






Towards Discriminative Representation: Multi-view Trajectory Contrastive Learning for Online Multi-object Tracking为CVPR2022,由华中科技大学和清华大学产出的一篇文章,其主要贡献在MOT任务中利用Memory Bank对于每个目标轨迹形成一个中心特征,类似于该目标的全局特征,并使用了对比学习来增强目标特征,并对所属目标的中心特征进行迭代更新。此外,MTrack还设计了可学习视图采样Learnable view sampling(LVS),以对目标进行更精细的外观特征提取。
overview
我们知道,目前的跟踪模型受限于检测器的精度和对时序信息的融合,如下图所示,大部分跟踪模型只是依靠上一帧传递下来的信息来获取目标特征,然后进行推理。而当目标在上一帧被遮挡时,传递的特征所拥有的有效特征就会减少,以至于在下一帧中无法进行跟踪。目前,不少跟踪模型都在尝试利用时序信息来融合目标的特征,MTrack收集了目标在不同帧中的轨迹信息,利用轨迹信息不断更新目标的中心特征,以此寻找目标。

在这篇paper中,作者基于CenterNet实现了MTrack,采用DLA34作为backbone。首先给定一个ξ帧的视频序列 V ξ V_ξ Vξ作为输入,使用backbone提取特征图,然后建立多个网络头将特征图转换为目标的期望属性,包括2D中心热图、中心偏移量和边界框大小。此外,作者在检测头的基础上并联了一个额外的嵌入头来提取外观特征。检测边界框是基于估计的2D中心热图、中心偏移和边界框大小生成的。检测到的对象根据其外观特征相似性进行关联。
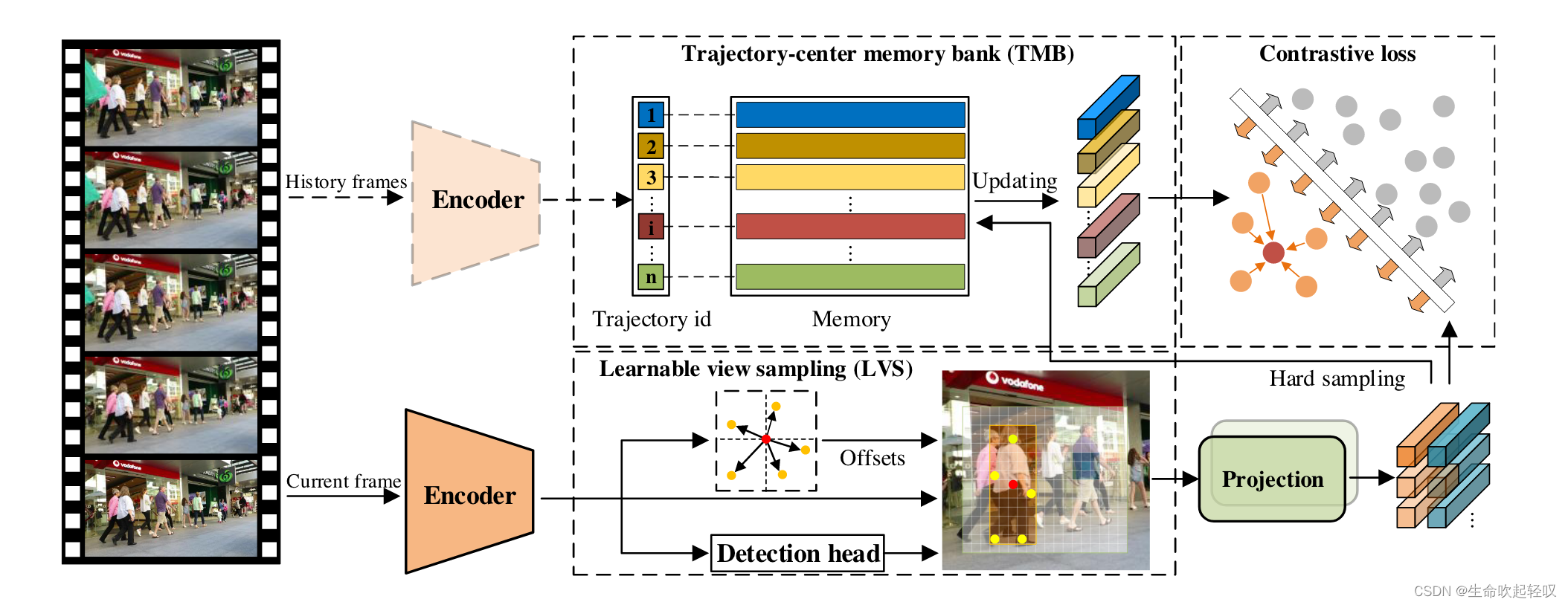
如上图所示,给定一个包含ξ帧 I t ( t = 1 , 2 , . . . , ξ ) I_t(t=1,2,...,ξ) It(t=1,2,...,ξ)的视频 V ξ V_ξ Vξ,Multi-view Trajectory contrastive learning包含4个步骤:
- 使用Encoder(backbone)从当前输入帧中提取特征图。
- 使用Learnable View Sampling从提取的特征图中选择信息丰富的特征点,并通过投影头将所选特征点的特征变换为目标外观向量。
- 对存储在memory bank中的外观向量和轨迹中心进行对比学习。
- 使用硬采样策略更新轨迹中心记忆库。
Multi-view Trajectory Contrastive Learning
在MTCL中,作者首先引入了LVS策略,该策略为每个目标自适应地生成多个外观向量,有助于更有效地利用帧内信息。Trajectory-center memory bank使得模型能够在计算资源有限的情况下实现轨迹对比学习,最后给出轨迹级对比学习的细节以及MTCL的整体流程。
Learnable view sampling
现有的基于CenterNet开发的跟踪器主要将每个目标表示为特征图上唯一的中心点,然而如下图所示,目标容易被其他物体所遮挡,这样提取的特征向量就无法完全反应目标的特征,并且仅仅使用一个向量表示每个目标不能为对比学习提供足够的样本。我们知道对比学习需要从大量的样本中学习,当样本量不足时,自然无法有效学习。

在此基础上,作者设计了LVS,将一个目标表示为多个自适应选择的关键点。给定视频的第t帧
I
t
I_t
It作为输入,首先使用backbone将其转为特征图
F
t
F_t
Ft,识别图中所有目标的中心点,记目标q在
F
t
F_t
Ft中的中心坐标为
Z
q
=
(
x
q
,
y
q
)
Z^q=(x^q,y^q)
Zq=(xq,yq),根据坐标在
F
t
F_t
Ft中提取中心点向量为
r
q
r^q
rq,其中包含了目标q的外观信息,因此可以通过线性变换W将
Z
q
Z^q
Zq的偏移量回归到
I
t
I_t
It中潜在的信息关键点:
Δ
Z
q
=
W
r
q
\Delta Z^q = Wr^q
ΔZq=Wrq
其中
Δ
Z
q
=
{
Δ
Z
i
q
}
i
=
1
N
k
,
N
k
\Delta Z^q=\{\Delta Z^q_i\}^{N_k}_{i=1},N_k
ΔZq={ΔZiq}i=1Nk,Nk表示所选关键点的全部数量,
Δ
Z
i
q
\Delta Z^q_i
ΔZiq则表示从
Z
q
Z^q
Zq到第i个关键点的偏移量。因此,第i哥关键点的坐标可以表示为:
Z
i
k
=
Φ
(
Z
q
+
Δ
Z
i
q
)
Z^k_i=\Phi(Z^q+\Delta Z^q_i)
Zik=Φ(Zq+ΔZiq)
其中
Φ
\Phi
Φ保证所有关键点落在边界框之内。
根据第i个关键点的坐标 Z i k Z^k_i Zik,我们可以从 F t F_t Ft中获得其对应的特征向量 v i k v^k_i vik,然后通过由4个全连接层组成的投影头,进一步将 v i k v^k_i vik转换为更具代表性的外观向量 v i k ~ \widetilde{v^k_i} vik 。由于为每个目标选取了 N k N_k Nk个关键点,因此可以得到目标不同位置对应的 N k N_k Nk个外观向量。将每个检测到的目标表示为这些 N k N_k Nk个外观向量,可以为对比学习提供更丰富的帧内样本。在推理中,这些外观向量将作为一个单独的向量表示目标。
Trajectory-center memory bank
如果将历史帧中所有样本作为对比学习的样本,那么对于计算资源的消耗是非常大的。为了解决这个问题,作者提出了Trajectory-center memory bank,将每条轨迹表示为一个trajectory center的向量,并将所有trajectory center都保存在memory bank中。
假设训练数据中有N条轨迹,在每个epoch开始时,memory bank初始化为包含N个零向量 { c i } i = 1 N \{c_i\}^N_{i=1} {ci}i=1N的集合。当epoch结束后,重新对其初始化。为了节省显存,作者没有保存所有迭代的梯度信息,而是提出了一种基于动量的更新策略(类似于MoCo),在每次迭代中动态更新轨迹中心,而不需要梯度信息。
对于输入的多帧视频序列,模型为每个实例生成
N
k
N_k
Nk个外观向量,并为多帧中所有实例标记轨迹ID,对于轨迹ID相同的实例中提取所有外观向量来更新trajectory center。将第l条轨迹对应批次中的所有外观向量表示为
P
l
=
{
p
i
l
}
i
=
1
N
t
P^l=\{p^l_i\}^{N_t}_{i=1}
Pl={pil}i=1Nt,选择其中与trajectory center余弦相似度最小的样本更新
c
l
c_l
cl。余弦相似度计算为:
s
i
l
=
p
i
l
⋅
c
l
∣
∣
p
i
l
∣
∣
2
×
∣
∣
c
l
∣
∣
2
s^l_i=\frac{p^l_i·c_l}{||p^l_i||_2\times||c_l||_2}
sil=∣∣pil∣∣2×∣∣cl∣∣2pil⋅cl
将余弦相似度最小的外观向量表示为
p
m
l
p^l_m
pml,更新公式为:
c
l
←
α
c
l
+
(
1
−
α
)
p
m
l
c_l\leftarrow\alpha c_l+(1-\alpha )p^l_m
cl←αcl+(1−α)pml
Trajectory-level contrastive loss
该文的一大亮点在于在MOT中引入了对比学习,其实对比学习在多目标跟踪中已经有尝试(QDTrack)。在该文中,LVS和TMB为对比学习提供了丰富的帧内和帧间样本,接下来就要实现对比学习的损失设计,并训练网络的嵌入头以产生判别式表示。
对于LVS产生的第k个外观向量
v
i
k
~
\widetilde{v^k_i}
vik
及其对应的trajectory center
c
l
c_l
cl,优化目标是使
v
i
k
~
\widetilde{v^k_i}
vik
靠近
c
l
c_l
cl,同时远离其他轨迹中心。
v
i
k
~
\widetilde{v^k_i}
vik
的损失可以表示为:
L
N
C
E
k
=
−
l
o
g
e
x
p
(
v
i
k
~
⋅
c
l
)
/
τ
∑
i
=
0
N
t
e
x
p
(
v
i
k
~
⋅
c
i
)
/
τ
L^k_{NCE}=-log\frac{exp(\widetilde{v^k_i}·c_l)/\tau}{\sum_{i=0}^{N_t}exp(\widetilde{v^k_i}·c_i)/\tau}
LNCEk=−log∑i=0Ntexp(vik
⋅ci)/τexp(vik
⋅cl)/τ
其中
τ
\tau
τ为超参数,
N
t
N_t
Nt为总的轨迹数量。为了充分利用帧间信息,作者计算每个外观向量的轨迹级对比损失:
L
t
c
l
=
1
N
a
∑
k
=
1
N
a
L
N
C
E
k
L_{tcl}=\frac{1}{N_a}\sum_{k=1}^{N_a}L^k_{NCE}
Ltcl=Na1k=1∑NaLNCEk
其中
N
a
N_a
Na为总的外观向量数量。总的损失为:
L
=
1
2
(
1
e
η
1
L
d
e
t
+
1
e
η
2
L
t
c
l
+
η
1
+
η
2
)
L=\frac{1}{2}(\frac{1}{e^{\eta_1}}L_{det}+\frac{1}{e^{\eta_2}}L_{tcl}+\eta_1+\eta_2)
L=21(eη11Ldet+eη21Ltcl+η1+η2)
其中
L
d
e
t
L_{det}
Ldet表示检测损失,
η
1
、
η
2
\eta_1、\eta_2
η1、η2为可学习权重,用以平衡
L
d
e
t
L_{det}
Ldet和
L
t
c
l
L_{tcl}
Ltcl。
模型训练伪代码如下图所示:

Similarity-guided Feature Fusion
在推理阶段,现有的模型往往使用动量更新策略来更新轨迹表示,如:
f
l
t
=
(
1
−
β
)
f
l
t
−
1
+
β
z
l
t
f^t_l=(1-\beta )f^{t-1}_l+\beta z^t_l
flt=(1−β)flt−1+βzlt
其中
f
l
t
、
f
l
t
−
1
、
z
l
t
、
β
f^t_l、f^{t-1}_l、z^t_l、\beta
flt、flt−1、zlt、β分别为第l条轨迹在t-1和t帧的表示,用于更新的目标特征向量和超参数。
β
\beta
β往往为静态变量,但是当特征向量由于遮挡等问题,包含了噪声,有效信息减少时,更新就变得有害。
因此,作者提出了自适应调整每一帧
β
\beta
β的SGFF,根据
z
l
t
z^t_l
zlt与最近Q帧中的特征向量的相似性来衡量
z
l
t
z^t_l
zlt的质量。如下图所示,在该策略中,根据
z
l
t
z^t_l
zlt与最近帧提取的特征之间的相似性,对每一帧自适应地调整
β
t
\beta^t
βt。如果相似,则推测向量包含信息,
β
\beta
β可以是一个很大的值:
β
t
=
m
a
x
{
0
,
1
Q
∑
i
=
1
Q
Ψ
d
(
z
l
t
,
z
l
t
−
i
)
}
\beta^t=max\{0,\frac{1}{Q}\sum_{i=1}^{Q}\Psi_d(z^t_l,z^{t-i}_l)\}
βt=max{0,Q1i=1∑QΨd(zlt,zlt−i)}
其中
Ψ
d
\Psi_d
Ψd表示一个计算余弦相似度的蒜子,在SGFF下,如果
z
l
t
z^t_l
zlt质量较差,那么
β
\beta
β就会变成一个很小的值,该策略降低了较差特征向量的影响。

Conclusion
在这篇工作中,融合了多帧中整个轨迹的信息,充分挖掘了帧内特征和帧间特征,利用对比学习提取表征的可辨别性。在推理阶段,提出SGFF,减少了质量较差的特征对轨迹中心向量的负面影响。经过实验表明,这些方法能够显著地提高跟踪性能。















 1993
1993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









