






教程地址:https://github.com/KindXiaoming/pykan/blob/master/README.md
本系列文章用于记录自己学习过程
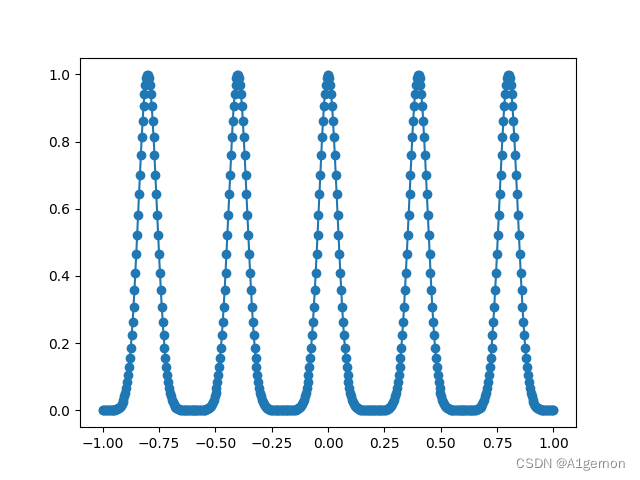
在本教程中,我们的目标是通过样本学习一个一维函数。该一维函数包含5个高斯峰。不同于将所有样本一次性呈现给神经网络,我们将进行五个学习阶段。在每个阶段中,仅向KAN(核逼近网络)呈现一个峰值周围的样本。我们发现,由于样条的局部性,KAN能够进行持续学习。
(1)环境设置和数据准备
from kan import *
import numpy as np
import torch
import matplotlib.pyplot as plt
datasets = []
n_peak = 5
n_num_per_peak = 100
n_sample = n_peak * n_num_per_peak
x_grid = torch.linspace(-1, 1, steps=n_sample)
x_centers = 2/n_peak * (np.arange(n_peak) - n_peak/2+0.5)
x_sample = torch.stack([torch.linspace(-1/n_peak, 1/n_peak, steps=n_num_per_peak) + center for center in x_centers]).reshape(-1,)
y = 0.
for center in x_centers:
y += torch.exp(-(x_grid - center) ** 2 * 300)
y_sample = 0.
for center in x_centers:
y_sample += torch.exp(-(x_sample - center) ** 2 * 300)
通过绘制这些数据,我们可以直观地看到高斯峰及其样本分布。
plt.plot(x_grid.detach().numpy(), y.detach().numpy())
plt.scatter(x_sample.detach().numpy(), y_sample.detach().numpy())
plt.show()
(2)分阶段呈现不同的峰值给KAN
我们分五个阶段,将每个峰值周围的样本逐步呈现给KAN。
plt.subplots(1, 5, figsize=(15, 2))
plt.subplots_adjust(wspace=0, hspace=0)
for i in range(1, 6):
plt.subplot(1, 5, i)
group_id = i - 1
plt.plot(x_grid.detach().numpy(), y.detach().numpy(), color='black', alpha=0.1)
plt.scatter(x_sample[group_id * n_num_per_peak:(group_id + 1) * n_num_per_peak].detach().numpy(), y_sample[group_id * n_num_per_peak:(group_id + 1) * n_num_per_peak].detach().numpy(), color="black", s=2)
plt.xlim(-1, 1)
plt.ylim(-1, 2)
plt.show()

(3)训练KAN模型
我们为每个阶段分别训练KAN模型。
ys = []
model = KAN(width=[1, 1], grid=200, k=3, noise_scale=0.1, bias_trainable=False, sp_trainable=False, sb_trainable=False)
for group_id in range(n_peak):
dataset = {}
dataset['train_input'] = x_sample[group_id * n_num_per_peak:(group_id + 1) * n_num_per_peak][:, None]
dataset['train_label'] = y_sample[group_id * n_num_per_peak:(group_id + 1) * n_num_per_peak][:, None]
dataset['test_input'] = x_sample[group_id * n_num_per_peak:(group_id + 1) * n_num_per_peak][:, None]
dataset['test_label'] = y_sample[group_id * n_num_per_peak:(group_id + 1) * n_num_per_peak][:, None]
model.train(dataset, opt='LBFGS', steps=100, update_grid=False)
y_pred = model(x_grid[:, None])
ys.append(y_pred.detach().numpy()[:, 0])
(4)每个阶段之后KAN的预测
我们绘制KAN在每个阶段之后的预测结果,以观察其学习过程。
plt.subplots(1, 5, figsize=(15, 2))
plt.subplots_adjust(wspace=0, hspace=0)
for i in range(1, 6):
plt.subplot(1, 5, i)
group_id = i - 1
plt.plot(x_grid.detach().numpy(), y.detach().numpy(), color='black', alpha=0.1)
plt.plot(x_grid.detach().numpy(), ys[i - 1], color='black')
plt.xlim(-1, 1)
plt.ylim(-1, 2)
plt.show()

通过以上步骤,我们成功实现了使用KAN进行的持续学习。在每个阶段,模型仅学习当前阶段的数据,但最终能够很好地拟合整个函数。这展示了KAN在处理持续学习任务中的有效性。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









