







Flume 分布式日志收集系统
Flume 概述
- 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统
- 支持在日志系统中定制各类数据发送方,用于收集数据
- 提供对数据进行简单处理,并可定制数据接受方
运行机制
Flume的核心(agent):把 数据 从 数据源(source) 收集 过来,再将 收集到的数据 送到 指定目的地(sink);为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据到channel(临时存储),当Channel存储到一定值时,将数据写入到Sink中,待数据完全传输到目的地(sink)后,Flume再删除自己缓存的数据, agent本身是一个 Java进程,一般运行在日志收集节点
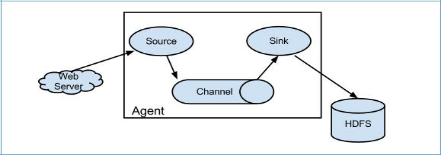
每一个 agent相当于一个数据传递员,内部有三个组件:
Source:采集源,用于跟数据源对接,以采集数据;Sink:目的地,采集数据的传送目的,可以是下一级agent的采集源 或 最终存储系统(HDFS 、Hive 或 Hbase)Channel: 临时存储容器,它将从source处接收到的event格式数据缓存起来,直到它们都到达sinks
channal是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接
在整个数据的传输过程中,流动的是 event(Flume内部数据传输的最基本单元,是一个字节数组)
event代表着一个数据的最小完整单元,也是事务的基本单位, 本身为一个字节数组,从Source流向Channel再到Sinkevent将传输的数据进行封装,完整的event包括:event headers 和 event body两部分,其中event body就是Flume收集到的日记记录- 收集文本文件时,通常一个
event代表一行数据
Flume安装部署使用
安装
前置条件:
Java 1.7 or later- 为
sources,channels和sinks提供充足的内存 - 为
channles提供充足的磁盘空间 - 为
agent提供读和写权限
安装步骤:
- 上传安装包到数据源所在节点上
- 解压
tar -zxvf apache-flume-1.9.0-bin.tar.gz - 进入
flume的目录,修改conf / flume-env.sh,在里面配置JAVA_HOME, - 配置
flume环境变量:vi ~/.bash_profile export FLUME_HOME=/root/bigdata/flume/bin export PATH=$FLUME_HOME/bin:$PATH source /root/.bash_profile - 检查是否配置成功:
flume-ng version查看flume版本 - 根据数据采集需求在配置文件中书写配置采集方案(文件名可任意自定义)
- 启动
Flume并运行配置文件:Flume路径/Flume-ng agent -n agent名字 -f 配置文件名
配置文件书写
配置 Flume 文件 步骤:
-
为
Agent、及其下的source、channal 和 sink命名
为提高辨识度,命名格式一般如下:
Agent命名为:source类型-channel类型-sink类型。如:exec-memory-kafka
source命名为:source类型-name。如:exec-source
channal命名为:channal 类型-name。如:memory-channel
sink命名为:sink类型-name。如:kafka-sink -
选型 并 配置
source -
选型 并 配置
channal -
选型 并 配置
sink -
将
source和sink通过channal绑定起来Agent名字.sources.source名字.channel=channel名字 Agent名字.sinks.sink名字.channel=channel名字 例如: exec-memory-avro.sources.exec-source.channels = memory-channel exec-memory-avro.sinks.avro-sink.channel = memory-channel
选型并配置Source
选型及配置格式:
agent名字 . sources . source名字 . type = Source 类型
agent名字 . sources . source名字 . 配置2 = value
agent名字 . sources . source名字 . 配置3 = value
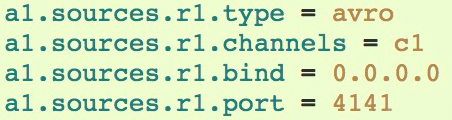
Avro Source:序列化数据源 通过网络传输
用于监听IP(非必本机,而是网络数据来源地IP) 和端口,用于获取数据
需要指定type,bind,ip、port,其他都可以使用默认配置,并且可以配置拦截IP的请求,对其不进行监听
模板配置如下:

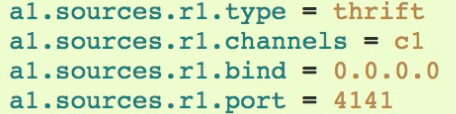
ThriftSource:序列化数据源
与Avro Source相差无几,但是不支持IP过滤
模板配置如下:
Exec Source:执行 指定的Linux命令行的数据源
可以运行指定的Unix命令并一直执行,例如:读取文件 作为flume数据的来源
需要配置type 和 运行命令;但不保证数据一定能够输送到channel,如果出现问题,则数据可能丢失

模板配置如下:
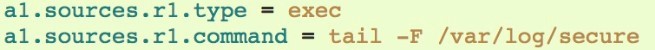
Spooling Directory Source: 监控指定目录
允许用户把文件放到磁盘上所谓Spooling目录,然后监控指定目录,一旦出现新的文件,就会解析新文件的内容,并传输到定义的sink中,传输过程中的解析逻辑可以自行指定,如果文件读取完毕之后,文件会重命名,或者可选择删除
其可靠性较强,而且即使flume重启,也不会丢失数据,为了保证可靠性,只能是不可变的,唯一命名的文件可以放在目录下,而且文件生成之后,一般不会更改,所以适合离线数据处理
模板配置如下:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1549
1549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









