







redis非关系型数据库
特点
Redis为非关系型的数据库的一种
- 不支持SQL语法
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。Redis存储结构主要为K:V形式, 跟关系型数据库中关系表完全不同,同时还提供list,set,zset,hash等数据结构的存储。Redis支持数据的备份,即master-slave模式的数据备份。
应用场景
- 用来做缓存(
ehcache/memcached) ——redis的所有数据是放在内存中的(内存型数据库) - 可以在某些特定应用场景下替代传统数据库——比如社交类的应用
- session共享、购物车 等
数据结构
redis是key-value的数据结构,每条数据都是⼀个键值对, 键的类型是字符串并且不能重复
redis数据库没有名称,默认有16个,通过0 - 15来标识,连接redis默认选择第一个数据库
键命令(公有命令)
-
查看键
keys *查看该数据库中所有的键keys a*查看该数据库中键名中包含a的键- 注意:获取的结果为键名而非键对应的值
-
删除键
del 键名1, 键名2删除指定键(包括键中的值) -
是否存在
exists 键名判断指定键是否存在,存在返回1,不存在返回0 -
查看键的类型
type 键名查看键对应值的的类型 -
为已存在的键设置过期时间
expire 键名 时间时间单位为秒,例:expire a1 3设置键a1的过期时间为3秒
没有指定过期时间的键,会⼀直存在,直到使⽤DEL移除 -
查看key的过期时间
ttl 键名 -
过期策略:惰性过期和定期过期
-
惰性过期
只有当访问一个key时,才会判断该key是否已过期,过期则清除。节省CPU资源,占用大量内存 -
定期过期
定期随机扫描数据库expires字典中一定数量的key,并清除其中已过期的key
通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果
-
字符串string
Redis中最为基础的数据存储类型- 在
Redis中是二进制保存的,即可以接受任何格式的数据,如JPEG图像数据或Json对象描述信息等 - 在
Redis中字符串类型的Value最多可以容纳的数据长度是512M
增
| 命令 | 作用 | 例子 | 含义 |
|---|---|---|---|
set 新键名 值 | 新增一条字符串数据 | set name "小明" | 储存一条name:"小明"的字符串数据 |
mset 键1 值1 键2 值2 ... | 新增多条字符串数据 | mset name "小明" age 18 | 储存两条name:"小明", age:18数据 |
setex 键 时间 值 | 新增一条数据并设过期时间 | setex name 10 "小明" | 储存一条数据并设置过期时间为10秒 |
注意:使用set 键名 值新增数据时若设置的键不存在则为添加,若存在则为修改
删
使用redis数据共有的删除方法:del 键名
改
| 命令 | 作用 | 例子 | 含义 |
|---|---|---|---|
set 指定键名 值 | 修改指定键的字符串数据 | set name "大明" | 将name键储存的"小明"字符串数据修改为"大明" |
append 指定键 增加值 | 为指定的键追加数据 | append name "亮" | 在原储存的字符串数据中追加数据(name:"大明亮") |
获取(查)
| 命令 | 作用 | 例子 | 含义 |
|---|---|---|---|
get 指定键 | 查看指定的键中的数据 | get name | 获取数据库中储存的键名为name的字符串数据("大明亮") |
mget 指定键1 键2 | 查看多个指定键中的数据 | mget name age | 获取数据库中键名为name和age的数据("大明亮"和18) |
注意: 根据键获取值,如果 不存在此键则返回nil 表示空
哈希hash
hash⽤于存储对象,对象的结构为属性:值,值的类型为string
增
| 命令 | 作用 | 例子 | 含义 |
|---|---|---|---|
hset 键名 新属性 值 | 新增一条单属性hash | hset stu name "小明" | 属性名为"name",值为"小明" |
hmset 键名 属性 值 属性 值 ... | 新增一条多属性hash | hmset stu sex "男" age 18 | 属性"sex" "age"值"男" "18" |
注意: 增加属性时, 若键不存在则会新建一条hash数据, 若存在并且类型为hash则表示追加属性, 若存在但不是hash类型则会报错
改
| 命令 | 作用 | 例子 | 含义 |
|---|---|---|---|
hset 键名 属性 值 | 修改指定键和属性中的值 | hset stu name "大明" | 将原属性(name:"小明")修改为name:"大明" |
注意: 使用hset 键名 属性名 值时, 若hash中存在指定属性为修改原属性值,不存在则为添加新属性
删
-
共有删除方法(
del 键名), 删除整个hash键(包括键名、所有属性和值) -
删除属性(
hdel 键名 属性1 属性2 ...),删除指定属性及其对应值
获取(查)
| 命令 | 作用 | 例子 | 含义 |
|---|---|---|---|
hget 键名 属性 | 查看指定的键中属性对应的值 | hget stu name | 获取stu键中name属性的值("大明") |
hmget 键名 属性 属性 | 查看指定键中多个属性对应的值 | hmget stu name age | 获取stu键中name和age属性的值 |
hkeys 键名 | 查看指定键中的所有属性名 | hkeys stu | 结果(一项一行):"name" "sex" "age" |
hvals 键名 | 查看指定键中的所有属性其值 | hvals stu | 结果:"大明" "男" "18" 三行显示 |
hgetall 键名 | 查看指定键中的所有属性及其值 | hgetall stu | 结果:"name" "大明" "sex" "男" … |
列表list
列表的元素类型为string
增
| 命令 | 作用 | 例子 | 备注 |
|---|---|---|---|
lpush 键名 值1 值2 ... | 命名储存一组字符串数据 | lpush a1 a b c | 数据从左侧插入,即插入顺序c b a,键名a1 |
rpush 键名 值1 值2 ... | 命名储存一组字符串数据 | lpush a1 0 1 | 数据从右侧插入,即插入顺序0 1,键名a1 |
注意:若键名不存在则表示新建;存在则表示在末尾添加
在指定元素的前或后插⼊新元素
格式:linsert 键名 before/after 指定元素 新元素
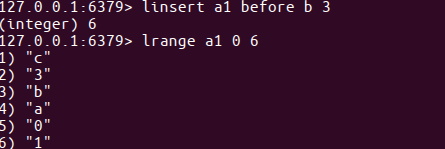
查询
返回列表⾥指定范围内的元素
格式:lrange 键名 开始索引 结束索引
- 索引从左侧开始,第⼀个元素为0
- 索引可以是负数,表示尾部开始计数,如-1表示最后⼀个元素
改
修改 指定索引位置 的元素值
格式:lset 键名 索引 新值
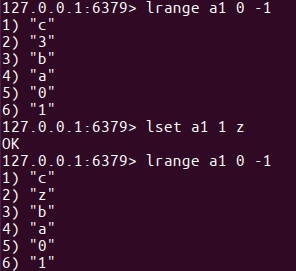
截取修剪
列表只保留指定区间内的元素(包含上下标元素),不在指定区间之内的元素都将被删除
格式:ltrim 键名 开始索引 结束索引
- 索引从左侧开始,第⼀个元素为0
- 索引可以是负数,表示尾部开始计数,如-1表示最后⼀个元素
无序集合set
- 元素为
string类型 - 元素具有唯⼀性,不重复
-
增
格式:sadd 键名 元素1 元素2 ...
例:sadd a3 张 王 李向键a3的集合中添加元素 张、王、李
键名不存在为新建,存在为添加 -
删除
删除指定元素
格式:srem 键名 指定元素
例:srem a3 李删除键a3的集合中元素李 -
获取
返回所有的元素
格式:smembers 键名
例:smembers a3获取键a3的集合中所有元素
有序集合zset
- 元素为
string类型 - 元素具有唯⼀性,不重复
- 每个元素都会关联⼀个
double类型的score,表示权重,通过权重将元素从⼩到⼤排序 - 没有修改操作
-
增加
格式:zadd 键名 权重1 值1 权重2 值2 ...
例1:zadd a4 4 一 5 二 6 三 3 四向键a4的集合中添加元素一、二、三、四,权重分别为4、5、6、3 -
删除
- 删除指定元素
格式:zrem 键名 值1 值2 ...
例:zrem a4 三删除集合a4中元素三 - 删除权重在指定范围的元素
格式:zremrangebyscore 键名 最小权重 最大权重
例:zremrangebyscore a4 5 6删除集合a4中权重在5、6之间的元素
- 删除指定元素
-
查询(获取)
-
返回指定元素的权重值
格式:zscore 键名 指定元素
例:zscore a4 三获取键a4的集合中元素三的权重 -
返回指定范围内的元素
格式:zrange 键名 元素开始索引 结束索引
索引从左侧开始,第⼀个元素为0
索引可以是负数,表示尾部开始计数,如-1表示最后⼀个元素
例:zrange a4 0 -1获取键a4的集合中所有元素 -
返回 权重值 在
最大权重和最小权重之间的元素
格式:zrangebyscore 键名 最小权重 最大权重包含最大最小权重
例:zrangebyscore a4 5 6获取键a4的集合中权重值在5和6之间的成员
-
事务
- Redis提供了一定的事务支持
- 保证一组操作原子执行不被打断
- 执行中出现错误,事务不会停止 也 不能回滚,仅记录错误信息并继续执行后面的指令
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set c 300
QUEUED
127.0.0.1:6379> hgetall a
QUEUED
127.0.0.1:6379> set d 400
QUEUED
127.0.0.1:6379> get d
QUEUED
127.0.0.1:6379> exec # 执行事务
1) OK
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
3) OK
4) "400"
127.0.0.1:6379>
使用multi开启事务后,操作的指令并未立即执行,而是被redis记录在队列中,等待一起执行。当执行exec命令后,开始执行事务指令,最终得到每条指令的结果
# watch监视:构建的redis事务在执行时依赖某些值,可以使用watch对数据值进行监视。
127.0.0.1:6379> set stock 100
OK
127.0.0.1:6379> watch stock
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incrby stock -1
QUEUED
127.0.0.1:6379> incr sales
QUEUED
127.0.0.1:6379> exec # 事务exec 执行前被监视的stock值未变化,事务正确执行。
1) (integer) 99
2) (integer) 1
# 若此时在另一个客户端修改stock的值,执行
127.0.0.1:6379> incrby stock -2
(integer) 98
# 当第一个客户端再执行exec时
127.0.0.1:6379> exec
(nil)
# 表明事务需要监视的stock值发生了变化,事务不能执行了
注意:Redis Cluster 集群不支持事务
持久化
redis可以将数据写入到磁盘中,在停机或宕机后,再次启动redis时,将磁盘中的备份数据加载到内存中恢复使用。这是redis的持久化
两种持久化方法:
- RDB 快照持久化(默认)定期触发
配置文件中秒数 数据库改变次数 # save 900 1 # 900秒(15分)后,至少有 1 个键改变 save 300 10 # 300秒(5分)后,至少有 10 个键改变 # save 60 10000 # 60秒后,如果至少更改了10000个键 save "" # 删除之前配置的所有保存点 注释掉所有的 “save行” 表示禁用保存功能BGSAVE:执行BGSAVE命令,手动触发RDB持久化SHUTDOWN:关闭redis时触发 - AOF 追加文件持久化(默认关闭)
将执行的所有指令追加记录到文件中持久化存储
redis可以通过配置如下项开启AOF机制
AOF机制记录操作的时机appendonly yes # 是否开启AOF appendfilename "appendonly.aof" # AOF文件# appendfsync always # 每个操作都写到磁盘中 appendfsync everysec # 每秒写一次磁盘,默认 # appendfsync no # 由操作系统决定写入磁盘的时机
Python和redis的交互
-
安装:
pip install redis
卸载:apt-get purge --auto-remove redis-server
参数--auto-remove表示:删除安装软件包
参数purge表示:删除本地文件和配置文件 -
引⼊模块:
impor redis -
构建数据库连接对象:
连接对象名 = StrictRedis(参数列表...)
参数:hostIP 默认为localhostport端口 默认为6379db数据库号默认为0password默认为None
例:
sr = StrictRedis(host='localhost', port=6379, db=0)简写sr=StrictRedis()






from redis import StrictRedis
if __name__=="__main__":
try:
# 创建StrictRedis对象,与redis服务器建⽴连接
r = StrictRedis.from_url('redis://127.0.0.1:6381/0')
# 创建管道,管道可以缓存命令,减少客户端与 redis-server 交互的次数
pl = r.pipeline()
pl.set('a', 100)
pl.set('b', 200)
pl.get('a')
pl.get('b')
# 执行管道
ret = pl.execute()
print(ret) # [True, True, b'100', b'200']
except Exception as e:
print(e)
def foreachPartition(partition):
import redis
import json
client = redis.StrictRedis(host="127.0.0.1", port=6379, db=10)
for r in partition:
data = {
"price": r.price
}
# 转成json字符串再保存,能保证数据再次倒出来时,能有效的转换成python类型
client.hset("ad_features", r.adgroupId, json.dumps(data))
spark_df.foreachPartition(foreachPartition)















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









