







Homework 1: COVID-19 Cases Prediction (Regression)
Author: Heng-Jui Chang
- author: 原文链接
- Video: https://www.bilibili.com/video/BV1zA411K7en?p=2
- 22hw1好文
Objectives:
- Solve a regression problem with deep neural networks (DNN).
- Understand basic DNN training tips.
- Get familiar with PyTorch.
下面代码是基于作者baseline改的,主要改动有以下几方面:
- 增加特征分析
- 修改损失函数为均方根误差
- 增加l2正则
- 归一化方法
- 修改一些超参
- 增加部分代码注释
Import Some Packages
# PyTorch
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# For data preprocess
import numpy as np
import csv
import os
# For plotting
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
#下面三个包是新增的
from sklearn.model_selection import train_test_split
import pandas as pd
import pprint as pp
myseed = 42069 # set a random seed for reproducibility
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(myseed)
torch.manual_seed(myseed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(myseed)
Download Data
数据可以去kaggle下载, 不过我已经下载放到github,在/data/目录下
tr_path = 'covid.train.csv' # path to training data
tt_path = 'covid.test.csv' # path to testing data
data_tr = pd.read_csv(tr_path) #读取训练数据
data_tt = pd.read_csv(tt_path) #读取测试数据
Data Analysis
可视化数据,筛选有用特征
data_tr.head(3) #数据量很大,看前三行就行,大致浏览下数据类型
Out[6]:
id AL AK ... worried_become_ill.2 worried_finances.2 tested_positive.2
0 0 1.0 0.0 ... 53.991549 43.604229 20.704935
1 1 1.0 0.0 ... 54.185521 42.665766 21.292911
2 2 1.0 0.0 ... 53.637069 42.972417 21.166656
3 rows × 95 columns
data_tt.head(3)
Out[7]:
id AL AK ... felt_isolated.2 worried_become_ill.2 worried_finances.2
0 0 0.0 0.0 ... 24.747837 66.194950 44.873473
1 1 0.0 0.0 ... 23.559622 57.015009 38.372829
2 2 0.0 0.0 ... 24.993341 55.291498 38.907257
3 rows × 94 columns 少的那列是预测值
data_tr.columns #查看有多少列特征
Index(['id', 'AL', 'AK', 'AZ', 'AR', 'CA', 'CO', 'CT', 'FL', 'GA', 'ID', 'IL',
'IN', 'IA', 'KS', 'KY', 'LA', 'MD', 'MA', 'MI', 'MN', 'MS', 'MO', 'NE',
'NV', 'NJ', 'NM', 'NY', 'NC', 'OH', 'OK', 'OR', 'PA', 'RI', 'SC', 'TX',
'UT', 'VA', 'WA', 'WV', 'WI', 'cli', 'ili', 'hh_cmnty_cli',
'nohh_cmnty_cli', 'wearing_mask', 'travel_outside_state',
'work_outside_home', 'shop', 'restaurant', 'spent_time', 'large_event',
'public_transit', 'anxious', 'depressed', 'felt_isolated',
'worried_become_ill', 'worried_finances', 'tested_positive', 'cli.1',
'ili.1', 'hh_cmnty_cli.1', 'nohh_cmnty_cli.1', 'wearing_mask.1',
'travel_outside_state.1', 'work_outside_home.1', 'shop.1',
'restaurant.1', 'spent_time.1', 'large_event.1', 'public_transit.1',
'anxious.1', 'depressed.1', 'felt_isolated.1', 'worried_become_ill.1',
'worried_finances.1', 'tested_positive.1', 'cli.2', 'ili.2',
'hh_cmnty_cli.2', 'nohh_cmnty_cli.2', 'wearing_mask.2',
'travel_outside_state.2', 'work_outside_home.2', 'shop.2',
'restaurant.2', 'spent_time.2', 'large_event.2', 'public_transit.2',
'anxious.2', 'depressed.2', 'felt_isolated.2', 'worried_become_ill.2',
'worried_finances.2', 'tested_positive.2'],
dtype='object')
data_tr.drop(['id'],axis = 1, inplace = True) #由于id列用不到,删除id列
data_tt.drop(['id'],axis = 1, inplace = True)
cols = list(data_tr.columns) #拿到特征列名称
pp.pprint(data_tr.columns)
Index(['AL', 'AK', 'AZ', 'AR', 'CA', 'CO', 'CT', 'FL', 'GA', 'ID', 'IL', 'IN',
'IA', 'KS', 'KY', 'LA', 'MD', 'MA', 'MI', 'MN', 'MS', 'MO', 'NE', 'NV',
'NJ', 'NM', 'NY', 'NC', 'OH', 'OK', 'OR', 'PA', 'RI', 'SC', 'TX', 'UT',
'VA', 'WA', 'WV', 'WI', 'cli', 'ili', 'hh_cmnty_cli', 'nohh_cmnty_cli',
'wearing_mask', 'travel_outside_state', 'work_outside_home', 'shop',
'restaurant', 'spent_time', 'large_event', 'public_transit', 'anxious',
'depressed', 'felt_isolated', 'worried_become_ill', 'worried_finances',
'tested_positive', 'cli.1', 'ili.1', 'hh_cmnty_cli.1',
'nohh_cmnty_cli.1', 'wearing_mask.1', 'travel_outside_state.1',
'work_outside_home.1', 'shop.1', 'restaurant.1', 'spent_time.1',
'large_event.1', 'public_transit.1', 'anxious.1', 'depressed.1',
'felt_isolated.1', 'worried_become_ill.1', 'worried_finances.1',
'tested_positive.1', 'cli.2', 'ili.2', 'hh_cmnty_cli.2',
'nohh_cmnty_cli.2', 'wearing_mask.2', 'travel_outside_state.2',
'work_outside_home.2', 'shop.2', 'restaurant.2', 'spent_time.2',
'large_event.2', 'public_transit.2', 'anxious.2', 'depressed.2',
'felt_isolated.2', 'worried_become_ill.2', 'worried_finances.2',
'tested_positive.2'],
dtype='object')
pp.pprint(data_tr.info()) #看每列数据类型和大小
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2700 entries, 0 to 2699
Data columns (total 94 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 AL 2700 non-null float64
1 AK 2700 non-null float64
2 AZ 2700 non-null float64
3 AR 2700 non-null float64
4 CA 2700 non-null float64
5 CO 2700 non-null float64
6 CT 2700 non-null float64
7 FL 2700 non-null float64
8 GA 2700 non-null float64
9 ID 2700 non-null float64
10 IL 2700 non-null float64
11 IN 2700 non-null float64
12 IA 2700 non-null float64
13 KS 2700 non-null float64
14 KY 2700 non-null float64
15 LA 2700 non-null float64
16 MD 2700 non-null float64
17 MA 2700 non-null float64
18 MI 2700 non-null float64
19 MN 2700 non-null float64
20 MS 2700 non-null float64
21 MO 2700 non-null float64
22 NE 2700 non-null float64
23 NV 2700 non-null float64
24 NJ 2700 non-null float64
25 NM 2700 non-null float64
26 NY 2700 non-null float64
27 NC 2700 non-null float64
28 OH 2700 non-null float64
29 OK 2700 non-null float64
30 OR 2700 non-null float64
31 PA 2700 non-null float64
32 RI 2700 non-null float64
33 SC 2700 non-null float64
34 TX 2700 non-null float64
35 UT 2700 non-null float64
36 VA 2700 non-null float64
37 WA 2700 non-null float64
38 WV 2700 non-null float64
39 WI 2700 non-null float64
40 cli 2700 non-null float64
41 ili 2700 non-null float64
42 hh_cmnty_cli 2700 non-null float64
43 nohh_cmnty_cli 2700 non-null float64
44 wearing_mask 2700 non-null float64
45 travel_outside_state 2700 non-null float64
46 work_outside_home 2700 non-null float64
47 shop 2700 non-null float64
48 restaurant 2700 non-null float64
49 spent_time 2700 non-null float64
50 large_event 2700 non-null float64
51 public_transit 2700 non-null float64
52 anxious 2700 non-null float64
53 depressed 2700 non-null float64
54 felt_isolated 2700 non-null float64
55 worried_become_ill 2700 non-null float64
56 worried_finances 2700 non-null float64
57 tested_positive 2700 non-null float64
58 cli.1 2700 non-null float64
59 ili.1 2700 non-null float64
60 hh_cmnty_cli.1 2700 non-null float64
61 nohh_cmnty_cli.1 2700 non-null float64
62 wearing_mask.1 2700 non-null float64
63 travel_outside_state.1 2700 non-null float64
64 work_outside_home.1 2700 non-null float64
65 shop.1 2700 non-null float64
66 restaurant.1 2700 non-null float64
67 spent_time.1 2700 non-null float64
68 large_event.1 2700 non-null float64
69 public_transit.1 2700 non-null float64
70 anxious.1 2700 non-null float64
71 depressed.1 2700 non-null float64
72 felt_isolated.1 2700 non-null float64
73 worried_become_ill.1 2700 non-null float64
74 worried_finances.1 2700 non-null float64
75 tested_positive.1 2700 non-null float64
76 cli.2 2700 non-null float64
77 ili.2 2700 non-null float64
78 hh_cmnty_cli.2 2700 non-null float64
79 nohh_cmnty_cli.2 2700 non-null float64
80 wearing_mask.2 2700 non-null float64
81 travel_outside_state.2 2700 non-null float64
82 work_outside_home.2 2700 non-null float64
83 shop.2 2700 non-null float64
84 restaurant.2 2700 non-null float64
85 spent_time.2 2700 non-null float64
86 large_event.2 2700 non-null float64
87 public_transit.2 2700 non-null float64
88 anxious.2 2700 non-null float64
89 depressed.2 2700 non-null float64
90 felt_isolated.2 2700 non-null float64
91 worried_become_ill.2 2700 non-null float64
92 worried_finances.2 2700 non-null float64
93 tested_positive.2 2700 non-null float64
dtypes: float64(94)
memory usage: 1.9 MB
None
WI_index = cols.index('WI') # WI列是states one-hot编码最后一列,取值为0或1,后面特征分析时需要把states特征删掉
WI_index #wi列索引 39
data_tr.iloc[:, 40:].describe() #从上面可以看出wi 列后面是cli, 所以列索引从40开始, 并查看这些数据分布
 8 rows × 54 columns
8 rows × 54 columns
data_tt.iloc[:, 40:].describe() #查看测试集数据分布,并和训练集数据分布对比,两者特征之间数据分布差异不是很大
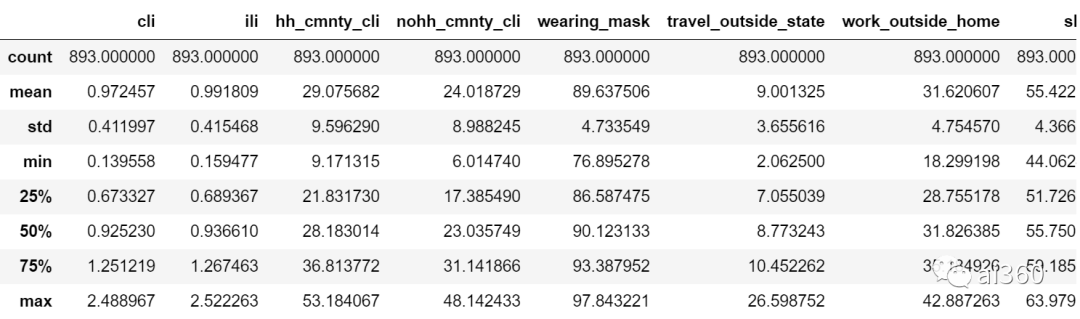 8 rows × 53 columns
8 rows × 53 columns
plt.scatter(data_tr.loc[:, 'cli'], data_tr.loc[:, 'tested_positive.2']) #肉眼分析cli特征与目标之间相关性
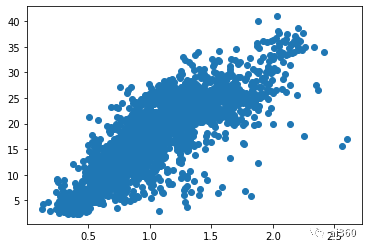 png
png
plt.scatter(data_tr.loc[:, 'ili'], data_tr.loc[:, 'tested_positive.2'])
 png
png
plt.scatter(data_tr.loc[:, 'cli'], data_tr.loc[:, 'ili']) #cli 和ili两者差不多,所以这两个特征用一个就行
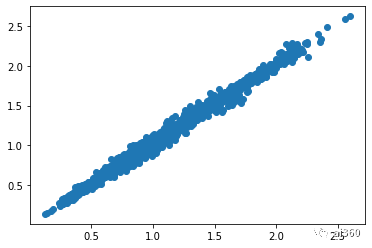 png
png
plt.scatter(data_tr.loc[:, 'tested_positive'], data_tr.loc[:, 'tested_positive.2']) #day1 目标值与day3目标值相关性,线性相关的
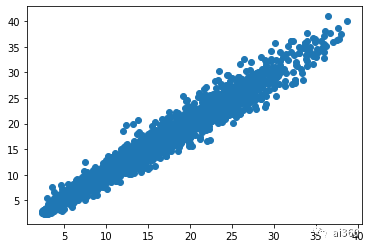 png
png
plt.scatter(data_tr.loc[:, 'tested_positive.1'], data_tr.loc[:, 'tested_positive.2']) #day2 目标值与day3目标值相关性,线性相关的
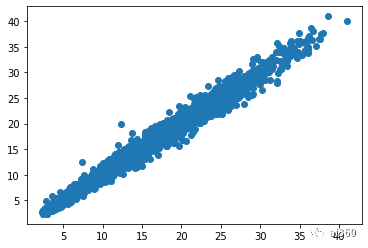 png
png
data_tr.iloc[:, 40:].corr() #上面手动分析太累,还是利用corr方法自动分析
 54 rows × 54 columns
54 rows × 54 columns
#锁定上面相关性矩阵最后一列,也就是目标值列,每行是与其相关性大小
data_corr = data_tr.iloc[:, 40:].corr()
target_col = data_corr['tested_positive.2']
target_col
cli 0.838504
ili 0.830527
hh_cmnty_cli 0.879724
nohh_cmnty_cli 0.869938
wearing_mask -0.069531
travel_outside_state -0.097303
work_outside_home 0.034865
shop -0.410430
restaurant -0.157945
spent_time -0.252125
large_event -0.052473
public_transit -0.448360
anxious 0.173295
depressed 0.037689
felt_isolated 0.082182
worried_become_ill 0.262211
worried_finances 0.475462
tested_positive 0.981165
cli.1 0.838224
ili.1 0.829200
hh_cmnty_cli.1 0.879438
nohh_cmnty_cli.1 0.869278
wearing_mask.1 -0.065600
travel_outside_state.1 -0.100407
work_outside_home.1 0.037930
shop.1 -0.412705
restaurant.1 -0.159121
spent_time.1 -0.255714
large_event.1 -0.058079
public_transit.1 -0.449079
anxious.1 0.164537
depressed.1 0.033149
felt_isolated.1 0.081521
worried_become_ill.1 0.264816
worried_finances.1 0.480958
tested_positive.1 0.991012
cli.2 0.835751
ili.2 0.826075
hh_cmnty_cli.2 0.878218
nohh_cmnty_cli.2 0.867535
wearing_mask.2 -0.062037
travel_outside_state.2 -0.103868
work_outside_home.2 0.039304
shop.2 -0.415130
restaurant.2 -0.160181
spent_time.2 -0.258956
large_event.2 -0.063709
public_transit.2 -0.450436
anxious.2 0.152903
depressed.2 0.029578
felt_isolated.2 0.081174
worried_become_ill.2 0.267610
worried_finances.2 0.485843
tested_positive.2 1.000000
Name: tested_positive.2, dtype: float64
feature = target_col[target_col > 0.8] #在最后一列相关性数据中选择大于0.8的行,这个0.8是自己设的超参,大家可以根据实际情况调节
feature
cli 0.838504
ili 0.830527
hh_cmnty_cli 0.879724
nohh_cmnty_cli 0.869938
tested_positive 0.981165
cli.1 0.838224
ili.1 0.829200
hh_cmnty_cli.1 0.879438
nohh_cmnty_cli.1 0.869278
tested_positive.1 0.991012
cli.2 0.835751
ili.2 0.826075
hh_cmnty_cli.2 0.878218
nohh_cmnty_cli.2 0.867535
tested_positive.2 1.000000
Name: tested_positive.2, dtype: float64
feature_cols = feature.index.tolist() #将选择特征名称拿出来
feature_cols.pop() #去掉test_positive标签
pp.pprint(feature_cols) #得到每个需要特征名称列表
['cli',
'ili',
'hh_cmnty_cli',
'nohh_cmnty_cli',
'tested_positive',
'cli.1',
'ili.1',
'hh_cmnty_cli.1',
'nohh_cmnty_cli.1',
'tested_positive.1',
'cli.2',
'ili.2',
'hh_cmnty_cli.2',
'nohh_cmnty_cli.2']
feats_selected = [cols.index(col) for col in feature_cols] #获取该特征对应列索引编号,后续就可以用feats + feats_selected作为特征值
feats_selected
[40, 41, 42, 43, 57, 58, 59, 60, 61, 75, 76, 77, 78, 79]
Some Utilities
You do not need to modify this part.
def get_device():
''' Get device (if GPU is available, use GPU) '''
return 'cuda' if torch.cuda.is_available() else 'cpu'
def plot_learning_curve(loss_record, title=''):
''' Plot learning curve of your DNN (train & dev loss) '''
total_steps = len(loss_record['train'])
x_1 = range(total_steps)
x_2 = x_1[::len(loss_record['train']) // len(loss_record['dev'])]
figure(figsize=(6, 4))
plt.plot(x_1, loss_record['train'], c='tab:red', label='train')
plt.plot(x_2, loss_record['dev'], c='tab:cyan', label='dev')
plt.ylim(0.0, 5.)
plt.xlabel('Training steps')
plt.ylabel('MSE loss')
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
def plot_pred(dv_set, model, device, lim=35., preds=None, targets=None):
''' Plot prediction of your DNN '''
if preds is None or targets is None:
model.eval()
preds, targets = [], []
for x, y in dv_set:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
targets.append(y.detach().cpu())
preds = torch.cat(preds, dim=0).numpy()
targets = torch.cat(targets, dim=0).numpy()
figure(figsize=(5, 5))
plt.scatter(targets, preds, c='r', alpha=0.5)
plt.plot([-0.2, lim], [-0.2, lim], c='b')
plt.xlim(-0.2, lim)
plt.ylim(-0.2, lim)
plt.xlabel('ground truth value')
plt.ylabel('predicted value')
plt.title('Ground Truth v.s. Prediction')
plt.show()
Preprocess
We have three kinds of datasets:
train: for trainingdev: for validationtest: for testing (w/o target value)
Dataset
The COVID19Dataset below does:
- read
.csvfiles - extract features
- split
covid.train.csvinto train/dev sets - normalize features
Finishing TODO below might make you pass medium baseline.
class COVID19Dataset(Dataset):
''' Dataset for loading and preprocessing the COVID19 dataset '''
def __init__(self,
path,
mu, #mu,std是我自己加,baseline代码归一化有问题,我重写归一化部分
std,
mode='train',
target_only=False):
self.mode = mode
# Read data into numpy arrays
with open(path, 'r') as fp:
data = list(csv.reader(fp))
data = np.array(data[1:])[:, 1:].astype(float)
if not target_only: #target_only 默认是false, 所以用的是全量特征,如果要用自己选择特征,则实例化这个类的时候,设置成True
feats = list(range(93))
else:
# TODO: Using 40 states & 2 tested_positive features (indices = 57 & 75)
# TODO: Using 40 states & 4 tested_positive features (indices = 57 & 75)
feats = list(range(40)) + feats_selected # feats_selected是我们选择特征, 40代表是states特征
#如果用只用两个特征,可以忽略前面数据分析过程,直接这样写
#feats = list(range(40)) + [57, 75]
if self.mode == 'test':
# Testing data
# data: 893 x 93 (40 states + day 1 (18) + day 2 (18) + day 3 (17))
data = data[:, feats]
self.data = torch.FloatTensor(data)
else:
# Training data (train/dev sets)
# data: 2700 x 94 (40 states + day 1 (18) + day 2 (18) + day 3 (18))
target = data[:, -1]
data = data[:, feats]
# Splitting training data into train & dev sets
# if mode == 'train':
# indices = [i for i in range(len(data)) if i % 10 != 0]
# elif mode == 'dev':
# indices = [i for i in range(len(data)) if i % 10 == 0]
#baseline上面这段代码划分训练集和测试集按照顺序选择数据,可能造成数据分布问题,我改成随机选择
indices_tr, indices_dev = train_test_split([i for i in range(data.shape[0])], test_size = 0.3, random_state = 0)
if self.mode == 'train':
indices = indices_tr
elif self.mode == 'dev':
indices = indices_dev
# Convert data into PyTorch tensors
self.data = torch.FloatTensor(data[indices])
self.target = torch.FloatTensor(target[indices])
# Normalize features (you may remove this part to see what will happen)
#self.data[:, 40:] = \
#(self.data[:, 40:] - self.data[:, 40:].mean(dim=0, keepdim=True)) \
#/ self.data[:, 40:].std(dim=0, keepdim=True)
#self.data = (self.data - self.data.mean(dim = 0, keepdim = True)) / self.data.std(dim=0, keepdim=True)
#baseline这段代码数据归一化用的是当前数据归一化,事实上验证集上和测试集上归一化一般只能用过去数据即训练集上均值和方差进行归一化
if self.mode == "train": #如果是训练集,均值和方差用自己数据
self.mu = self.data[:, 40:].mean(dim=0, keepdim=True)
self.std = self.data[:, 40:].std(dim=0, keepdim=True)
else: #测试集和开发集,传进来的均值和方差是来自训练集保存,如何保存均值和方差,看数据dataload部分
self.mu = mu
self.std = std
self.data[:,40:] = (self.data[:, 40:] - self.mu) / self.std #归一化
self.dim = self.data.shape[1]
print('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})'
.format(mode, len(self.data), self.dim))
def __getitem__(self, index):
# Returns one sample at a time
if self.mode in ['train', 'dev']:
# For training
return self.data[index], self.target[index]
else:
# For testing (no target)
return self.data[index]
def __len__(self):
# Returns the size of the dataset
return len(self.data)
DataLoader
A DataLoader loads data from a given Dataset into batches.
def prep_dataloader(path, mode, batch_size, n_jobs=0, target_only=False, mu=None, std=None): #训练集不需要传mu,std, 所以默认值设置为None
''' Generates a dataset, then is put into a dataloader. '''
dataset = COVID19Dataset(path, mu, std, mode=mode, target_only=target_only) # Construct dataset
if mode == 'train': #如果是训练集,把训练集上均值和方差保存下来
mu = dataset.mu
std = dataset.std
dataloader = DataLoader(
dataset, batch_size,
shuffle=(mode == 'train'), drop_last=False,
num_workers=n_jobs, pin_memory=True) # Construct dataloader
return dataloader, mu, std
Deep Neural Network
NeuralNet is an nn.Module designed for regression.
The DNN consists of 2 fully-connected layers with ReLU activation.
This module also included a function cal_loss for calculating loss.
class NeuralNet(nn.Module):
''' A simple fully-connected deep neural network '''
def __init__(self, input_dim):
super(NeuralNet, self).__init__()
# Define your neural network here
# TODO: How to modify this model to achieve better performance?
self.net = nn.Sequential(
nn.Linear(input_dim, 68), #70是我调得最好的, 而且加层很容易过拟和
nn.ReLU(),
nn.Linear(68,1)
)
# Mean squared error loss
self.criterion = nn.MSELoss(reduction='mean')
def forward(self, x):
''' Given input of size (batch_size x input_dim), compute output of the network '''
return self.net(x).squeeze(1)
def cal_loss(self, pred, target):
''' Calculate loss '''
# TODO: you may implement L2 regularization here
eps = 1e-6
l2_reg = 0
alpha = 0.0001
#这段代码是l2正则,但是实际操作l2正则效果不好,大家也也可以调,把下面这段代码取消注释就行
# for name, w in self.net.named_parameters():
# if 'weight' in name:
# l2_reg += alpha * torch.norm(w, p = 2).to(device)
return torch.sqrt(self.criterion(pred, target) + eps) + l2_reg
#lr_reg=0, 后面那段代码用的是均方根误差,均方根误差和kaggle评测指标一致,而且训练模型也更平稳
Train/Dev/Test
Training
def train(tr_set, dv_set, model, config, device):
''' DNN training '''
n_epochs = config['n_epochs'] # Maximum number of epochs
# Setup optimizer
optimizer = getattr(torch.optim, config['optimizer'])(
model.parameters(), **config['optim_hparas'])
min_mse = 1000.
loss_record = {'train': [], 'dev': []} # for recording training loss
early_stop_cnt = 0
epoch = 0
while epoch < n_epochs:
model.train() # set model to training mode
for x, y in tr_set: # iterate through the dataloader
optimizer.zero_grad() # set gradient to zero
x, y = x.to(device), y.to(device) # move data to device (cpu/cuda)
pred = model(x) # forward pass (compute output)
mse_loss = model.cal_loss(pred, y) # compute loss
mse_loss.backward() # compute gradient (backpropagation)
optimizer.step() # update model with optimizer
loss_record['train'].append(mse_loss.detach().cpu().item())
# After each epoch, test your model on the validation (development) set.
dev_mse = dev(dv_set, model, device)
if dev_mse < min_mse:
# Save model if your model improved
min_mse = dev_mse
print('Saving model (epoch = {:4d}, loss = {:.4f})'
.format(epoch + 1, min_mse))
torch.save(model.state_dict(), config['save_path']) # Save model to specified path
early_stop_cnt = 0
else:
early_stop_cnt += 1
epoch += 1
loss_record['dev'].append(dev_mse)
if early_stop_cnt > config['early_stop']:
# Stop training if your model stops improving for "config['early_stop']" epochs.
break
print('Finished training after {} epochs'.format(epoch))
return min_mse, loss_record
Validation
def dev(dv_set, model, device):
model.eval() # set model to evalutation mode
total_loss = 0
for x, y in dv_set: # iterate through the dataloader
x, y = x.to(device), y.to(device) # move data to device (cpu/cuda)
with torch.no_grad(): # disable gradient calculation
pred = model(x) # forward pass (compute output)
mse_loss = model.cal_loss(pred, y) # compute loss
total_loss += mse_loss.detach().cpu().item() * len(x) # accumulate loss
total_loss = total_loss / len(dv_set.dataset) # compute averaged loss
return total_loss
Testing
def test(tt_set, model, device):
model.eval() # set model to evalutation mode
preds = []
for x in tt_set: # iterate through the dataloader
x = x.to(device) # move data to device (cpu/cuda)
with torch.no_grad(): # disable gradient calculation
pred = model(x) # forward pass (compute output)
preds.append(pred.detach().cpu()) # collect prediction
preds = torch.cat(preds, dim=0).numpy() # concatenate all predictions and convert to a numpy array
return preds
Setup Hyper-parameters
config contains hyper-parameters for training and the path to save your model.
device = get_device() # get the current available device ('cpu' or 'cuda')
os.makedirs('models', exist_ok=True) # The trained model will be saved to ./models/
#target_only = False ## TODO: Using 40 states & 2 tested_positive features
target_only = True # 使用自己的特征,如果设置成False,用的是全量特征
# TODO: How to tune these hyper-parameters to improve your model's performance? 这里超参数没怎么调,已经最优的了
config = {
'n_epochs': 3000, # maximum number of epochs
'batch_size': 270, # mini-batch size for dataloader
'optimizer': 'SGD', # optimization algorithm (optimizer in torch.optim)
'optim_hparas': { # hyper-parameters for the optimizer (depends on which optimizer you are using)
'lr': 0.005, # learning rate of SGD
'momentum': 0.5 # momentum for SGD
},
'early_stop': 200, # early stopping epochs (the number epochs since your model's last improvement)
#'save_path': 'models/model.pth' # your model will be saved here
'save_path': 'models/model_select.path'
}
Load data and model
tr_set, tr_mu, tr_std = prep_dataloader(tr_path, 'train', config['batch_size'], target_only=target_only)
dv_set, mu_none, std_none = prep_dataloader(tr_path, 'dev', config['batch_size'], target_only=target_only, mu=tr_mu, std=tr_std)
tt_set, mu_none, std_none = prep_dataloader(tr_path, 'test', config['batch_size'], target_only=target_only, mu=tr_mu, std=tr_std)
Finished reading the train set of COVID19 Dataset (1890 samples found, each dim = 54)
Finished reading the dev set of COVID19 Dataset (810 samples found, each dim = 54)
Finished reading the test set of COVID19 Dataset (2700 samples found, each dim = 54)
model = NeuralNet(tr_set.dataset.dim).to(device) # Construct model and move to device
Start Training!
model_loss, model_loss_record = train(tr_set, dv_set, model, config, device)
Saving ,model (epoch = 1, loss = 17.9400)
Saving ,model (epoch = 2, loss = 17.7633)
Saving ,model (epoch = 3, loss = 17.5787)
Saving ,model (epoch = 4, loss = 17.3771)
Saving ,model (epoch = 5, loss = 17.1470)
Saving ,model (epoch = 6, loss = 16.8771)
Saving ,model (epoch = 7, loss = 16.5431)
Saving ,model (epoch = 8, loss = 16.1448)
Saving ,model (epoch = 9, loss = 15.6431)
Saving ,model (epoch = 10, loss = 15.0301)
Saving ,model (epoch = 11, loss = 14.2973)
Saving ,model (epoch = 12, loss = 13.4373)
Saving ,model (epoch = 13, loss = 12.4802)
Saving ,model (epoch = 14, loss = 11.5376)
Saving ,model (epoch = 15, loss = 10.7088)
Saving ,model (epoch = 16, loss = 10.0928)
Saving ,model (epoch = 17, loss = 9.6834)
.....
Saving ,model (epoch = 498, loss = 0.9614)
Saving ,model (epoch = 539, loss = 0.9614)
Saving ,model (epoch = 545, loss = 0.9613)
Saving ,model (epoch = 567, loss = 0.9612)
Saving ,model (epoch = 568, loss = 0.9611)
Saving ,model (epoch = 581, loss = 0.9606)
Saving ,model (epoch = 594, loss = 0.9606)
Saving ,model (epoch = 598, loss = 0.9606)
Saving ,model (epoch = 599, loss = 0.9604)
Saving ,model (epoch = 600, loss = 0.9603)
Saving ,model (epoch = 621, loss = 0.9603)
Saving ,model (epoch = 706, loss = 0.9601)
Saving ,model (epoch = 741, loss = 0.9601)
Saving ,model (epoch = 781, loss = 0.9598)
Saving ,model (epoch = 786, loss = 0.9597)
Finished training after 987 epochs
plot_learning_curve(model_loss_record, title='deep model')
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OFyE9vN4-1689515262658)(C:\Users\yunche\AppData\Roaming\Typora\typora-user-images\image-20230716191357601.png)]
dev(dv_set, model, device) #验证集损失
0.9632348616917928
del model
model = NeuralNet(tr_set.dataset.dim).to(device)
ckpt = torch.load(config['save_path'], map_location='cpu') # Load your best model
model.load_state_dict(ckpt)
plot_pred(dv_set, model, device) # Show prediction on the validation set
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QmT4rMMv-1689515262658)(C:\Users\yunche\AppData\Roaming\Typora\typora-user-images\image-20230716191431967.png)]
Testing
The predictions of your model on testing set will be stored at pred.csv.
def save_pred(preds, file):
''' Save predictions to specified file '''
print('Saving results to {}'.format(file))
with open(file, 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['id', 'tested_positive'])
for i, p in enumerate(preds):
writer.writerow([i, p])
preds = test(tt_set, model, device) # predict COVID-19 cases with your model
save_pred(preds, 'pred.csv') # save prediction file to pred.csv
Saving results to pred.csv
总结
这个case由于数据量比较小,训练数据与测试数据分布基本一致,而且每列数据的值都是百分数,所以特征之间数据分布差异不是很大,导致数据做完归一化效果也没有多大提升。原文数据归一化方法有问题,我改过以后效果也没有提升。其它超参数如增加层,节点,修改激活函数对结果提升也不是很明显, 提升比较显著的是特征筛选。simple baseline 用了93个特征,通过数据分析,我用了52个特征,一下就过了medium baseline, 然后微调了下训练集和验证集数据划分方式为随机选择,比例为7:3,结果一下接近了strong baseline。simple baseline 损失函数均方方差,我改为均方根误差,模型训练收敛比较快,而且loss下降比较平稳,均方误差训练震荡比较大。最后试图用了l2正则,但训练集上效果反而不是很高,所以把l2去掉。除了以上trick,大家还可以尝试修改优化方法,比如adam, kfold等。
附上23年hw1的部分代码
def same_seed(seed):
'''Fixes random number generator seeds for reproducibility.'''
# 使用确定的卷积算法 (A bool that, if True, causes cuDNN to only use deterministic convolution algorithms.)
torch.backends.cudnn.deterministic = True
# 不对多个卷积算法进行基准测试和选择最优 (A bool that, if True, causes cuDNN to benchmark multiple convolution algorithms and select the fastest.)
torch.backends.cudnn.benchmark = False
# 设置随机数种子
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
def train_valid_split(data_set, valid_ratio, seed):
'''Split provided training data into training set and validation set'''
valid_set_size = int(valid_ratio * len(data_set))
train_set_size = len(data_set) - valid_set_size
train_set, valid_set = random_split(data_set, [train_set_size, valid_set_size], generator=torch.Generator().manual_seed(seed))
return np.array(train_set), np.array(valid_set)
def predict(test_loader, model, device):
# 用于评估模型(验证/测试)
model.eval() # Set your model to evaluation mode.
preds = []
for x in tqdm(test_loader):
# device (int, optional): if specified, all parameters will be copied to that device)
x = x.to(device) # 将数据 copy 到 device
with torch.no_grad(): # 禁用梯度计算,以减少消耗
pred = model(x)
preds.append(pred.detach().cpu()) # detach() 创建一个不在计算图中的新张量,值相同
preds = torch.cat(preds, dim=0).numpy() # 连接 preds
return preds
Dataset
class COVID19Dataset(Dataset):
'''
x: Features.
y: Targets, if none, do prediction.
'''
def __init__(self, x, y=None):
if y is None:
self.y = y
else:
self.y = torch.FloatTensor(y)
self.x = torch.FloatTensor(x)
'''meth:`__getitem__`, supporting fetching a data sample for a given key.'''
def __getitem__(self, idx): # 自定义 dataset 的 idx 对应的 sample
if self.y is None:
return self.x[idx]
else:
return self.x[idx], self.y[idx]
def __len__(self):
return len(self.x)
class My_Model(nn.Module):
def __init__(self, input_dim):
super(My_Model, self).__init__()
# TODO: modify model's structure in hyper-parameter: 'config', be aware of dimensions.
self.layers = nn.Sequential(
nn.Linear(input_dim, config['layer'][0]),
nn.ReLU(),
nn.Linear(config['layer'][0], config['layer'][1]),
nn.ReLU(),
nn.Linear(config['layer'][1], 1)
)
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x
from sklearn.feature_selection import SelectKBest, f_regression
k = config['k'] # 所要选择的特征数量
selector = SelectKBest(score_func=f_regression, k=k)
result = selector.fit(train_data[:, :-1], train_data[:,-1])
idx = np.argsort(result.scores_)[::-1]
feat_idx = list(np.sort(idx[:k]))
def trainer(train_loader, valid_loader, model, config, device):
criterion = nn.MSELoss(reduction='mean') # Define your loss function, do not modify this.
# Define your optimization algorithm.
# TODO: Please check https://pytorch.org/docs/stable/optim.html to get more available algorithms.
# TODO: L2 regularization (optimizer(weight decay...) or implement by your self).
optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=config['momentum']) # 设置 optimizer 为SGD
writer = SummaryWriter() # Writer of tensoboard.
if not os.path.isdir('./models'):
os.mkdir('./models') # Create directory of saving models.
n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0
for epoch in range(n_epochs):
model.train() # Set your model to train mode.
loss_record = [] # 初始化空列表,用于记录训练误差
# tqdm is a package to visualize your training progress.
train_pbar = tqdm(train_loader, position=0, leave=True) # 让训练进度显示出来,可以去除这一行,然后将下面的 train_pbar 改成 train_loader(目的是尽量减少 jupyter notebook 的打印,因为如果这段代码在 kaggle 执行,在一定的输出后会报错: IOPub message rate exceeded...)
for x, y in train_pbar:
optimizer.zero_grad() # Set gradient to zero.
x, y = x.to(device), y.to(device) # Move your data to device.
pred = model(x) # 等价于 model.forward(x)
loss = criterion(pred, y) # 计算 pred 和 y 的均方误差
loss.backward() # Compute gradient(backpropagation).
optimizer.step() # Update parameters.
step += 1
loss_record.append(loss.detach().item())
# Display current epoch number and loss on tqdm progress bar.
train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]')
train_pbar.set_postfix({'loss': loss.detach().item()})
mean_train_loss = sum(loss_record)/len(loss_record)
writer.add_scalar('Loss/train', mean_train_loss, step)
model.eval() # Set your model to evaluation mode.
loss_record = [] # 初始化空列表,用于记录验证误差
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
loss_record.append(loss.item())
mean_valid_loss = sum(loss_record)/len(loss_record)
print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')
# writer.add_scalar('Loss/valid', mean_valid_loss, step)
if mean_valid_loss < best_loss:
best_loss = mean_valid_loss
torch.save(model.state_dict(), config['save_path']) # Save your best model
print('Saving model with loss {:.3f}...'.format(best_loss))
early_stop_count = 0
else:
early_stop_count += 1
if early_stop_count >= config['early_stop']:
print('\nModel is not improving, so we halt the training session.')
return
Reference
This code is completely written by Heng-Jui Chang @ NTUEE.
Copying or reusing this code is required to specify the original author.
E.g.
Source: Heng-Jui Chang @ NTUEE (https://github.com/ga642381/ML2021-Spring/blob/main/HW01/HW01.ipynb)















 2855
2855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









