






SMILEtrack: SiMIlarity LEarning for Multiple Object Tracking是22年11月17日挂载于arXiv的最新论文,并且在MOT17上达到了SOTA。文章提出了SMILEtrack模型,该模型是基于Tracking-By-Detection(TBD) + Separate Detection and Embedding model (SDE)范式的。
SDE至少要求两个模块:一个检测头和一个re-identification model 。首先,检测器定位目标位置,然后re-id模型从每个bbox中提取目标的特征生成embedding。最后,将这些bbox与现有的跟踪轨迹关联。
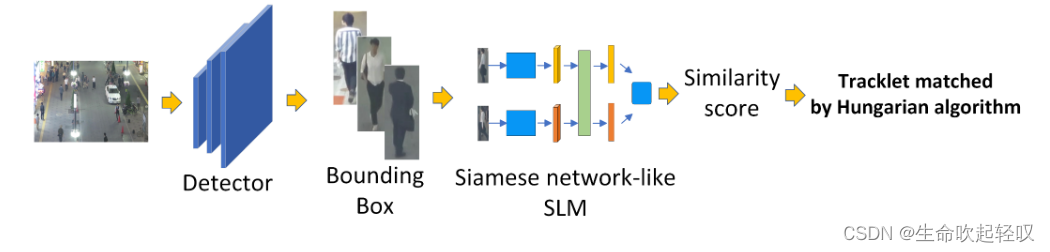
该文章的贡献如下:
- 推出了基于SDE范式的SMILEtrack模型,并使用Similarity Learning Module(SLM)学习每个目标的相似度。
- 对于SLM中的特征提取部分,该文构建了Image Slicing Attention Block(ISA),利用了ViT中的图像切片技术和Transformer的注意力机制学习目标特征。
- 为了完成跟踪匹配,该文构建了Similarity Matching Cascade (SMC)模块来为每帧中的bbox进行关联。
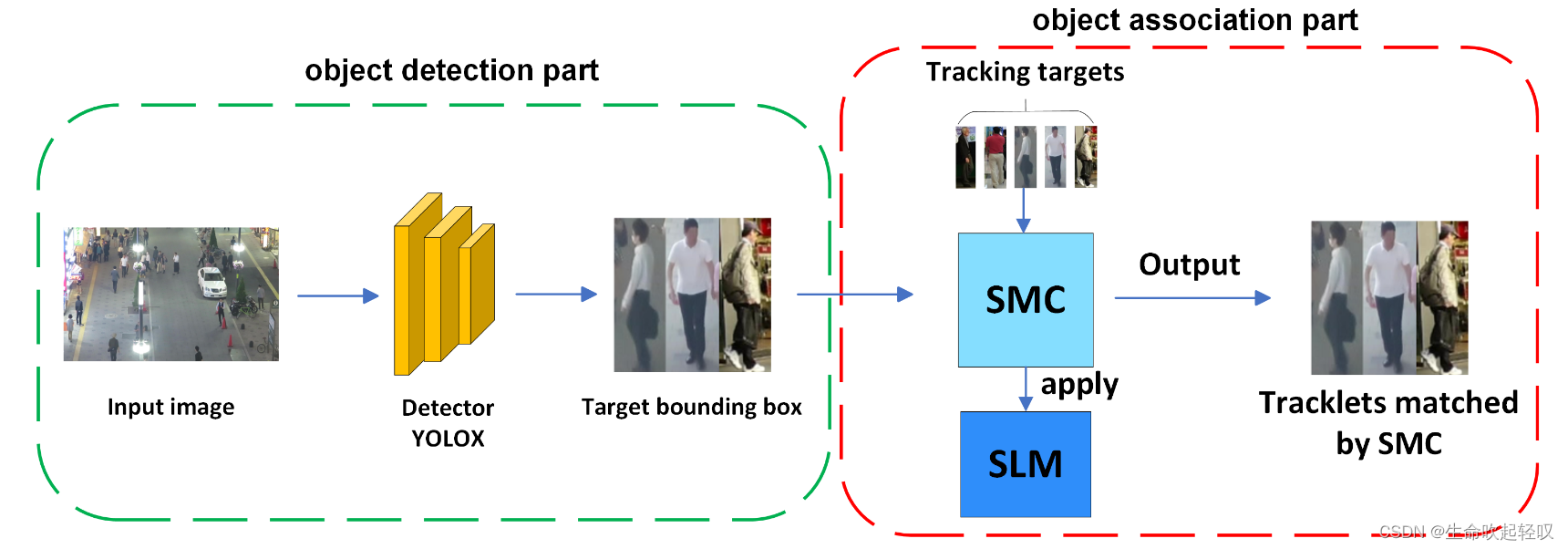
SMILEtrack网络架构如下,整体分为两个部分:
- 使用PRB检测头定位目标位置。
- 数据关联:MOT问题通过关联相邻帧中的每个对象来实现。在得到PRB生成的检测结果后,计算每一帧之间的运动相似度矩阵和外观相似度矩阵,结合代价矩阵通过匈牙利算法求解线性分配问题。
SLM for Re-ID
想要实现跟踪的鲁棒性,目标的外观信息是不可或缺的。该文提出了Similarity Learning Module(SLM)来提取目标的外貌信息。
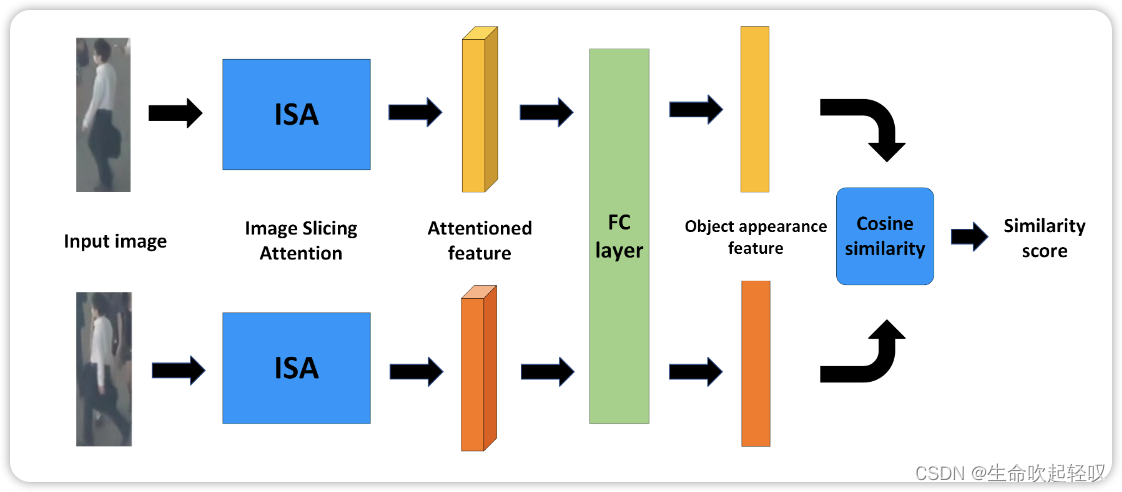
首先将两张不同图像同时输入SLM中,首先它们会经过一个共享权重的ISA模块,得到各自的注意力特征,然后使用全连接层对特征进行聚合,然后使用余弦相似度距离计算出两张图像的相似度得分,同一个目标相似度得分越高。
ISA
尽管Transformer在特征增强上有着显著的效果,但是将一个完整的encoder-decoder结构移植到SLM中未免使得网络太过臃肿,受到ViT的启发,该文作者设计了ISA模块,将图像切片技术和注意力机制应用到特征提取中。
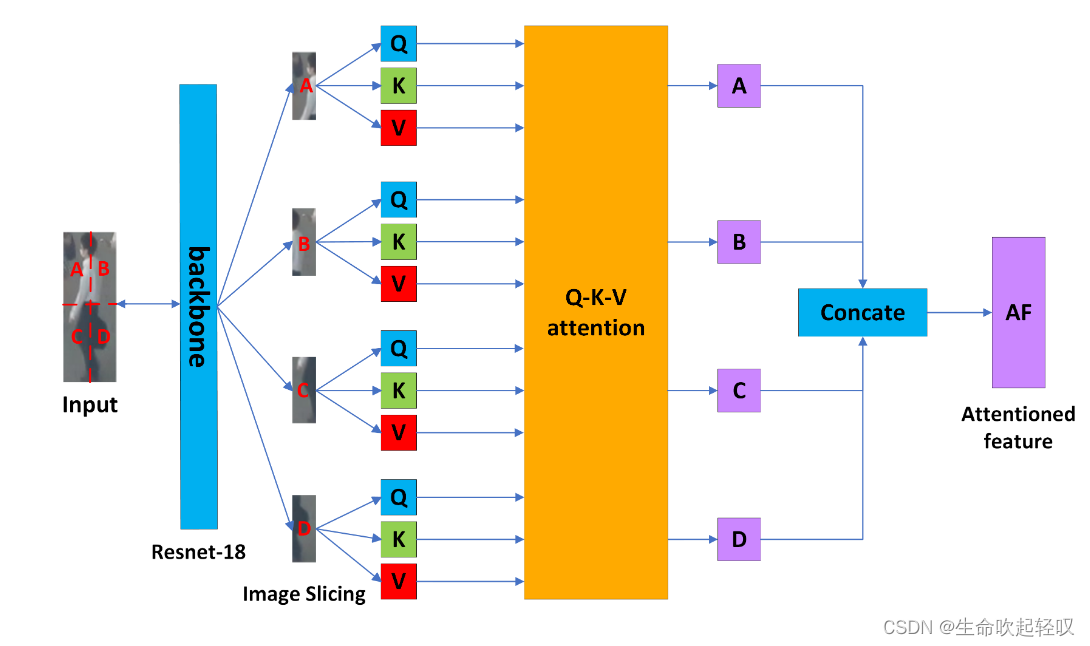
Image Slicing
由于每一个目标的bbox尺寸不同,所以首先将它们resize到同一大小。然后使用resnet-18生成特征图,然后将其分为左上、右上、左下、右下四个部分,然后对于每一个切片,分别加上1D position embedding。最后我们得到具有位置信息的特征图切片,作为attention block的输入。
The Q-K-V attention block
得到特征图切片后,将它们输入全连接层以得到Q、K、V矩阵,然后输入attention block进行注意力计算:
S
A
=
S
A
(
Q
S
1
,
K
S
1
,
V
S
1
)
+
C
A
(
Q
S
1
,
K
S
2
,
V
S
2
)
+
C
A
(
Q
S
1
,
K
S
3
,
V
S
3
)
+
C
A
(
Q
S
1
,
K
S
4
,
V
S
4
)
S_A=SA(Q_{S1},K_{S1},V_{S1})+CA(Q_{S1},K_{S2},V_{S2})+CA(Q_{S1},K_{S3},V_{S3})+CA(Q_{S1},K_{S4},V_{S4})
SA=SA(QS1,KS1,VS1)+CA(QS1,KS2,VS2)+CA(QS1,KS3,VS3)+CA(QS1,KS4,VS4)
S
B
=
S
A
(
Q
S
2
,
K
S
2
,
V
S
2
)
+
C
A
(
Q
S
2
,
K
S
1
,
V
S
1
)
+
C
A
(
Q
S
2
,
K
S
3
,
V
S
3
)
+
C
A
(
Q
S
2
,
K
S
4
,
V
S
4
)
S_B=SA(Q_{S2},K_{S2},V_{S2})+CA(Q_{S2},K_{S1},V_{S1})+CA(Q_{S2},K_{S3},V_{S3})+CA(Q_{S2},K_{S4},V_{S4})
SB=SA(QS2,KS2,VS2)+CA(QS2,KS1,VS1)+CA(QS2,KS3,VS3)+CA(QS2,KS4,VS4)
S
C
=
S
A
(
Q
S
3
,
K
S
3
,
V
S
3
)
+
C
A
(
Q
S
3
,
K
S
1
,
V
S
1
)
+
C
A
(
Q
S
3
,
K
S
2
,
V
S
2
)
+
C
A
(
Q
S
3
,
K
S
4
,
V
S
4
)
S_C=SA(Q_{S3},K_{S3},V_{S3})+CA(Q_{S3},K_{S1},V_{S1})+CA(Q_{S3},K_{S2},V_{S2})+CA(Q_{S3},K_{S4},V_{S4})
SC=SA(QS3,KS3,VS3)+CA(QS3,KS1,VS1)+CA(QS3,KS2,VS2)+CA(QS3,KS4,VS4)
S
D
=
S
A
(
Q
S
4
,
K
S
4
,
V
S
4
)
+
C
A
(
Q
S
4
,
K
S
1
,
V
S
1
)
+
C
A
(
Q
S
4
,
K
S
2
,
V
S
2
)
+
C
A
(
Q
S
4
,
K
S
3
,
V
S
3
)
S_D=SA(Q_{S4},K_{S4},V_{S4})+CA(Q_{S4},K_{S1},V_{S1})+CA(Q_{S4},K_{S2},V_{S2})+CA(Q_{S4},K_{S3},V_{S3})
SD=SA(QS4,KS4,VS4)+CA(QS4,KS1,VS1)+CA(QS4,KS2,VS2)+CA(QS4,KS3,VS3)
其中
Q
S
i
Q_{Si}
QSi指
S
i
Si
Si的query矩阵,
S
A
SA
SA指self-attention,
C
A
CA
CA指cross-attention。
在计算得到4个切片的注意力特征后,再将其进行Concate操作得到该目标的注意力特征。
Similarity Matching Cascade (SMC) for Target Tracking
作者提出,在数据关联中仅仅使用IoU距离会导致一些问题,例如当场景拥挤时,id-switch将会变得很频繁。由此,作者结合ByteTrack(使用IoU距离)和本文中的SLM设计了SMC进行匹配。
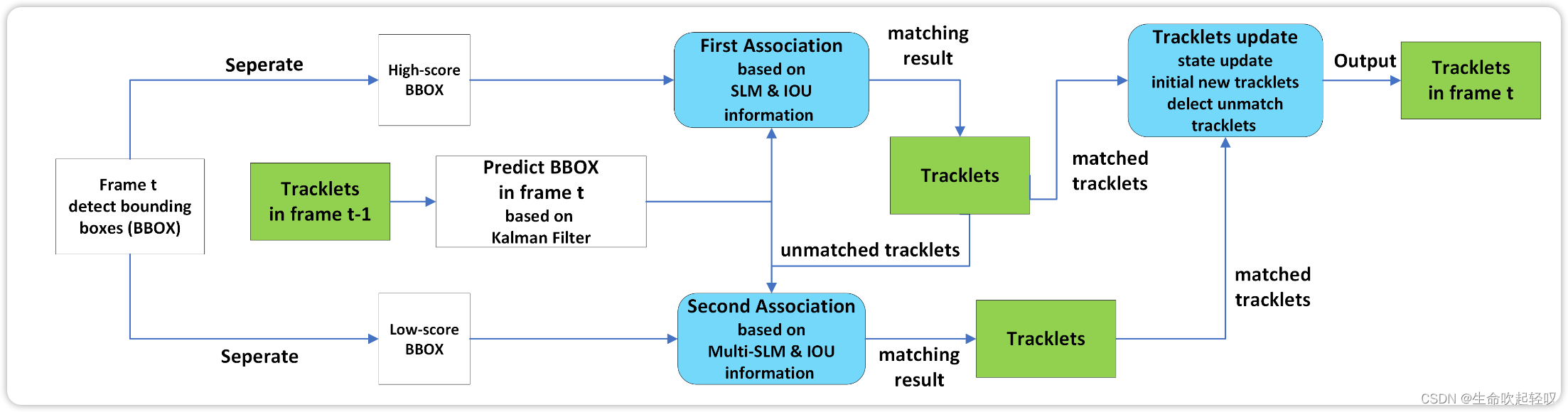
如上图所示,首先确定第t帧中的bbox,然后根据thres将其划分为High-score bbox和Low-score bbox两部分。然后把丢失的目标列表LL和跟踪目标列表TL进行融合,使用卡尔曼滤波器预测TL中的目标在当前帧的位置。接下来的匹配部分分为两个阶段:
**stage 1:**计算出TL和
D
h
i
g
h
D_{high}
Dhigh之间的the motion matrix
M
m
M_m
Mm and appearance similarity matrix
M
a
M_a
Ma,然后计算得到
C
h
i
g
h
:
C_{high}:
Chigh:
C
h
i
g
h
=
M
m
(
i
,
j
)
−
(
1
−
M
a
(
i
,
j
)
)
C_{high}=M_m(i,j)-(1-M_a(i,j))
Chigh=Mm(i,j)−(1−Ma(i,j))
然后,在第一阶段匹配中,利用匈牙利算法结合cost矩阵
C
h
i
g
h
C_{high}
Chigh完成线性分配。
D
h
i
g
h
D_{high}
Dhigh中未能完成匹配的目标和TL中未能完成匹配的轨迹放入
D
r
e
m
a
i
n
D_{remain}
Dremain和
T
L
r
e
m
a
i
n
TL_{remain}
TLremain中。
**stage 2:**第二阶段对
D
r
e
m
a
i
n
D_{remain}
Dremain和
T
L
r
e
m
a
i
n
TL_{remain}
TLremain进行匹配,the motion matrix
M
m
M_m
Mm的计算和第一阶段相同,appearance similarity matrix
M
a
M_a
Ma则使用了multi-template-SLM方法,保存轨迹在一段时间中的特征
f
i
f_i
fi,然后使用最大的
M
a
(
i
,
j
)
M_a(i,j)
Ma(i,j),这是因为
D
l
o
w
D_{low}
Dlow中的目标特征会因为遮挡等原因导致每帧的特征不尽相同。接着和第一阶段相同,对
D
r
e
m
a
i
n
D_{remain}
Dremain和
T
L
r
e
m
a
i
n
TL_{remain}
TLremain进行匹配。未能匹配的放入
D
R
R
e
m
a
i
n
D_{RRemain}
DRRemain和
T
L
R
R
e
m
a
i
n
T L_{RRemain}
TLRRemain。
在完成目标关联阶段后,作者设置了一个阈值H来初始化新的轨迹。 D R e m a i n D_{Remain} DRemain中得分高于H的未匹配检测可以初始化新的轨迹,并将 T L R R e m a i n TL_{RRemain} TLRRemain中的未匹配轨迹移动到丢失的目标列表LL中。将未匹配的检测 D R R e m a i n D_{RRemain} DRRemain作为背景。只有当LL中存在30帧以上的轨迹时,才删除LL中的轨迹。
总结
在SMILEtrack中,提出了基于注意力机制的SLM来计算目标的外貌特征,然后在目标匹配中利用目标间的外貌相似度进行匹配,开发了一个相似性匹配级联( SMC ),用于每帧中的边界框关联。实验表明,SMILEtrack在MOT17上取得了较高的MOTA、IDF1和IDs性能得分。由于SMILEtrack是一种单独的检测和嵌入( SDE )方法,其运行速度比联合检测和嵌入( JDE )方法慢。总体而言,也是非常不错的工作。















 1517
1517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









