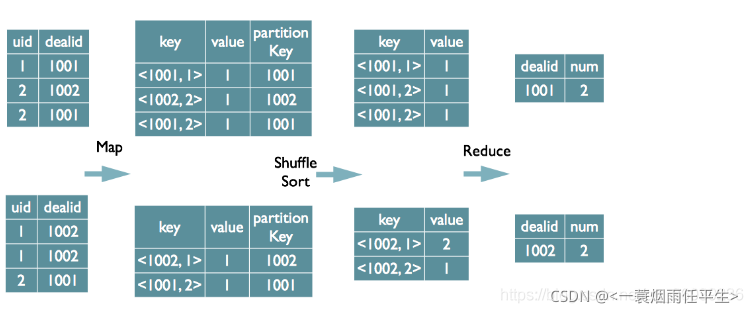
Hive Distinct 的实现原理 select dealid, count(distinct uid) num from order group by dealid; 当只有一个distinct字段时,如果不考虑Map阶段的Hash GroupBy,只需要将GroupBy字段和Distinct字段组合为map输出key,利用mapreduce的排序,同时将GroupBy字段作 为reduce的key,在reduce阶段保存LastKey即可完成去重。 如果有多个distinct字段呢,如下面的SQL: select








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2837
2837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








