







线性回归与逻辑回归
1 线性回归与逻辑回归的区别与联系
线性回归和逻辑回归都是广义上的线性回归。但两者又有不同。
| 方法 | 自变量(特征) | 因变量(结果) | 关系 | 应用 |
|---|---|---|---|---|
| 线性回归(Linear Regression) | 连续或离散 | 连续实数 | 线性 | 回归 |
| 逻辑回归(Logistic Regression) | 连续或离散 | (0,1)之间连续值 | 非线性 | 分类 |
1.1 决策边界
线性回归 是利用数理统计中的回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。表达形式为y = θx + e,其中e为误差服从均值为0的正态分布。适用于有监督学习的预测。
- 单变量线性回归:hθ(x)=θ0+θ1x,只包含一个自变量x和一个因变量hθ(x),且二者的关系可以用一条直线近似表示;
- 多变量线性回归:hθ(x)=θ0+θ1x1+…+θnxn,包括两个或两个以上的自变量(x1、x2 …),并且因变量和自变量是线性关系。
逻辑回归 首先通过sigmoid函数将样本映射到[0,1]之间的数值。sigmoid函数可以把任何连续的值映射到[0,1]之间,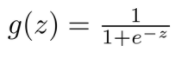
决策边界:对多变量线性回归方程求sigmoid函数,
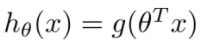
线性回归在整个实数域范围内进行预测,敏感度一致,而分类范围需要在[0,1]。逻辑回归是在线性回归的基础上,多一步sigmoid非线性映射。即减小预测范围,将预测值限定为[0,1]间的一种回归模型。所以线性回归模型对异常值敏感,而逻辑回归通过非线性变换减弱分离平面较远的点的影响,鲁棒性比线性回归的要好。
1.2 代价函数
代价函数是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。用来评价模型的预测值和真实值不一样的程度,通常代价函数越小,模型的性能越好。
线性回归
-
单变量线性回归:
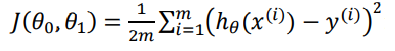
-
多变量线性回归:
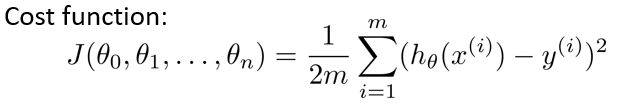
其中, -
m:训练样本的个数;
-
hθ(x):用参数θ和x预测出来的y值;
-
y:原训练样本中的y值,也就是标准答案;
-
上角标(i):第i个样本。
逻辑回归
对于线性回归,使用MSE得到的J(θ)为凸函数,但是对于logistic回归,由于进行了sigmoid非线性映射,在寻优时容易陷入局部最优的问题,所以考虑把sigmoid作log,得到的J(θ)。
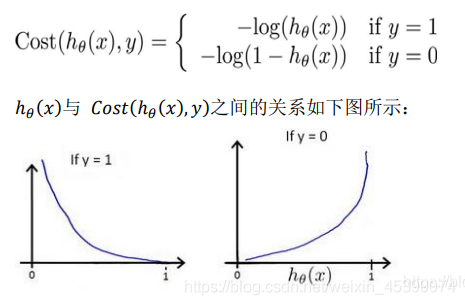
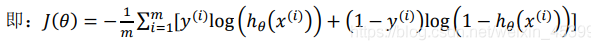
J(θ)对θ求二阶导,得到其二阶导大于0,说明J(θ)为凸函数,使用梯度下降法寻优时,可以保证找到全局最小。
1.3 梯度下降法
使用梯度下降算法来求得能使代价函数最小的参数。
线性回归

逻辑回归
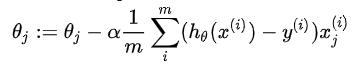
经梯度下降算法后线性回归与逻辑回归的公式形式看上去是一致的,但实际上两者是完全不同的,因为假设函数是不同的。
注:线性回归可使用正规方程求使代价函数最小的θ,但逻辑回归无法使用正规方程。
1.4 应用场景
线性回归
- 用于驱动力分析:某个因变量指标受多个因素所影响,分析不同因素对因变量驱动力的强弱(驱动力指相关性,不是因果性)
- 用于预测:自变量与因变量呈线性关系的预测
逻辑回归
逻辑回归是一种用于解决二分类问题的机器学习方法,是一种判别模型:表现为直接对条件概率P(y|x)建模,而不关心背后的数据分布P(x,y)。
- 用于分类:适合做很多分类算法的基础组件
- 用于预测:预测事件发生的概率(输出)
- 用于分析:单一因素对某一个事件发生的影响因素分析(特征参数值)
1.5 优缺点
线性回归
优点
- 思想简单,实现容易。建模迅速,对于小数据量、简单的关系很有效
- 是许多强大的非线性模型的基础
逻辑回归
优点
- 以概率的形式输出结果,不只是0和1的判定,可以做ranking model
- 可解释强,可控性高
- 训练快,feature engineering之后效果赞
- 添加feature简单
线性回归和逻辑回归的缺点基本一致
- 因为本质上是一个线性的分类器,所以处理不好特征之间相关的情况
- 特征空间很大时,性能不好,容易欠拟合,精度不高
2 线性回归的代码实现
2.1 单变量线性回归
import numpy as np
import pandas as pd
# 读取数据
data = pd.read_csv(path, header=None, names=['x', 'y'])
# 代价函数
def computeCost(X, y, theta):
inner = np.power(((X * theta.T) - y), 2)
return np.sum(inner) / (2 * len(X))
# 处理数据及初始化
data.insert(0, 'Ones', 1) #在训练集中添加一列,以便可以使用向量化的解决方案来计算代价和梯度
cols = data.shape[1] #获取矩阵的列数
X = data.iloc[:,0:cols-1] #X是所有行,去掉最后一列
y = data.iloc[:,cols-1:cols] #y是所有行,最后一列
X = np.matrix(X.values)
y = np.matrix(y.values)
theta = np.matrix(np.array([0,0]))
computeCost(X, y, theta)
# 批量梯度下降算法
def gradientDescent(X, y, theta, alpha, iters):
temp = np.matrix(np.zeros(theta.shape))
parameters = int(theta.ravel().shape[1])
cost = np.zeros(iters)
for i in range(iters):
error = (X * theta.T) - y
for j in range(parameters):
term = np.multiply(error, X[:,j])
temp[0,j] = theta[0,j] - ((alpha / len(X)) * np.sum(term))
theta = temp
cost[i] = computeCost(X, y, theta)
return theta, cost
alpha = 0.01 #设置学习率α
iters = 2000 #设置迭代次数
g, cost = gradientDescent(X, y, theta, alpha, iters) # 运行梯度下降算法来将我们的参数θ适合于训练集
computeCost(X, y, g) #使用我们拟合的参数计算训练模型的代价函数
可视化结果
# 绘制线性模型
import matplotlib 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1184
1184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









