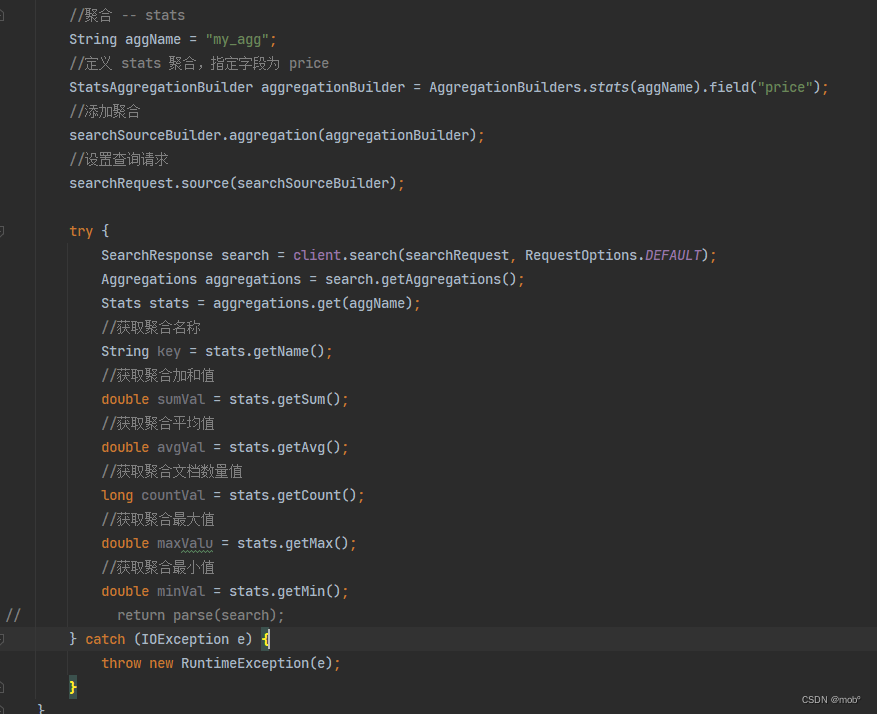
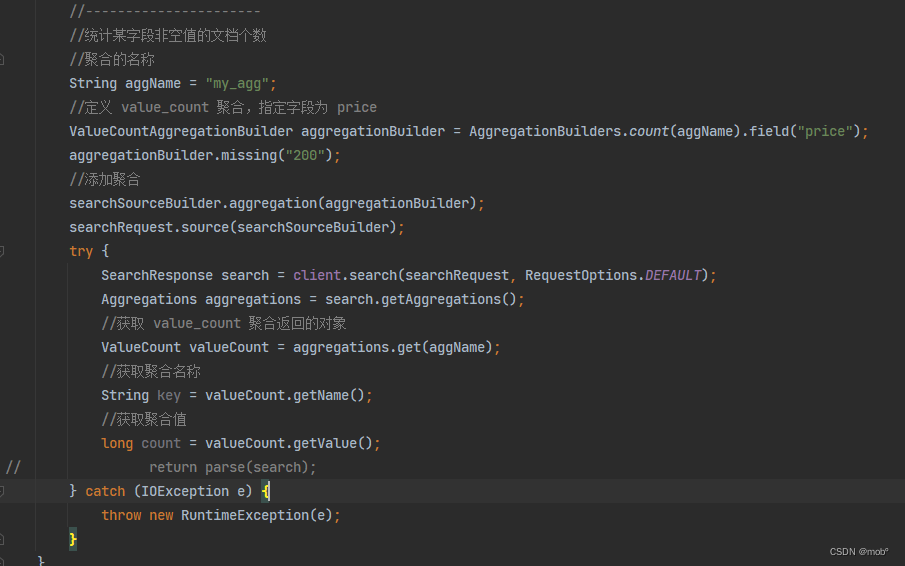
-
value_count 聚合,该聚合用于统计字段非空值的个数(比如有些文档某字段缺失)。下面的DSL 使用value_count 聚合统计了price字段中非空值的个数。
/ GET /hotel/_search { "size": 0, "aggs": { "my_agg": { "value_count": { //统计price字段中非空值的个数 "field": "price" } } } } -
返回结果:
{ "hits": { "total": { "value": 5, "relation": "eq" }, "max_score": null, "hits": [] }, "aggregations": { "my_agg": { //price 字段中非空值的个数 "value": 4 } } } -
Java 客户端代码:
-
值得注意的是,如果判断的字段是数组类型,则 value_count 统计的是符合条件的所有文档中该字段数组中元素个数的总和,而不是数组的个数总和。
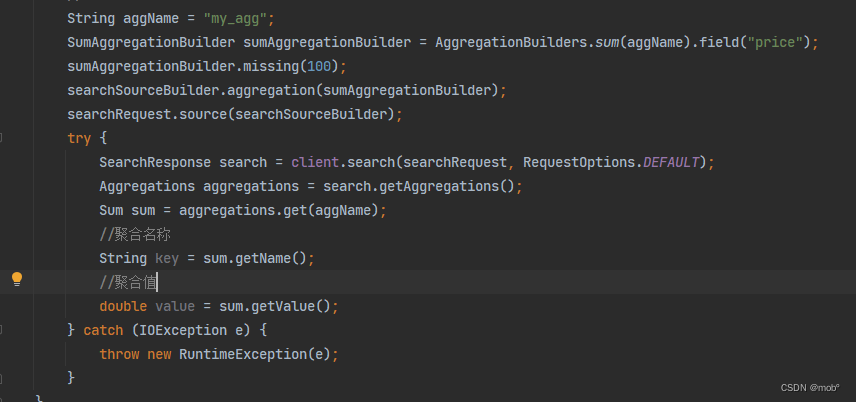
-
如果在进行聚合操作时,需要对空值字段的数据进行默认值填充,可是使用如下查询:
GET /hotel/_search { "size": 0, "aggs": { "my_agg": { "sum": { "field": "price", "missing": 100 //计算加和值时将price字段中的空值用100代替 } } } } -
Java 客户端代码:
2. 桶聚合
-
有时需要根据某些维度进行聚合,比如更具酒店是否满房、按照城市、标签等信息进行聚合。按一个维度对文档进行聚合就是单维度桶聚合。按照多个维度进行聚合就是多维度桶嵌套聚合。
-
在桶聚合时,聚合的桶也需要匹配,匹配的方式有 terms,filter 和 ranges 等。
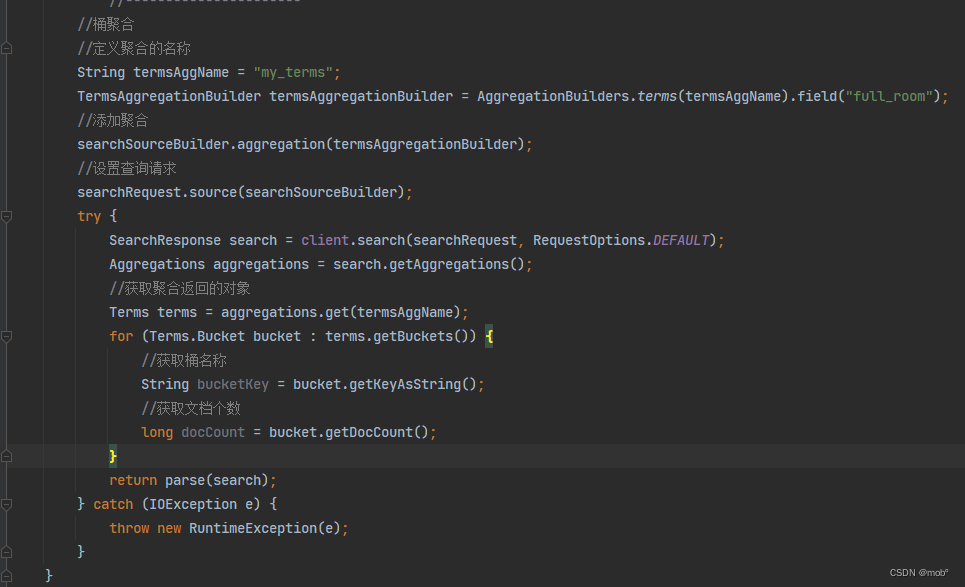
-
按照城市进行聚合的DSL
GET /hotel/_search { "size": 0, "aggs": { "my_agg": { "terms": { "field": "city" } } } } -
Java 客户端代码:
-
range 的桶聚合:DSL
GET /hotel/_search { "size": 0, "aggs": { "my_agg": { "range": { "field": "price", "ranges": [ //多个范围桶 { "to": 200 //不指定 from ,默认 from 为0 }, { "from": 200, "to": 500 }, { "from": 500 //不指定to,默认to为该字段最大值 } ] } } } } -
Java 客户端代码:
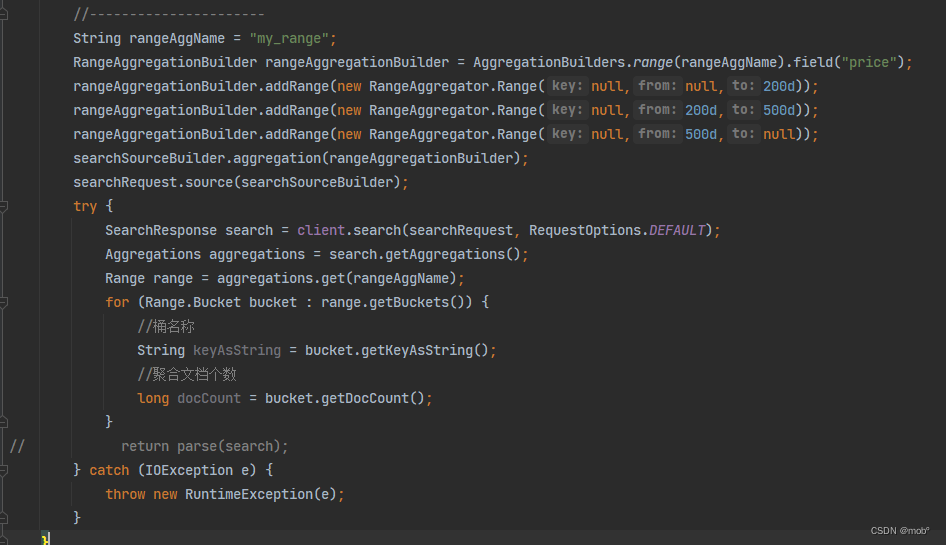
-
有时还需要对单维度桶指定聚合指标,聚合指标单独使用子 aggs 进行封装,该 aggs 子句的使用方式和上一节介绍的聚合指标相同。按照 城市维度进行聚合,统计各个城市的平均酒店价格:
GET /hotel/_search { "size": 0, "aggs": { "my_agg": { //单维度聚合名称 "terms": { //定义单维度桶 "field": "city" }, "aggs": { //用于封装单维度桶下的聚合指标 "my_sum": { //聚合指标名称 "sum": { //对price字段进行加和 "field": "price", "missing": 200 } } } } } } -
Java 客户端代码:
-
有时候我们需要多个维度的嵌套聚合,ES 支持嵌套聚合,可是使用 aggs 字句进行子桶的继续嵌套,指标放在最里面的子桶内,DSL 如下:
GET /hotel/_search { "size": 0, "aggs": { "group_city": { //多维度桶名称 "terms": { "field": "city" }, "aggs": { //单维度桶 "group_fulll_room": { "terms": { "field": "full_room" }, "aggs": { //聚合指标 "my_sum": { "avg": { "field": "price", "missing": 200 } } } } } } } -
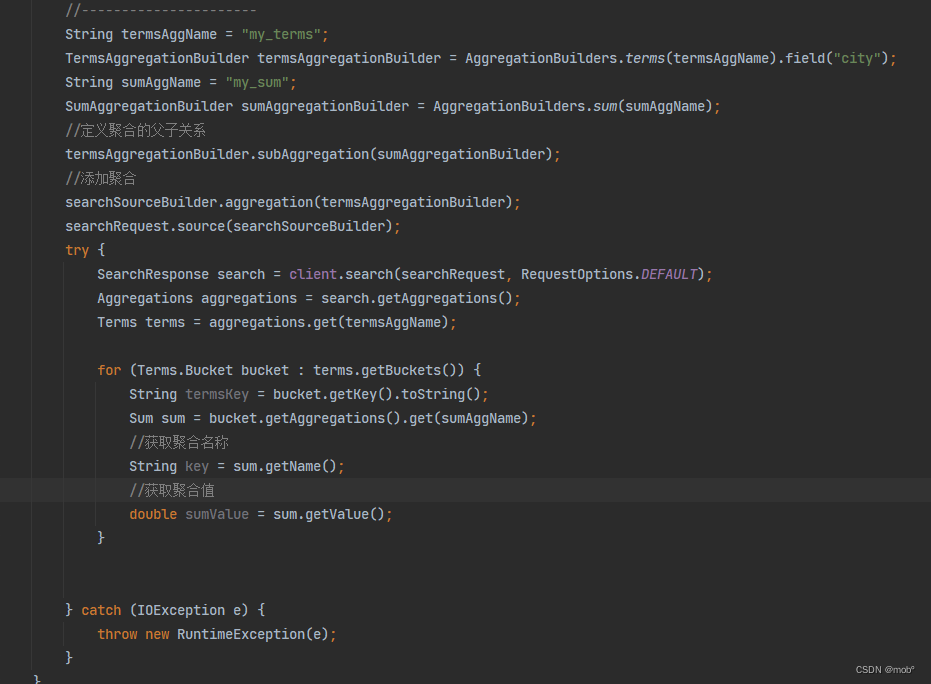
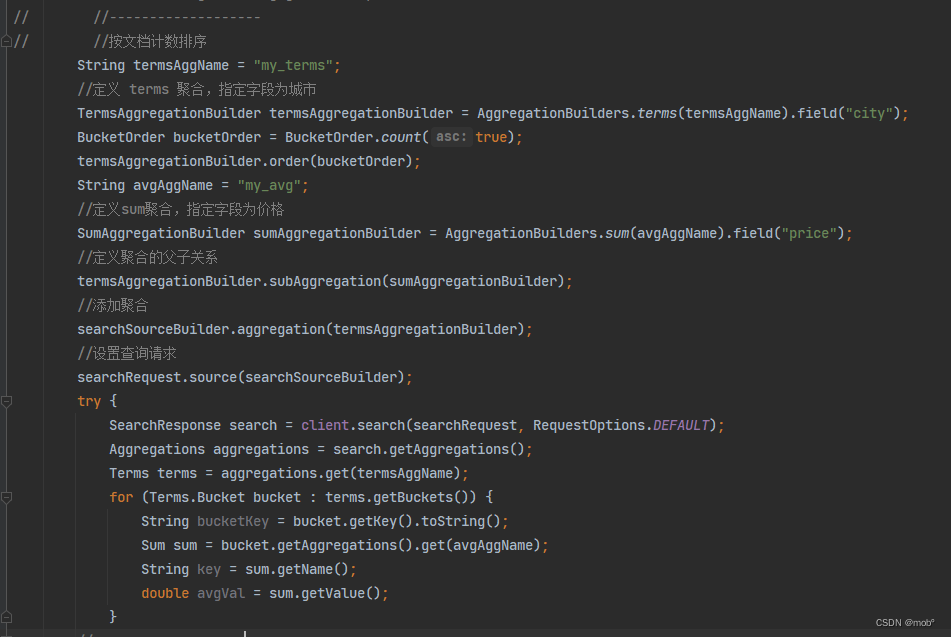
Java 客户端代码:
//多维度桶嵌套聚合 //按城市聚合的名称 String aggNameCity = "my_terms_city"; //定义 terms 聚合,指定字段为城市 TermsAggregationBuilder termsAggCity = AggregationBuilders.terms(aggNameCity).field("city"); //按满房状态的聚合的名称 String aggNameFullRoom = "my_terms_full_room"; //定义 terms 聚合,指定字段为满房状态 TermsAggregationBuilder termsArrFullRoom = AggregationBuilders.terms(aggNameFullRoom).field("full_room"); //sum 聚合的名称 String sumAggName = "my_sum"; //定义sum 聚合,指定字段为价格 SumAggregationBuilder sumAgg = AggregationBuilders.sum(sumAggName).field("price"); //定义聚合的父子关系 termsArrFullRoom.subAggregation(sumAgg); termsAggCity.subAggregation(termsArrFullRoom); //添加聚合 searchSourceBuilder.aggregation(termsArrFullRoom); searchRequest.source(searchSourceBuilder); try { SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT); Aggregations aggregations = search.getAggregations(); Terms terms = aggregations.get(aggNameCity); //遍历第一层 bucket for (Terms.Bucket bucket : terms.getBuckets()) { //获取第一层 bucket 名称 String termsKeyCity = bucket.getKey().toString(); Terms termsFullRom = bucket.getAggregations().get(aggNameCity); //遍历第二层bucket for (Terms.Bucket termsFullRomBucket : termsFullRom.getBuckets()) { //获取第二层 bucket 名称 String termsKeyFullRoom = termsFullRomBucket.getKeyAsString(); //获取聚合指标 Sum sum = termsFullRomBucket.getAggregations().get(sumAggName); //获取聚合指标名称 String key = sum.getName(); //获取聚合指标值 double sumVal = sum.getValue(); } } } catch (IOException e) { throw new RuntimeException(e); } -
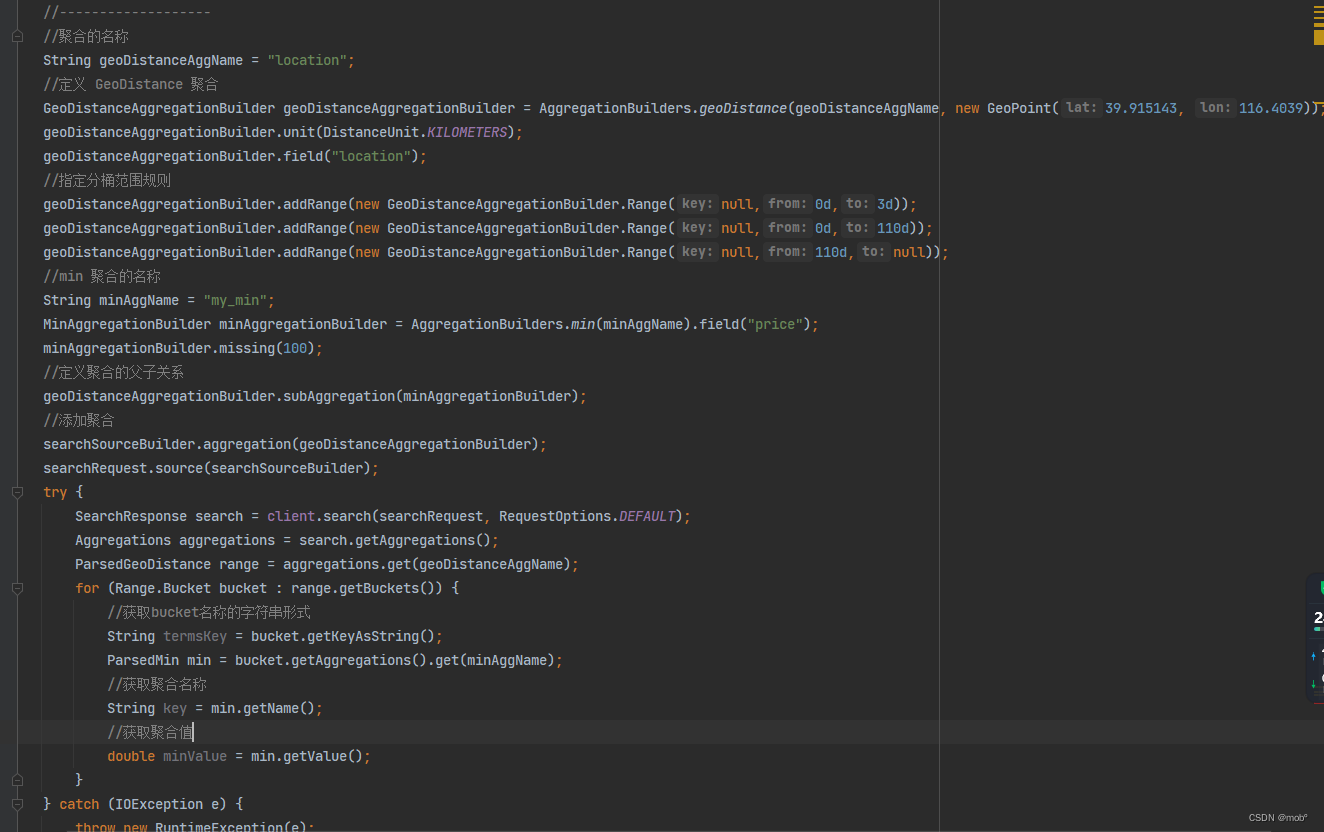
地理距离聚合。用户可以使用 geo_distance 聚合进行地理距离聚合,通过 field 参数来设置距离计算的字段,可以在 origin字句中设定距离的原点,通过 unit 参数来设置距离的单位,可以选择 mi 和 km,分别表示米和千米。ranges 字句用来对距离进行阶段性的分组,该字句和使用方式和前面介绍的range 聚合类似。DSL使用 geo_distance 聚合进行地理距离聚合的方法。
GET /hotel/_search { "size": 0, "aggs": { "my_agg": { "geo_distance": { "field": "location", //指定聚合的中心点经纬度 "origin": { "lat": 39.915143, "lon": 116.4039 }, "unit": "km", //指定聚合时的距离计量单位 "ranges": [ //指定每一个聚合桶的距离范围 { "to": 3 }, { "from": 3, "to": 10 }, { "from": 10 } ] } } } } -
在上述的 DSL 中,给定一个地理位置,此处使用 ranges 聚合对距离该位置的酒店划分了3个分组的桶;第一个桶为3km范围内,第二个桶为3~10km;第3个桶为大于等于10km。
-
也可以指定聚合指标进行地理距离聚合,下面的DSL将按照bucket 分桶聚合酒店的最低价格:
GET /hotel/_search { "size": 0, "aggs": { "my_agg": { "geo_distance": { "field": "location", //指定聚合的中心点经纬度 "origin": { "lat": 39.915143, "lon": 116.4039 }, "unit": "km", //指定聚合时的距离计量单位 "ranges": [ //指定每一个聚合桶的距离范围 { "to": 3 }, { "from": 3, "to": 10 }, { "from": 10 } ] }, "aggs": { "my_min": { //指定聚合指标 "min": { //聚合指标名称 "field": "price", //计算每个桶内price字段的最小值 "missing": 100 } } } } } } -
Java 客户端代码:
3. 聚合方式
-
直接聚合:指的是聚合时的DSL没有query子句,是直接对索引内的所有文档进行聚合。前面介绍的都属于直接聚合。
-
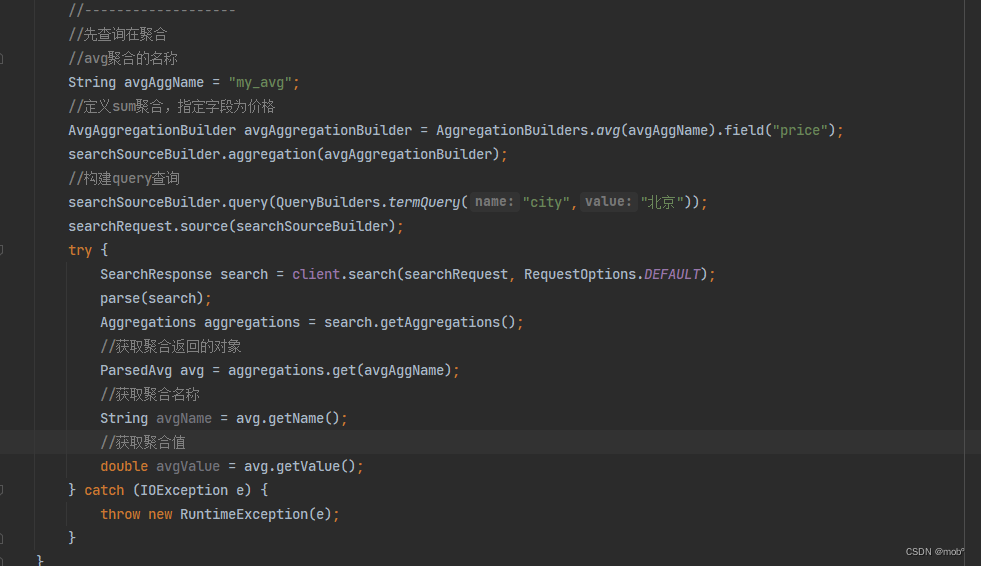
与直接聚合相对应,这种查询方式需要增加query子句,query子句和普通的query查询没有区别,参加聚合的文档必须匹配query查询。DSL 如下:
{ "size": 0, "query": { //指定查询query逻辑 "term": { "city": { "value": "北京" } } }, "aggs": { //指定聚合逻辑 "my_agg": { "avg": { "field": "price" } } } } -
Java 客户端代码如下:
-
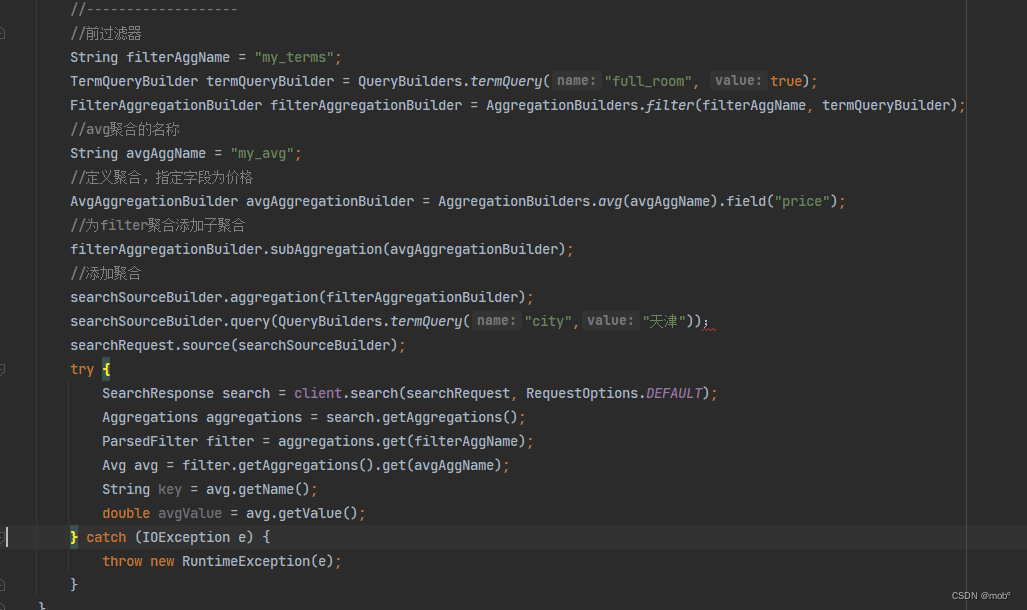
前过滤器:有时需要对聚合条件进一步地过滤,但是又不能影响当前的查询条件。例如用户进行酒店搜索时的搜索条件是天津的酒店,但是聚合时需要将非满房的酒店平均价格进行聚合并展示给用户。此时不能变更用户的查询条件,需要在聚合子句中添加过滤条件。下面的DSL展示了在聚合时使用过滤条件的用法:
GET /hotel/_search { "size": 0, "query": { //指定查询query逻辑 "term": { "city": { "value": "北京" } } }, "aggs": { "my_agg": { "filter": { //指定过滤器逻辑 "term": { "full_room": false } }, "aggs": { //指定聚合逻辑 "my_avg": { "avg": { "field": "price" } } } } } } -
返回结果:
{
...
"hits": {
"total": {
"value": 2,
"relation": "rq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"my_agg": {
"doc_count": 1, //只有文档004没有被过滤
"my_avg": {
"value": 500.0
}
}
}
}
-
通过上述结果可以知道,满足查询条件的文档个数为2,命中的文档为004和005,但是在聚合时要求匹配非满足的酒店,只有文档004满足聚合条件,因此酒店的平均值为文档004的price字段值。
-
Java客户端代码:
-
后过滤器:根据条件进行数据查询,但是聚合的结果集不受影响。例如在酒店搜索场景中,用户的查询词为“假日”此时应该展现标题中带有“假日”的酒店。但是在该页面中,如果还希望给用户呈现出全国各个城市的酒店的平均价格,这时可以使用 ES 提供的后过滤器功能。该过滤器是现在查询和聚合之后进行过滤的,因此它的过滤条件对聚合没有影响。DSL 如下:
GET /hotel/_search { "size": 0, "query": { "match": { "title": "假日" } }, "post_filter": { "term": { "city": "北京" } }, "aggs": { "my_agg": { "avg": { "field": "price", "missing": 200 } } } } -
在上面的查询中,使用 match 匹配title包含“假日”的酒店,并且查询出这些酒店的平均价格,最后使用 post_filter 设置后过滤器的条件,将酒店的诚实锁定为 "北京”。
-
返回结果:
... { "hits": { "total": { "value": 3, "relation": "eq" }, "max_score": null, "hits": [] }, "aggregations": { "my_agg": { //聚合时酒店的诚实锁定为“北京” "value": 364.0 } } } -
更具查询结果可知,match 查询命中了4个文档,对这4个文档的price字段取平均值为364,最后通过 post_filter 将其中的文档004过滤掉,因此hits子句中的total数量为3.
-
Java客户端代码为:

4. 聚合排序
- ES 提供的 sort 字句进行自定义排序,有多种排序方式供用户选择;可以按照聚合后的文档计数的大小进行排序;可以按照聚合后的某个指标进行排序;还可以按照每个组的名称进行排序。下面将介绍3中排序方式。
1. 按文档计数排序
-
按照每个组聚合后的文档数量进行排序的场景。此时可以使用_count 来引用每组聚合的文档计数排序排序。
-
按照城市的酒店平均价格进行聚合,并按照聚合后的文档计数进行升序排序的请求。
GET /hotel/_search { "size": 0, "aggs": { "group_city": { "terms": { "field": "city", "order": { //按照文档计数进行升序排列 "_count": "asc" } }, "aggs": { "my_avg": { "avg": { //使用价格平均值作为聚合指标 "field": "price", "missing": 200 } } } } } } -
Java 客户端代码:
2. 按聚合指标排序
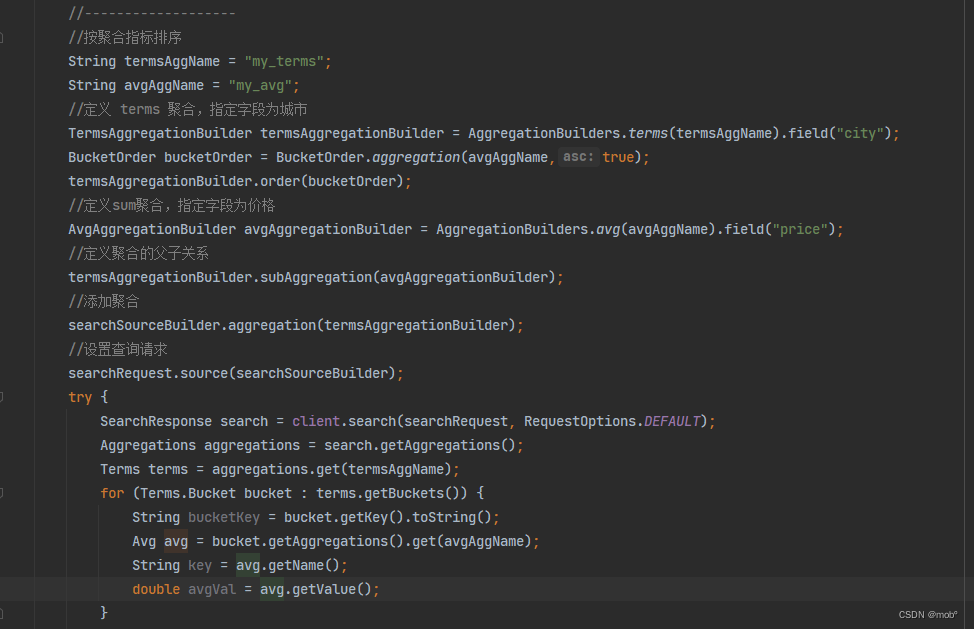
-
按照每个组聚合后的指标进行排序。比如按照城市的酒店平均价格进行聚合,并按照聚合后的平均价格进行升序排序的请求。
GET /hotel/_search { "size": 0, "aggs": { "group_city": { "terms": { "field": "city", "order": { //按照文档计数进行升序排列 "my_avg": "asc" } }, "aggs": { "my_avg": { "avg": { //使用价格平均值作为聚合指标 "field": "price", "missing": 200 } } } } } } -
Java 客户端代码:
3. 按分组 key 排序
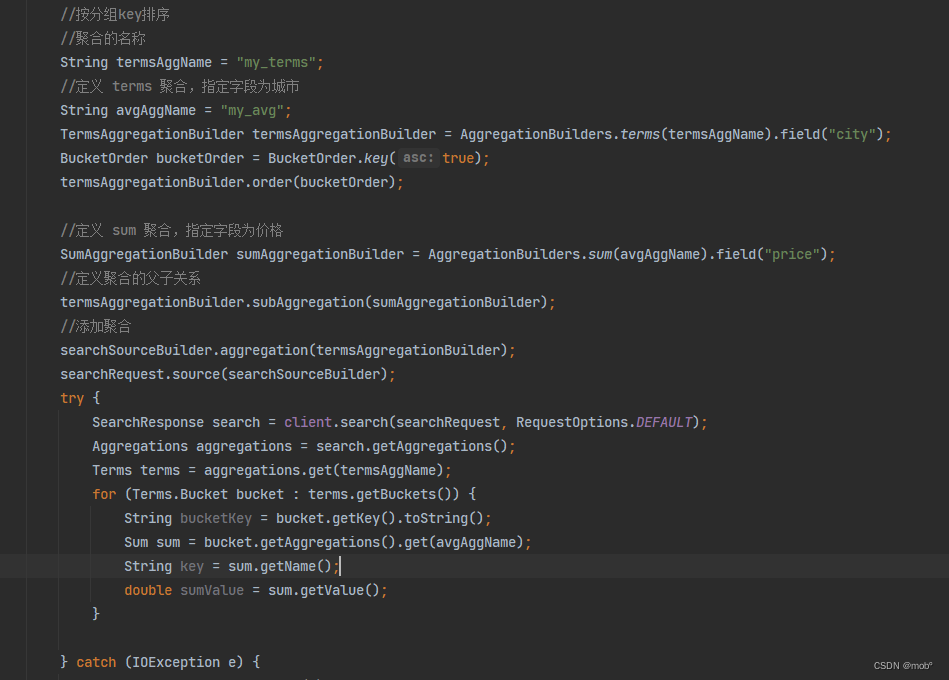
-
按照每个分组的组名称排序的场景。此时可以使用_key来引用分组名称。比如:按照城市的酒店平均价格进行聚合,并按照聚合后的分组名称进行升序排序的请求:
GET /hotel/_search { "size": 0, "aggs": { "group_city": { "terms": { "field": "city", "order": { //按照文档计数进行升序排列 "_key": "asc" } }, "aggs": { "my_avg": { "avg": { //使用价格平均值作为聚合指标 "field": "price", "missing": 200 } } } } } } -
Java 客户端代码:
4. 聚合分页
- ES 提供的 Top hits 聚合和 Collapse可以完成分页。
1. Top hits 聚合
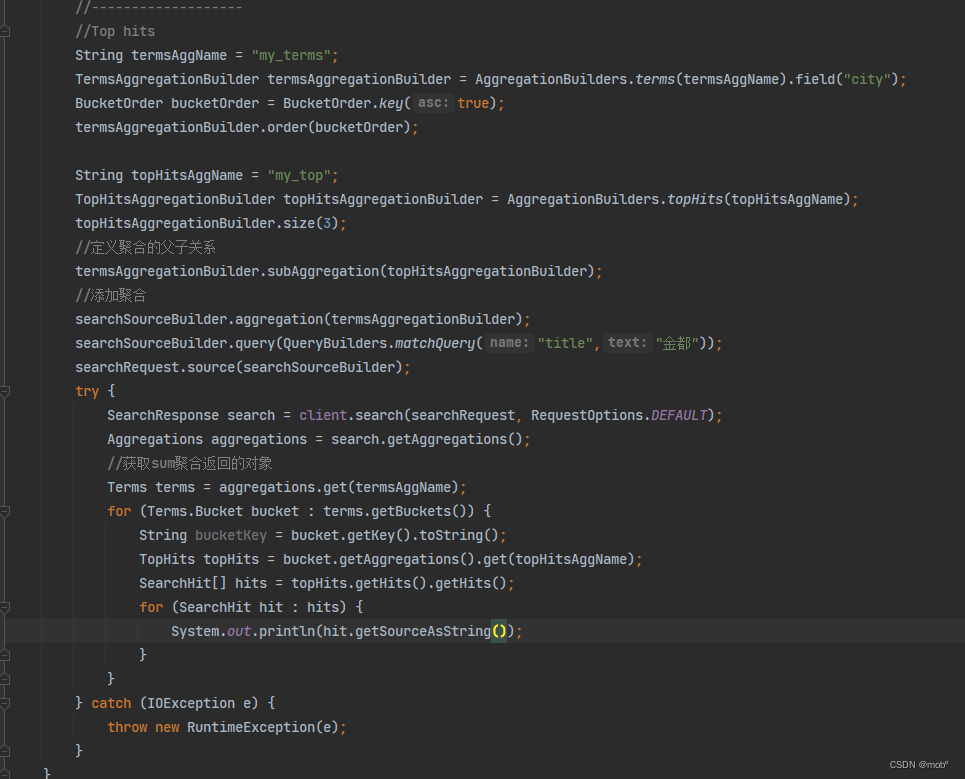
-
Top hits 聚合指的是聚合时在每个分组内部按照某个规则选出前 N 个文档进行展示。例如,搜索“金都”时,如果希望按照城市分组,每组 按照匹配分数降序展示3条文档数据,DSL 如下:
{ "size": 0, "query": { "match": { "title": "金都" } }, "aggs": { "group_city": { "terms": { //按照城市进行桶聚合 "field": "city" }, "aggs": { "my_avg": { "top_hits": { //指定返回每个桶的前3个文档 "size": 3 } } } } } } -
Java 客户端代码:
2. Collapse 聚合
-
当在索引中有大量数据命中时,Top hits 聚合存在效率问题,并且需要用户自行排序。针对上述问题。ES 推出了 Collapse 聚合,即用户可以在 collapse 子句中指定分组字段,匹配 query 的结果按照该字段进行分组,并且每个分组中按照得分高低展示组内的文档。当用户在 query 子句外指定 from 和 size 时,将作用在 Collapse 聚合之后,即此时的分页是作用在分组之后的,以下DSL 展示了 Collapse 聚合的用法。
GET /hotel/_search { "from": 0, //指定分页的起始位置 "size": 5, //指定每页返回的数量 "query": { //指定查询的query逻辑 "match": { "title": "金都" } }, "collapse": { //指定按照城市进行Collapse聚合 "field": "city" } } -
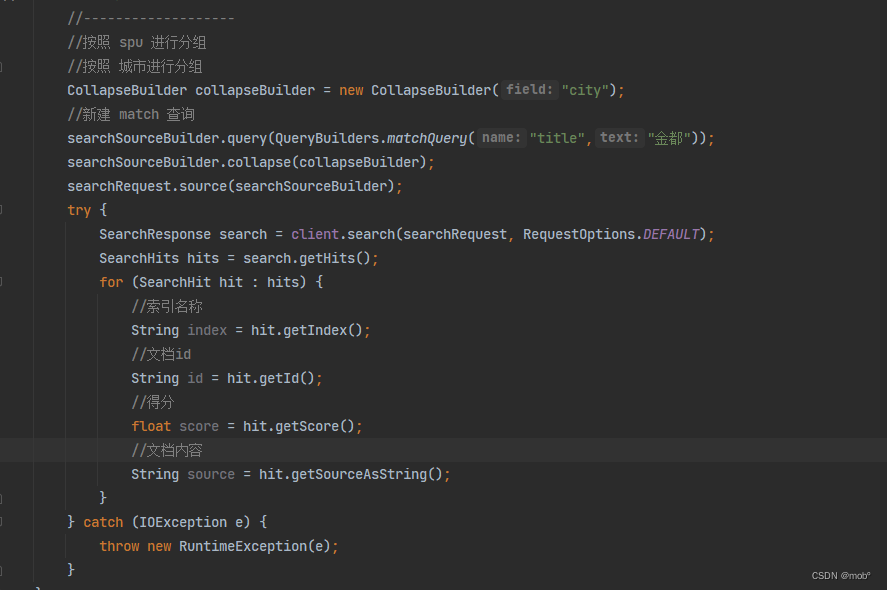
Java客户端代码:















 1604
1604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









