



前言
上一篇介绍了直接安装并使用CTGAN作为独立库
现在来试试官方推荐的通过 SDV 库中的CTGANSynthesizer模块来实践 CTGAN 方法
三者的区别:
SDV(Synthetic Data Vault)即合成数据库,是 DataCebo 公司开发的开源 Python 库,用于生成合成数据,在数据隐私保护、模型训练等领域应用广泛。
CTGAN 是基于生成对抗网络(GAN)的一种用于数据建模的技术,核心是利用生成器和判别器对抗训练来学习数据分布。CTGAN 专注于实现数据分布学习和生成的算法逻辑。在训练过程中,生成器尝试生成逼真的数据,判别器则判断数据是真实的还是生成的,通过不断对抗训练优化二者性能,以达到生成数据接近真实数据分布的目的。
CTGANSynthesizer 是 SDV(Synthetic Data Vault)库中的一个类,是基于 CTGAN 技术实现的合成器,用于生成合成数据。可以说 CTGANSynthesizer 是对 CTGAN 技术进行封装和集成,使其更便于在特定的数据合成场景中使用的工具。
在CTGAN的github官网上推荐使用SDV来实践CTGAN
https://github.com/sdv-dev/CTGAN?tab=readme-ov-file
实践部分(截图均来自官网)
一、数据处理及元数据获取
1. 数据处理
下面仍然以HCI_data进行实践
数据集获取及介绍请参见:
# 准备原始数据
hci_data=pd.read_csv(r'HCI_Datasheet.csv')
hci_data=hci_data.drop(columns=['S. No','Decision Date','Application Date'])
# 创建了一个新的列 'University_Program',其值是 'University' 列和 'Programme' 列的值用空格连接起来的结果
hci_data['University_Program']=hci_data.University+' '+hci_data.Programme
hci_data.University=hci_data.University_Program
hci_data=hci_data.drop(columns=['Programme','University_Program','Year of Entry'])
# fillna 方法将缺失值替换为指定的值
hci_data['GRE']=hci_data['GRE'].fillna(330)
hci_data['TOEFL']=hci_data['TOEFL'].fillna(120)
print("转化类别标签及替换缺失值后的数据",hci_data)
print("增删列后的数据",hci_data)2.元数据获取及修正

元数据识别在使用 CTGANSynthesizer 及数据处理中作用主要有:
1.助于理解数据,可以确定每列数据的类型,例如是数值型(整数、浮点数)、文本型、日期型等。这有助于 CTGANSynthesizer 采用合适的方法对不同类型的数据进行建模和生成。
2.能指导合成过程,可以让 CTGANSynthesizer 针对不同的数据特征选择更合适的合成算法和参数。
3.可确保质量一致,在生成合成数据之前,可以利用识别到的元数据对原始数据进行验证,检查数据是否符合预期的格式和规则。
4. 还可以将一些约束添加在元数据中,比如这里我可以要求QS Rank这一列生成的数值全部为21(见 二 - 3.增加约束)
好消息是,官网提供了自动检测元数据的方法Metadata.detect_from_dataframe
坏消息是检测的结果不一定准确,所以需要手动修正
# 自动检测元数据
metadata = Metadata.detect_from_dataframe(data=hci_data, table_name='hci_data')
# 手动修正元数据
metadata.update_column(column_name='Work Experience', sdtype='categorical')
metadata.update_columns(
column_names=['Research Papers','Class Size', 'THE Rank', 'QS Rank'],
sdtype='numerical')
# 将元数据对象保存为 JSON 文件并再次加载以供将来使用
os.remove('metadata_v1.json')
metadata.save_to_json(filepath='metadata_v1.json')
metadata = Metadata.load_from_json(filepath='metadata_v1.json')但我怎么知道元数据可以是哪些类型呢?请参考官网回答:
Sdtypes | Synthetic Data Vault
有些小朋友不想参考的,请看我的截图:

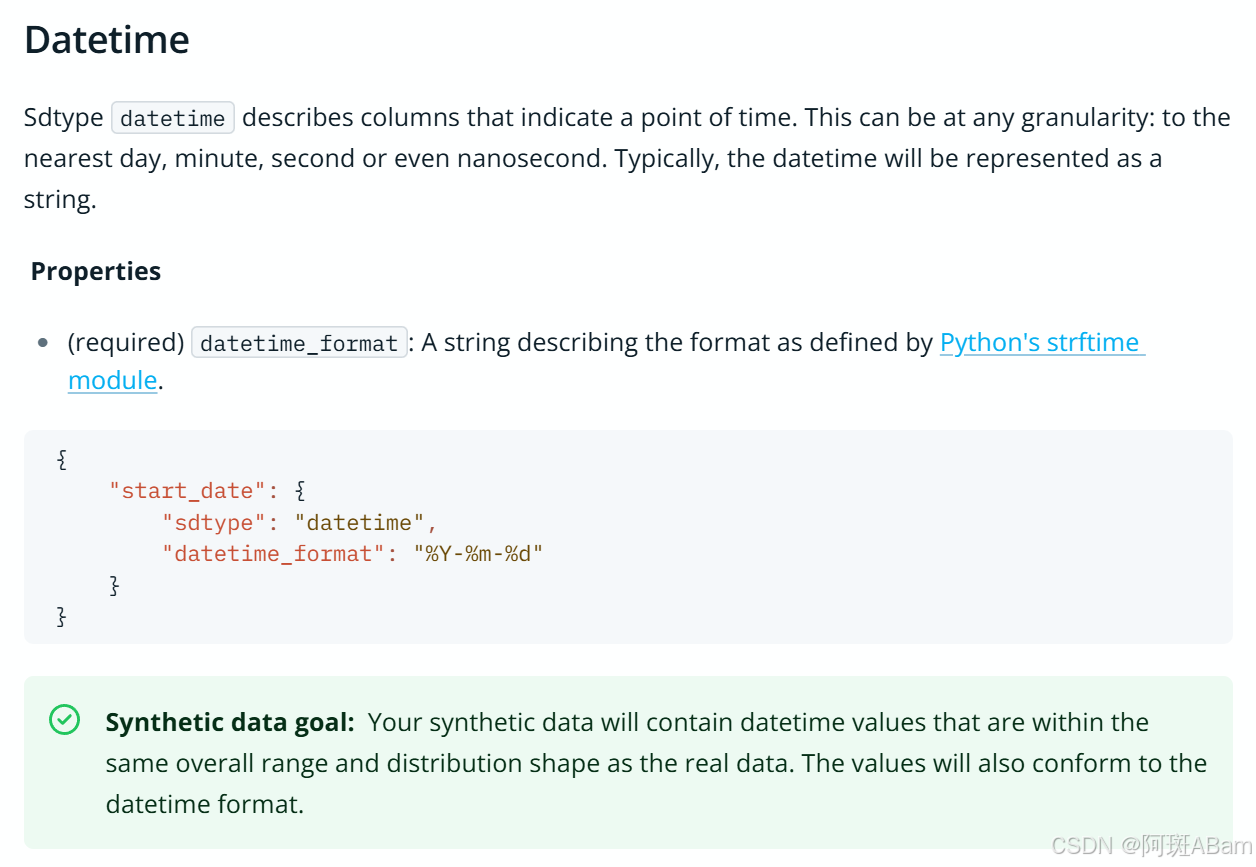



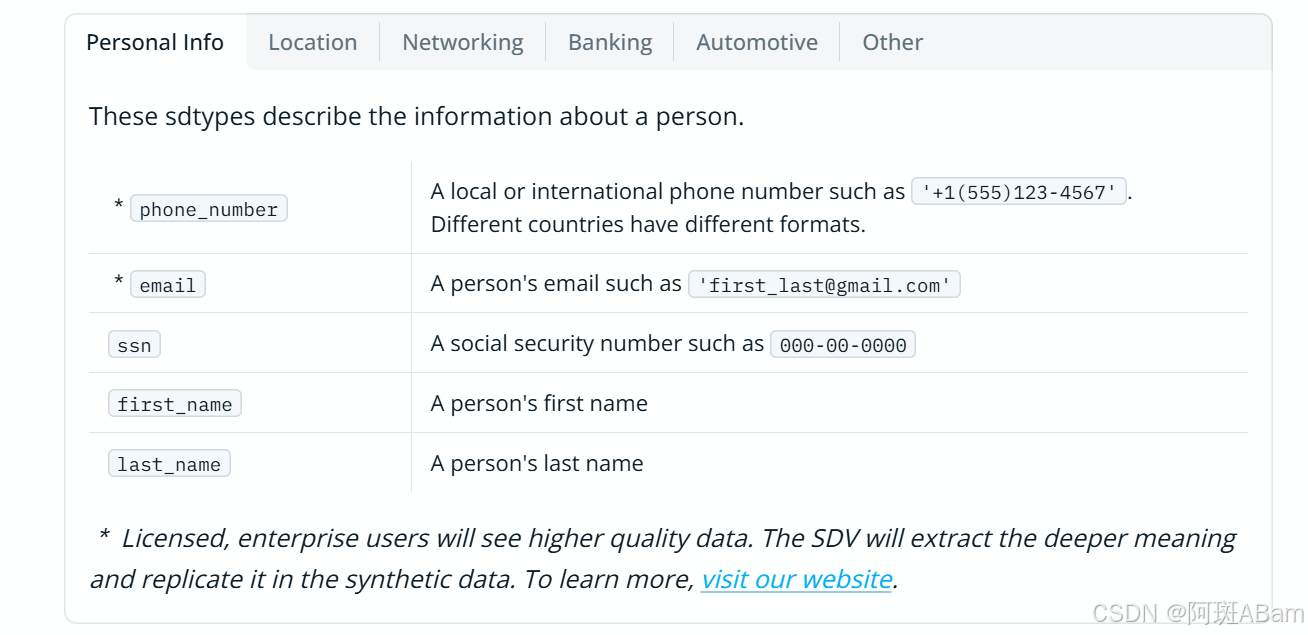
总的来说,主要分为布尔值,分类,时间,数值,ID,领域特定概念及敏感身份信息(PII)
还包括一些小众的类型:
二、创建CTGAN合成器
1.CTGANSynthesizer 的介绍
请参见官网:
CTGANSynthesizer | Synthetic Data Vault
该模块涉及的主要参数有:


其他一些超参数及默认值:

2.CTGANSynthesizer 实例化
首先创建一个 CTGANSynthesizer 类的实例 synthesizer。
在创建实例时,必须传入 metadata 对象,该对象描述了数据的结构和约束信息,
例如列的数据类型、列之间的关系、约束条件等。
CTGANSynthesizer 会根据这些元数据来生成符合要求的合成数据
然后传入其他参数:
enforce_min_max_values=True,针对全局所有列,确保所有数值列生成的值都落在原始真实数据中对应列的最小值和最大值范围内
enforce_rounding=True,针对全局所有列,合成数据中各列的小数位数会和原始数据中对应列的小数位数保持一致。
verbose:控制是否打印每个训练时期的结果,True 打印生成器和鉴别器的损失值,便于跟踪训练情况;False 则不打印
from sdv.single_table import CTGANSynthesizer
synthesizer = CTGANSynthesizer(
metadata, # required
enforce_min_max_values=True,
enforce_rounding=True,
epochs=1500,
verbose=True
)3. 增加约束
我们知道,CTGAN的特点之一是可以考虑对生成数据增加约束
请看官方提供的对数据的约束类型 (官网贴心地区分了单表和多表分别的用法)
Predefined Constraints | Synthetic Data Vault
主要截图如下:
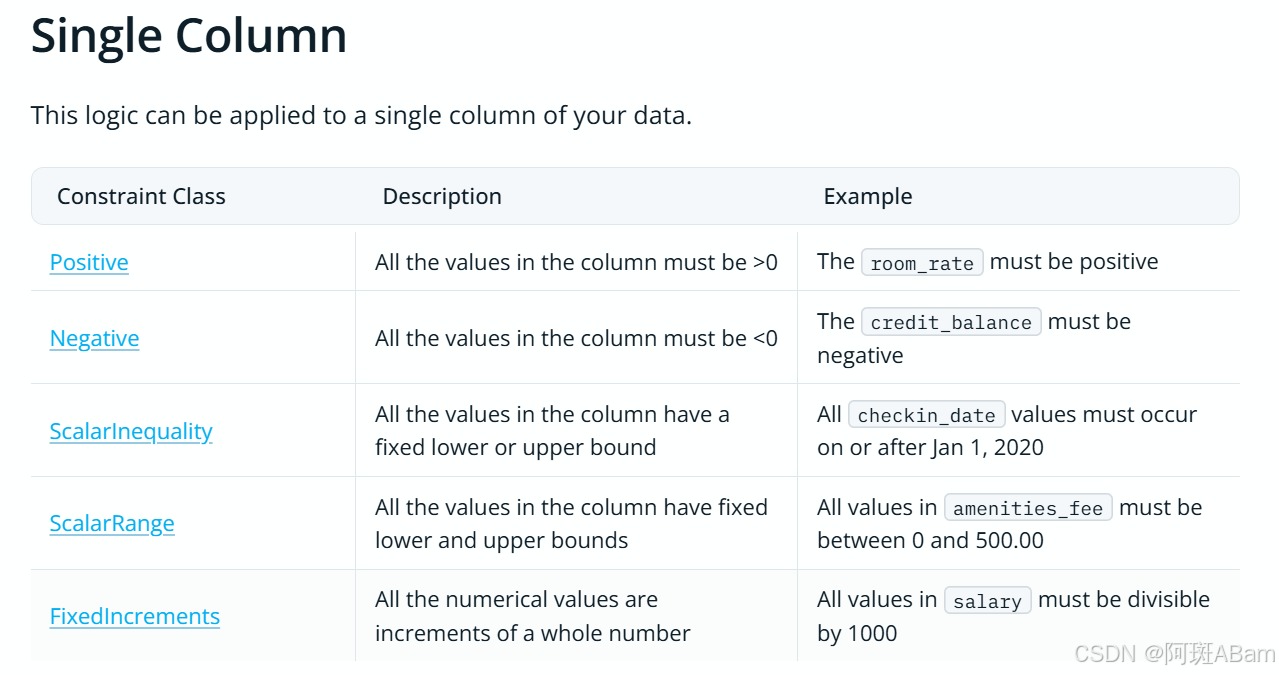
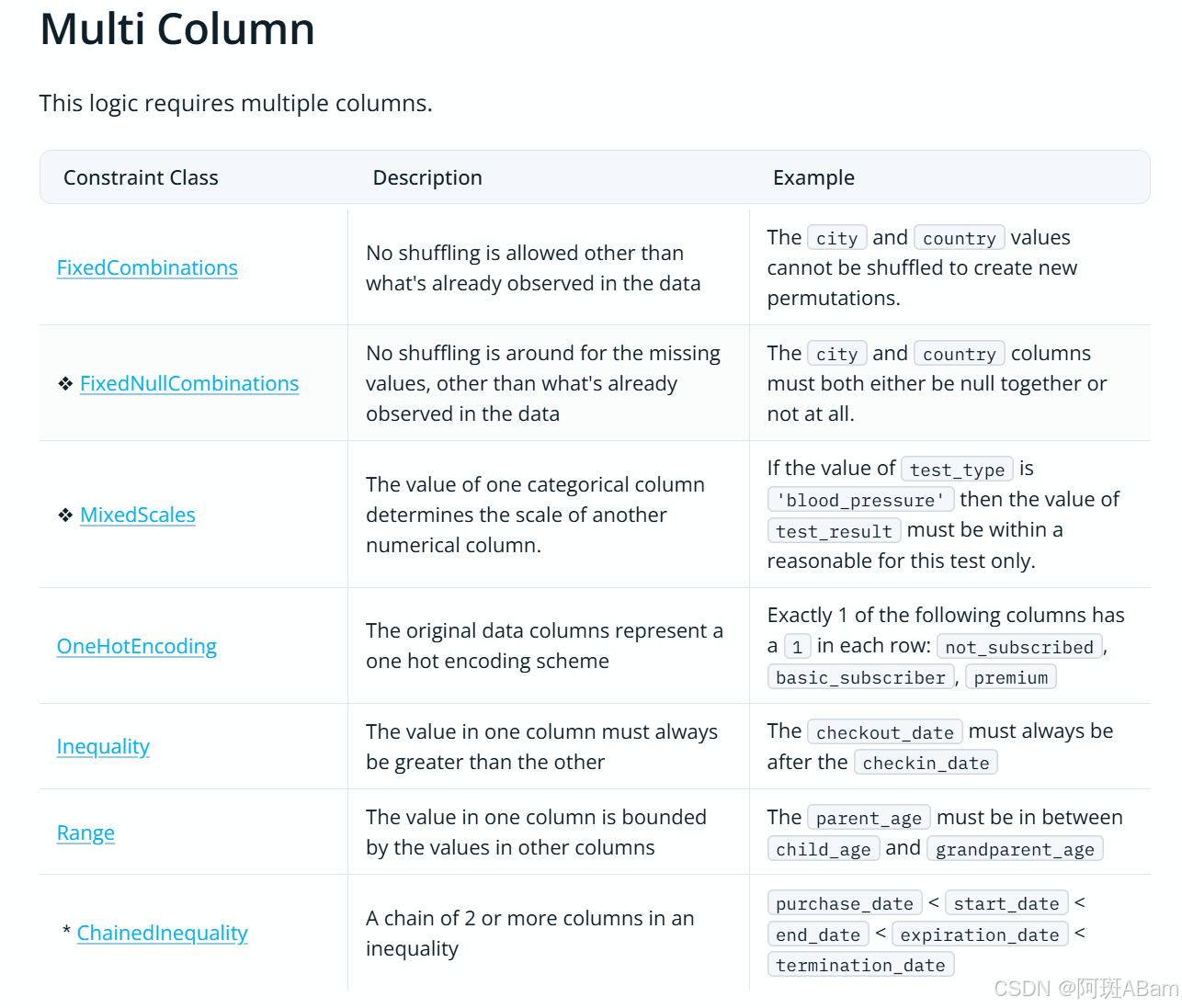
比如我这里可以要求Research paper 只能取0~6
# 添加约束,要求 Research Papers 只能取0~6
constraint_RP = {
'constraint_class': 'ScalarRange',
#'table_name': 'hci_data', # for multi table synthesizers
'constraint_parameters': {
'column_name': 'Research Papers',
'low_value': 0,
'high_value': 6,
'strict_boundaries': False # 是否严格大于low_value且严格小于high_value
}
}
synthesizer.add_constraints(constraints=[constraint_RP])三、训练模型
synthesizer.fit(hci_data)
# CTGANSynthesizer 会学习 hci_data 中数据的分布特征,例如数值的范围、不同类别之间的比例等。
# 通过不断调整生成器和判别器的参数,使得生成器能够生成越来越接近真实数据分布的合成数据。
loss_values = synthesizer.get_loss_values()
# 获取损失值,输出一个包含 epoch 数、生成器损失值和鉴别器损失值的 pandas.DataFrame 对象
print(loss_values)
# synthetic_data = synthesizer.sample(num_rows=100, conditions=conditions)
synthetic_data = synthesizer.sample(num_rows=len(hci_data))
# 调用 sample 方法从训练好的 CTGANSynthesizer 中生成合成num_rows行数据。
# 生成的数据会存储在 synthetic_data 中,列名和数据类型与 hci_data 相同。
synthetic_data.to_csv("synthetic_data.csv", index=False)
fig = synthesizer.get_loss_values_plot()
fig.show()四、完整代码
import pandas as pd
from sdv.single_table import CTGANSynthesizer
from sdv.metadata import Metadata
from sdv.constraints import ScalarInequality
import matplotlib.pyplot as plt
from sdv.metadata import Metadata
import os
import numpy as np
import seaborn as sns
# 准备原始数据
hci_data=pd.read_csv(r'HCI_Datasheet.csv')
hci_data=hci_data.drop(columns=['S. No','Decision Date','Application Date'])
# 创建了一个新的列 'University_Program',其值是 'University' 列和 'Programme' 列的值用空格连接起来的结果
hci_data['University_Program']=hci_data.University+' '+hci_data.Programme
hci_data.University=hci_data.University_Program
hci_data=hci_data.drop(columns=['Programme','University_Program','Year of Entry'])
# fillna 方法将缺失值替换为指定的值
hci_data['GRE']=hci_data['GRE'].fillna(330)
hci_data['TOEFL']=hci_data['TOEFL'].fillna(120)
print("转化类别标签及替换缺失值后的数据",hci_data)
print("增删列后的数据",hci_data)
# ------------ 1. 创建元数据 ----------
# 自动检测元数据
metadata = Metadata.detect_from_dataframe(data=hci_data, table_name='hci_data')
# 手动修正元数据
metadata.update_column(column_name='Work Experience', sdtype='categorical')
metadata.update_columns(
column_names=['Research Papers','Class Size', 'THE Rank', 'QS Rank'],
sdtype='numerical')
# 将元数据对象保存为 JSON 文件并再次加载以供将来使用
os.remove('metadata_v1.json')
metadata.save_to_json(filepath='metadata_v1.json')
metadata = Metadata.load_from_json(filepath='metadata_v1.json')
# ------------ 2. 创建CTGAN合成器 ----------
synthesizer = CTGANSynthesizer(
metadata, # required
enforce_min_max_values=True,
enforce_rounding=True,
epochs=1500,
verbose=True
)
# # 添加约束,要求 Research Papers 只能取0,1,2,3
# constraint_RP = {
# 'constraint_class': 'ScalarRange',
# #'table_name': 'hci_data', # for multi table synthesizers
# 'constraint_parameters': {
# 'column_name': 'Research Papers',
# 'low_value': 0,
# 'high_value': 6,
# 'strict_boundaries': False # 是否严格大于low_value且严格小于high_value
# }
# }
# synthesizer.add_constraints(constraints=[constraint_RP])
# ------------ 3. 训练CTGAN ----------
synthesizer.fit(hci_data)
# CTGANSynthesizer 会学习 hci_data 中数据的分布特征,例如数值的范围、不同类别之间的比例等。
# 通过不断调整生成器和判别器的参数,使得生成器能够生成越来越接近真实数据分布的合成数据。
loss_values = synthesizer.get_loss_values()
# 获取损失值,输出一个包含 epoch 数、生成器损失值和鉴别器损失值的 pandas.DataFrame 对象
print(loss_values)
# synthetic_data = synthesizer.sample(num_rows=100, conditions=conditions)
synthetic_data = synthesizer.sample(num_rows=len(hci_data))
# 调用 sample 方法从训练好的 CTGANSynthesizer 中生成合成num_rows行数据。
# 生成的数据会存储在 synthetic_data 中,列名和数据类型与 hci_data 相同。
synthetic_data.to_csv("synthetic_data.csv", index=False)
fig = synthesizer.get_loss_values_plot()
fig.show()

















 36
36

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









