







 CTGAN是一种针对表格数据的条件生成对抗网络,旨在解决离散和连续列的混合建模、非高斯分布、多模式分布以及类别不平衡等问题。通过引入针对模式的归一化和条件生成器等技术,CTGAN在合成表格数据生成任务中表现出色,优于贝叶斯网络基线和其它深度学习方法。
CTGAN是一种针对表格数据的条件生成对抗网络,旨在解决离散和连续列的混合建模、非高斯分布、多模式分布以及类别不平衡等问题。通过引入针对模式的归一化和条件生成器等技术,CTGAN在合成表格数据生成任务中表现出色,优于贝叶斯网络基线和其它深度学习方法。
论文地址:[1907.00503] Modeling Tabular data using Conditional GAN (arxiv.org)

摘要
对表格数据中行的概率分布进行建模并生成真实的合成数据是一项非常重要的任务,有着许多挑战。本文设计了CTGAN,使用条件生成器解决挑战。为了帮助进行公平和彻底的比较建模这类数据的方法,本文设计了一个基准测试,包括7个模拟数据集和8个真实数据集,以及几个贝叶斯网络基线。CTGAN在大多数真实数据集上都优于贝叶斯方法,而其他深度学习方法则不然。
1、介绍
GAN在建模分布方面比其统计对应方法具有更大的灵活性。新的GAN方法的激增需要一个评估机制。
- 为了评估这些GAN,本文使用了一组真实的数据集来建立一个基准系统,并实现了三种最新的技术。
- 为了进行比较,本文使用贝叶斯网络创建了两种基准方法。
在使用模拟数据集和真实数据集对这些模型进行测试后,我们发现,表格数据建模对GAN提出了独特的挑战,导致它们在许多指标上无法达到基线方法,如合成生成数据的可能性适合度和机器学习效率。这些挑战包括:
- 需要同时对离散列和连续列进行建模
- 每个连续列中的多模态非高斯值
- 类别列的严重不平衡问题。
为了应对这些挑战,在本文中提出了条件表格GAN(CTGAN)。引入了几种新技术方法:
- 通过针对模式的归一化、架构更改来增强训练过程。
- 通过使用条件生成器和采样训练来解决数据不平衡问题。
当使用有基准测试的相同数据集时,CTGAN的性能明显优于贝叶斯网络基线和其他测试的GAN。如下图所示。
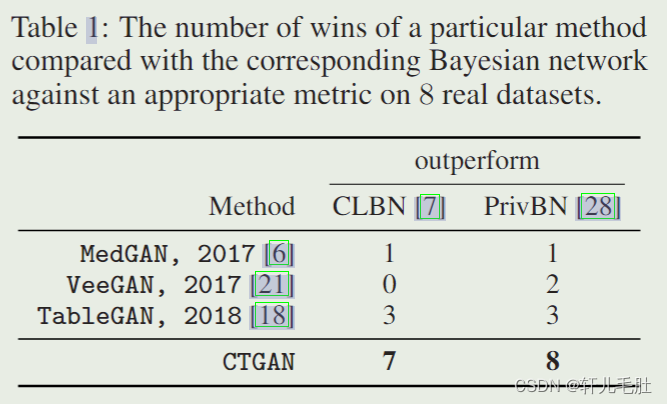
论文的贡献如下:
- 一个用于合成表格数据生成的条件GAN。本文建议CTGAN作为一个合成表格数据生成器由于以下几点:
- CTGAN比迄今为止的所有方法都要好,在至少87.5%的数据集上超过了贝叶斯网络。
- 为了进一步挑战CTGAN,采用变分自动编码器(VAE)来生成混合类型的表格数据,称之为TVAE。VAE直接使用数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











