







目录
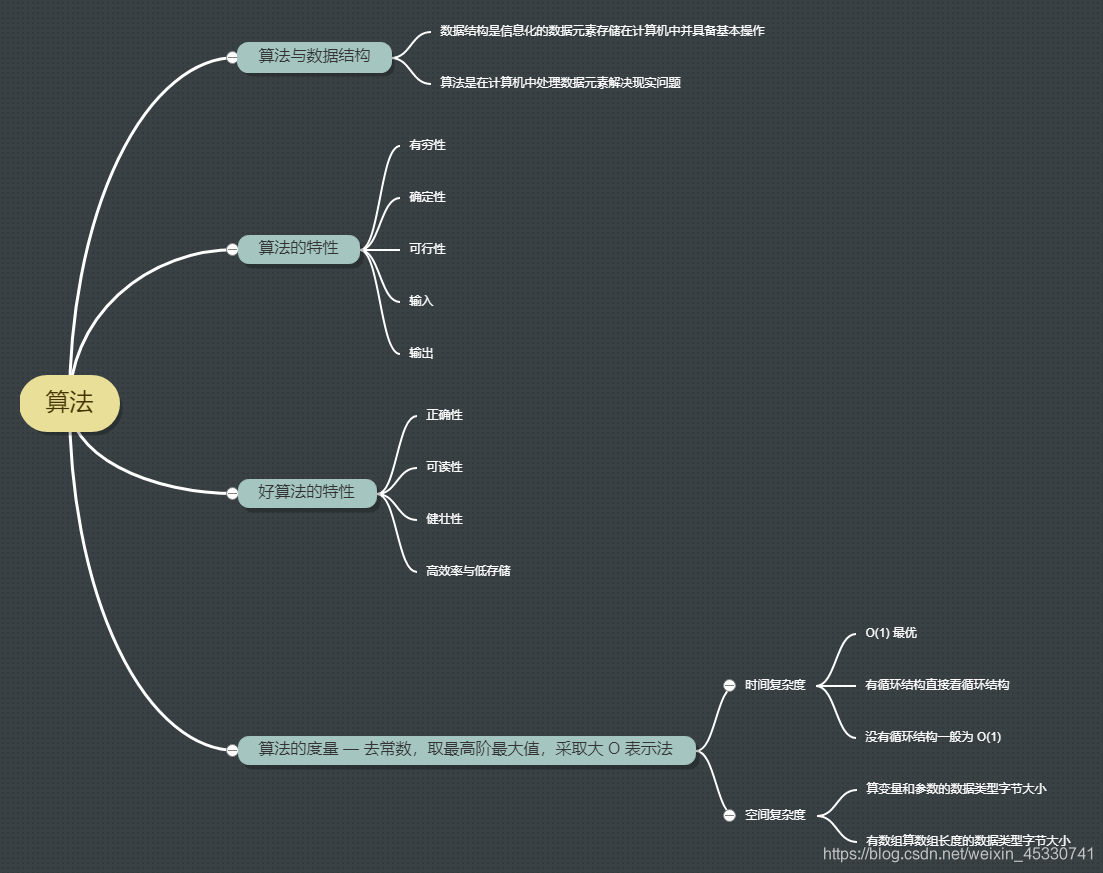
1.1 什么是算法
瑞士计算机科学家尼古拉斯·沃斯曾说过 " Algorithm+Data Structures=Programs ",翻译过来就是那句名言 “ 算法 + 数据结构 = 程序 ” 。

数据结构就是把现实数据元素信息化(逻辑结构)之后,将信息存储到计算机(存储结构)中,并实现对信息的基本操作(数据的运算)。算法则是通过处理数据元素存储的信息来解决现实问题。比如说我们希望电商 app 中的商品列表能够根据价格升序排列。电商 app 中的商品就是信息化的数据元素,将它们放在一起就是商品列表,所以商品列表是数据结构,而价格升序排列,就是利用商品数据元素存储的价格信息来进行从小到大的排序,所以价格升序排列就是算法。
1.2 算法的特性
- 有穷性:一个算法必须总在执行有穷步骤之后结束,且每一步都可在有穷时间内完成。但区分的是算法是有穷的,程序可以是无穷的。
- 确定性:算法中每条指令必须有确切的含义,每次相同的输入得出的输出结果必须也是相同的。比如:一个算法,输入 1,输出结果为 2,那么以后对于这个算法输入 1 的结果只能是 2,如果出现输出结果为 3,那么说明这个算法是有 bug 的。
- 可行性:算法中描述的操作都可以通过已经实现的基本运算执行有限次来实现。
- 输入:一个算法有零个或多个输入。零个输入是什么情况?比如:我们初学计算机高级语言时打印的 “ Hello World ”。
- 输出:一个算法有一个或多个输出。
1.3 好算法的特质
- 正确性
- 可读性
- 健壮性:输入非法数据时,算法能适当地做出反应或进行处理,而不会产生莫名其妙的输出结果
- 高效率与低存储
算法的高效率和低存储是一个算法好坏的评价标准之一,但我们怎样才能知道一个算法的运行效率和所需空间的呢?这就需要对一个算法的时间开销和空间开销进行度量。
1.4 算法的度量
一个算法的时间开销用时间复杂度进行度量,空间开销用空间复杂度进行度量。
1.4.1 时间复杂度
先来看这一段代码
int main() {
int n = 0;
printf("请输入打印次数:\n");
scanf("%d", &n);
outputPrintCount(n);
}
void outputPrintCount(int n) {
int i = 1;
while (i <= n) {
printf("打印第 %d 次", i);
i++;
}
}这段代码中算法的运行次数是不是与输入的 n 有着直接关系,比如:输入的 n 为 5,程序就打印 5 次,输入的 n 为 5000,程序就打印 5000 次。当输入的 n 越大,程序的打印次数也越多,那么算法的运行时间也越久,也意味着算法的时间复杂度越高。代码中的 n 就是问题规模,问题规模越大,时间复杂度也越高,所以问题规模和时间复杂度是有着联系的。
分析一下上面这段代码的时间复杂度,main 函数是程序的入口,所以首先从这里开始运行,变量 n 初始化,执行 1 次,调用打印函数,执行 1 次,调用输入函数 1 次,跳转到函数 outputPrintCount,对变量 i 进行初始化,执行 1 次,进行 while 循环,执行 n + 1 次(多出来的一次是最后 while 判断 i 比 n 大并结束循环),打印函数执行 n 次,i++ 执行 n 次。通常时间复杂度用 T 表示,问题规模用 n 表示,根据分析,可以得到
计算机科学中规定,时间复杂度要去掉常数,且只取最大值和最高阶,用大 O 表示法表示,即
取最大值的意思,上面的程序中有可能输入 0,那么 while 直接不用执行,时间复杂度也跟着变化。但我们计算时间复杂度时不用考虑这种情况,只需考虑取得最大值 n 的情况。
取最高阶的意思,当 时,
。
下面来看看其他代码的时间复杂度
int main() {
int i = 0;
while(i <= 5) {
printf("Hello World");
i++;
}
}来分析一下这段代码,变量 i 赋值执行 1 次,while 循环执行 7 次,打印函数执行 6 次,i++ 执行 6 次。所以 ,是一个常数,常数在大 O 表示法中,用
表示,所以这段代码的时间复杂度用大 O 表示法就是
。
下面对比这两段代码
int main() {
int n = 0;
printf("请输入打印次数:\n");
scanf("%d", &n);
outputPrintCount(n);
}
void outputPrintCount(int n) {
int i = 1;
while (i < n) {
printf("打印第 %d 次", i);
i++;
}
}int main() {
int n = 0;
printf("请输入打印次数:\n");
scanf("%d", &n);
outputPrintCount(n);
}
void outputPrintCount(int n) {
int i = 1;
while (i < n) {
printf("打印第 %d 次", i);
i = i * 2;
}
}假设这两段程序输入的 n 都为 8,第一段代码的 while 循环中 i 从 1 开始自增,分别是 1、2、3、4、5、6、7、8,执行 8 次。第二段代码的 while 循环中 i 从 1 开始乘二,分别是 1、2、4、8,执行 5 次。假设第一个 while 循环的执行次数是 N,第二个 while 循环的执行次数是 n,它们之间的关系就是 ,所以第二段代码的时间复杂度为
通过上面这些代码我们可以发现,时间复杂度与循环结构是有联系的,如果程序中有循环结构,计算它的时间复杂度直接看它的循环结构就好了。如果程序没有循环结构或者循环的次数是已经给定的常数,那么时间复杂度为 。
总结一下各种时间复杂度的大小关系
可能有读者感觉时间复杂度低和时间复杂度高没有什么区别,我们来看看各个时间复杂度的函数图像。

通过函数图像我们可以发现,几个函数一开始几乎是重叠的,但随着 x 的增大,间隔也越来越大。我们觉得时间复杂度低和时间复杂度高的算法差别不大,是因为我们用的数据还不够多,看不出差别。如果我们用的数据很多,那差别可以说是立竿见影的。举一个不是很严谨的例子:短视频软件的日活用户数量超 4 亿,我们就估值为 4 亿,一天有 86400 秒,,所以每一秒就有 4630 人在使用。如果该软件的算法时间复杂度为
,再估算一下,时间复杂度就是 4630 * 4630 = 21436900。现在换成时间复杂度为
的算法,那么它的时间复杂度就是 4630,哪一种更划算,是不是就一目了然。
1.4.2 空间复杂度
一个算法的空间开销,是指操作系统的虚拟内存开销。程序在被编译成机器指令后,会被传到操作系统的虚拟内存中,虚拟内存中又会有一片固定大小的区域用来存储编译好的机器指令,之后又会根据机器指令生成参数,变量的字节大小空间。

现在回到最开始的那段代码
int main() {
int n = 0;
printf("请输入打印次数:\n");
scanf("%d", &n);
outputPrintCount(n);
}
void outputPrintCount(int n1) {
int i = 1;
while (i <= n1) {
printf("打印第 %d 次", i);
i++;
}
}分析一下它的空间开销,程序编译后进入固定大小的区域后,main 方法作为程序入口,会先运行,生成整数型变量(整数型为 4 字节) n 所需空间 —— 4 个字节,接下来就是 outputPrintCount 函数生成整数型参数 n1 所需空间 —— 4 个字节,生成局部变量 i 所需空间 —— 4 个字节,最终空间开销为 4 + 4 + 4 = 12 字节,是一个常数。现在用 S 表示空间复杂度,n 表示问题规模,那么就有
计算机科学中规定,空间复杂度也要去掉常数,且也只取最大值和最高阶,用大 O 表示法表示,所以
当算法的空间复杂度为常数时,我们称这个算法原地工作(术语)。
下面看看这段代码的空间复杂度
void test(int n) {
int flag[n];
int i;
}它的空间复杂度就是
void test(int n) {
int flag[n][n];
int i;
} 它的空间复杂度为
同样,各种空间复杂度的大小关系为
1.5 总结














 1608
1608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









