







目录
- 前言
- 投稿须知
- 投稿倒计时:Anywhere on Earth
- 类似的论文标题
- 可能用到的搜索关键词
- 用于人机交互凝视技术的综述
- IMWUT2023
- CHI2024
- CHI2022
- CHI2021
- CHI2020
- ECSCW
- 定性研究 (componental qualitative research )
- 随手插入一些概念性的笔记
- 一些后记
- 一些其他参考
前言
写这个笔记的起源是虽然已经博士二年级了,但是仍然处于一种还没有入门科研,觉得前面有万水千山,感觉自己完全走不下去,于是想通过一些量化的可见的东西给自己一点信心。开始写这个笔记应该是2024.4.13,中间应该是一直有断断续续地增加一些新的读书笔记,感觉我已经把csdn当日记写了。一直这样积累下来,将读博的输入可视化真的会减少很多读博期间因为没有正反馈所导致的无意义感。
目前,终于差不多定好了,博士期间的方向应该是VR/AR领域内的凝视交互,如果有类似方向的朋友可以评论或者私聊我一起交流。
CHI2025的网址:https://chi2025.acm.org/,估计这次还是赶不上2025了,如果赶不上2025我就把标题改成冲击2026(狗头)。好的,已经改好了新的标题(狗头狗头)
突然对CHIPlay很感兴趣!想冲击CHIPLAY2026(小小的科研火焰燃烧中
投稿须知
https://blog.csdn.net/luoxuexiong/article/details/107066568
投稿倒计时:Anywhere on Earth
https://time.is/zh/Anywhere_on_Earth
类似的论文标题
Making Sense of Maritime Simulators Use: A Multiple Case Study in Norway
Abstract: This paper reports a multiple case study of a training center collaboration with
three offshore companiesanda coastline authority. Through aqualitative inquiry, we utilized the actor-network theory to analyze the common understanding of simulator use in these organizations.The paper argues that the simulator itself is an actorthat can integrate shared interests with other actors to establish an actor-network. Such an actor-network expands simulator use beyond purely training purposes. It advocates that the simulator is a medium between maritime academia and industry and aligns it with the same actor-network to facilitate the process of “meaning construction.” Such a meaning construction process offers simulator-based training with a valuable definition of the learning outcomes. It helps clarifying who will gain the benefits from simulator use in the future, as well as when and on what basis. The paper also reflects on the benefits and limitations of utilizing a multiple case study in the maritime domain.
Augmented testing to support manual GUI-based regression testing: An empirical study
Context Manual graphical user interface (GUI) software testing presents a substantial part of the overall practiced testing efforts, despite various research efforts to further increase test automation. Augmented Testing (AT), a novel approach for GUI testing, aims to aid manual GUI-based testing through a tool-supported approach where an intermediary visual layer is rendered between the system under test (SUT) and the tester, superimposing relevant test information. Objective The primary objective of this study is to gather empirical evidence regarding AT’s efficiency compared to manual GUI-based regression testing. Existing studies involving testing approaches under the AT definition primarily focus on exploratory GUI testing, leaving a gap in the context of regression testing.
As a secondary objective, we investigate AT’s benefits, drawbacks, and usability issues when deployed with the demonstrator tool, Scout. Method We conducted an experiment involving 13 industry professionals, from six companies, comparing AT to manual GUI-based regression testing. These results were complemented by interviews and Bayesian data analysis (BDA) of the study’s quantitative results. Results The results of the Bayesian data analysis revealed that the use of AT shortens test durations in 70% of the cases on average, concluding that AT is more efficient. When comparing the means of the total duration to perform all tests, AT reduced the test duration by 36% in total. Participant interviews highlighted nine benefits and eleven drawbacks of AT, while observations revealed four usability issues. Conclusion This study presents empirical evidence of improved efficiency using AT in the context of manual GUI-based regression testing. We further report AT’s benefits, drawbacks, and usability issues. The majority of identified usability issues and drawbacks can be attributed to the tool implementation of AT and, thus, can serve as valuable input for future tool development.
Are current usabilty methods viable for maritime operation systems?
Usability is strongly linked to loss of life in many technical and incident reports. Maritime operation systems are sociomaterial systems in which many operators work cooperatively on ship bridges and decks. However, current usability methods focus more on individual interaction. Hence, applying such methods to maritime operation systems leads to several problems. Moreover, a few evaluation methods are hard to duplicate from other research fields owing to various reasons. In this paper, we indicate that maritime operation systems should consider cooperative work for providing a complete picture of interaction issues. In addition, evaluation for maritime operation systems needs deeper understanding of the relationships between human beings and systems. We discuss several usability methods that have been extracted from other close field (e.g., aviation systems, fishing systems, maritime navigation systems, and nuclear power plants) and apply insights from such fields to our case - deep-water anchor handling operation. We assert that usability in maritime domain should be expended as interaction in ecosystems such as the maritime operation system. We suggest that interaction study in maritime operation systems can offer a path to draw and measure a complete picture of maritime operation rather than purely focusing on individual usability issues.
Exploring Holistic HMI Design for Automated Vehicles: Insights from a Participatory Workshop to Bridge In-Vehicle and External Communication
As the field of automated vehicles (AVs) advances, it has become increasingly critical to develop human-machine interfaces (HMI) for both internal and external communication. Critical dialogue is emerging around the potential necessity for a holistic approach to HMI designs, which promotes the integration of both in-vehicle user and external road user perspectives. This approach aims to create a unified and coherent experience for different stakeholders interacting with AVs. This workshop seeks to bring together designers, engineers, researchers, and other stakeholders to delve into relevant use cases, exploring the potential advantages and challenges of this approach. The insights generated from this workshop aim to inform further design and research in the development of coherent HMIs for AVs, ultimately for more seamless integration of AVs into existing traffic.
What do Older Adults Want from Social Robots? A Qualitative Research Approach to Human-Robot Interaction (HRI) Studies
This study investigates what older adults want from social robots. Older adults are often presented with social robots designed based on developers’ assumptions that only vaguely address their actual needs. By lacking an understanding of older adults’ opinions of what technology should or could do for them–and what it should not do–we risk users of robots not finding them useful. Social and humanistic research on the robotization of care argues that it is important to prioritize user needs in technology design and implementation. Following this urgent call, we investigate older adults’ experiences of and approach to social robots in their everyday lives. This is done empirically through a qualitative analysis of data collected from six group interviews on care robots with health care service users, informal caregivers (relatives), and professional caregivers (healthcare workers). Through this “Need-Driven-Innovation” study we argue that, to secure a functional and valuable technology-fit for the user, it is crucial to take older adults’ wishes, fears, and desires about technology into account when implementing robots. It is also crucial to consider their wider networks of care, as the people in these networks also often interact with the assistive technology service users receive. Our study shows that more qualitative knowledge on the social aspect of human-robot interaction is needed to support future robot development and use in the health and care field and advocates for the crucial importance of strengthening the position of user-centered qualitative research in the field of social robotics.
可能用到的搜索关键词
Situational Awareness; Human-CPS interactions(Human-Cyber-Physical Systems Interaction); Unmanned Surface Vehicles; Participatory design; Ethnographic Study;
用于人机交互凝视技术的综述
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Eye Gaze Techniques for Human Computer Interaction: A Research Survey |
| 关键字 | 凝视技术 |
| 来源 | 2013 |
这些技术有助于开发和改善用户与计算机的交互。正在使用这些基于HCI的技术开发各种工程界面[1-3]。正在开发基于HCI的系统,以实现简单、有效、高效、安全和愉快的学习使用。这些应用程序成本低、节省时间。它们为用户提供了便利、安全和保障。传统的输入设备有一定的局限性。这些设备需要用户的接近和物理触摸,使得系统在没有用户手的情况下难以操作。此外,这些设备不能被不同能力的人使用,包括那些有肌肉残疾的人。有各种类型的HCI可以向计算系统发出指令。这些指令可以以不同的非常规和非物理方式给出。这种方法可能需要捕捉和解释面部、头部运动、眼睛凝视、手、手臂甚至整个身体。这种技术使用面部表情、手势、头部姿势、情感、语音或语音、眼睛凝视等的检测、分析和识别进行进一步处理。分析面部表情,如快乐、仇恨、恐惧、悲伤、厌恶、愤怒和惊讶,可能有助于理解和改善人类与计算系统的互动和交流。人脸检测技术包括提取面部特征,如前额、下巴、眉毛、眼睛、鼻子、嘴巴和发际线等。特别是眼睛定位算法也有助于准确的人脸识别。人脸检测技术在图像处理、模式识别和认证等领域非常重要,也有助于计算机视觉的交互式和实时应用[4,5]。基于手势的方法使用手,作为没有任何物理触摸的输入设备。这些方法可用于虚拟环境(VE)中的导航、选择和操作任务,例如手术模拟和训练系统。像数据手套这样的机电或磁传感设备是检测手部运动的一些有效工具。然而,在这些方法中存在一定的困难。这些包括高维问题、自我遮挡、处理速度、不受控制的环境和快速手部运动等[6]。头部姿势通过全脸模型的拟合结果来估计。头部运动可以分为不同的运动,如平行于图像平面、平行于镜头的光轴和旋转、向右或向左转动、朝上或朝下、颈部下降[7,8]。情感识别有助于找出用户的真实情感或感受,如愤怒、快乐、悲伤等。语音或语音识别有助于用户的识别和授权。飞行员、放射科医生和用户可以使用语音识别进行酒店和铁路预订。噪声水平、噪声类型、麦克风的位置以及用户语音的速度和方式是影响语音识别质量的一些因素。这些方法也有一定的局限性,如不准确、音频质量低等。眼球运动和检测是一种图像处理技术,可以定位眼睛注视技术的某些改进可以开发自然的人机界面。眼睛检测广泛用于人脸检测和不同的领域,如人工智能(AI)、虚拟现实(VR)、普适计算(UC)、增强现实(AR)、人工神经网络(ANN)等。眼睛注视是人机交互的另一种方法。在这些技术中,实时数据被收集用于跟踪和估计眼睛注视。这种估计通常是根据眼睛位置和运动的注视方向来完成的。它进一步用于执行用户对计算系统的期望指令,以进行调查、分析用户的愿望和情绪状态。眼睛检测等HCI应用程序被用于分析驾驶员的头部姿势检测行为[9],设计用于外科和医疗应用的模拟器[10],用于捕获和控制大脑信号作为脑机接口(BCI)[11]。眼睛注视技术的其他一些高端应用包括检测驾驶员的嗜睡和提高网络可用性[13]。眼睛注视系统的主要功能是人类活动识别、面部表情识别、指向和选择、激活命令以及与其他定点设备的组合。基于眼睛注视的技术也可用于提高金融交易输入代码的安全性或真实性等。正在研究眼睛注视模式以检测谎言或识别特定的人或场景[16]。消费者购物行为的影响评估,包装设计和产品投放,发展心理学,体育,眼科,神经科学,非人灵长类动物研究,心理语言学和广告研究是眼睛注视技术正在探索的许多领域之一。眼睛凝视技术可以使不同能力的人更容易和舒适地使用计算系统。这种交互方法对于弱智、不同能力和老年人等残疾人来说是一种独特而有效的工具,眼动可能是与计算机和其他人交流和交互的唯一可用手段[17,18]。这种技术也有助于那些由于肌肉或其他异常而无法握住或操作键盘或鼠标的人。
Blink‑To‑Live eye‑based communication system for users with speech impairments
眨眼直播是一种基于改进的眨眼说话语言和计算机视觉的眼睛跟踪系统,适用于有语言障碍的患者。手机摄像头通过向计算机视觉模块发送实时视频帧来跟踪患者的眼睛,用于面部地标检测、眼睛识别和跟踪。眨眼直播基于眼睛的交流语言中有四个定义的关键字母:左、右、上和眨眼。这些眼睛手势编码了60多个日常生活命令,这些命令由三个眼睛运动状态序列表达。
Framed guessability: using embodied allegories to increase user agreement on gesture sets(CHI2018)
使用具身预言来设计出感觉自然且用户可以直观地“猜到”的控制手势
[33]描述了设计“抓握敏感对象”的模型。“抓握”手势由五个“有意义的因素”定义,在实现抓握敏感用户界面时应考虑这些因素:
我们的目标(例如,螺丝刀的预期用途)、我们与对象的心理关系(例如,属于我们的组织与另一个人使用的组织)、我们手的解剖结构(例如,手掌大小)、对象所在的设置(例如,架子上的瓶子与箱子中的瓶子)以及对象的其他属性(例如,其大小)。1
量化手势的可猜测性(来源:Maximizing the Guessability of Symbolic Input|CHI2005)
量化可猜测性:
准确性:参与者正确猜测符号的概率。
一致性:不同参与者对同一符号的猜测一致性。
简洁性:符号形式简单直观,易于理解和记忆。
分组与冲突解决:将相同的符号分组,并使用评分函数(如之前提到的方程1和方程2)来解决冲突,确定哪些符号将被采用。
计算准确性:对于每个符号,计算参与者正确猜测的概率。这可以通过比较参与者提出的符号与最终采用的符号来实现。
量化步骤:
a. 计算平均准确性:
对于每个符号,计算参与者正确猜测的比例。
将所有符号的准确性平均值作为可猜测性的量化指标。
b. 计算一致性:
对于每个符号,计算不同参与者提出相同符号的比例。
将所有符号的一致性平均值作为可猜测性的量化指标。
c. 计算简洁性:
对于每个符号,评估其复杂度,可以是基于符号的长度、形状的复杂性等。
将所有符号的简洁性平均值作为可猜测性的量化指标。
综合评分:
将准确性、一致性和简洁性等指标加权综合,得到一个总体的可猜测性评分。
权重可以根据具体应用场景的重要性来设定。


The Emergence Of Eyeplay: A Survey Of Eye Interaction In Games 游戏中的眼动综述
Fixations,Saccades,Smooth Pursuits,Compensatory Eye Movements:These are involuntarysmooth movements that occur when moving the head whilstkeeping the eyes fixated at the same point in the visual field[19]. Until recently, the use of these movements for HCI wasdifficult, because eye trackers needed users’ heads to remainstationary (some even requiring a chin support) in order totrack gaze accurately. However, modern trackers are nowrobust enough to compensate for head movements, and areable to detect that the user is looking at the same spot, evenas they translate and rotate their head.Vergence:These movements focus the eyes at a distant target[19]. The further the target, the more parallel the two eyes willbe. In HCI, they are particularly useful for transparent displays,as the system can detect whether the user is looking at theforeground (i.e. at the screen) or the background (i.e. throughthe screen) [92]. Even though, we did not find applicationsfor vergence in games, this could be incorporated into gameslikeKeyewai[3] andRelationship Tunnel Vision[14], whichuse a see-through, gaze-enabled display where which playerssit across from each other. By observing vergence, the gameswould be able to detect whether the focus of attention is at thescreen or at the other player.Eyelid gesturesinclude winks and blinks.Winks are voluntaryclosures of one of the eyes. Winks have been long proposedas an eyes-only trigger to replace mouse clicks [54], and theyhave been used in games as a trigger while users aim with apistol [35]. However, not every user is able to wink voluntar-ily, with some people only being able to wink with one eye,and some not being able to wink at all [65]. Winking alsotransmits substantial nonverbal content, signaling collusion,shared secrecy, momentary intimacy , flirtation and trust [52,56]. As a social gesture, Da Silva et al. implemented a gamein which a little girl steals the player’s homework, which hecan recover by winking at her [15]. Blinking is part of thenatural maintenance of the eyes and occur semi-automatically.Therefore, when used for interactive purposes, blinks must beheld for longer to distinguish them from natural blinks. 2
眼睛手势的常见问题包括由于与自然搜索模式的潜在重叠而导致的意外激活;手势锚的屏幕空间有限;和扫视疲劳,因为故意控制囊是不自然和令人厌烦的[55].
众所周知,停留时间激活会受到Midas Touch问题的影响,即用户扫描环境时无意中激活目标[42]。虽然增加停留 时间阈值可以最大限度地减少这个问题,但它也会减缓交互并导致不自然的注视行为。平稳的追求比停留时间的选择更自然,因为眼睛会自然地被移动的物体吸引,从而减轻压力。然而,它们也容易受到有意激活和缓慢选择时间的影响。通过自愿改变瞳孔大小进行选择是可能的,但很困难。这种变化可能是由身体活动、自我诱导的疼痛、积极情绪、消极情绪、认知任务、专注的目光和注意力引起的[22]
Because of the jittery andsudden nature of eye movements, a 1:1 mapping of gaze to theviewport control is infeasible.由于眼球运动的紧张和突然性质,将视线与视口控制进行1:1映射是不可行的。
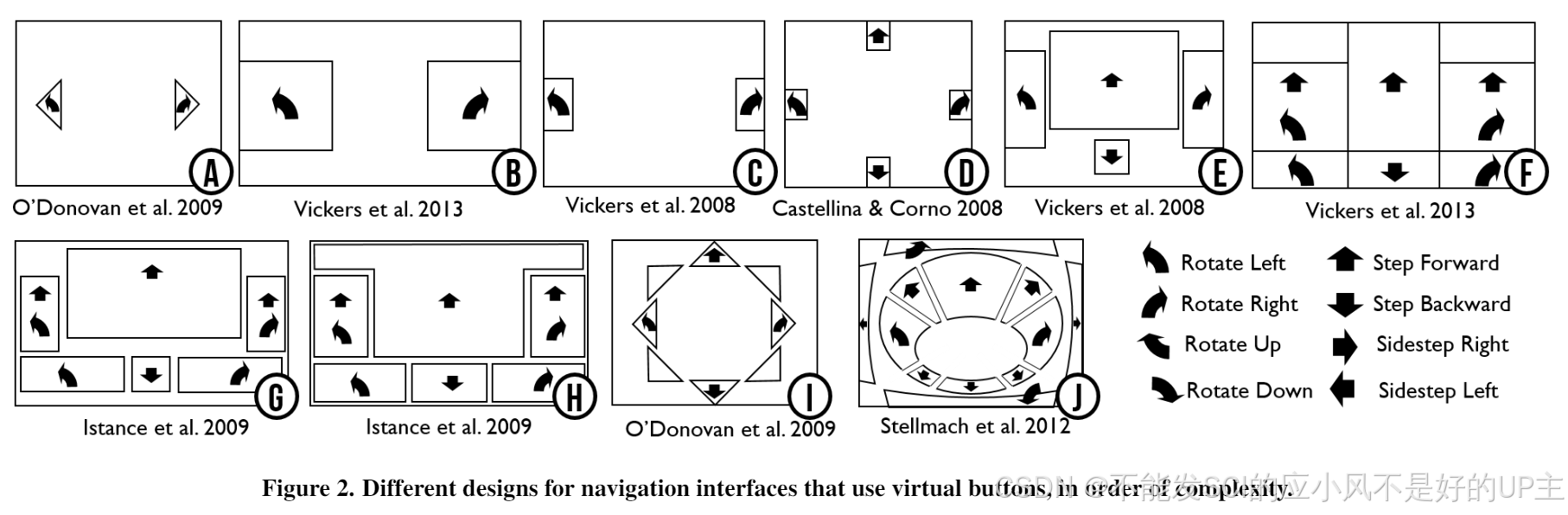
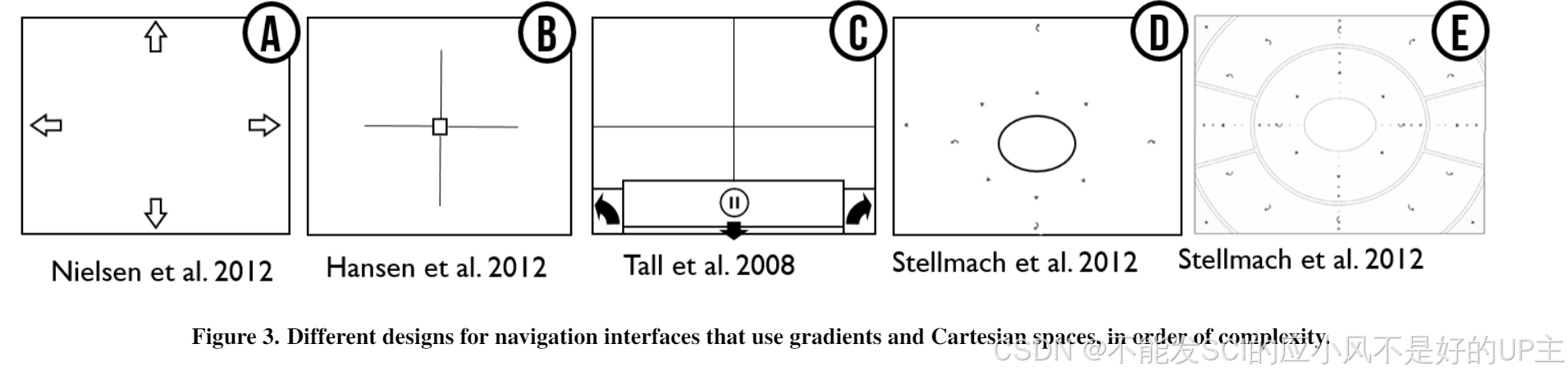
IMWUT2023
在AR环境中选择小型3D虚拟对象的自适应操作
| * | # |
|---|---|
| 链接 | link. |
| 题目 | FocalPoint: Adaptive Direct Manipulation for Selecting Small 3D |
| Virtual Objects | |
| 关键字 | 滚雪球法 |
| 来源 | IMWUT2023 |
先前的工作[41,70]已经发现,人们经常用他们的非惯用手握住他们的智能手机进行屏幕上的交互,而让另一只手自由地进行其他任务。自然,在智能手机AR的上下文中,惯用手变得可用于执行徒手直接操作以及其他3D手交互[73]。这种bimanual interaction modality 在研究文献[30,49,74]和商业产品[36,60]中都被广泛采用和研究。通过将交互手从智能手机屏幕上移开,这种双目方法绕过了传统2D触摸交互带来的许多问题,例如屏幕遮挡、屏幕尺寸小以及2D输入对3D交互的固有限制[73]。此外,双模态还为交互的手提供了新的交互可能性,例如握笔进行物体操作[65]和携带微型屏幕进行半空绘画[51]
他们首先进行了一个Preliminary formal research 招募用户通过观察自由形式选择任务期间的自然参与者行为,以告知我们的技术设计,随后进行:

- 实证观察Empirical Observations
- 行为分析Behavior Analysis
- 设计考虑Design considerations
其中一些设计元素可以由研究人员经验确定(determined empirically)。

总的来说,焦点在我们的评估中平均达到了70%的准确率。
尽管未来肯定还有改进的空间,但我们认为,当与选择小目标或拥挤目标的其他选择技术放在一起时,70%是一个合理的准确率。首先,焦点的准确率几乎是基线技术的三倍,基线技术是一种改进的直接操作方法,已经结合了文献中广泛使用的技术,包括排名、阈值和消歧机制,如第6.1.1节所述。
关于baseline方法的选择
基线条件。如相关工作中所述并在表1中所示,现有技术不适合直接用于基线比较,因为它们要么不是为智能手机双元设置[6,16,22,31]开发的,要么被设计为仅处理大对象[8,10,24],要么不支持徒手直接操作[39,45,63]。因此,为了评估Focus alPoint在多大程度上改善了小对象(R1)的徒手直接操作选择体验,
我们整合了现有的广泛使用的解决方案来构建基线技术。具体来说,我们添加了一种类似于IDS和Smart Ray[22,45]的排序机制,通过对象到用户交互手的距离来对对象进行评分。排名最高的对象用3D绿色轮廓突出显示。阈值,在许多直接操作技术[8,24,49]中发现的一种常见机制,也用于在手捏和触摸目标的手指数量超过设定阈值(在我们的例子中为3个)时触发选择。对于选择消歧,如果多个对象被指骨相交,则选择具有最多骨头的对象。
基线的另一种形式是单手体积射线投射方法,其中选择几何形状从屏幕投射,但另一只手不用于选择过程。在这种技术中,需要eparate步骤来确认选择,例如旋转[15,33]或按下从中投射选择几何形状的输入控制器[10]。我们的智能手机设置中的一个等效步骤是在屏幕上旋转或敲击。在实践中,这可以加快选择速度,并导致更快的任务完成时间,因为旋转或敲击比捏更快地执行。先前的研究还表明,光线投射通常比徒手操作执行得更快[50,68]。另一方面,这个额外的步骤可能会引入轻微的屏幕移动,从而动摇选择几何形状,对小物体的选择精度产生负面影响。
我们没有将Focus alPoint与体积光线投射技术进行比较,原因有两个。首先,由于我们的目标是改善在智能手机上选择小物体的直接操作体验,将焦点与徒手直接操作技术(即我们构建的基线)进行比较,而不是体积光线投射,有助于我们更好地研究R1。其次,体积光线投射技术中使用的基于距离的排名算法[10,15,33]考虑了中心光线和虚拟物体之间的距离,这类似于我们基线中使用的排名算法。总之,我们的基线更适合帮助我们调查我们的研究问题,同时结合了体积光线投射技术的某些优势。
射线选择技术Ray Casting Selection Techniques
该篇文章针对的是超小物体3
他的技术类型从用户的手或输入设备投射一条射线,以选择与该射线相交的对象[15,33,42]。当目标很小,位于一定距离,或者靠近或被其他对象遮挡时,它可能会变得缓慢和不准确[31,54,61]。具体来说,选择预期的对象很困难,因为小的运动沿着射线被放大。当对象密集时,遮挡也增加了定位和消除目标对象歧义的难度[54,61]。为了解决这些问题,一些方法修改射线本身,使其向目标弯曲[10,14],或者对射线可以相交的位置增加限制[2]。在那边[58]通过在多个射线之间进行三角测量来识别目标位置。聚光灯技术[33]引入了体积光线投射,投射一个圆锥体而不是光线来减轻突然运动的影响。Forsberg等人[15]通过添加控制来调整选择圆锥体的大小和方向,进一步发展了它。有时光线投射与直接操纵相结合,以改善用户的选择体验。Go-Go技术[48]允许用户"甩开"虚拟的手到达远处的物体。HOMER技术[69]使用光线投射进行选择,并使用手的交互进行操纵。然而,这些作品并没有探索选择密密麻麻的小物体的问题,而这正是Focus alPoint的重点。
行为驱动的选择技术Behavior-Driven Selection Techniques
其他技术采用行为线索来提高选择精度(表1)。Hook[43]跟踪用户光标跟随移动对象的时间,以预测潜在目标。类似地,Smart Ray[22]计算光线在时间上在对象附近停留的时间,以确定目标对象。SenseShapes[42]结合手势和语音输入,Zhang et. al[75]使用时间模式,如敲击或眨眼,Esteves et.al[13]采用运动匹配来根据输入模态动态改变选择逻辑。意图驱动选择(IDS)技术[45]将选择球体连接到用户的手上,并使用动作效率[7,20]和动作持久性[37]等线索来选择距离其邻居1毫米的小至6毫米宽的对象。然而,在较小的遮挡对象上使用IDS会导致选择速度变慢,因为用户很难看到哪些对象与选择球相交。在概念上类似,我们考虑行为模式,并使用先前选择对象的屏幕位置来连续自适应地更新选择几何的大小和位置
歧义消除Selection Disambiguation
选择消歧的主要目的是从一组可能的候选对象中确定用户的预期目标。在此过程中使用的一种常见机制是渐进式细化。首先由Kopper等人[31]提出,它将每个选择任务划分为更简单的子任务,直到选择目标[11]。正如Weise等人[67]所分类的那样,渐进式细化可以进一步分为离散和连续的类别。
虽然离散渐进细化可以非常准确,但由于多步骤过程和对用户在细化过程中的错误的低容忍度,选择通常不太流畅[54]。在这些步骤中去除环境和空间上下文进一步降低了沉浸感,并使目标获取更加困难[45]
CHI2024
*凝视方式进行3D作画
| * | # |
|---|---|
| 链接 | link. |
| 题目 | EyeGuide & EyeConGuide: Gaze-based Visual Guides to Improve 3D Sketching Systems |
| 关键字 | 特定场景的凝视方法 |
| 来源 | CHI2024 |
我们提出了两项用户研究,以调查我们提案的草图绘制性能、质量和用户体验。第一个侧重于绘制基本形状,例如线条和圆形,第二个侧重于复杂形状,例如开罐器的 3D 模型。在这两项研究中,我们将提出的技术与两个基线进行了比较4,一个没有视觉参考线,另一个带有不可切换的基于控制器的网格片段。
*在 VR 中设计为脊髓性肌萎缩症患者设计的上半身交互
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Designing Upper-Body Gesture Interaction with and for People with Spinal Muscular Atrophy in VR |
| 关键字 | 特定VR凝视、启发式设计 |
| 来源 | CHI2024 |
最近的研究提出了凝视辅助手势来增强虚拟现实 (VR) 中的交互,为运动障碍者提供体验 VR 的机会。与其他运动障碍患者相比,脊髓性肌萎缩症 (SMA) 患者表现出增强的远端肢体活动能力,为他们提供了更多的设计空间。然而,目前尚不清楚 SMA 患者想要并能够执行什么凝视辅助上半身手势。我们进行了一项启发研究,其中 12 名有 VR 经验的 SMA 患者为 26 个 VR 命令设计了上半身手势,并收集了 312 个用户定义的手势。参与者主要喜欢用手创造手势。任务类型和参与者的能力会影响他们为手势设计选择的身体部位。参与者倾向于增强他们的身体参与,并更喜欢需要最少体力劳动且在美学上令人愉悦的手势。我们的研究将有助于为运动障碍人士创造更好的基于手势的输入方法,以便与 VR 互动。
由于眼球运动是运动规划的固有部分,并且先于动作 [20],这种方法利用了眼球选择和手势确认的交互范式,利用了眼球运动的快速性和手势的灵巧性。“凝视 + 手势”已用于 Apple Vision Pro 等商业产品1,有望成为 SMA 患者的 VR 系统的交互式模式。然而,目前尚不清楚他们希望如何使用这种交互范式进行 VR 交互并使用其他上半身部件对其进行修改。
本文提出以下贡献:
(1)我们确定并描述了一组 26 个常见命令,以涵盖一般的 VR 交互。
(2)我们发现了一种用户定义的上半身手势分类法,这些手势基于SMA患者设计的手势,以完成上述命令集。
(3)我们推导了SMA参与者在设计上半身手势时的心智模型和考虑因素,以增加VR交互的可及性。
用户启发的手势设计
2.3 用户定义的手势设计5
用户定义的手势已被广泛用作发现和识别手势词汇的启发研究。事实证明,用户定义的手势比研究人员定义的手势更容易记住和学习 [27]。Wobbrock等[58]开始为多点触控表面计算提供用户定义手势,这是第一个在手势集的开发中使用用户而不是原则的方法。他们首先招募了没有使用触摸屏经验的非技术参与者,向他们展示所指对象或动作的效果,然后通过使用发声思考协议和视频分析来引出旨在调用它们的一组手势。这种手势设计过程已应用于各种领域,例如键盘 [3]、公共显示器 [19]、有形系统 [18, 50]、智能手表 [2]、车载用户界面 [56] 和增强现实 [35]。至于VR,Wu等[59]报道了一个关于VR购物应用程序用户定义手势的研究项目,该项目在前一阶段从每个参与者那里获得两个手势,并从所有手势中选择前两个手势。此外,Moran-Ledesma等[25]对20个类似CAD和开放世界的游戏类指称(VR中动作的效果)的操作手势进行了启发研究。Nanjappan等[28]提出了一项类似的用户启发研究,用于在虚拟现实环境中操纵3D对象。我们的研究是由这些用户定义的方法推动的。具体来说,我们的研究采用了类似的以用户为中心的方法,调查了脊髓性肌萎缩症患者想要创建哪些凝视辅助上半身手势,以及他们希望如何使用这些手势来完成 VR 系统的任务。
启发式设计 (an elicitation study )
我们的研究的动机是需要为SMA患者提供可访问的VR输入方法,而这些“凝视+手势”的工作原理。
我们的用户定义手势设计方法的灵感来自于先前在其他情况下为运动障碍者设计用户定义手势的成功[63]。在这项工作中,我们聘请了 12 名 SMA 患者设计了 26 个 VR 常见命令的上半身手势,并根据先前的研究扩展了包括眼睛、嘴巴、面部、头部和保持上肢活动度的设计 [13, 30, 41, 55]。在研究过程中,参与者观看了解释每个VR命令及其效果(即指涉)的视频剪辑,然后设计并执行了上半身手势。之后,参与者使用 7 点李克特量表评估了设计手势所需的努力以及他们所创建的手势的心理需求、身体需求和满意度。最后,我们进行了半结构化访谈,以更多地了解他们的考虑因素。我们总共收集了 312 个用户定义的手势,并确定了他们对 VR 输入方法的偏好和心智模型。6
整个研究过程如图 4 所示
1) 引言。在介绍阶段,我们首先简要介绍了我们的项目,然后要求参与者自我报告他们的运动能力,包括他们的日常活动和使用各种设备的挑战,以更好地了解他们的能力。在参与者演示他们的身体状态时,我们观察了他们运动的最大和最小范围,并指导参与者修改相机的角度或调整他们与相机的距离。这确保了参与者的所有手势都全面地显示在视频中。然后,向参与者展示了包括视频在内的材料8、图像和文本来说明 VR 中注视辅助交互的方法。在查看了这些材料后,我们确认了参与者的理解情况。
2) 参考观看。在设计手势之前,参与者首先会接触到简短的视频剪辑,这些视频剪辑说明了每个 VR 命令(即 referent,由 Wobbrock 等人 [58] 首先调用)的效果。在图 5 中,显示了 “Grab Distant Object” 命令的视频剪辑帧示例(该视频可在补充材料中找到)。每个视频剪辑由两部分组成,如图 5 (a) 所示。在屏幕右侧,佩戴 Quest2 耳机的研究人员记录了执行命令的第一人称视角。在左侧,展示了研究人员在现实中执行 VR 命令时的动作,以帮助理解.^5。这两个透视图经过编辑,以实现时间同步。需要注意的是,视频中显示的健全动作不是手势,而只是 VR 命令指令的一个组成部分。我们向参与者强调了这一点,鼓励他们根据自己的能力和偏好设计手势。

3) 手势设计。每次观看后,参与者都被要求为 VR 命令创建一个上半身手势,并向主持人执行该手势。在这个过程中,我们要求参与者在设计过程中大声思考,用语言表达他们的想法。研究人员询问了参与者在设计阶段分享的思维过程。例如,如果参与者表达了创建酷手势的愿望,主持人会更深入地研究,询问他们为什么想要设计具有酷炫外表的手势,以及他们认为很酷的特征。这种方法旨在更深入、更全面地了解 VR 手势设计过程中 SMA 个体的心智模型。
为了减少手势冲突,我们要求参与者为同一类别中的每个命令设计不同的手势。对于不同类别的命令,参与者可以执行相同的手势。但是,由于命令数量众多,一些参与者可能已经忘记了他们以前的设计。因此,主持人会监控已经创建的手势,如果她发现设计中存在冲突,她会提醒参与者将当前或以前设计的手势更改为不同的手势。参与者可以在过程中的任何时候更改他们之前的手势。
4) 对手势进行评分。完成每个手势设计后,参与者被要求用 7 分李克特量表对他们手势的四个方面进行评分,包括设计努力(为当前所指对象设计手势所涉及的难度)、心理需求(执行建议的手势所需的认知负荷,例如记忆)、身体需求(执行建议的手势的身体工作量), 以及对所提议手势的总体满意度。研究人员对这些评级进行了跟进,以更深入地了解参与者的观点。例如,如果一个手势在身体需求方面被评为高,但在总体满意度方面也很高,研究人员会询问这些评级背后的原因。
5) 半结构化面试。完成所有手势设计后,我们对每位参与者进行了半结构化访谈。这些访谈是根据参与者在设计手势期间的回答量身定制的,使我们能够提出后续问题以获得更深入的信息。访谈的重点是参与者在当前 VR 设备使用中遇到无障碍问题的经验、他们的偏好和设计手势时的主要考虑因素、他们对 VR 交互方法的期望以及他们希望添加的任何其他内容。例如,由于担心将来会出现进行性肌肉萎缩,一些参与者建议希望使用与眼球运动和 UI 组件集成的通用手势集。
怎么利用文件和材料来总结目前vr的常见命令
为了收集 VR 命令并向参与者展示效果,我们回顾了以前的 VR 命令论文,但没有发现任何包含完整命令作为我们工作参考的论文。虽然有三篇关于用户定义的 VR 手势的论文,但每篇论文都侧重于特定 VR 应用程序(例如 CAD 和开放世界游戏 [25]、VR 购物应用程序 [59] 和操作 3D 对象 [29])中的交互,而没有涉及常见的 VR 交互。7
结合文献综述和对市场上许多 VR 应用程序的参考,从 VR 中的典型交互中得出了 30 个命令和任务。这导致了 30 个任务单元,这些任务单元分为 3 个类别(9 个子类别):对象控制(选择、取消选择、移动、旋转、均匀缩放、编辑)、场景控制(视点变换)和系统控制(全局命令、临时命令)。下面的表 2 显示了 3 个类别下 30 个选定任务单元的列表。出自文献:https://link.springer.com/chapter/10.1007/978-3-319-92141-9_2

心智模型分析法
3.4.1 手势分析方法。
用户定义的手势的原始分析方法[58]涉及两个主要步骤:首先,将每个手势沿四个维度(形式、性质、绑定和流程)分类为一个分类法,以描述手势设计空间。其次,将相同的手势分组,并选择共识最大的一组作为每个引用的代表手势,以供将来的设计参考。鉴于我们专注于 SMA 和 VR,我们进行了两项重大更改,同时考虑了两个因素:身体部位和类似模式。从针对运动障碍个体的以用户为中心的手势设计研究中汲取灵感 [63],该研究根据所涉及的身体部位对手势分类法进行分类,我们用所涉及的身体部位替换了四个维度(形式、性质、绑定和流动)。我们还提到了对 VR 以用户为中心的手势设计的研究 [25, 59]。这促使我们将标准从“手势必须相同”转变为“具有相似图案的手势”,承认 VR 手势设计的多样性。用户定义的手势是根据参与者的描述来识别的,并通过摄像头或亲自执行。
3.4.2 心智模型分析法。8
数据包括在线会议的录音,包括参与者在发声思考设计阶段的表情、他们对设计努力的评分解释、心理需求、身体需求和对设计手势的满意度,以及他们在最终的半结构化访谈中表达的整体担忧和期望。这些录音被转录成文本脚本。两名研究人员最初将这些脚本通读了几遍,以全面了解参与者在手势设计中的心智模型。随后,研究人员使用开放编码方法独立编写脚本 [7]。主题、子主题和特定内容是通过为参与者的回答分配关键字来归纳构建的。重复或类似的关键词被分组到更高级别的类别中。例如,当 “错误识别”、“担心识别” 和 “无法识别” 等短语频繁出现时,子主题 “对微手势识别准确性的担忧” 就出现了。编码人员定期讨论并协调任何编码差异。与其他合著者进行了进一步的会议,以根据初步编码最终确定协议。最终,我们确定了 SMA 参与者的四种心智模型,详见第 5 节:心智模型观察。心智模型的密码本在补充材料中。
*凝视交互的 2D 平台游戏对用户享受、感知能力和数字眼疲劳的影响
| * | # |
|---|---|
| 链接 | link. |
| 题目 | FocusFlow: 3D Gaze-Depth Interaction in Virtual Reality Liveraging Active Visual Depth Manipulation |
| 关键字 | 凝视游戏,related work |
| 来源 | CHI2024 |
2.1 Eye Gaze — 游戏中的技术采用
.2 眼睛凝视作为一种交互方式
眼动追踪作为一种纯粹的交互技术,在人机交互中有着悠久的历史。早在 1990 年,Jacob [33] 就提出了交互技术,例如基于凝视的选择(眼睛凝视选择一个对象,按键模拟点击)、对象移动、文本滚动(当到达文本底部时,文本会自动滚动)或菜单。主要工作研究了眼睛凝视输入作为一种可访问性工具,或补充和增强传统输入法[29,30,31,32,50,60,66],或增加沉浸感,例如,通过自适应渲染[21]。此外,眼睛凝视还用于调整游戏难度 [4] 或自动瞄准 [13]。除了凝视点外,还采用了眨眼 [15]、眨眼 [10] 或周边视觉 [51]。
经典方法通常描述用于交互的凝视隐喻方法。
通常,经典的凝视范式“”所见即所得“[51],即使用中央凹视觉区域与物体交互(例如,选择/瞄准物体)。例如,Istance 等人 [31] 实现了两条腿和三条腿的凝视交互,这意味着凝视需要执行两个或三个不同的动作(例如,向上、对角线向左移动,然后回到三足交互的原始位置)。他们发现,三足方法所需的时间大约是两条腿的两倍。在《魔兽世界》中使用两条腿的凝视交互时,这些手势对于事件表现良好,但对于连续交互(例如移动角色)表现不佳。Lankes等[40]提议使用眼睛注视方向作为线索来指导玩家进行探索游戏。如果玩家的中央视图或凝视靠近相关对象,则大小不一的晕影将表示接近。通过利用眼睛凝视,体验和性能得到了改善。Kocur等[35]使用眼睛凝视来增强多目标场景的子弹磁力机制[67]。然而,这种相互作用没有经过实证评估。
除了 “”所见即所得“ 之外,还有不同的尝试来利用眼交互的可能性。
Ramirez Gomez 和 Gellersen [52] 提出了“not looking”作为游戏的隐喻。例如,角色会随着规律的眼球运动(即跟随凝视)而持续移动,但可以在闭上眼睛后传送到眼睛凝视的位置。参与者发现这种互动总体上具有挑战性但很有趣。Lankes 和 Berger [39] 提出了“盲点”。在他们的艺术装置中,观察者的中央凹视觉区域被遮挡,迫使观察者依赖周边视觉。Ramirez Gomez 和 Gellersen [51] 也包括周边视觉。为此,它们包括不同的任务(例如,检索有关外围对象的信息以进行决策或外围交互,即通过键盘与对象交互)和挑战或规则(例如,“不得查看对象”[51,第 3 页]),然后通过隐喻将其纳入游戏中。作者发现,这创造了一种“引人入胜和有趣的体验”[51,第 1 页]
Ekman 等人的 Invisible Eni 和 Vidal 等人的 Shynosaurs 在设计中融入了刻意的挑战,以相当大的难度说明了凝视界面。例如,在《隐形埃尼》[15]中,玩家需要通过控制瞳孔放大来操纵游戏元素,而《Shynosaurs》[69]则让玩家在保持与怪物的眼神交流和有效协调手部动作之间陷入困境。
Nacke等[44]评估了直接(如眼睛凝视)和间接(如心率)生理博弈相互作用对传统控制的作用。作者表现出对用户之间直接互动的偏好。眼睛凝视作为一种交互方法的实现如下:激活后,眼睛凝视会暂时冻结敌人和移动的平台(因此,准确地命名为美杜莎的凝视)。
最后,之前的工作也被纳入多玩家设置中并进行了评估,例如,在首选实时热图的情况下推断他人的意图[46]。然后,可视化可以用作游戏机制,例如,欺骗其他玩家 [45]。
关于眼睛凝视交互的性能与小鼠与凝视交互的比较,Dechant 等人 [11] 发现“鼠标是最快的技术,而凝视是最慢且最容易出错的技术”[11,第 1 页]。
2.3眼睛凝视交互分类9
关于基于凝视的交互,Isokoski 等 [29] 定义了四种技术方法,使视频游戏适应使用眼睛凝视作为交互方式:(1) 使用停留时间代替鼠标输入等,(2) 使用额外的软件将事件注册到游戏中,(3) 调整游戏的源代码,以及 (4) 从头开始开发游戏。但是,随着 Unity 等游戏引擎的激增,这种分类法变得不那么相关,这些引擎可以轻松创建游戏。
Ramirez Gomez 和 Lankes [53] 引入了一个与凝视交互的框架,具有四个维度:身份;映射;注意力;和 Direction (方向)。在“Sheed Some Fear”中,我们专注于 Identity 玩家、Mapping 凝视、Attention direct 和 Direction 玩家的(第二个)头像。
Almeida等[3]将眼动追踪的工作分为电子游戏的输入和视觉注意力研究。在“Shed Some Fear”中,我们关注输入机制。
Velloso 和 Carter [65] 提供了 112 种单独的游戏机制的列表。他们提出了关于眼球运动(注视、扫视、平滑追踪、补偿性眼球运动、辐辏和视动性眼球震颤;另见[3]))、输入类型(离散-仅、连续-仅、离散+连续)、游戏机制(导航、瞄准和射击、选择和命令、隐含命令和带有子类别的视觉效果)的分类法。在 “Shed Some Fear” 中,我们融入了其中的几个,例如,固定、平滑的追求,以及离散或连续的输入。
同样在Eye Ball: Gazing as a Dilemma in a Competitive Virtual Reality Game的related
work中也有类似综述。
利用视觉深度(眼睛发散和收敛)来进行凝视交互
| * | # |
|---|---|
| 链接 | link. |
| 题目 | FocusFlow: 3D Gaze-Depth Interaction in Virtual Reality Liveraging Active Visual Depth Manipulation |
| 关键字 | |
| 来源 | CHI2024 |
最近关于基于凝视的VR/AR交互的工作表明,视觉深度作为交互输入解决Midas触摸问题的巨大潜力。这些方法要么引导用户观察不同深度的物理或虚拟物体[3,27,37,44,45],要么依靠自愿的眼睛收敛和发散[13,15],要求用户专注于鼻子或想象注视显示平面后面的某个点。 这些工作证明了利用视觉深度作为VR头显输入的可行性,然而,这种新的交互设计的可用性和可学习性尚未得到充分探索。容易失败且难以学习的体验会导致用户感到沮丧和疲劳,使交互无法使用。如何引导用户学会操纵他们的视觉深度作为可靠的输入仍然是一个研究空白。7
吃东西的时候增加音效提高趣味性
| * | # |
|---|---|
| 链接 | link. |
| 题目 | GustosonicSense: Towards understanding the design of playful gustosonic eating experiences |
| 关键字 | 滚雪球法 |
| 来源 | CHI2024 |
滚雪球法 snowball method 招募被试
滚雪球法是一种用于研究的参与者招募技术
它包括最初招募少数符合特定标准的参与者,然后要求这些参与者推荐其他也符合标准的潜在参与者。
这种方法产生了连锁反应,最初的参与者推荐其他人,导致研究的样本量不断增加。
在这篇研究论文的背景下,滚雪球法与方便抽样相结合,招募了一项关于GustosonicSense用户体验的野外研究的参与者。
通过利用滚雪球方法,研究人员可以接触到更广泛的参与者,这些参与者可能不容易通过传统的招募方法获得,从而提高研究样本的多样性和代表性。
方便抽样 Convenience Sampling
便利抽样是一种非概率抽样技术,研究人员根据参与者的易用性和可用性来选择他们。
在方便抽样中,选择参与者是因为他们很方便接触,例如研究人员很容易接触到他们,或者符合使他们易于用于研究的特定标准。
当时间、资源或物流限制使实施更复杂的采样技术具有挑战性时,通常会使用这种方法。
在研究论文中,将方便抽样与滚雪球法相结合,招募参与者参与GustosonicSense的用户体验研究。
虽然方便抽样可能缺乏概率抽样方法的随机性和代表性,但它仍然可以提供有价值的见解,特别是在探索性研究或特定人群感兴趣时。
研究人员应该谨慎地将研究结果从方便样本推广到更大的群体中去。

主题分析 inductive thematic analysis
We used NVivo [ 57] to undertake an inductive thematic analysis[ 63 ]. 我们将每个问题和每个参与者的答案结合起来,并将它们视为定性数据的一个单元。总共有183个数据单元。两名研究人员阅读了三次成绩单以熟悉数据,然后独立编码。他们的编码帮助团队识别和分组数据单元最有趣的特征。在第一轮主题分析中,我们开发了12个代码标签。在第二轮中,两名研究人员讨论并重新检查代码以合并相似的代码并降低复杂性。然后在一名高级研究人员的帮助下,这些标签被迭代地聚类成三个更高级别的主题。
公共场景可视化
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Make Interaction Situated: Designing User Acceptable Interaction for Situated Visualization in Public Environments |
| 关键字 | 5W1Hs, the formative study |
| 来源 | CHI2024 |
形成性研究
5W1Hs
By formulating requirements based on the 5W1Hs design space, which stands for Who, What, Where, When, Why, and How, researchers aim to gather comprehensive information about user needs and preferences in situated visualization.
谁、什么、在哪里、何时、为什么和如何
The 5W1Hs design space helps in identifying the specific tasks users undertake in different scenarios, their preferences for interacting with situated visualization, the preferred locations for displaying data, and the methods for activating situated visualization in public settings.
临终关怀患者对虚拟姑息治疗助理的看法(定性分析)
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Challenges and Requirements in Multi-Drone Interfaces |
| 关键字 | extended abstract 、针对特定场合的与专家一起设计/评估 |
| 来源 | CHI2024 EA # CHI2024 |
多无人机协作界面设计
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Challenges and Requirements in Multi-Drone Interfaces |
| 关键字 | extended abstract 、针对特定场合的与专家一起设计/评估 |
| 来源 | CHI2023 EA |
我们对三种控制方法中的两种(信标和领导者无人机)使用了 Wizard-of-Oz 方法——这是无人机交互研究中的常见做法 [3, 10, 24]。
在整个研究过程中,各种讨论都集中在了解自动化以及影响用户对自主功能的 SA 和信任的方面 [13, 31]。当演示活动在室外进行时,参与者对周围环境保持谨慎,并不断确保无人机处于稳定和安全的运行状态。但是,随着无人机数量的增加,这很困难,有些无人机会超出用户的视线。
对于一些参与者来说,区分无人机至关重要,这样他们才能立即识别哪架无人机行为异常或找到了物体。我们尝试使用颜色和形状来解决这个问题,虽然目前它已经足够了,但将来缩放时会出现问题。编号系统是理想的,但如果无人机成群飞行并重叠,则可能仍然不够。目前,所有参与操作的无人机始终显示在地图上,但可能并不总是需要显示它们。为了安全地使用此类功能,研究需要探索是否有必要始终显示单个无人机,或者探索随着无人机数量的增加而更适当地扩展的替代方案。
为了维持 SA,参与者表示,他们需要知道无人机已经做了什么以及他们将做什么。Endsley [14] 的工作表明,为了让用户做出明智的决定,重要的是不要遗漏信息,而是以一种允许用户获得信息的方式提供信息,而不会不知所措或不必寻求信息。与 Agrawal 等人 [1] 一样,研究应该寻求了解我们如何设计界面来保持高水平的 SA。
从共同设计会议中可以明显看出,只有在自动化层支持用户的情况下,多无人机系统才可行。在 SAR 的情况下,视频馈送和飞行自动化中的对象检测对于无人机集群的成功至关重要。然而,研究表明,自动化的视觉表示会导致对系统的过度信任,用户会高估系统的能力 [12]。用户仍应被允许进行干预,不仅在出现问题时,而且在自动化行为不符合他们的喜好时。这正是一些用户在当前用于单无人机控制的商业软件中遇到的问题 [9, 37]。在调整自动化时,用户控制的适当粒度仍不确定。未来的研究应寻求为如何在多无人机系统中处理自动化制定指导方针。
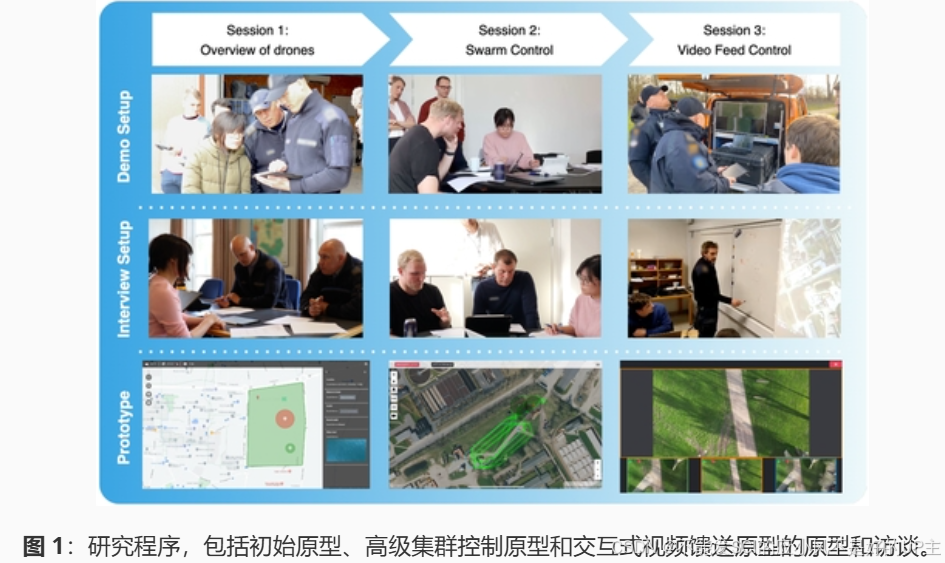
参与式设计/与 Agrawal 等人 [1] 一样,研究如何设计界面来保持高水平的 SA10
| * | # |
|---|---|
| 链接 | link. |
| 题目 | The Next Generation of Human-Drone Partnerships: Co-Designing an Emergency Response System |
| 关键字 | 参与式设计, |
| 来源 | CHI2023 EA |
使用半自动无人驾驶飞行器(UAV)来支持紧急响应场景,如fre监视和搜索和救援,提供了巨大的社会效益的潜力。然而,在这个复杂的领域设计一个有效的解决方案代表了一个
“邪恶的设计”问题,需要在无人机自主与人类控制、任务功能与安全以及不同利益相关者的不同需求之间进行权衡。本文的重点是使用场景驱动的参与式设计过程进行态势感知(SA)设计。我们开发了SA卡,描述了六个常见的设计问题,称为SA恶魔,以及三个对我们领域很重要的新恶魔。然后,我们使用这些SA卡为领域专家提供SA知识,以便他们能够更充分地参与设计过程。我们设计了一个潜在的可重用解决方案,用于在多利益相关者、多无人机、应急响应应用程序中实现SA.
[Intro]设计这种类型的系统代表了一个“邪恶的”设计问题[45,11],Rittel和Webber将其描述为一个独特的问题,没有精心制定的解决方案,多个利益相关者有矛盾的需求,没有对解决方案有效性的直接测试,并且很少有机会通过反复试验来学习[45]。解决这些问题需要设计者深入理解利益相关者的需求,确定矛盾的目标,理解随后的权衡,并最终设计一个平衡这些目标的解决方案,并在现实世界中测试解决方案[51,54]。
从历史上看,许多CPS故障起源于用户交互界面(UI)。
鉴于部署半自动无人机用于应急响应的新颖性以及随后缺乏现有的、明确定义的和可重复使用的设计解决方案,我们采用了参与式设计方法[5]。这使我们能够受益于货船的知识,发展共同的愿景,并让货船充分参与设计和验证过程.
“Wicked design problem” 是一种指代复杂、难以解决的设计问题的术语。这个概念起源于设计和规划领域,通常用于描述那些没有明确解决方案,或者解决方案本身会引发新的问题的情境。与传统问题不同,wicked design problem 具有以下特征:
多重相互冲突的需求:在一个复杂系统中,不同的利益相关者(如操作无人机的人员、应急响应团队、政策制定者等)可能有不同的、甚至相互冲突的需求和目标,很难找到一个统一的解决方案。
没有明确的正确或错误答案:wicked问题没有一个完美的或普遍正确的答案。相反,设计者往往只能做出妥协和权衡,解决某些部分的问题,可能会使其他部分变得更复杂或带来新的问题。
不断变化的条件:问题的条件或环境常常在变动,随着时间推移,可能需要反复修正和调整设计方案。对于无人机支持的应急响应场景来说,这个复杂环境可能包括技术发展、法律法规的变化、紧急情况的性质、人员的能力等多方面。

我们的工作重点是在一个漫长的社会技术CPS领域中为SA进行参与式设计11 . 虽然许多作者描述了参与式设计的研究[5,27,48],但在参与式设计和SA的交叉点上几乎没有工作,尤其是在CPS领域。Endsley[14]关于SA恶魔的开创性工作侧重于以用户为中心的设计,而不是参与式设计;然而,我们的目标是让领域专家作为共同设计师参与进来,而不是为他们设计产品。12 在一个例外中,Lukosch等人[27]探索了参与式设计在严肃游戏中的使用,这些游戏提供了一个虚拟世界环境来发展SA技能。然而,虚拟环境与应急响应的生死攸关领域非常不同.
情境感知被定义为用户在特定情境下完全感知、理解和做出决策的能力[14]。感知(1级SA)是最基本的级别,包括识别和监控元素,如人、物体和环境因素及其当前状态。理解(2级SA)建立在感知的基础上,包括通过使用模式识别、评估和解释来综合信息来描绘当前情况的能力。最后,SA的最高级别,投影(3级SA),包括理解环境的动态和未来状态的投影。有效的UI设计必须支持所有三个SA级别。
之后作者介绍了 Endsley [14]提出的SA demon在作者领域可能出现的8种情况。
有八种常见的设计错误在用户交互界面设计中经常出现,它们抑制了SA。这些被Endsley[14]记录为SA恶魔,并在下面简要讨论它们与我们领域的相关性。
D-1:注意隧道(AT)紧急情况需要对任务的当前状态有广泛的了解;然而,在快节奏的社会技术CPS环境中,用户需要不断处理来自多个来源的信息。注意隧道发生在用户将注意力集中在单个信息通道上一段不健康的时间,从而忽略了其他关键信息,并且未能执行其他重要任务[56,43]。例如,在搜救场景中,如果设计允许用户以完全覆盖来自其他无人机的状态消息的方式扩展来自一架无人机的图像流,则可能会发生注意隧道.
然后,我们使用了一组纸质原型,包括地图、视频流和物体(例如无人机、人、fre引擎),这些物体是飞机司机手动排列到他们想要的屏幕布局中的。这项活动提供了关于屏幕布局和对飞机司机特别重要的元素的一般反馈。例如,他们讨论了特定的角色(例如,事件指挥官对无人机指挥官)及其信息需求,并要求新功能来跟踪无人机和人,并在地图上标记物体,例如fre引擎或危险。We followed standard design principles based on Nielson’s [35] and Norman’s [36] principles for interaction design, as well as Endsley’s design principles for avoiding SA demons [14].
然后,作者召开了会议总结了一个use case 并且为了给专家讲解SA的概念,制定了SA卡如下图:10
方法:吸引领域专家在设计过程的早期阶段,我们认识到领域专家需要理解情境感知的概念,以便更积极地参与设计过程[20]。通过让领域专家了解SA设计概念,我们希望(1)在我们合作评估紧急设计时,他们可以提供更好的输入,(2)根据他们对SA设计的知识提供更高质量的设计建议。我们探索了不同的解决方案,并采用了两种技术:(1)使用视觉辅助工具来建立对情境感知的理解,以及(2)使用基于场景的方法来评估初步设计的情境感知。选择第一种技术是为了让我们的利益相关者能够识别和讨论SA问题,而采用场景是因为它们被证明是让用户参与需求发现和设计过程的有效性.
然后,我们系统地进行了场景演练[26],使用以下问题来触发对每个场景的讨论。•发生了什么?这个问题旨在测试SA对感知(即1级SA)和理解(即2级SA)的支持。例如,在场景S2中,我们探讨了用户是否理解通信已经丢失,后来恢复到无人机。我们还询问是否丢失了任何重要信息。•您希望能够做什么?情境感知不仅描述了当前正在发生的事情,还使用户能够根据对未来事件的预测(即3级SA)做出决策。例如,在场景S1中,当无人机检测到具有一定可信度的潜在受害者时,我们询问货船他们希望能够做什么以及他们希望无人机拥有多少自主权.你看到SA恶魔在起作用吗?为了鼓励货船评估设计,我们提出了一些探索SA恶魔的问题。例如,“如果这个场景在雨天实施,会改变你的行为吗(为什么或为什么不)?”旨在探索错误的心理模型恶魔。

AR纪念碑:案例研究、经验教训和开放挑战
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Location-based AR for Social Justice: Case Studies, Lessons, and Open Challenges |
| 关键字 | 案例研究、extended abstract 、Case Studies of HCI in Practice |
| 来源 | CHI2023 EA 优秀论文 |
技术动机
AR 的基本价值来自数字内容和物理现实的独特结合,因此“虚拟内容以引人注目且有意义的方式与现实相连”。[1] 近几十年来,AR 见证了无数的技术进步,并在商业领域多次流行起来。
然而,AR 尚未发挥其作为促进物理世界中有意义体验的工具的潜力。尽管现代 AR 系统擅长检测位置和形状等基本属性,但它们通常缺乏推断材料等物理属性或身份和文化意义等语义属性的能力。换句话说,现代 AR 系统可以理解事物在哪里,但很少了解它们是什么,也很少了解它们为什么重要。
因此,Pokémon Go 是广受欢迎使用的最著名的 AR 应用程序,其内容覆盖在现实上,但缺乏与现实的有意义的联系。其他平台(如 Google Lens)能够对对象或网站进行基本的语义理解,但目前主要是缺乏交互性和内容的参考工具。
虽然使用市售 AR 进行广义语义理解所需的技术尚不存在,但创建基于位置的 AR 体验的许多必要元素已经存在。我们使用视觉标记来触发我们设计的基于位置的体验,从而为空间的语义理解问题部署了一个临时解决方案。这使我们能够在大规模实现之前探索创建有意义的基于位置的 AR 的承诺和挑战。
考虑到技术和社会目标,我们创建了 Charleston Reconstructed 和 Dear Visitor 这两种基于位置的 AR 体验。随着技术的发展,这些案例研究的经验教训将有助于规划未来的项目。
给自动驾驶车装上眼睛提供交互性
| * | # |
|---|---|
| 链接 | link. |
| 题目 | A Field Study on Pedestrians’ Thoughts toward a Car with Gazing Eyes |
| 关键字 | 绿野仙踪法,李克量表,采访 |
| 来源 | CHI2023 |
绿野仙踪法(The Wizard of OZ)。
”绿野仙踪法“13,这个童话故事原名叫《奥兹国的魔法师》(The Wizard of OZ),讲的是小女孩被一阵龙卷风吹到奥兹国,听说要找到法力无边的法师奥兹才能帮助她回家。但是当她终于找到奥兹时,只是一个通过躲在幕后扮演巫师的小魔术师。
绿野仙踪法,强调的就是这个幕布后的小魔术师。
在这种原型测试中,交互设计师就扮演幕后的魔术师的角色。设计师不需要做有交互的动态原型,只需要做静态原型就可以。测试用户操作系统界面时,实验者(交互设计师)通过各种手段来模拟出系统效果。
用户可以 learning-by-doing*来学习一些基础教程
设置
这些问题旨在收集与汽车与行人互动中最重要的问题相关的信息,包括安全感、信任感和沟通有效性。Q1 到 Q5 是 5 个量表的李克特问题,后面是“为什么”问题。我们强调“为什么”很重要,并要求参与者尽可能多地写下他们的想法。我们收到了李克特量表的答案,包括原因(为什么问题)。
问卷
4,2 问卷的主题(归纳)分析
这些问题旨在收集与汽车与行人互动中最重要的问题相关的信息,包括安全感、信任感和沟通有效性。Q1 到 Q5 是 5 个量表的李克特问题,后面是“为什么”问题。我们强调“为什么”很重要,并要求参与者尽可能多地写下他们的想法。我们收到了李克特量表的答案,包括原因(为什么问题)。一位研究人员仔细研究了所有回复并得出了主题。第二位研究人员随后加入,进行主题讨论,回顾和总结行人对有眼睛的自动驾驶汽车的想法的主要发现。问题是:
Q1:眼睛能告诉你这辆车是不是自动驾驶吗?为什么?
Q2:眼睛能帮你了解汽车的驾驶意图吗?为什么?
Q3:眼睛能让你更信任这辆车吗?为什么?
Q4:眼睛能让你感觉到汽车在注意到你吗?为什么?
Q5:眼睛能帮你增强安全感吗?为什么?
Q6:请用一个词来形容你的眼睛看着你时的感受?
提出引导性问题可能会使结果产生偏差。我们继续以这种方式提出问题,以向他们强调他们应该只根据他们对眼睛的感觉来回答这些问题。
在社交场合利用VR给视障人士提供眼神交流
| * | # |
|---|---|
| 链接 | link. |
| 题目 | VR, Gaze, and Visual Impairment: An Exploratory Study of the Perception of Eye Contact across different Sensory Modalities for People with Visual Impairments in Virtual Reality |
| 关键字 | 李克量表,采访 |
| 来源 | CHI2023 |
问卷
在原型测试之前,有八名参与者(P3-P11,P5除外)进行了45分钟的小组讨论。五个一般问题按以下顺序被问到:(1)你如何看待社交信号?,(2)眼神交流对你有多重要?,(3)眼神交流对你来说意味着什么?,(4)你是否曾经因为在谈话或情境中无法感知凝视而感到处于不利地位?(5)你是如何意识到眼神交流的?对于个人VR设置,使用了HTC Vive Pro Eye,并使用游戏引擎Unity实施了该研究。参与者坐在桌子前的椅子上,首先被问及人口统计信息及其诊断。随后,我们向参与者提出了以下问题:(1)小组讨论中的第二个问题,(2)你是否总是试图直视你的谈话对象的眼睛?(3)小组讨论中的第四个问题。提出相同问题的原因是,参与者可能不太愿意在更大的小组环境中发表意见。之后,参与者戴上VR护目镜并拿起控制器。VR场景被嵌入到一个定制的类似咖啡馆的设置中,里面有休息室和桌子(图1a)。
将头部凝视和头部手势分开成两种输入模式14
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Classifying Head Movements to Separate Head-Gaze and Head Gestures as Distinct Modes of Input |
| 关键字 | 实验 |
| 来源 | CHI2023 |
实验
我们在这项工作中的主要目的是将头部运动分为头部凝视和头部手势,以便将它们用作不同的输入模式。之前的一项研究,BimodalGaze,探索了头部手势对凝视输入的细化,并提出了一种在凝视模式和头部模式之间切换的启发式方法,以避免与初始凝视转移相关的头部运动产生的意外输入[46]。这项工作展示了
将头部凝视与头部手势分开的复杂性。当头部支撑凝视时,它的移动速度比眼睛慢,大部分头部运动通常发生在注视已经瞄准目标时。当头部追赶时,眼睛会补偿头部运动以注视目标。在头部手势中观察到头部和眼睛的相同相对运动,其中眼睛补偿头部运动以稳定视力,因此很难区分手势和凝视驱动的行为。为了克服启发式方法观察到的局限性,我们探索了机器学习对头部凝视与头部手势进行分类。
数据收集本身是与18名参与者一起进行的,并产生了超过100万个带有时间戳的头部位置、头部方向、头部方向和世界之眼方向的样本作为分类的输入。
别的论文中关于头部和凝视协作的研究

我们认识到,协作是微妙的微观行为的结果,例如学习者的身体姿势、手势、头部方向、视觉注意力和话语。这些行为是复杂的、交织在一起的,并导致了丰富的行为编排,从而创造了复杂的社会互动。这些模式提供了用户凝视或身体姿势的“原始测量”。然后,这些数据用于捕获特定的“可观察行为”,例如联合视觉注意力 (JVA) 或身体相似性。我们可以将这些行为用作“理论结构”(Wise et al. this volume)的代理,例如,一个群体的共同点的质量(Clark and Brennan 1991)或群体成员相互模仿的程度(Chartrand and Bargh 1999)。原始测量、可观察行为和结构可用于预测感兴趣的结果(例如,小组的协作情况)、模拟协作过程(例如,社交互动如何随时间变化)、解释它们(例如,有助于协作理论)或支持协作(例如,设计使用传感器数据支持学习的干预措施)。
CITE
@article{schneider2021gesture,
title={Gesture and gaze: Multimodal data in dyadic interactions},
author={Schneider, Bertrand and Worsley, Marcelo and Martinez-Maldonado, Roberto},
journal={International handbook of computer-supported collaborative learning},
pages={625–641},
year={2021},
publisher={Springer}
}
从参与式研讨会中获取的自动驾驶汽车的整体 HMI 设计
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Exploring Holistic HMI Design for Automated Vehicles: Insights from a Participatory Workshop to Bridge In-Vehicle and External Communication |
| 关键字 | 参与式设计 |
| 来源 | CHI2023 |
参与式设计
12名与会者出席了研讨会,他们都是人机交互(HCI)和人为因素或技术咨询方面的研究人员或从业人员。他们的经验各不相同,从初级研究人员/博士生到经验丰富的教授或行业专业人士。他们的研究重点在于汽车用户界面(iHMI、eHMI和/或一般汽车人为因素),这些界面由抵达时分发的彩色徽章表示。
研讨会首先介绍了目标、时间表和预期成果。两位受邀的主讲人,专门研究iHMI和eHMI,然后概述了各自领域的技术进展。随后是第一轮全体讨论,与会者平等地表达了他们的想法、关注点或愿景,以形成对自动驾驶汽车整体HMI设计的共识。
然后将参与者分为三组进行促进小组活动。每个小组由四名成员组成,根据彩色徽章,他们的研究重点不同。在小组活动中,每个小组的任务是协作开发一个涉及多个交通参与者的交互场景,从而为整体HMI设置用例。研讨会结束时,每个小组都展示了他们的方案,然后是最后的全体会议讨论,反映了整体HMI设计方法。车间概况如图1所示。

拍摄了三个小组制定的三种方案的照片。此外,在参与者的口头同意下,所有小组活动和讨论都通过视频和音频记录进行记录。研讨会结束后,每个小组的主持人总结了讨论和创建的场景。他们通过审查和注释录音来实现这一目标,这种方法受到
定性研究中“直接分析”概念的影响[25,26]。 为了确保我们数据的可靠性,我们指派了第二位审稿人——来自不同小组的主持人——来验证注释。随后,作者对所开发的场景进行了协作分析和编码,从而提取了关键见解。
最终结论包含场景说明Scenario Description和讨论要点Discussion Highlights。15


Empathy map 同理心地图
为了帮助参与者创建考虑多个用户视角的场景,我们利用了参与式研讨会技术和一套工具包,包括详细说明和物理令牌[29]。这些说明将场景分解为四个关键组件:用户、车辆、环境设置和交互。为了定义这些组件中的每一个,我们提供了四个指导性问题
用户。考虑了两种类型的用户:车内用户和行人。定义每个用户的问题的灵感来自同理心地图[11],这是设计思维中常用的工具:
•你是谁?(例如,年龄、性别、工作)
•你在干什么?
•你在感知/听到/看到/闻到什么?
•你的心态是怎样的?
同理心地图可以用于设计者捕捉最终用户态度和行为
移情图象限
说 — 特定用户说的话。这可以是用户研究访谈的直接引用,也可以是用户可以想象说的话。
思考 — 用户可能有的想法,尤其是在整个体验过程中。用户可能认为他们没有用语言表达什么?
执行 — 用户演示的行为以及用户在体验期间执行的操作。这可能是观察到用户正在做的事情,也可能是用户可以想象做的事情。
感觉 — 用户体验到的情绪。用户遇到什么导致他们有这种感觉?
某些版本的移情图包括一个额外的部分,称为“痛苦和收获”,允许更集中地列出用户的挫折和愿望。

戴夫·格雷(Dave Gray)是同理心地图的创始人,他创建了同理心地图的更新版本,以便团队可以以更明确的目标开始练习。在这个新版本中,移情映射从回答以下问题开始:
“我们想了解的人是谁?”
“他们处于什么境地?”
“他们需要做什么?”
“我们怎么知道他们成功了?”
CITE:
@article{dam2018empathy,
title={Empathy map–Why and how to Use It},
author={Dam, R and Siang, T},
journal={Interaction Design website https://www. interactiondesign. org/literature/article/empathy-map-why-andhow-to-use-it. Published},
year={2018}
}
【29】[https://www.researchgate.net/publication/262851486_Probes_toolkits_and_prototypes_Three_approaches_to_making_in_codesigning]{https://www.researchgate.net/publication/262851486_Probes_toolkits_and_prototypes_Three_approaches_to_making_in_codesigning}

两种不同的思维模式:为设计和与设计。它们分别对应于图2中所示的“作为主体的用户”和“作为合作伙伴的用户”的观点。在这里,我们可以看到,从专家驱动的思维模式中产生的探针,举例说明了为方法而设计,并涵盖了预设计和生成组件。生成工具包tooltiks来自参与式思维模式,主要在生成阶段使用设计方法。另一方面,原型设计可以从为设计或以思维模式设计中进行,正如本期特刊中的一些论文将展示的那样。探针、工具包和原型之间的重叠区域经过精心布置,以反映我们对当前制造方法状态的看法。随着不断探索新的方法和工具,重叠领域将来可能会变得更大。


CHI2022
*远距离自动驾驶的挑战(没看完但是很重要)
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Driving from a Distance: Challenges and Guidelines for Autonomous Vehicle Teleoperation Interfaces |
| 关键字 | AV的人机交互挑战, 采访加观察 |
| 来源 | CHI2022 |
启发研究为无人机提出了一种手势集(没看完但是很重要
https://ieeexplore.ieee.org/abstract/document/8673010
通过自然的注视移位和人水平注视位移最大范围的差值来解决midas问题
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Kuiper Belt: Utilizing the “Out-of-natural Angle” Region in the Eye-gaze Interaction for Virtual Reality |
| 关键字 | Midas 触摸问题,within-participant design. |
| 来源 | CHI2022 |
水平人眼运动的最大物理范围约为 45°。然而,在自然的注视移位中,相对于头部正面方向的注视方向的差异很少超过 25°。我们将这个25°-45°的区域命名为眼睛-凝视相互作用中的“柯伊伯带”。我们尝试利用这个区域来解决 Midas 触摸问题,以启用搜索任务,同时减少虚拟现实环境中的错误输入。在这项工作中,我们进行了两项研究,以弄清楚我们如何将菜单项放置在柯伊伯带中作为眼球凝视运动的“非自然角度”区域的设计原则,并确定基于柯伊伯带的方法的有效性和工作量。
Midas问题
The eye-gaze interface is one of the promising input methods because it is fast and the eye-tracker can be naturally mounted onto the HMD. However, monomodal gaze input has a problem called the “Midas touch problem” [ 23 ]眼睛凝视界面是有前途的输入方法之一,因为它速度快,眼睛跟踪器可以自然安装到头盔显示器上。然而,单模凝视输入有一个叫做“迈达斯触摸问题”的问题[23]因此,由于无法区分出于选择或检查目的的凝视fxation,从而违背用户的意图选择目标。研究人员提出了解决这个问题的技术,例如停留时间调整[32,37,42,59]、凝视笔画手势[7,22]和平滑追求[46,58]。相比之下,这些研究降低了基于标准停留时间的眼睛-凝视界面中的误差率(Midas touch);然而,有一些缺点,如更低的错误率、更长的停留时间和/或任务完成时间。我们还通过在眼睛-凝视交互研究中利用一个称为“柯伊伯带”的新区域来解决这个问题,以实现更低的误差率和更低的停留时间.
通过结合眼睛-凝视输入和其他模式进行选择。
解决迈达斯触摸问题的一种流行方法是将凝视与其他模式相结合。用户可以通过在另一种模式中执行决策触发器时使用凝视来指示目标来避免无意的选择。其他模式包括点击鼠标[65]、做出脚手势[16]、通过牙齿开关点击[67]和使用面部肌电开关[55]。多模态交互中的显式触发器易于理解和使用。类似地,已经提出了在虚拟现实和磁共振中结合凝视和其他输入界面的各种方法,特别是基于头部运动和凝视的结合[49]。眼睛和头部运动的组合作为一种输入方法适用于虚拟现实和磁共振,因为眼睛和头部运动都可以很容易地与HMD同时跟踪,并且用户可以在不使用任何一只手的情况下指向和选择目标
使用停留时间的选择方法。
在单模凝视界面中,最常见的方法是当凝视停留在目标上一定时间时选择目标。当停留时间设置为150毫秒时,凝视输入比鼠标[47]实现了更快的目标选择。另一方面,缩短停留时间导致频繁的错误输入,因此每次研究眼睛打字[34]的停留时间都设置为450毫秒到1000毫秒之间。由于停留时间越长,运动时间越长,以解决迈达斯触摸问题并减少停留时间
目标和标签的分离。
这些研究采用了外部任务,其中要选择的目标要么清晰突出显示,要么像打眼键盘一样在视觉和位置上进行固定。然而,对于复杂但实际的任务,用户必须在各种对象中视觉搜索所需的和位置上未固定的目标对象;我们将此目标选择任务称为“视觉搜索任务”。张等人认为复杂的视觉搜索增加了所需的停留时间[66]。实验任务是从七个候选目标中选择一个带有特定标签的目标,每个目标内部都写有标签。当视觉搜索困难且停留时间为1100毫秒时,该实验的错误率为16.9%。Pfeufer等人还认为,1000毫秒的停留时间对于视觉搜索任务来说是不够的(错误率为9.72%),2000毫秒的停留时间更可取[40]。因此,当任务难度很大时,设置较长的停留时间不足以解决点石成金的触摸问题
实验
We used a within-participant design.
参与者设计 within-participant design
在心理学和实验设计领域,“within-participant design” 是一种实验设计,其中每位参与者都参与所有的实验条件或处理条件。与之相对的是"between-participant design",在这种设计中,参与者被分配到不同的处理条件下,以便比较它们之间的差异。
在"within-participant design"中,每个参与者都会经历不同的实验条件,通常是在不同的时间点或不同的情境下。通过在同一参与者身上收集数据,这种设计可以减少参与者间的变异性,从而提高实验的统计功效。
举例来说,如果研究人员想要测试一种新的记忆训练方法,他们可能会使用"within-participant design",其中每位参与者都会接受这种训练方法和标准训练方法。这样,研究人员可以比较同一参与者在不同训练方法下的表现,而不必担心个体差异对结果的影响。
错误率、身体舒适度、精神舒适度和美国航天局-TLX问卷项目
因变量是错误率、身体舒适度、精神舒适度和美国航天局-TLX问卷项目。如果选择了不正确的菜单项或试验时间超过5.0秒,则该试验被认为是错误的。身体和心理舒适度问卷量化了用户的舒适度(身体和精神)在iRelance和iDirection的每个组合中的变化,参考[62]。为了收集数据,在精神和身体舒适度方面使用了5分量表(从1“强烈同意”到5“强烈不同意”)(“我在指向任务完成后感到精神或身体疲劳。”)。最后,我们使用了美国航天局任务负载指数(美国航天局-TLX)[15]问卷来评估每个iRelance的工作量。
NASA_TLX:https://www.wjx.cn/m/75064257.aspx

过程和任务
首先,我们欢迎参与者,然后向他们简要介绍了这项研究。所有参与者都提供了书面和知情同意。我们使用图形图像提供了详细的任务说明。参与者对HTC Vive Pro Eye上最初安装的程序进行了5点眼动追踪校准。所有参与者在主要课程之前都进行了练习;练习课程使用了不同的参数(iRelance=10°)。
划重点:他们不仅定义了这个KB这个环,还找到了环内设置点击按钮更好的位置Idirection/大小Idistence。比较2SS,HG和KB三个界面。设计了三个usecase

CHI2021
凝视辅助触摸选择
| * | # |
|---|---|
| 链接 | link. |
| 题目 | GazeBar: Exploiting the Midas Touch in Gaze Interaction |
| 关键字 | Midas 触摸问题 |
| 来源 | CHI2021 |
还没看这篇论文
无人机人机交互访谈给出设计意见
What Matters in Professional Drone Pilots’ Practice? An Interview Study to Understand the Complexity of Their Work and Inform Human-Drone Interaction Research
*还没开始看 这周开始看
CHI2020
使用移动刺激方法的轮廓高亮提示来解决遮挡问题
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Outline Pursuits: Gaze-assisted Selection of Occluded Objects in Virtual Reality |
| 关键字 | 使用移动刺激方法的轮廓高亮提示来解决遮挡问题 眼动 |
| 来源 | CHI2020 |
还没有看但是很重要

Intro: 不考虑模态,遮挡是VR环境中选择的主要问题。根据用户的观点,在不同深度渲染的对象可能会出现重叠,甚至完全遮挡。这减少了指向的目标区域并增加了
选择模糊性,因为输入准确性受到用户运动技能(例如手抖[47]、眼睛fxations[26]中的自然抖动)以及传感设备的f-快感和精度的限制。缓解策略是让用户改变他们的位置以改善他们对预期目标的看法。然而,这增加了工作量,当用户坐下时是一个有限的选择,并且对于仅跟踪头部旋转运动但不跟踪空间平移的便携式VR系统(例如Oculus Go和FOVE)是不可能的。
概念是显示位于用户指向的方向上的对象的轮廓,并在每个轮廓周围产生不同的运动。然后,用户可以通过用眼睛跟随他们预期目标周围的运动来消除选择的歧义。轮廓追踪利用用户看着他们想要选择的对象,人类很自然地跟随显示的运动,相应的平滑套装眼球运动。以前的工作表明,平滑追逐对选择非常有效,因为这是一种自然的闭环行为,我们的眼睛只有在受到移动刺激时才会表现出来[28,43]。平滑追逐可以被稳健地检测到,因为它不同于扫视眼球运动,相关目标可以通过运动相关性推断[40]。追踪技术不需要将眼睛注视与显示坐标进行任何校准,因为它基于用户的注视与目标的相对运动进行匹配[43],并且出于同样的原因,也与目标的大小无关[10]
轮廓追踪可以与任何指向模式相结合。我们介绍了两种特殊技术,一种用于免提选择,另一种用于用控制器增强指向。在免提轮廓追踪中,潜在目标通过头部指向识别,然后平滑地追踪生成的轮廓之一。在这种技术中,轮廓追踪不仅消除了目标的歧义,还用于最终选择确认。这有一个优点,即用户可以自由地将手用于其他任务或休息它们(例如避免gorilla arm(*大猩猩手臂”是指使用垂直或站立式触摸屏的人感到疲劳或手臂开始受伤,因为需要笨拙且不太符合人体工程学的定位。*)[13]),同时解决免提替代方案的可用性问题,例如选择的不自然停留时间。
待看无人机搜救系统设计
| * | # |
|---|---|
| 链接 | link. |
| 题目 | The Next Generation of Human-Drone Partnerships: Co-Designing an Emergency Response System |
| 关键字 | SA相关,人控制和自主控制的平衡,系统设计 |
| 来源 | CCFA |
ECSCW
用参与式设计来帮助老年人融入数字化的社区
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Making online participatory design work: Understanding the digital ecologies of older adults |
| 关键字 | 参与式设计 |
| 来源 | CCFB |
参与式设计Participatory Design与访谈
关于采访在论文中的记录示例(研究人员的表情也可以记录)
在介绍这项任务时,我们鼓励老年人自己在米罗导航,因为在最后一次汇报中,他们表示希望在我们的研讨会期间能够自主地完成更多任务;此外,这也符合项目的总体目标(支持老年人在数字工具方面变得更加自主)。

别的文章中参与式设计实验方法(Heuristics任务诱导)
| * | # |
|---|---|
| 链接 | link. |
| 题目 | User-defined gesture interaction for in-vehicle information systems |
| 关键字 | 参与式设计,手势诱导 |
| 来源 | Multimedia Tools and Applications (CCFB) |
Abstract:传统的手势启发研究往往受到手势分歧和遗留偏见问题的困扰,可能无法为目标系统生成最佳手势。本文报告了一个关于用户定义的手势与车载信息系统交互的研究项目。
我们研究的主要贡献在于我们提出的三阶段参与式设计方法,该方法比传统的手势激发方法更可靠。使用这种方法,我们为车载信息系统中的次要任务生成了一组用户定义的手势。根据我们的研究,我们制定了一套手绘手势设计的设计指南。我们强调了这项工作对所有手势界面的手势启发的影响。
Intro:尽管许多实证结果表明了手势交互的好处,但在车载信息系统基于手势的手绘交互设计中仍然存在一些未解决的问题和悬而未决的问题。
例如,许多系统都是根据专业设计师选择的手势设计的,最终用户几乎没有机会参与设计过程。这种做法可能导致设计者想象的手势和最终用户实际执行的手势之间的手势不一致问题[59]。最近,启发研究(一种从参与式设计领域兴起的方法)已被广泛用于通过让真实用户参与手势设计过程来收集需求和期望。12然而,这种方法存在遗留的偏见问题[32],即最终用户的手势建议往往受到他们自己的偏好或对先前用户界面的体验的偏见,例如WIMP(窗口、图标、菜单、指点设备)界面或基于触摸的用户界面。因此,传统的手势启发研究可能经常被困在局部最小值中,无法发现可能更适合给定目标任务的手势。
Contribution:我们的工作与早期关于手势诱发的努力不同,在考虑在先验阶段推导两个手势,并在传统诱导研究的后验阶段分别为每个目标任务选择前两个手势。实验结果表明,所提方法能够有效缓解手势不一致问题,抵消手势诱导研究中用户遗留的偏差。
[34] The set of gestures in an interface is called the “gesture vocabulary”. 界面中的手势集称为“手势词汇表”。This should not be confused with a general non-verbal communication dictionary. There are several ways of labelling gestures. This paper uses the taxonomy presented by Justine Cassell [1].
重要的是要记住,手势界面应被视为现有界面技术的补充或替代,如旧的桌面范例。其他例子是鼠标的新替代品,如人体工程学轨迹球、鼠标笔和iGesture Pad[9]。它们都可以用鼠标光标在视窗界面上导航,就像鼠标一样或比鼠标更好,而在快速电脑游戏中,如3D射击游戏和飞机模拟器,它们可能或多或少是无用的。开发手势界面时,目标不应该是“制作一个通用的手势界面”。手势界面并不是任何应用程序的最佳界面。目标是为给定的应用程序“开发一个更有效的界面”。手势研究[1]表明,不存在通用手势,因此一个好的手势词汇可能只匹配一个特定的应用程序和用户群。16
选择手势有两种方法;基于技术的方法和基于人的方法。选择手势的技术方法是选择一组易于识别的手势。它从一种可以识别某些特定手势的方法的想法开始。就像作者所在部门的一个例子,该方法计算伸出手指的数量。一旦建立了这个手势词汇,下一步就是将它们应用于应用程序。这种技术方法的问题是,一些手势对一些人来说是有压力的或不可能执行的。此外,功能和手势的映射不合逻辑。要问的一个重要问题是文化依赖是否是一个问题。便利的国际界面通常是英语的,但是大多数软件都有可选择的国家语言包,一些国家有不同的键盘布局。在手势界面中,如果徽章[1]对另一种文化来说是不合逻辑的,这可以翻译成可选择的手势集。此外,如果使用文化上依赖的手势,这并不一定意味着其他文化学习它们是完全不合逻辑的。
基于人类的手势方法调查将要使用界面的人。绿野仙踪实验已被证明在手势[10]的开发中很有价值。这些实验通过让一个人对用户命令做出反应来模拟系统的反应。13寻找手势的方法:在接口开发中,场景已被证明是有价值的,
[21]可以定义上下文、功能,并调查用户和问题域17。这种方法的一个工具是通过准备脚本来检查这些场景中的人与人之间的非语言交流。受试者将被带到场景中,这样他们就可以像与计算机应用程序交流一样与人交流。第2.1节的九个可用性启发式中的第1点和第2点支持手势必须通过观察自然手势来选择的观点,但也表明受试者必须是指定用户组的一部分。这项调查有两种方法:自下而上和自上而下。自下而上获取功能并找到匹配的手势,而自上而下呈现手势并找到哪些功能在逻辑上与手势匹配。另一个需要的工具是一个基准,通过基于人的方法中重视的原则来衡量手势的优劣18
寻找手势的过程:
1.找功能。查找应用程序所需的功能以及手势必须传达的功能。记住标准界面的现有类似应用程序的用户界面。
2.从用户领域收集手势。目标是找到代表步骤1中找到的功能的手势。这是通过对人的实验来完成的,方法是让他们在摄像机监控下经历场景,在这些场景中,他们交流上述功能,否则他们会将这些功能传达给计算机,例如“算子”(即进行实验的人)或另一个考生。重要的是要设计实验,让被测试者以自然的方式使用手势,尤其是在与有技术头脑的人进行测试时。否则,他们仍然有可能从接口和算法的角度思考。如果希望编写一个具有技术接口方面的场景,可以作为绿野仙踪实验[3][10]来执行,该实验不仅测试手势,还测试整个界面的设计,包括来自系统的反馈和接口中的顺序。这项调查所需的人数取决于用户群体的广度以及测试结果的多样性。
3.评估。对视频记录的数据进行评估,以提取受试者在互动中使用的手势。注意并捕捉常用手势的帧,并注意不同受试者使用它们的一致性。参考上面图片的要求。
4.测试。 对选定的手势词汇进行基准测试最后一步是测试由此产生的手势词汇。这可能会导致手势词汇的变化。测试有三个部分。以下内容将在基准测试中进行测试:语义解释、概括、直觉、记忆、学习率和压力。最低的分数是最好的。①测试1:猜测功能给考生一份功能列表。呈现手势,并要求这个人猜测功能。依赖于上下文的手势必须在上下文中呈现。分数=错误除以手势数量②测试2:记忆将手势词汇交给考生,然后考生将尝试手势以确保它们被理解。快速展示功能名称的幻灯片,每个功能2秒。考生必须在显示名称时正确执行它们。顺序应该符合应用程序中的顺序。每次误拍时重新启动幻灯片,并在每次重试之间向考生显示手势词汇。继续,直到它们全部正确。分数=重新启动的次数。③测试3:压力这是对人体工程学的主观评估。给出手势序列的列表。考生必须执行序列X次,其中X乘以手势词汇的大小等于200。在每个手势之间,回到中立的手位置注意它们有多紧张。为注释留出空间,以说明是否是某些手势造成了压力。对每个手势和整个序列使用以下分数列表: 1)没问题。2)轻度疲劳/压力。3)疲劳/压力。4)非常烦人。5)不可能基准可以用来比较两个手势词汇,但是测试2只有在词汇大小相同的情况下才具有可比性。如果测试单个词汇,必须说明合理的成功标准。这些目标取决于手头的手势词汇。请参阅第4节步骤D如何在实践中做到这一点。它也可以用来比较不同的用户配置文件和测试文化依赖。
基于人类的体验测试。首先是确定需要几种功能。为了涵盖有意识和潜意识的自上而下的调查,为用户测试选择了三种场景,下面概述了这三种场景–



[34]这篇论文给了一个示例关于引导手势并且评估
@InProceedings{10.1007/978-3-540-24598-8_38,
author="Nielsen, Michael
and St{\"o}rring, Moritz
and Moeslund, Thomas B.
and Granum, Erik",
editor="Camurri, Antonio
and Volpe, Gualtiero",
title="A Procedure for Developing Intuitive and Ergonomic Gesture Interfaces for HCI",
booktitle="Gesture-Based Communication in Human-Computer Interaction",
year="2004",
publisher="Springer Berlin Heidelberg",
address="Berlin, Heidelberg",
pages="409--420",
}
*诱发性研究的局限性有 19
首先,由于
启发研究的开放性,来自最终用户的手势建议可能非常多样化,期望最终用户能够直观地为给定的目标任务产生相同的手势是不现实的。这是因为他们的手势建议可能依赖于他们的个人偏好以及对先前界面和技术的经验。
其次,在传统的启发研究中,仍然缺乏关于应考虑的最小手势数量的一般设计指导。在大多数情况下,参与者被要求为给定的目标任务提出一个手势。然而,这种方法经常受到“遗留偏见”问题的困扰,即参与者不一定能回忆起给定目标任务的最佳手势。这可能会导致启发研究陷入局部最小值,并且无法发现一些可能更适合给定目标任务的潜在手势。有时,当参与者看到其他设计师提出的一些手势候选者时,特别是一些高度可教的手势,他们可能更有可能改变主意并使用它们[10,59]。 为了降低在早期设计阶段拒绝有前途的手势候选者的风险,Morris等[32]和Chan等[7]应用启动和生产技术来抵消遗留偏见,其中参与者被要求为给定的目标任务设计至少三个手势。
第三,传统的启发研究采用了Wobbrock等[57]的一致公式,对来自最终用户的相同手势进行分组和排序,然后遵循“赢家通吃”策略,将顶部手势分配给给定的目标任务。通过这种方法,最终生成了一组规范的引出手势。与“赢家通吃”技术相反,Seyed 等[44]通过选择至少三个不同参与者为每个目标任务提出的手势来确定最终的手势集。然而,这些方法面临着在手势设计的早期阶段拒绝一些具有较低一致性分数的潜在流行手势的风险。例如,Choi等[10]进行了一个三阶段实验,发现在第一个实验中得出的一些顶部手势在第二个和第三个实验中很少甚至没有被选中,而在前两个实验中产生的一些独特但高度可教的手势被选为第三个实验中的顶部手势。一般来说,不同实验之间顶部手势的变化率为66%。他们的研究结果表明,手势的频率并不一定保证手势的受欢迎程度
第四,基于手绘手势的交互仍处于起步阶段,目前还没有“标准”设计。因此,对于任何给定的应用域和交互上下文,都没有正确或错误的手势。不同的研究人员在不同的条件下可能会采取不同的策略并产生不同的结果。
为了解决运行手势启发研究和分析其结果(即参与者提出的手势)的问题,目的是优化推荐手势集。我们进行了一个三阶段的用户研究,并提出了以下假设来确定问题:
H1:要求参与者为每个给定任务提出 2 个手势可能会发现一些潜在的流行手势,由于遗留偏见问题,参与者可能无法回忆起这些手势。
H2:使用协议公式[50,57]对手势提案进行分组和排序后,为每个给定任务选择前两个手势,可以缓解手势分歧问题,从而提高参与者之间的共识水平。
学习曲线怎么评价 12
“学习曲线较为陡峭” 是一个比喻,表示用户在学习某个新技能或工具时,需要花费较多时间和精力才能熟练掌握。这通常意味着系统或界面设计的复杂性较高,用户初次接触时需要较长的适应期,或需要较多的培训才能有效操作。
在你希望证明交互方法的学习曲线不陡峭时,可以从以下几个方面进行论证,并提供数据和证据支持:
- 定义学习曲线
首先,你需要明确"学习曲线"的定义。可以通过以下内容来解释:
学习曲线描述了用户在使用系统时,随着时间推移和操作经验积累,用户对系统掌握程度的变化。
陡峭的学习曲线意味着用户需要投入大量时间和学习才能熟练掌握,而平缓的学习曲线意味着用户能够相对快速地上手并有效操作。
2. 制定衡量学习曲线的指标
你需要定义具体的指标来衡量交互方法的学习难度,这些指标可以通过实验或用户测试来收集。常见的学习曲线指标包括:
初次完成任务的时间:用户首次执行任务时需要花费的时间,时间越短,学习曲线越平缓。
错误率:用户在初次使用和多次使用后犯错误的次数。错误率的快速降低也意味着学习曲线不陡峭。
用户自我评估:通过问卷或访谈,收集用户对系统的直观感受,包括对易用性和学习过程的评估。
重复任务的效率提升:通过用户多次重复某些操作后效率的提升来评估学习曲线。如果用户的效率提升较快,说明学习曲线较为平缓。
3. 设计用户实验验证
在论文中,你可以设计实验,邀请用户参与使用你的无人船控制界面,并收集数据以验证学习曲线的平缓性。实验设计时,可以分为以下几个步骤:
用户分组:将测试参与者分为新手用户和有经验用户两组,以对比两类用户的表现。
任务设计:让用户在无人船控制界面上完成一系列典型任务,例如简单的船只导航、任务规划等。
数据采集:记录用户初次操作时的完成时间、错误次数,并在经过几次任务练习后再记录数据。还可以通过用户反馈调查评估操作的易用性。
4. 展示实验数据
在论文中,使用实验结果来量化学习曲线的平缓程度。你可以通过以下方式展示结果:
图表:通过绘制学习曲线图,横轴为操作次数或时间,纵轴为用户的任务完成时间或错误率。若曲线在早期迅速下降,说明用户掌握系统的速度较快,学习曲线较为平缓。
对比分析:将新手用户和有经验用户的学习曲线进行对比,展示新手用户能够快速缩小与经验用户之间的差距。
用户主观评价:结合问卷调查或访谈,展示用户在多次操作后对界面易用性和上手难度的评价变化。
5. 结合理论背景
在论文中,你可以引用已有的人机交互理论和学习曲线模型来支持你的论证。例如:
Fitts’s Law(菲茨定律):用于解释用户在视觉反馈界面中进行点选操作的速度与界面设计之间的关系。平滑且符合直觉的操作界面能够减少用户的操作时间,进而证明学习曲线不陡峭。
Hick’s Law(希克定律):该定律指出,用户的反应时间与可供选择的选项数量成正比。简化界面操作流程和减少复杂度可以缩短用户的决策时间。
可用性五要素模型(Usability Heuristics):如简化、可见性和反馈等原则,可以论证如何设计出直观且易学的界面,帮助用户快速掌握系统操作。
6. 案例支持
你可以结合无人船的具体使用场景,展示界面交互设计如何帮助用户快速上手。例如:
通过减少操作步骤和降低操作复杂度,让用户可以在短时间内完成任务。
利用界面反馈和视觉提示帮助用户及时纠正错误,避免新手频繁操作失误。
车载信息系统徒手手势研究 (论文中可能也需要做相关的手势综述
HCI中基于gesutre的相互作用的启发研究5
不幸的是,仍然缺乏一般的设计指南。上面提到的大多数手势都是由HCI专业人员设计的,并且与相应的任务任意关联[61]。此外,最终用户几乎没有机会参与设计和开发过程。因此,此类系统可能无法识别用户自然执行的手势,因此面临系统可用性差和用户接受度低的风险。
为了解决这些问题,一些以用户为中心的设计 (UCD) 方法已被用于调查最终用户的行为。例如,Nielsen等[34]提出了一个四步程序,从以用户为中心的视角推导出HCI的合理手势。在此过程中,最终用户参与了手势设计和生成的手势集的评估。Löcken等[26]扩展了Nielsen等人的工作,并推导出了一组用户定义的手势来控制音乐播放。与Löcken和Nielsen等人的工作相反,Wu等[58]提供了一种以用户为中心的四阶段方法,用于设计基于手势的手绘用户交互,该方法要求最终用户参与整个手势开发生命周期,包括手势定义、手势派生、手势开发和手势评估。实验结果表明,通过让实际终端用户参与到最终系统的实际场景中,可以提高手势识别的准确性和用户满意度。
为了更好地了解最终用户最喜欢哪种类型的手势,一些研究人员进行了手势诱导研究,以探索最终用户偏好和个性化行为的规律。在这种方法下,最终用户会单独看到给定目标任务(也称为参照物)的预期效果,然后需要设计一个手势来实现该效果。因此,从最终用户的所有建议中选择顶部手势,然后分配给相应的目标任务。
在传统的手势启发研究中,由于手势分歧问题,很难确定最终用户最流行的手势[59]。为了解决这个问题,已经进行了一些研究工作,以衡量最终用户在多大程度上同意为给定目标任务选择的最自然的姿态。例如,Wobbrock等[56,57]提出了一种协议度量,即使用协议分数来分析来自最终用户的手势建议。Findlater等[16]、Morris等[31]和Vatavu等[50,51]进一步扩展了这一协议措施。 通过这种方法,设计人员可以使用协议分数来衡量最终用户为给定任务选择相同手势的可能性:协议分数越高,拥有相同手势的可能性就越大。因此,这些一致性测量方法已被标准启发研究广泛采用。
定性研究 (componental qualitative research )
https://www.scribbr.com/methodology/qualitative-research/
定性研究的策略:
- 叙事探究
- 现象学
- 扎根理论
- 民族志
- 案例研究

访谈的流程


如何确定你的用户样本量
https://www.woshipm.com/user-research/648261.html
你可以在滚动的基础上去决定你的定性研究的样本量。也可以在调研前就先阐明样本量。
你对滚动或先决样本量的使用将决定你如何解释为什么你终止了数据收集。对于滚动样本,你可以说:“我们在分析之后,发现收集更多的数据将不再出现有价值的样本,因此终止了数据收集。” 如果你使用了先决样本量,你可以说:“在访谈了我们预先决定的数量的受访者之后,我们停止了数据收集,并对收集来的数据进行了充分的分析。”
我们使用先决样本量的时候依然能维持一个严谨的流程,它的发现依然是有效的。数据饱和帮助我们确保了这个结果。在使用先决样本时,为了阐明你已经尽职地完成了确定样本量的调查和达到数据饱和,你需要完成这3个步骤:
在有意义的基础上去决定样本量;
达到数据收集的饱和;
达到数据分析的饱和。
数据饱和是来源于学术调研的一个概念。学者们对饱和的定义也是各执己见。最基础的理念是获取足够的数据来支持你所做的决定,然后穷尽你所需要分析的数据。为了创造一个有意义的问题和推荐你已经详尽无疑的数据分析,你需要获取足够多的数据。达到数据饱和取决于你具体的数据收集手段。访谈通常被用来做为最能保证达到数据饱和的研究手段。
研究人员通常不单独使用样本量作为评估饱和的标准。我支持其中一个双管齐下的定义:数据收集的饱和与数据分析的饱和。在研究当中,你需要满足两者的饱和。你也需要在进行数据收集和分析的同时,了解你在调研结束前是否已经达到饱和。

当你创建了一个问题大纲时,让他人帮你优化和提供反馈,并且事先演练一下数据收集,这样可以帮助你收集到丰富的数据。
关于数据收集的饱和:收集了足够有意义的信息来定义主要问题和做出推荐方案。你从调研结果中有了一个可行的解决方案:建立一个强调透明化和个人联系的初次使用体验。而且它仅仅在你访谈了12个受访者后就得到了。你完成了剩下的3个访谈来验证你已经了解到的东西,并为下一部分的“饱和”储存了更多数据。
关于数据分析的饱和:你需要对你的数据进行提炼(data coding:定性研究中将收集到的信息整理、归纳、分类、概括的数据分析方法。)。你可以归纳性地提炼(基于数据显示的信息),或者演绎性地提炼(预先决定好的提炼方式),试图确定数据中有意义的问题和要点。当你完成了所有数据的提炼和根据提炼的数据确定了问题时,你就让数据分析饱和了。这也是研究员的经验发挥作用的地方了。经验会帮助你更快地确定和提炼有意义的问题,然后将他们转化成可行的推荐方案。
焦点小组

Focus groups焦点小组
The emphasis is on both the interaction between individuals and the AND content of what is discussed.
重点是与会者之间的互动,和他们交流的内容。 Inspired each others.互相的启发和提示
Pros:
1,quick and easy. “idea generation”.效率高。
2, similarities & differences in the participants’ opinions and experiences can be gathered directly. Observe how individuals are influenced by others’ opinions.相同与差异可以直接察到,以及相互的影响。
3,与会者釈极性高因为感受“家”身份。participants can feel empowered as they are treated as experts.
4,与会者不需要立刻的回复,有思考时间。participants are not required to provide immediate response.
5,尤其合中国当人们不慣独立对待particularly appropriate in collectivistic societies, people are comfortable in a group when being asked about opinions.

Focus groups焦点小组(contd)
缺点Cons:
-
容易圧制某些人的双点。特別是害羞的和不善于公话的人。 Group discussions can suppress individuals with exceptional views or unusual experiences. Esp. shy members, less confident members; esp. collectivist societies where hierarchy, seniority and harmony are priorities in a social encounter.
-
有时容易不好把控方向。May hard to control direction as the group research is
flexible and opened. -
整组不怎么参与可能会需要研究人员过多的介入,被視为“被汚染的” The interactions of a group discussion can be seen as “contaminated” as focus groups are controlled by the researcher.
-不利于建和谐的交流环境 。Are not allowed researcher to develop rapport with respondents.
民族志
https://www.scribbr.com/methodology/ethnography/

民族志的核心是从内部观察群体。在沉浸在环境中时,会记录这些观察结果;它们构成了最终书面民族志的基础。它们通常是手写的,但其他解决方案(例如录音)可能是有用的替代方案。
现场笔记记录了所有重要数据:观察到的现象、对话、初步分析。例如,如果你正在研究服务人员如何与客户互动,你应该写下你注意到的关于这些互动的任何信息——肢体语言、反复使用的短语、员工之间的差异和相似之处、客户的反应。
多案例分析之ANT理论
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Making Sense of Maritime Simulators Use: A Multiple Case Study in Norway |
| 关键字 | ANT定性分析 |
| 来源 | Original research |
行动者网络理论(ANT,Actor-Network Theory)是社会学和科学技术研究中的一种理论框架,由布鲁诺·拉图尔(Bruno Latour)、米歇尔·卡隆(Michel Callon)和约翰·罗(John Law)等学者提出。ANT的核心思想是,将社会和技术视为相互交织的网络,任何社会现象都是由人类与非人类(技术、物品、概念等)行动者共同作用的结果。
ANT的基本概念:
行动者(Actants/Actors):
在ANT中,行动者不仅限于人类,还包括任何能够影响其他实体的非人类,如机器、技术、文本、规章制度等。每个行动者在网络中都有自己的作用和意图。
网络(Network):
行动者之间的关系构成了一个网络。这个网络不是静态的,而是动态的,随着不同行动者的互动和关系变化而不断重构。网络中的每个节点(即行动者)都依赖其他节点来维持其地位和功能。
翻译(Translation):
翻译是指行动者将其他行动者纳入其计划、定义和解释的过程。在这个过程中,行动者试图调动资源、影响其他行动者并建立联盟,以实现特定的目标。翻译过程通常包括问题化(Problematization)、利益化(Interessement)、入驻(Enrollment)和动员(Mobilization)四个阶段。
黑箱(Black Box):
当一个网络的运作变得稳定且被广泛接受时,它会被“黑箱化”,即其内部复杂的关系和动态被隐藏,人们只关注它的输入和输出,而忽略了中间的过程。
住宅老年护理丰富技术设计的关键考虑因素:一项人种学研究
| * | # |
|---|---|
| 链接 | link. |
| 题目 | Key Considerations for The Design of Technology for Enrichment in Residential Aged Care: An Ethnographic Study |
| 关键字 | 民族志 |
| 来源 | CHI23 |
数据分析
数据分析流程
出自哔哩哔哩up主:Dr_RaymondXia
https://www.bilibili.com/video/BV1HU4y1F779/?spm_id_from=333.999.0.0&vd_source=d73bcadcbd9e57a79d4f2d6f16be5b41



*注意 所有研究都有偏见,一定要坦诚阐述自己的偏见。

开放编码-主轴编码-选择性编码



如何呈现你的分析发现
- 比较表
- 描述性表格
- 分层树
- 附图
- 手绘图
如何报告分析发现
- 从每个主题的多个视角出发
- 隐喻和类比
- 引用原话
- 具体细节
- 紧张和矛盾
主题研究
https://www.scribbr.com/methodology/thematic-analysis/


| * | # |
|---|---|
| 链接 | link. |
| 题目 | Reflexivity of Account, Professional Vision, and Computer-Supported Cooperative Work: Working in the Maritime Domain |
| 关键字 | 民族志 专题分析 |
| 来源 | PACM HCI |
我使用专题分析方法[57]分析了访谈和观察数据。我的目的不是从经验观察中提取理论见解,而是理解实践的细节,我对采访笔录和观察笔记进行了编码。手工(从2015年开始)。任何可识别的参与者信息都是匿名的。视频分析[40]仅用于解决需要详细审查以构建我的分析账户。如果一个视频脚本特别有趣,我用iMovie来模糊参与者在公开呈现视频之前面对并处理他们的声音(例如,与船东)。船东有可能会认出我在海上跟踪的经营者;然而,因为我的工作是调查所有海洋系统的设计我观察到的工程项目,我选择的视频只解决了我观察到的差异在海上和模拟器室操作员的工作实践之间,这些工作实践,是操作员更大工作实践的片段浓缩成几分钟,所以他们船东用来评估经营者的表现是不合适的。可能识别船上物品,如个人物品、标志、咖啡机和笔,被模糊以进一步保护操作员的匿名性。只有他们的工作实践和他们互动的系统可以观看。
随手插入一些概念性的笔记


一些后记
关于去码头整点薯条。在读博期间能带给我平静和幸福的只有二次元和动物了。(先暂时抛弃一下游戏,因为打游戏的时候我竟然也会内耗,觉得我把别人学习的时间都用来打游戏了,也没见打得多好。但其实这是由于一切的痛苦都源于彻底的不摆烂)。所以为什么是二次元和动物呢,可以这么说,我这一生,爸妈没有特别认同我,学术没有认同我,但是我在二次元和动物中获得了没有要求的接纳和认同。在漫展中,只有同好,没有人会问你科研做得怎么样。在猫猫狗狗眼里,你是会陪他们玩,会每天在外面打猎带回丰富猎物的人类。科研的失败不会影响你在猫猫狗狗面前的形象。所以,让我能在枯燥高压的科研生活走下去的就是去漫展和撸猫猫狗狗,他们会永远喜欢你,无论你的科研做得有多烂。甚至,我有想过退学后全职干二次元或者去干宠物店。但是我发现,如果我退学,就没有稳定的工资来养宠物和去漫展;如果不退学的话,就很难抱着很好的心情(总会带着科研没做完的焦虑和遇到问题的挫败)和完整的时间来养宠物和去漫展。这何尝不是放下剑就不能抱起ta…
此处放一段我很喜欢的话(98,不愧是你文艺b,虽然《死神》结局烂了(我个人觉得),但是卷前诗写得是真的好)
剣を握らなければ おまえdaoを守れない
如果我手上没有剑,我就无法保护你
剣を握ったままでは おまえを抱きしめられない
如果我一直握着剑,我就无法抱紧你
【后续】关于猫咪。已经在小红书创建流浪猫救助个人账号啦——苏州流浪猫博士后流动站。有兴趣的小伙伴可以移步小红书关注一下,欢迎来云吸猫!希望所有的流浪小猫都能有一个心软的神给他们一个温暖的家。自从建立这个救猫账号以来,真的收获了特别多的温暖和爱,有义卖时偷偷多付钱的姐妹,有把一大堆手工制品直接赠与连成本费都不需要我掏的美术老师,有把自己门店的商品放在我这里寄售只收很少手续费的主理人姐姐,有愿意只收10块钱稿费的画手太太,还有第一个支持我建立账号一直陪伴我把账号做下去的亲友。在救猫这条路上,我感觉虽然还没走多久,但是真的收获了特别特别多的帮助,这段时间从陌生人上收获到的温暖比我过去的二十几年收获到的还多。我朋友的原话:“这一路真的走得特别顺,特别的不真实。”写到这里的时候,眼眶已经湿润了,不知道为什么就是特别想哭。我想,或许是,科研这条路我走得真的特别不顺,在科研遇到了好多精致的利己主义者(当然也遇到过特别好的人,但是比例来说比较低)。换了一个赛道,每天都有正反馈,有很多好心人跟我分享领养细则应该怎么优化,做手工把热熔枪用到冒火星有好心人二话不说把自己的手作拿来义卖并且手工费全部捐出,每一步都有很多很好的人愿意托举我(或者说给救助这件事添柴生火)。真的特别幸运遇见了流浪的小咪,特别开心他们能赖上我。从现在开始,要好好做科研,好好生活下去,这样就能给更多猫咪一个家,毕竟这只猫咪在乎,那只猫咪也在乎。
关于科研。把“科研是一个巨大的草台班子”在心里默念三遍。都到这一步了,其实我们心里都明白,做科研有的时候就是选择大于努力。好的组就是顺风顺水,坏的组一穷二白可能就是白努力。所以作为学生来说,避免焦虑的最好方法是别从自己身上找原因,多责怪别人,课题不行环境不行反正不是自己人不行。(虽然我自己也没做到就是了。)关于一个成功的科研,我认为的排序是:运气,导师的支持,天赋和个人的努力。我的感悟是绝大部分人天生是没有科研能力的,都是后天培养的。那么多发好文章的人,大部分都不是天才。研究生是一颗种子,生长的土壤很重要。
2024.8.29作为跟班跟隔壁组的一个宝可梦同好去了合作研究院体验了一下他的科研课题,突然感觉我做的东西确实不像是科研,科研就该在这种环境中做,老师一周一次的例会单独指导,提供合作的研究院给你资源,还有一起协作的同学学弟学妹。当然,不可否认他本人也很厉害,远超过我认识的博士生的平均线。再当然,以上的四个方面我都没有。这可能是造成我内耗最深层次的原因,不管是内归因和外归因都只能得到现在的结果,一个主体竭尽全力的结果。
关于退学。我经常会跟自己说晚上再emo也不要做任何决定,尽管我仍然在无数个4.5点的凌晨痛苦,然后在outlook里写好给教务处的退学信。博士毕不了业不是死路一条,毕不了业可以延毕,也可以退学。人生是旷野,怎么会是死路一条呢,选择读博只是去看看另一种风景,而不是底下是深渊只能向死而生的独木桥。人生不过是一个巨大的游乐园,一些刺激的项目尝试了一下不想玩了下来便是,一些玩不上的项目不玩便是,总有你可以玩的项目,也总会出现你想玩的项目。我时刻在劝告自己,人生没有是那么是特别重要的东西,不管是理想、信仰、朋友还是恋人。小时候的我一直觉得我死也得死在成为游戏制作人的路上,结果后来从游戏行业出来(其实是被毕业hhh)的心情也没有小时候想象中那样波澜起伏。人生不过三万天,这三万天不是用来演绎完美的,而是用来体验的,无论干什么,能自洽就好。
关于休息和内耗。写下这段话的时候已经是24.11.15当天,我已经🐏了快一周了,也一周没有工作过了(ta都请假了)。
关于组会。就我个人而言,组会最大的意义就是让我清楚地认识到我不适合科研(误)。如果组内搞得方向都不一样的话,我感觉组会就是给帮老板总结工作,以及给老板一个供他们发挥指导的大舞台。尤其是那种好几个方向老师组织起来的大组会,我每次开完就是一整个无聊加内耗的叠加状态:“啊!听起来好厉害啊!”;“啊!完全听不懂啊!”。
一些其他参考
How to Write Effective Peer Review Comments:https://www.youtube.com/watch?v=kMWZBDUlHUA
在我们的设计中也应该要给到具体的场景(这篇文章中说的框架),最好定义出各个因素,包括:目标,操作者和对象之间的心理关系,交互方式的结构,对象所在的设置,其他属性。同时我们希望我们设计的规则是有猜解性和一致性的,或许可以考虑使用“Maximizing the Guessability of Symbolic Input”论文中的方程来评估。 ↩︎
在我们的设计中,用户设计之前应该也要获得一份类似关于眼睛运动的介绍:每个动作在生理层面上是如何工作的,以及如何识别和跟踪它们。也需要提醒用户不要忽视掉眼球因为紧张而突然的自然动作。 ↩︎
这篇论文针对超小物体,根据密度尺寸和动作空间做了区分进行对比。 / ↩︎
在我们的工作中,我们提出的技术应该也应找到基线对比(或许是最原始的交互方法?) ↩︎
不确定在我的论文中的intro或者relatedwork的部分是不是也要说明一下启发式设计的成功。 在论文中也可以使用这样的method:观看并解释每个VR命令及其效果的视频剪辑,然后设计,使用 7 点李克特量表评估了设计手势所需的努力以及他们所创建的手势的心理需求、身体需求和满意度。最后,我们进行了半结构化访谈,以更多地了解他们的考虑因素。 ↩︎
在related work中,当有论文已经提出了一些交互方案,有个角度可以说前人的工作证明了可行性,但是可用性和可学习性(重复实验学习时长?)没有得到充分探索。 ↩︎ ↩︎
在我们的论文应该也需分析心智模型 ↩︎
我们论文的related work部分应该也要总数一下目前凝视交互的分类 ↩︎
在workshop1的专家访谈也需要得出这样一个use case,在workshop3我们可能也需要制定SA卡片方便用户理解并且通过卡片思考。
 ↩︎ ↩︎
↩︎ ↩︎同时需要强调的是,在我们的场景里(与该论文类似 应该都要考虑到SA)USV是半自主运行的,人类事件指挥官(human Incident Commander?操作者)需要充分了解无人船权限的范围和任务的当前状态。这包括标记它们的地理边界,了解它们当前的模式(例如,搜索,回家),能力(例如,热或可见光图像)和约束(例如,光线不佳需要热图像)? ↩︎
我们之所以选择采用参与式设计方法,是因为在传统的以用户为中心的设计过程中,尽管经过专业工程师的培训后新手用户能够操作无人船,但界面设计仍存在诸多局限。(这个可以在专家访谈的Rethinking部分)首先,这种设计往往不够直观,依赖于专工程师的培训,没有统一的培训资料大部分依赖于经验,学习曲线较为陡峭,导致用户的上手难度较大。其次,以用户为中心的设计(UCD)会导致设计团队的理解和用户实际需求之间存在一定的落差。参与式设计能增强用户对系统的信任和理解,这可以有效提高系统的接受度和用户体验,减少因不熟悉系统带来的操作压力。无人船的用户群体可能涵盖了不同背景、经验水平和使用需求的用户(例如新手、专业操作员等)。单一的用户研究难以全面覆盖所有场景的需求。参与式设计也更适合无人船复杂、多样化的使用场景,能够更好地满足不同用户的需求。关于衡量学习曲线的指标:初次完成任务的时间:用户首次执行任务时需要花费的时间,时间越短,学习曲线越平缓。错误率:用户在初次使用和多次使用后犯错误的次数。错误率的快速降低也意味着学习曲线不陡峭。用户自我评估:通过问卷或访谈,收集用户对系统的直观感受,包括对易用性和学习过程的评估,展示用户在多次操作后对界面易用性和上手难度的评价变化。。重复任务的效率提升:通过用户多次重复某些操作后效率的提升来评估学习曲线。如果用户的效率提升较快,说明学习曲线较为平缓。同时可以结合Fitts’s Law(菲茨定律),Hick’s Law(希克定律),可用性五要素模型(Usability Heuristics). ↩︎ ↩︎ ↩︎
感觉gaze gesture和head gesture也可以作为一个博士课题做下去。在这篇论文中有44.46都是同一个作者做的,应该课题组的大方向是这个【协作是微妙的微观行为的结果,例如学习者的身体姿势、手势、头部方向、视觉注意力和话语。这些行为是复杂的、交织在一起的,并导致了丰富的行为编排,从而创造了复杂的社会互动。】/ ↩︎
在我们的与工程师一对一访谈中也需要对场景用例进行讨论要点的说明。 ↩︎
这一点 我可能也需要在论文里面强调,我们不是想设计一个通用的界面而是目前技术的补充–为特定的场景开发一个有效的界面 ↩︎
在我们的论文中为使用场景定义上下文、功能,并调查用户和问题域是有必要的 ↩︎
需要考虑谁来定义基准?研究人员?还是专业工程师?产品经理?用户完成任务的时间/步骤/评价来完成基准的评估? ↩︎
这一部分也要体现在我们论文的研究动机里面(启发性研究的问题,我们怎么去解决) ↩︎


















 2904
2904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









