






Python中一个应用广泛的方向就是爬虫。
今天就给大家讲讲爬虫的原理,并举个小案例说明爬虫的流程。
1、什么是爬虫?
我们日常浏览的文字、图片、视频等数据是在别人服务器上的,通过网络传输到浏览器展示给我们看,那如果我们想把浏览器上展示的数据存放到本地怎么办呢?
少量的我们可以复制粘贴,那多了呢?此时就体现出了代码的魅力
可以把整个互联网想象成一张数据网,而我们编写的代码的工作就是从这个数据网上获取我们需要的信息,存储下来。
2、爬虫的原理
一句话:代替浏览器去向服务器要数据
平常我们获取数据流程是这样的:
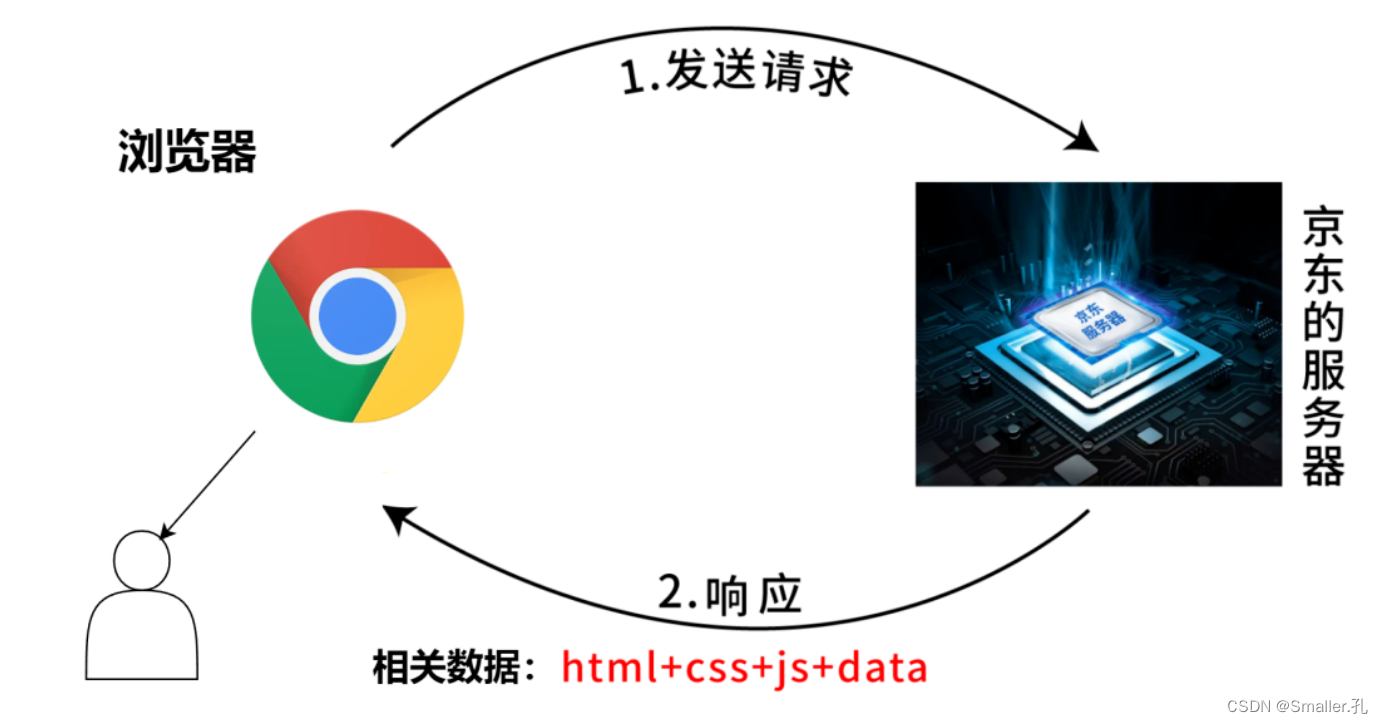
流程:告诉浏览器要看啥—浏览器找服务器要—服务器给浏览器要的数据—浏览器呈现给你。
可以看到最后你需要的数据就来到了浏览器手中。
那写了爬虫代码之后是这样的:
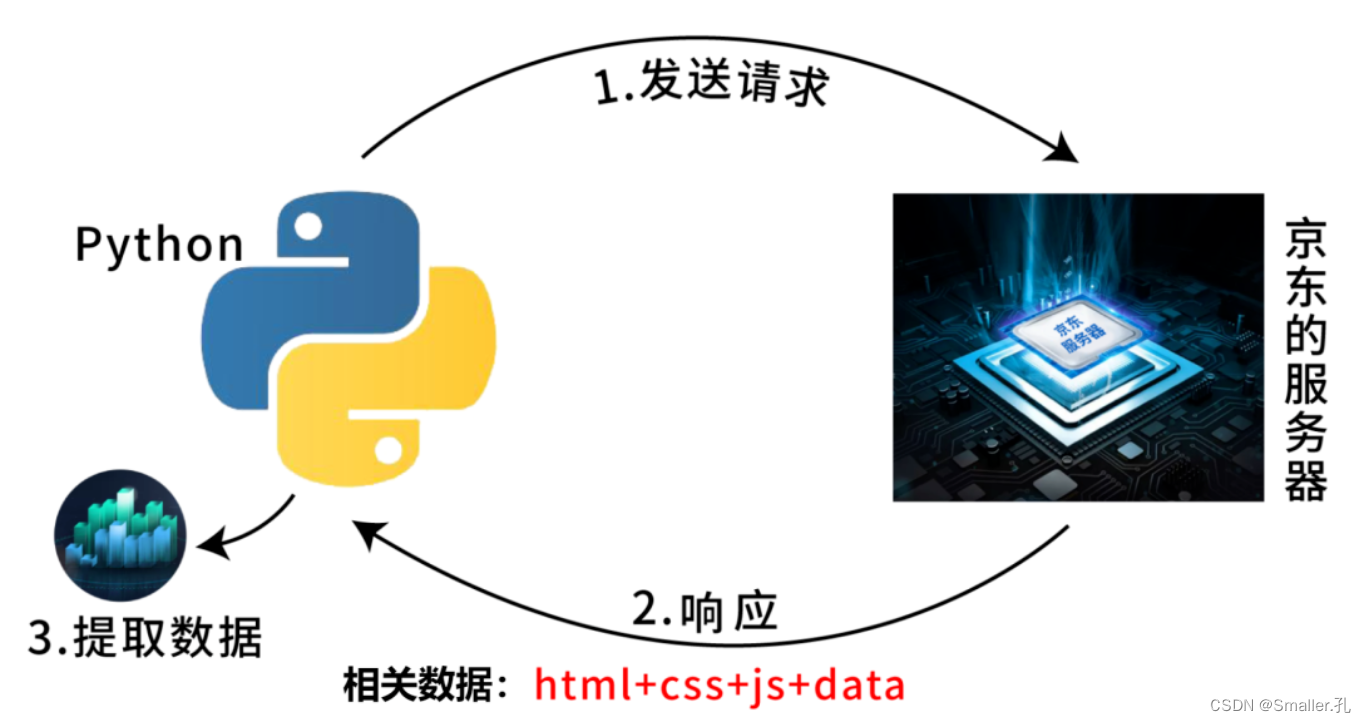
爬虫代码直接替代了浏览器的角色,最后数据跑到了爬虫代码手中,那爬虫代码的不就是你的嘛。
3、爬虫代码的构成
上面说了,爬虫是替代的浏览器的角色,帮我们找服务器要数据的。
既然是替代,那就得易容的很像浏览器,不然服务器一眼看出你是披着羊皮的狼,肯定不会开门把数据给你。
所以编写整个爬虫代码的核心就是:
把自己打扮的像浏览器,包括穿着打扮,一言一行,越像越好。
那既然要像浏览器,就得知道浏览器找服务器要数据的时候穿啥样,需不需要身份证明啥的,这就是请求的构造部分。
任意网页,点击F12—刷新下网页—Nerwork—Headers,就可以看到浏览器发送的请求
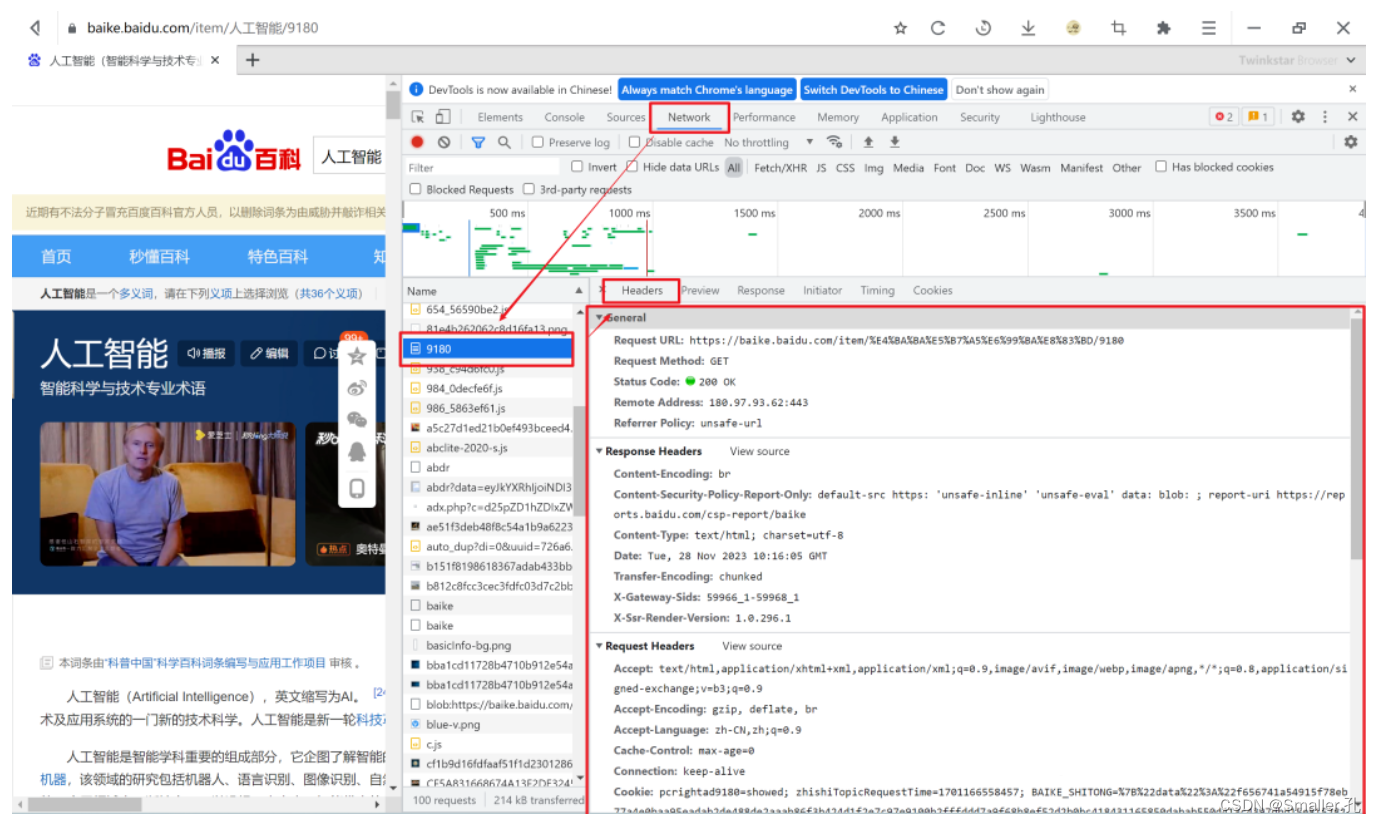
当你的请求得到了服务器的认可,他就会把数据包给你。
随便选一个网页,右键查看源代码就可以看到数据的样子。


可以看到,源数据密密麻麻,我们把需要的数据提取出来即可。
4、爬虫的难点
实际在浏览器和服务器交流的时候,浏览器的请求以及服务器的回复是非常多的。

这个我们通过F12开发者工具就可以看到,左侧的Name一栏就是浏览器与服务器的交互记录。
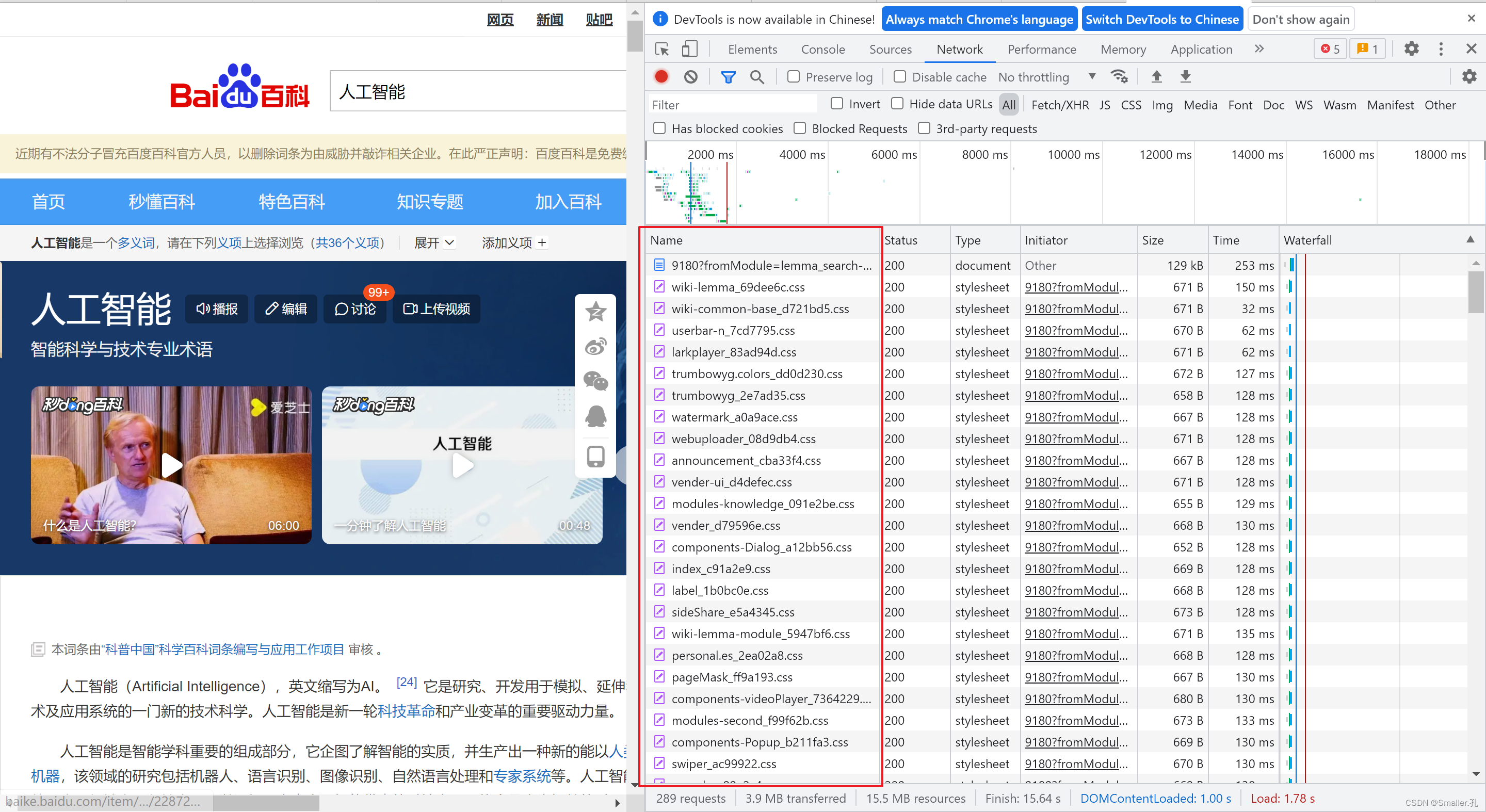
可以看到记录很多,而且不同的交互记录中,浏览器的请求数据和方式是不同的,没法一概而论。
所以难的就在于,我们如何从这些交互记录中找到带有我们需要数据的那几条。
然后才能模仿浏览器在获取目标数据时发送的请求,通过爬虫来构造去获取数据。
5、找记录
上面说了我们需要找到带有我们需要数据的交互记录。
那最笨的方法就是一条条的记录去看,别笑,对简单网页这方法最常用。
因为通常的静态网页中,浏览器直接能看到的主要内容都在第一条记录中了。
并且这条记录的Headers中的请求的URL就是我们网页的URL(最重要判断方式)
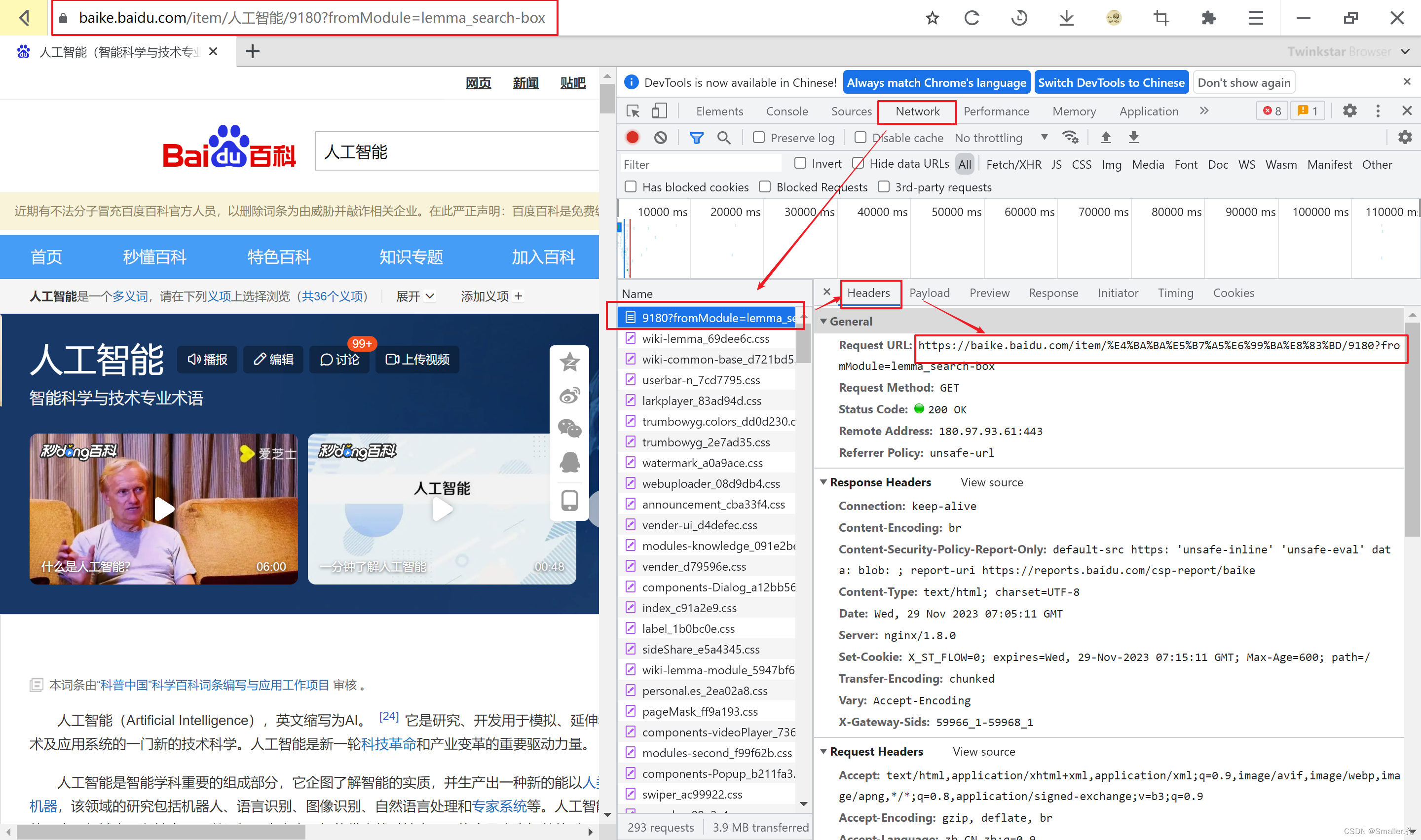
本篇文章中也只说这一种,其他方法都比较复杂,有空再述~
怎么识别该条记录中包含的数据?
方法:F12后—刷新一下—Network—点击任意记录—Preview/Response
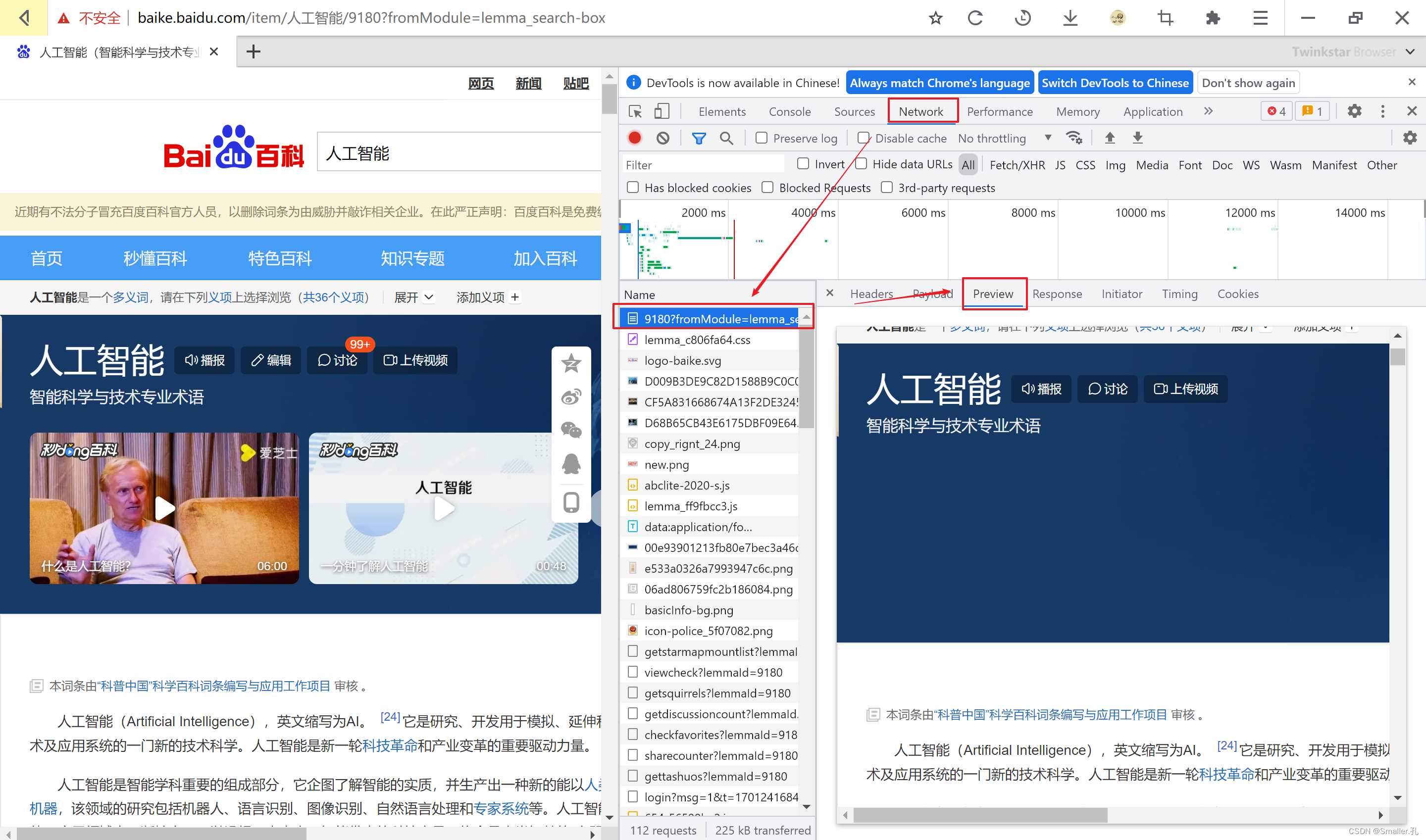
一般建议Preview看即可,这是浏览器渲染过的,容易查看;
Response下的是html格式,不容易查看。
OK,这样就找到了我们需要数据的记录。
6、模仿构造请求
找到目标记录后,我们就开始用代码模仿浏览器进行请求
打开记录的Headers,就可以看到浏览器请求时发送给服务器的数据。
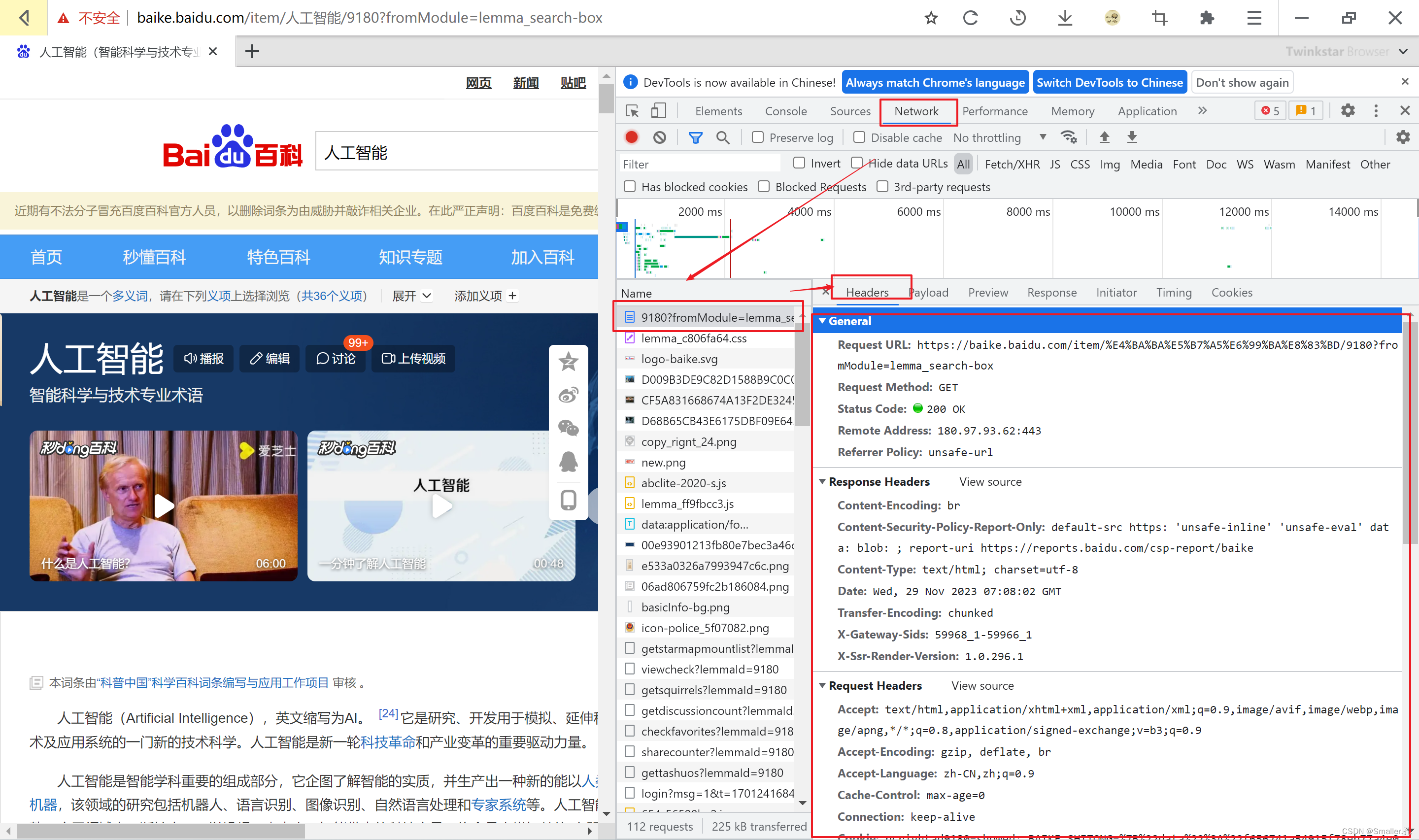
可以看到数据很多,而我们也不需要全都模仿,只需要模拟几个最重要的数据。
主要是:
URL:请求的网址(对应了服务器的数据存放位置)
Method:请求方式,常用get(不需要带数据),post(需要带数据)
User-Agent: 浏览器的标识,相当于爬虫的衣服。
Cookie(简单的可有可无)
对应到本案例中:
URL:
https://baike.baidu.com/item/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/9180
Method:get
User-Agent:Headers最底部
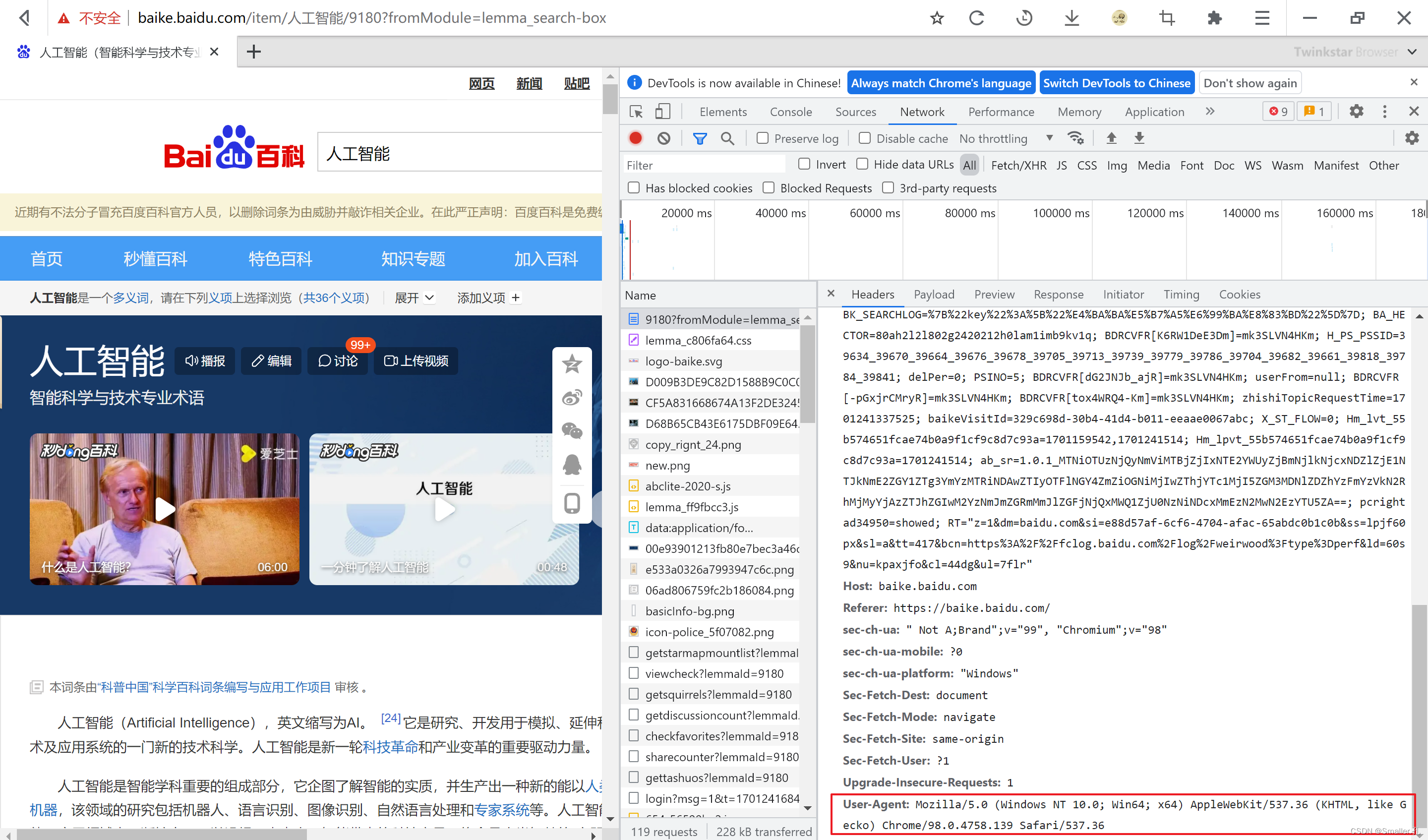
OK,明确了以上需要的请求数据,我们就开始写代码了。
7、用代码请求数据
需要用到的库是requests库
没有的安装即可:
pip install requests
把我们的url和User-Agent直接复制过来准备好:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36',
}
url='https://baike.baidu.com/item/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/9180'
请求方式为get,所以使用requests的get方法进行请求构造即可。
response=requests.get(url,headers=headers)
最后打印出text即可。
print(response.text)
完整代码如下:
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36',
}
url='https://baike.baidu.com/item/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/9180'
response=requests.get(url,headers=headers)
print(response.text)
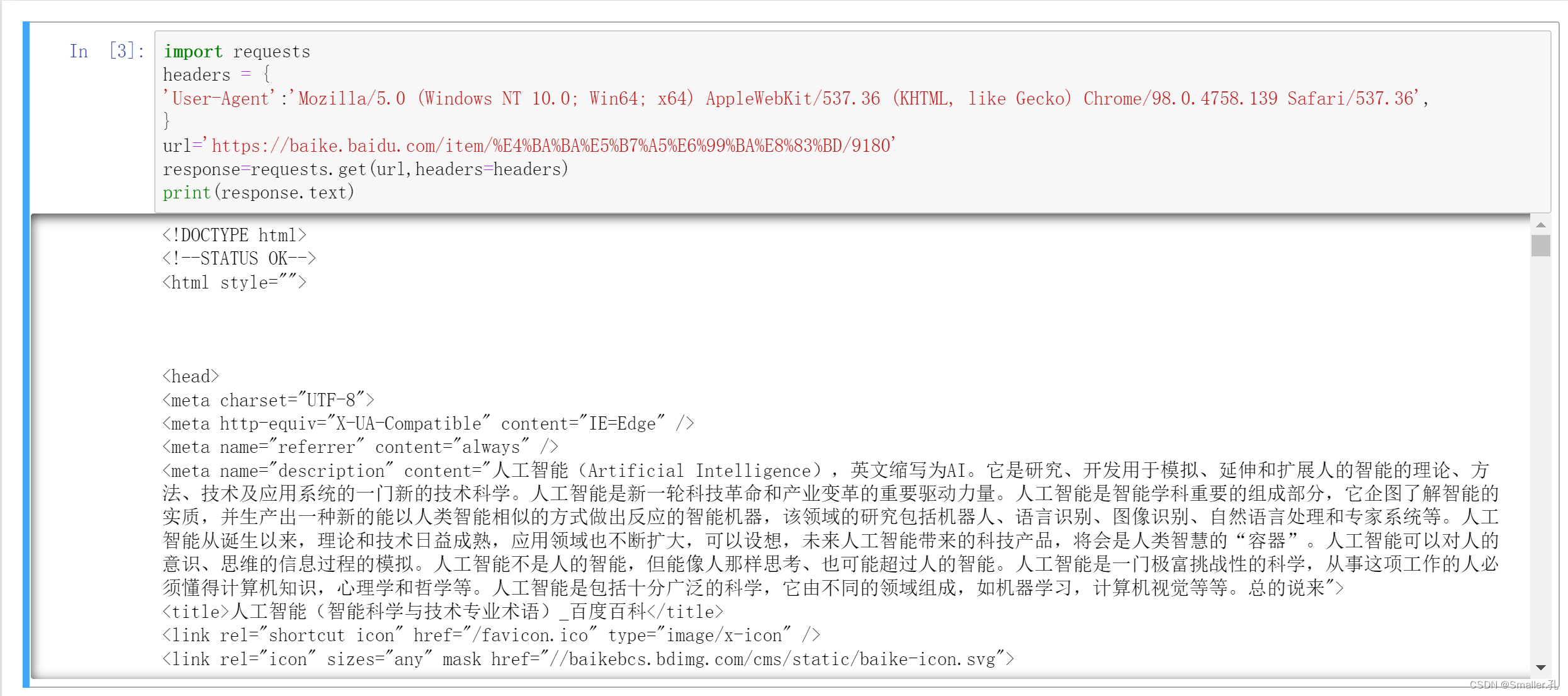
可以看到,获取的数据和我们浏览器右键查看网页源代码是一样的内容
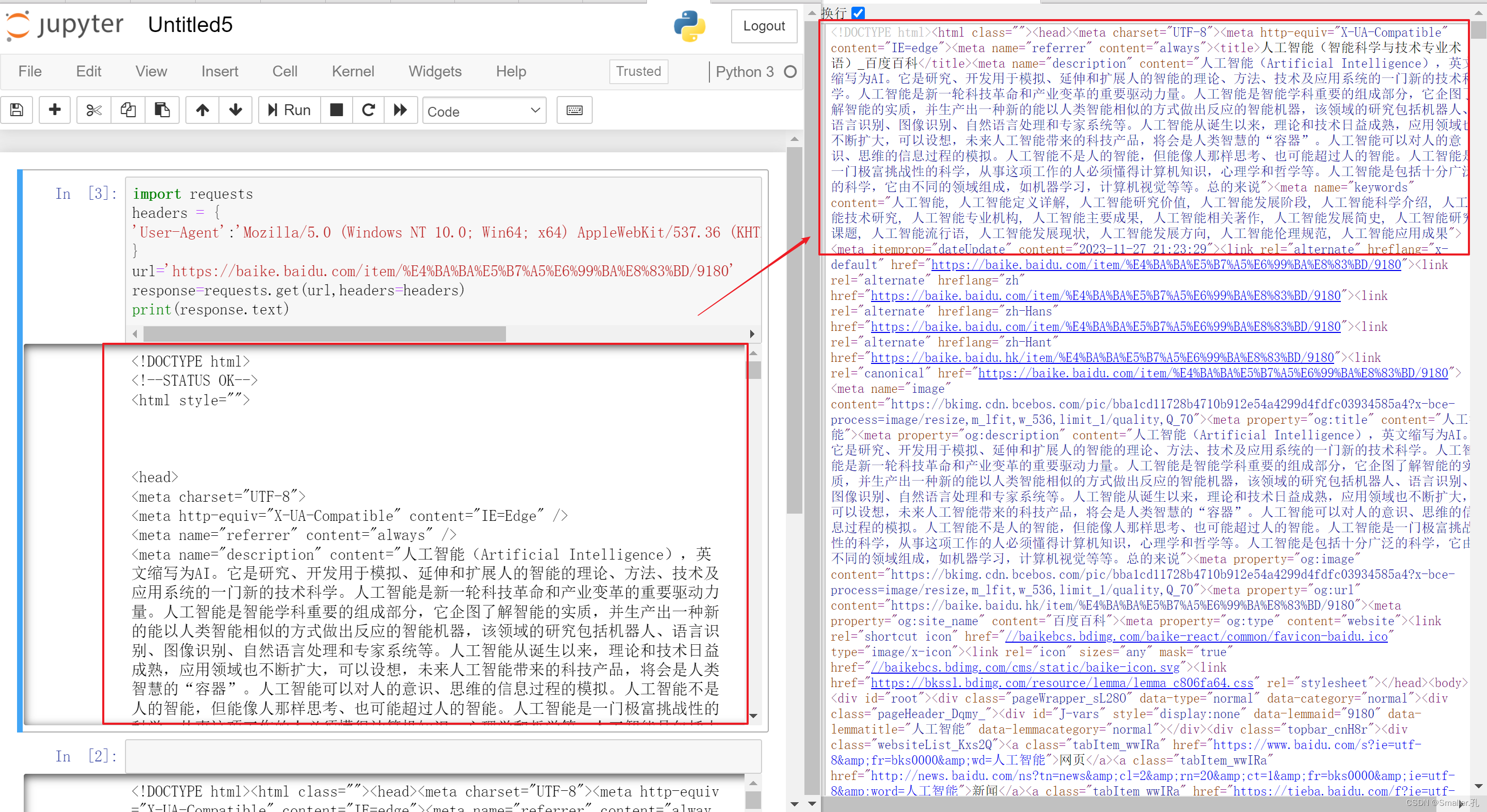
就说明我们成功把该条记录的数据爬取了下了。剩下的就是数据的清洗、提取和保存工作了。
内容过多,此篇就不展开了,留个坑,后续补上~
有所收益的话,欢迎点赞关注,感谢支持,持续更新~














 2438
2438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









