






摘要
这周学习了机器学习的基本概念,包括机器学习的函式输入输出类型以及函数类别有哪些,分析training过程的三个步骤,包括简版和复杂模型版。了解了Sigmoid、ReLu激活函数,以及神经网络的的结构,通过正向传播得到神经网络计算的结果的误差值,采用反向传播求误差对权重的梯度,回传误差,以调整权值降低误差,这样就能让神经网络在更多的数据上表现得更加准确,并提高模型的预测能力。手动推导了Corss-Entropy、Softmax反向传播的计算过程。也进一步理解了反向传播的思想以及反向传播中涉及的计算思路。
Abstract
This week, I learned the basic concepts of machine learning, including the types of input and output functions and the types of functions in machine learning. I analyzed the three steps of the training process, including the simplified version and the complex model version. Understand the sigmoid, ReLu Activation function, and the structure of the neural network, obtain the error value of the neural network calculation result through forward propagation, use reverse propagation to calculate the gradient of the error to the weight, and return the error to adjust the weight value to reduce the error, so that the neural network can perform more accurately on more data and improve the prediction ability of the model. The calculation process of Corss Entropy and Softmax backpropagation was manually derived. Further understanding of the concept of backpropagation and the computational ideas involved in backpropagation.
一、机器学习基本概念
通俗的来讲,机器学习就是使机器具备学习的能力。机器学习本质就是找一个合适的函数,基于输入数据(如声音信号,图片,视频等),输出特定的结果。而该函数是一种类神经网络,其输入和输出为:
- 函数的输入可以是向量,矩阵(影像辨识时需要用到矩阵)或序列(语音辨识时需要用到序列)
- 函数的输出可以是数值,类别(提供给机器几个选项,机器选择出任意一个输出),文本,图片
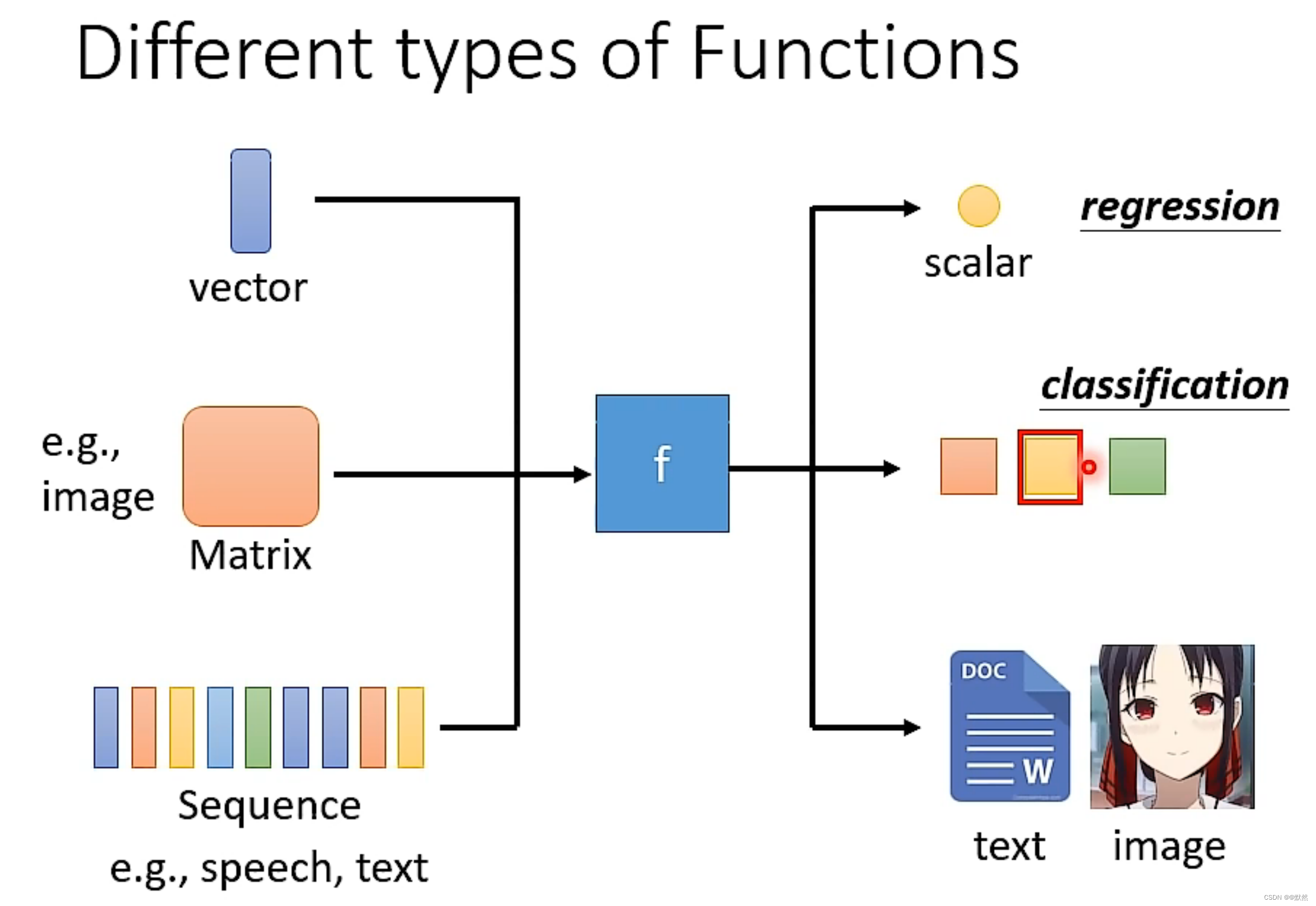
函数的类型
- Regression:函数的输出是个数值。
例如,假设让机器做的事情是 输出未来某个时间 PM2.5 的数值。如下图,寻找函数 f 的任务称为 Regression。

-
Classification:首先准备好一些选项,这些选项被称之为类别,函数输出则是从设定好的选项里,选择出一个当作输出。这个任务就是 Classification。
例如,给出一封邮件,函数 f 判断是否是垃圾邮件,给出yes/no两个选项,从中选择出一个选项进行判断。

如果要让机器下围棋,则给出的选项是根据棋盘上的位置数量来决定的。如下图:

-
Structured Learning:生成有结构的物件,让机器学会创造。比如画一张图,写一篇文章
机器如何找一个合适的函数呢?
猜想:能否通过对某平台,某个创作者过往的所有资讯(观看人数、点赞等),预测出某一天或者某一时刻的资讯。

二、Training步骤
机器学习可以解决上述猜想,已知输入为某用户账号过往的资讯信息,输出为未来某一天或某一时刻的资讯。找出上述函数Funtion的过程分为三个步骤:
1. Function with Unknown Parameters(带有未知参数的函数)
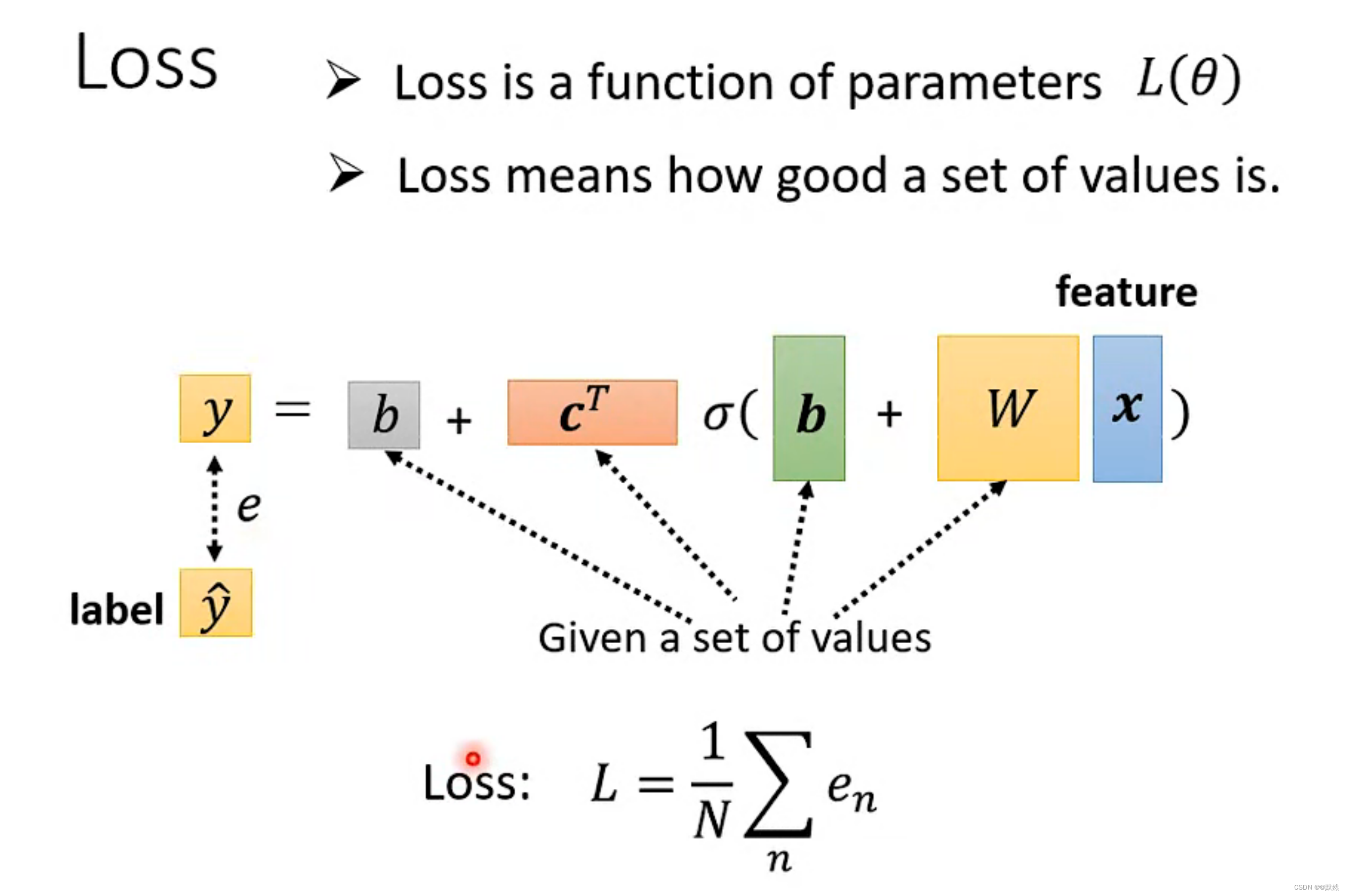
Function称之为Model。x为已知数据,叫做feature。w为权重参数。b为bias,即偏移量 (线性回归)

2. Define Loss from Training Data
Loss是一个带参的函数:L(b, w)
Loss输出的值代表的是:如果输入一组b和w,判断这组b和w的数值是好与坏
以youTube的点阅人数预测为例:
假设给未知的函数设定是 L(0.5k, 1) => 输入 b 为 0.5k, w 为 1。则:

已知的过去点阅数据:

将某天的数据x带入,通过 y = 0.5k + 1x 求出预测值,将预测值与上图中的实际值进行比较,实际值与预测值之差的绝对值就是误差e。
同理,可计算出后续每天的误差e。
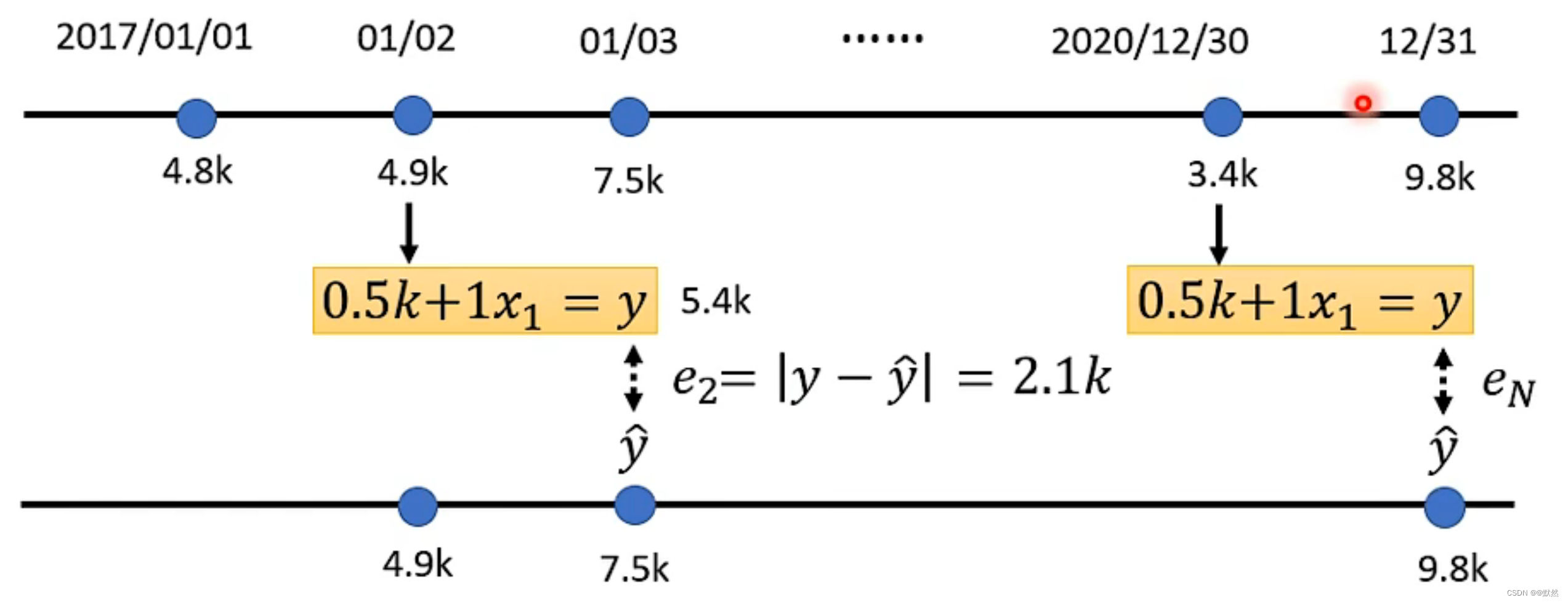
根据计算得出每一天的误差值,计算Loss(L的值越大,即预测误差越大,说明这组参数不好;L的值越小,即误差越小,说明这组参数越好)

loss函数可自己定义,以下常见两类:MAE、MSE,根据需求以及对任务的理解选择误差e计算方式:

3. Optimization (最佳化)
寻找最佳的w*, b*,使得Loss值达到最小
采用 Gradient Descent (梯度下降) 方法寻找w*, b*
梯度下降是一种优化算法,用于在机器学习和深度学习中发现最小化损失函数的参数。在梯度下降算法中,从初始参数开始,沿着损失函数下降的方向一步步更新每个参数,直到达到局部或全局最小值。这个方向是损失函数在当前参数上的梯度,因此叫做梯度下降。
单参 L(w)

双参 L(w, b)


如图所示数据呈现周期性规律,七天为一个周期。

但是这个 Model y = 0.1k + 0.97x 仍存在缺陷,只能根据前一天的数据,评估出数据。上图所示的数据为7天一个周期,最合适的方式应为根据前七天的数据,评估出数据。因此需要修改模型,将前七天的数据都列入考虑,同时也可以尝试将前28天的数据列入考虑,对比 L 的大小

由此可见,当列入考虑的天数越多,L 值越小。但当列入考虑的天数达到一个极限后,L 值也几乎不会改变。这些模型都是把输入的x(feature)乘上一个weight加上bias,这样的模型有一个共同的名字叫作Linear Models。
三、更为复杂的 flexible model
1. Model bias
上述 Linear models 过于简单了,w和b不管如何变化,Linear models 始终都是一条直线。因此无法拟合复杂的折线。就比如我们上述的某平台某用户的点阅量这个例子,可能隔天点阅量并不是持续增长的,而下图中蓝色线所预估的点阅量则是持续增长。

因此 Linear models 有很多限制,这种来自于 models 的限制被称之为 Model Bias。
2. 我们需要找出一个更为复杂的 flexible model
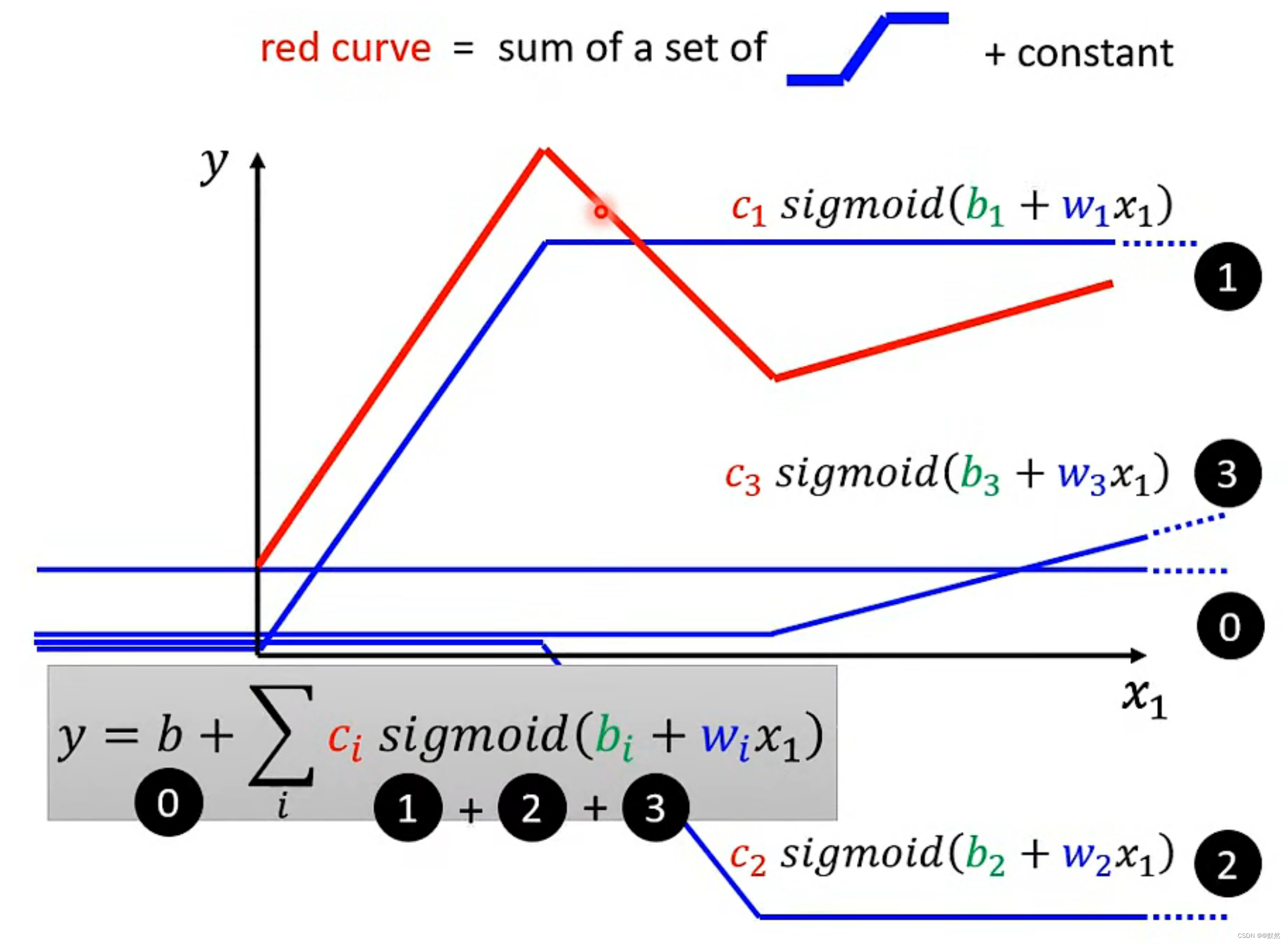
如下图,我们观察红色线是由若干个蓝色线所组成。红色线 = 0 + 1 + 2 + 3。【注】0,1,2,3分别是对应的蓝色线。而红色线所表示的 Function 就是我们数学中所学习到的分段线性函数

所有的 Piecewise Linear(分段线性) 都由常数项和若干个蓝色线组成
Piecewise Linear(分段线性)是一种数学函数,通常用于逼近非线性函数或处理非线性问题。它是由多个线性段组成的函数,每个线性段都有一个斜率和截距,因此可以通过一组斜率和截距来定义整个函数。

对于非线性函数,我们通常会在图像中取若干个点,然后将各个点连接起来

可以通过 Piecewise Linear(分段线性) 去逼近任何的连续曲线
3. Function with Unknown Parameters(带有多个未知参数的函数)

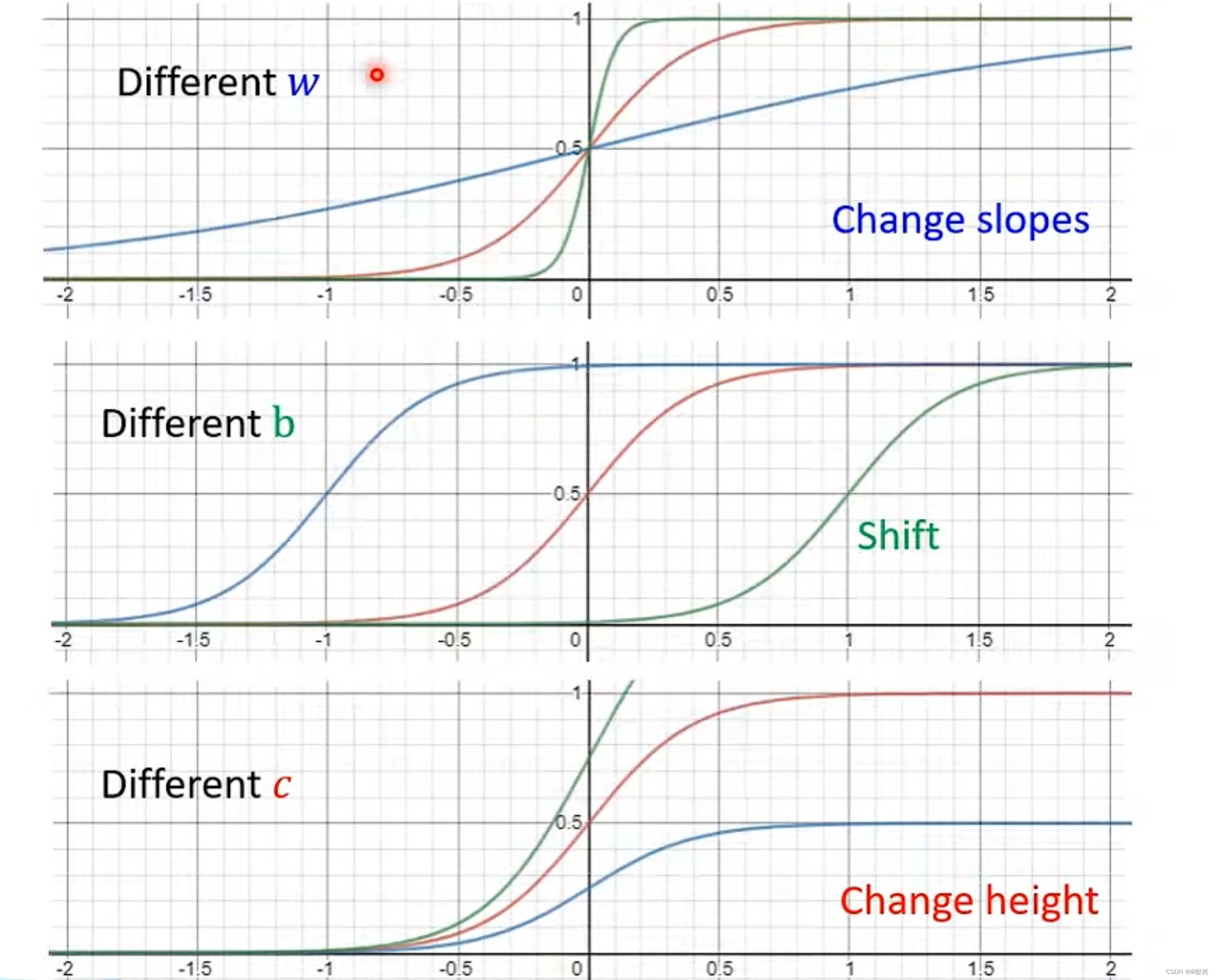
我们可以调整c,w,b的值,从而产生不同形状的Sigmoid Function,不断逼近上图中蓝实线所表示的Function
Sigmoid Function 是一种常见的数学函数,其产生的值域在0到1之间。它通常被用作神经网络中的一个激活函数,用来处理非线性分类问题。所谓非线性分类问题,是指在给定的输入数据中,无法用简单的线性函数或者线性组合对数据进行分类或者回归。例如,一组二维数据中,如果无法用一条直线来将数据分成两类,那么这就是一个非线性分类问题。
将不同的 Sigmoid Function 相互叠加起来,用来近似地逼近 Piecewise Linear 的 Function。从而逼近各种不同的 Continuous 的 Function
寻找出更有弹性的并含有未知参数的 Function,可以减少 Model Bias 的限制
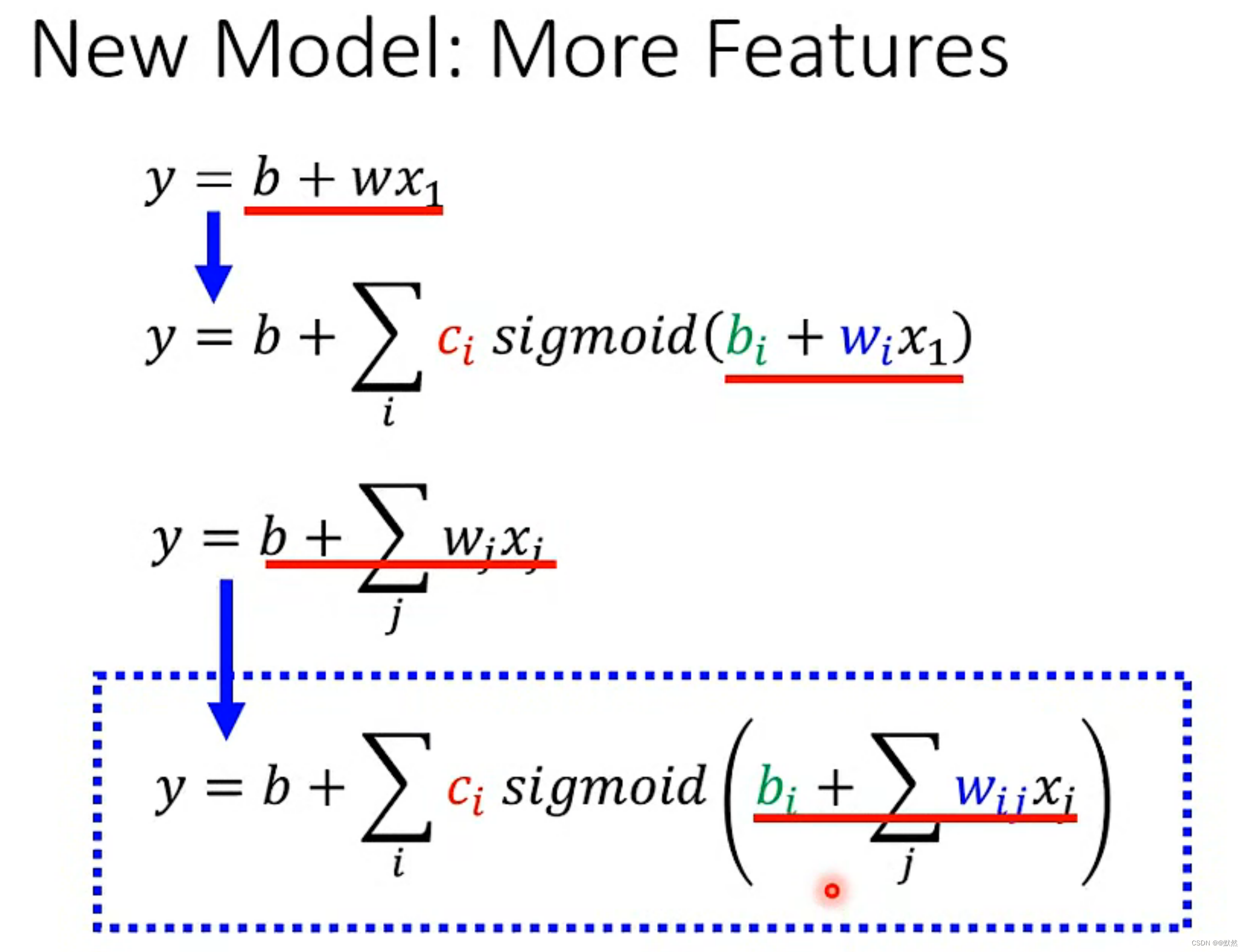
对于蓝色虚线框中的公式,我们首先只考虑前3天的features,即 j 为1,2,3。x1,x2,x3分别为前一天,前两天,前三天的点阅量。每一个 i 代表一个Sigmoid Function,在这里 i 分别取 1,2,3。
【注】Sigmoid 的个数根据需求而定,Sigmoid越多,就能够逼近越复杂的 Function。
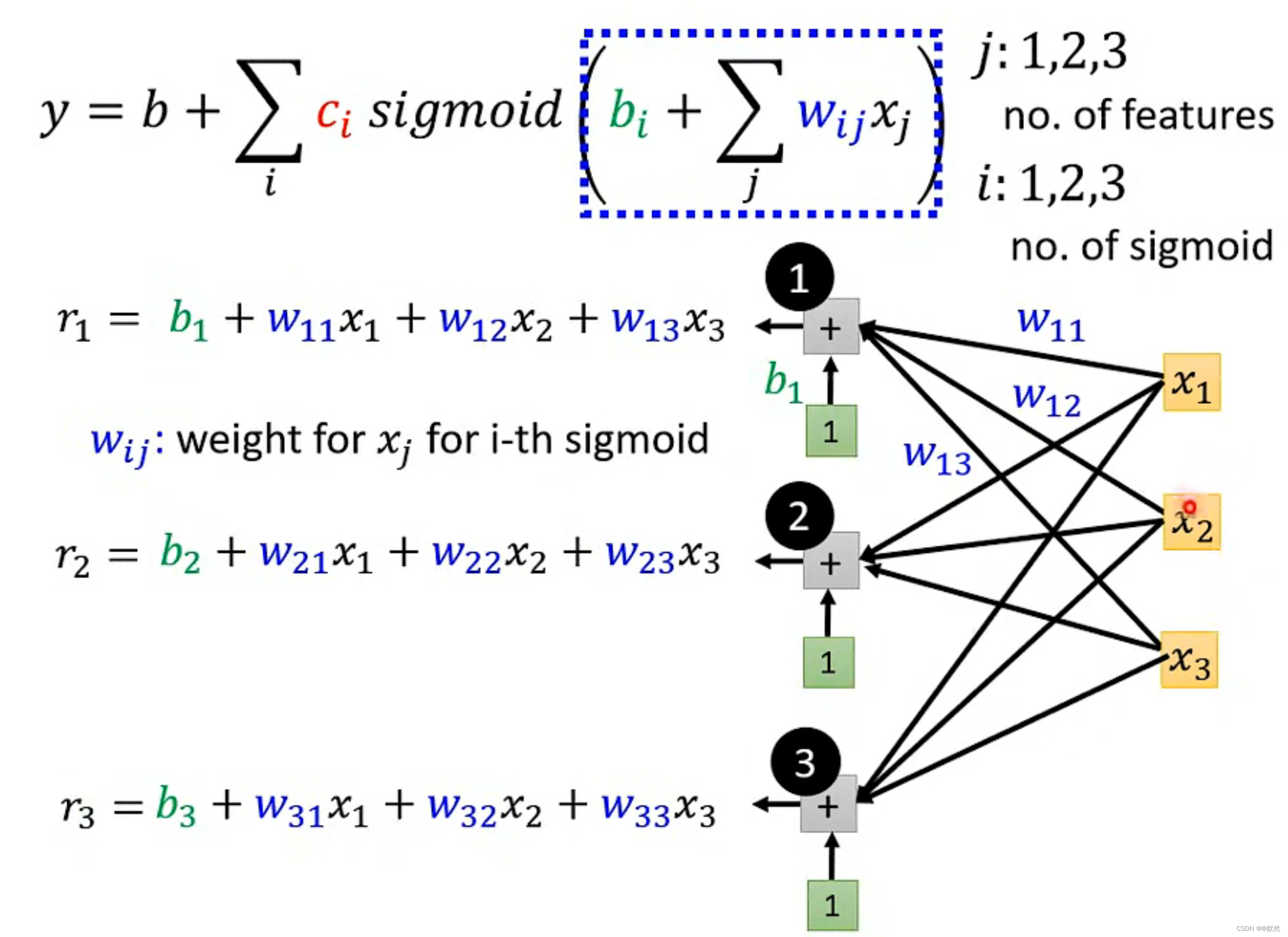
用矩阵和向量相乘的方法,来表示 r1,r2,r3之间的关系

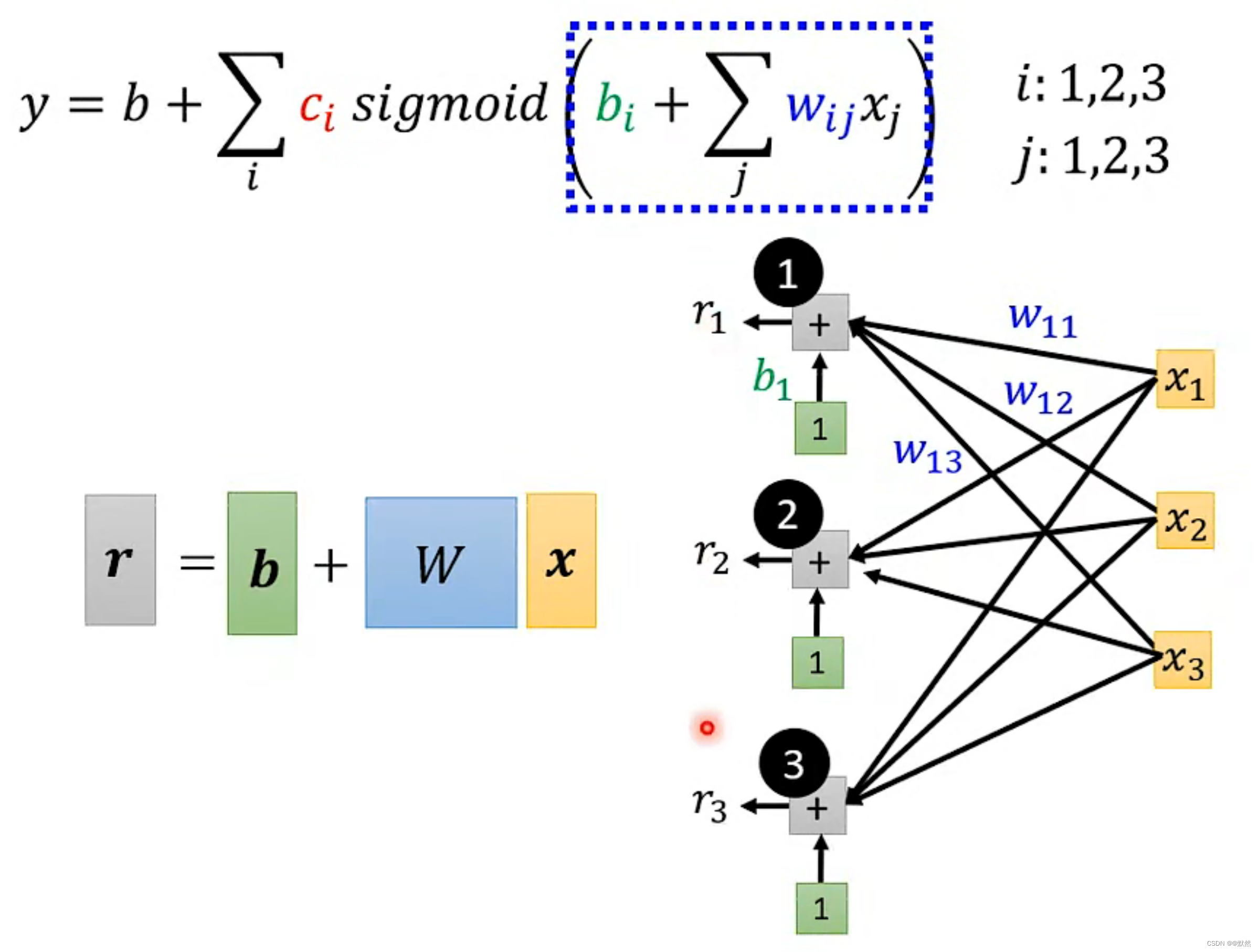
这个过程可分为三步:
- 输入 x 这个 features 向量,然后 x 乘上 W 权重矩阵,再加上 b 误差,得到 r
- 再将r输入进sigmoid得到向量a;
- 再将a进行一个线性组合得到最终输出y。
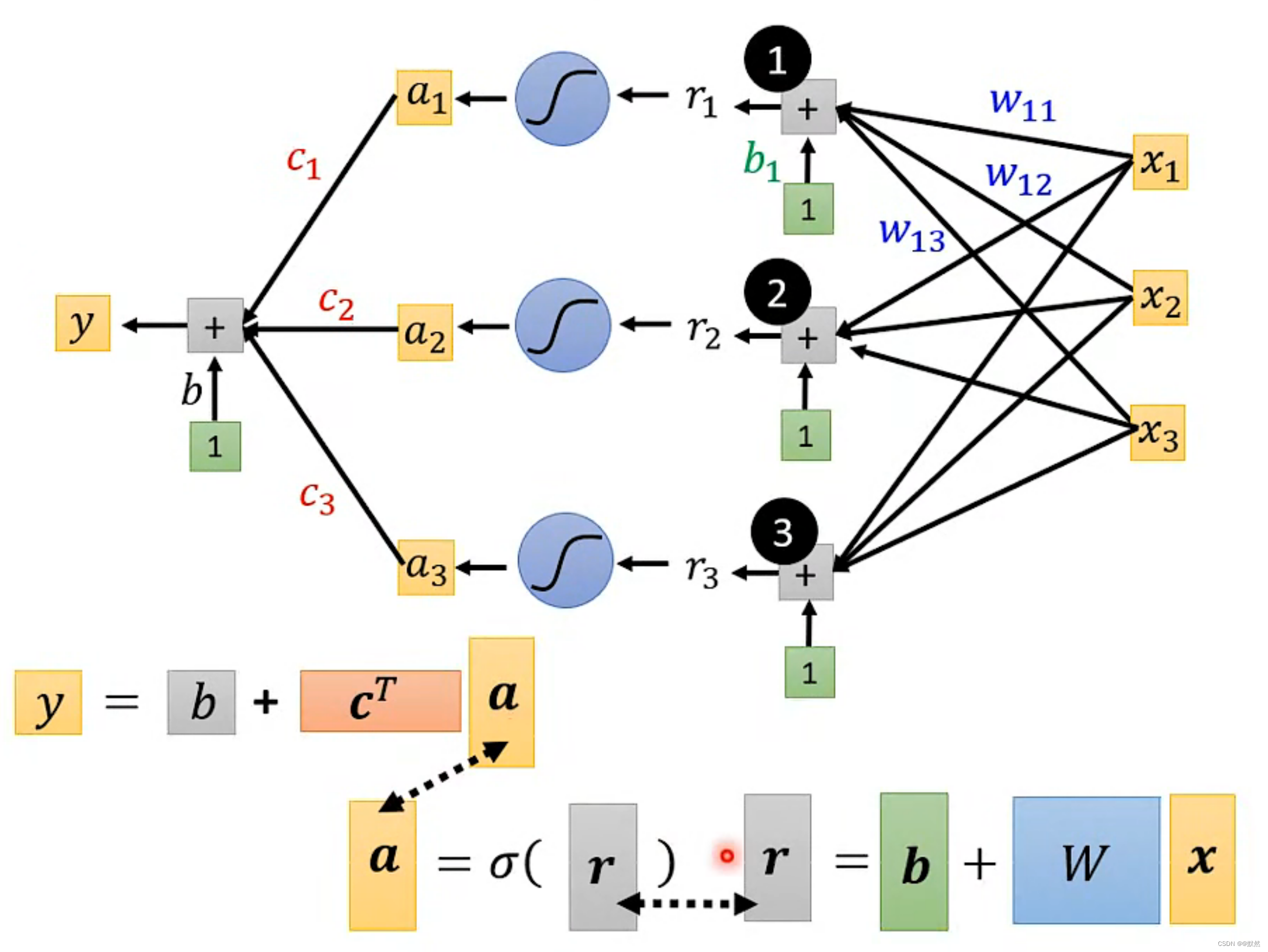
最后 y 可以用一个线性代数式表示,其中x是特征向量(feature),W , b , cT, b (注意两个b不是一个意思哦~)是未知参数 ,将未知参数列成一列,统称为θ

此时我们就重写了机器学习的第一步,重新定义了一个带多个未知参数的function!
4. define loss from training data
5. Optimization of New Model



6. ReLU 激活函数
两个relu叠起来就可以变成一个Hard Sigmoid。Hard Sigmoid 是一种非线性函数,用于在人工神经网络中作为激活函数。它是一种近似于sigmoid函数的函数
ReLU的优点:
- ReLu具有稀疏性,可以使稀疏后的模型能够更好地挖掘相关特征,拟合训练数据;
- 在x>0区域上,不会出现梯度饱和、梯度消失的问题;
- 计算复杂度低,不需要进行指数运算,只要一个阈值就可以得到激活值。
RuLU的缺点:
- 输出不是0对称
- 由于小于0的时候激活函数值为0,梯度为0,所以存在一部分神经元永远不会得到更新
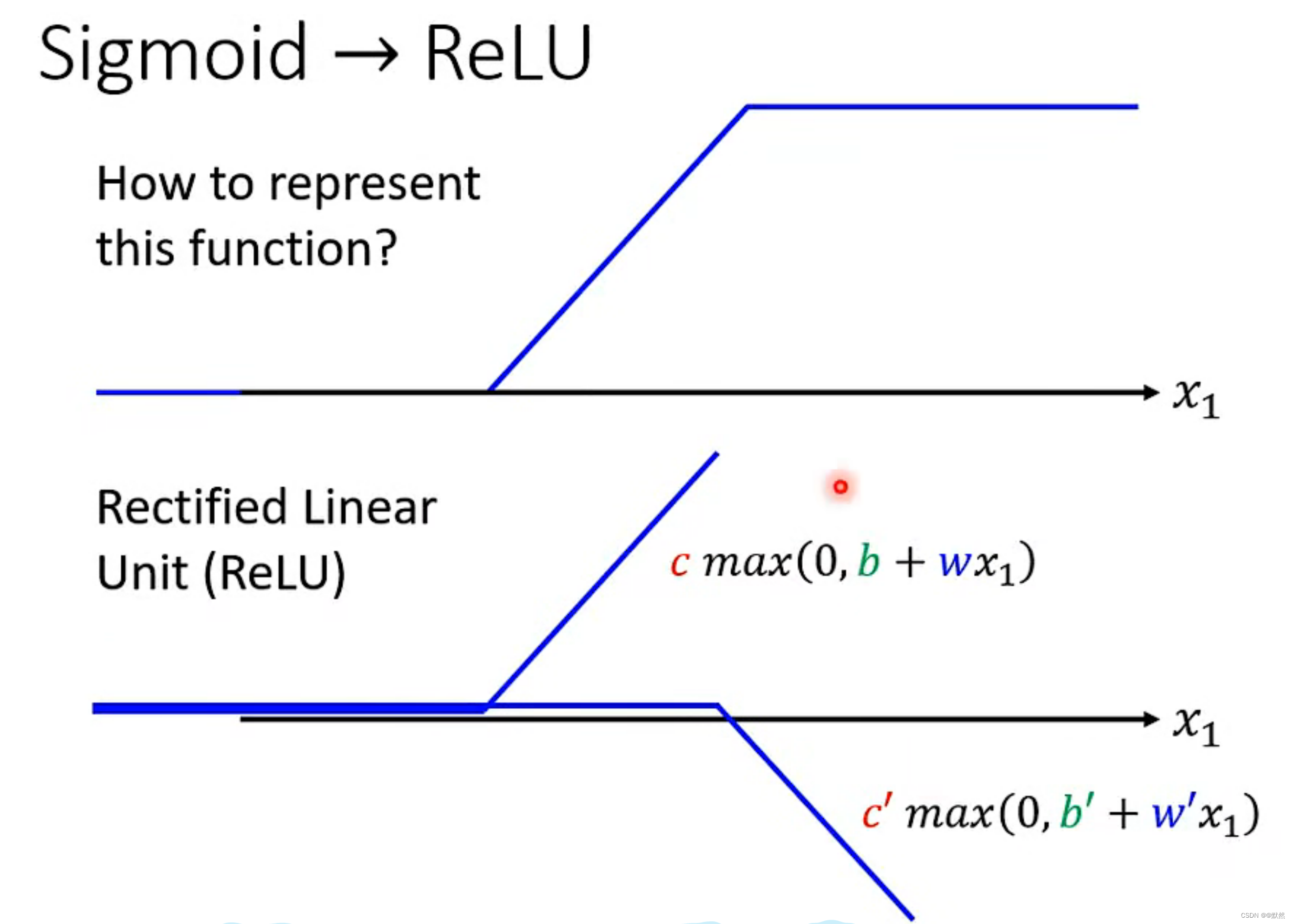
由于两个ReLU叠加变成一个Hard Sigmoid,因此 ReLU 的数量为 2i
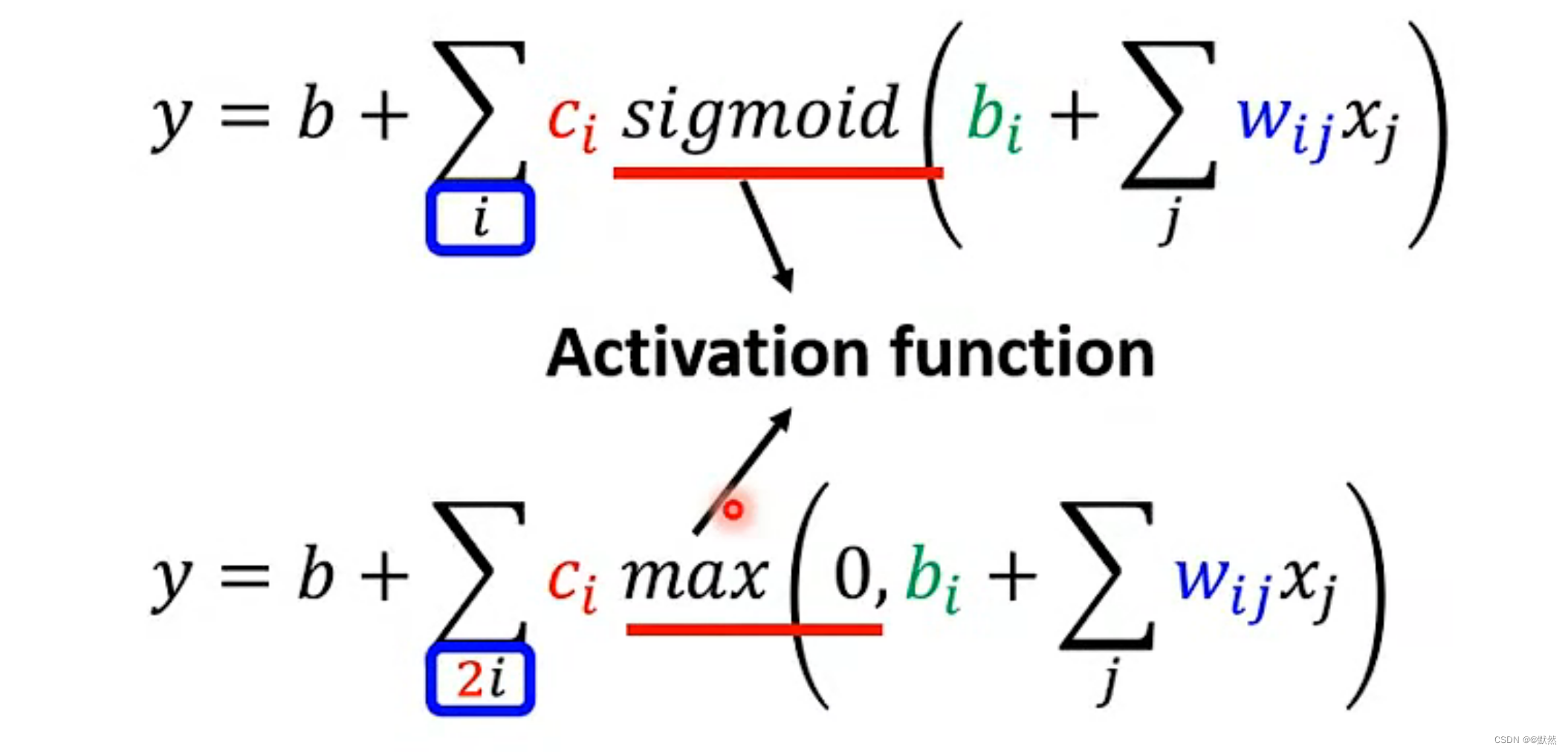
ReLU和Sigmoid 都是激活函数
7. 实验结果
结果显示,ReLU经过多层叠加,最终使得预测数据逐步精准。

8. 神经网络
输入x加权求和加偏差b后进入激活函数中称为一层layer,将输出a继续这个步骤第二次进入激活函数后输出称为第二层layer。反复进行多层,这样组成的网络即为deep learning。
将激活函数称作Neuron(神经元),运算的网络结构称为neural network(神经网络)
理想中的激活函数是如下图中的阶跃函数,它将输入值映射为输出值 “0” 或 “1”,显然 “1” 对应于神经元兴奋,“0” 对应于神经元抑制。然而,阶跃函数具有不连续、不光滑等不太好的性质,因此实际常用 Sigmoid 函数作为激活函数。
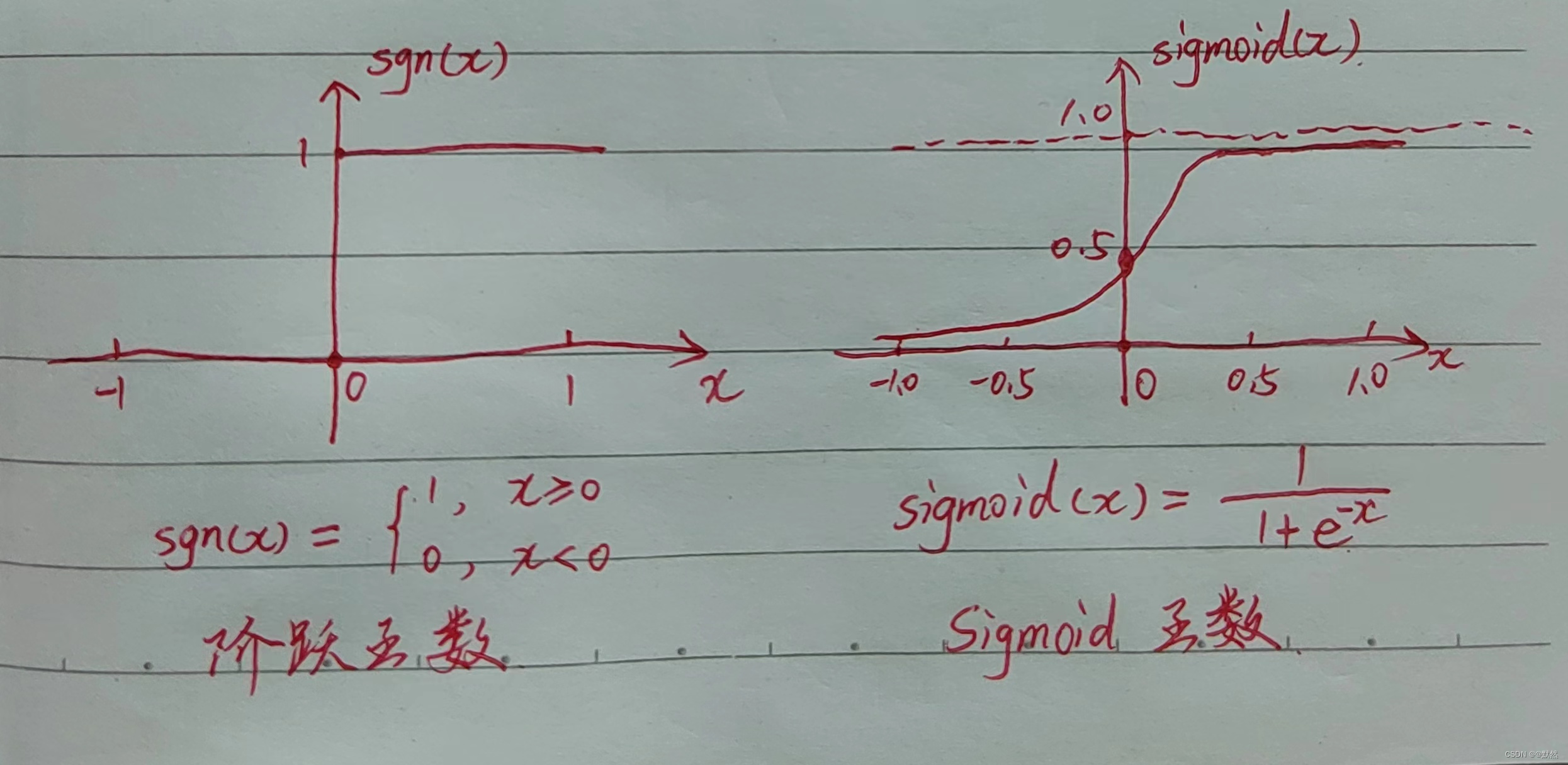

我们用 ReLU 或 Sigmoid去逼近一个复杂的 Function,实际上只要够多的 ReLU,或者够多的 Sigmoid 都可以逼近任何的连续的 Function,那么将 ReLU 和 Sigmoid 反复用,反复迭代,目的在于让机器进行深度学习,不断提高精度,减少误差。

那么,layer层数越多越好吗?随着层数增加,测试集损失值在逐渐下降。但是,到第4层的时候,测试集的损失值反而上升了。我们把这种现象称为“过拟合”。意思就是在训练过得资料上有变化,但是在没看过的资料上没有变化。

四、深度学习
专业术语
- 神经元(Neuron):任意的一个逻辑回归单元
- 神经网络(Neural Network):不同的连接导致不同的网络结构
- 网络参数(Network parameter)𝜃:“神经元”中的所有权重weight和偏差bias
深度学习三步骤
- define a set of function (定义一组函数)
- goodness of function (判断函数的好坏)
- pick the best function (选择最佳函数)
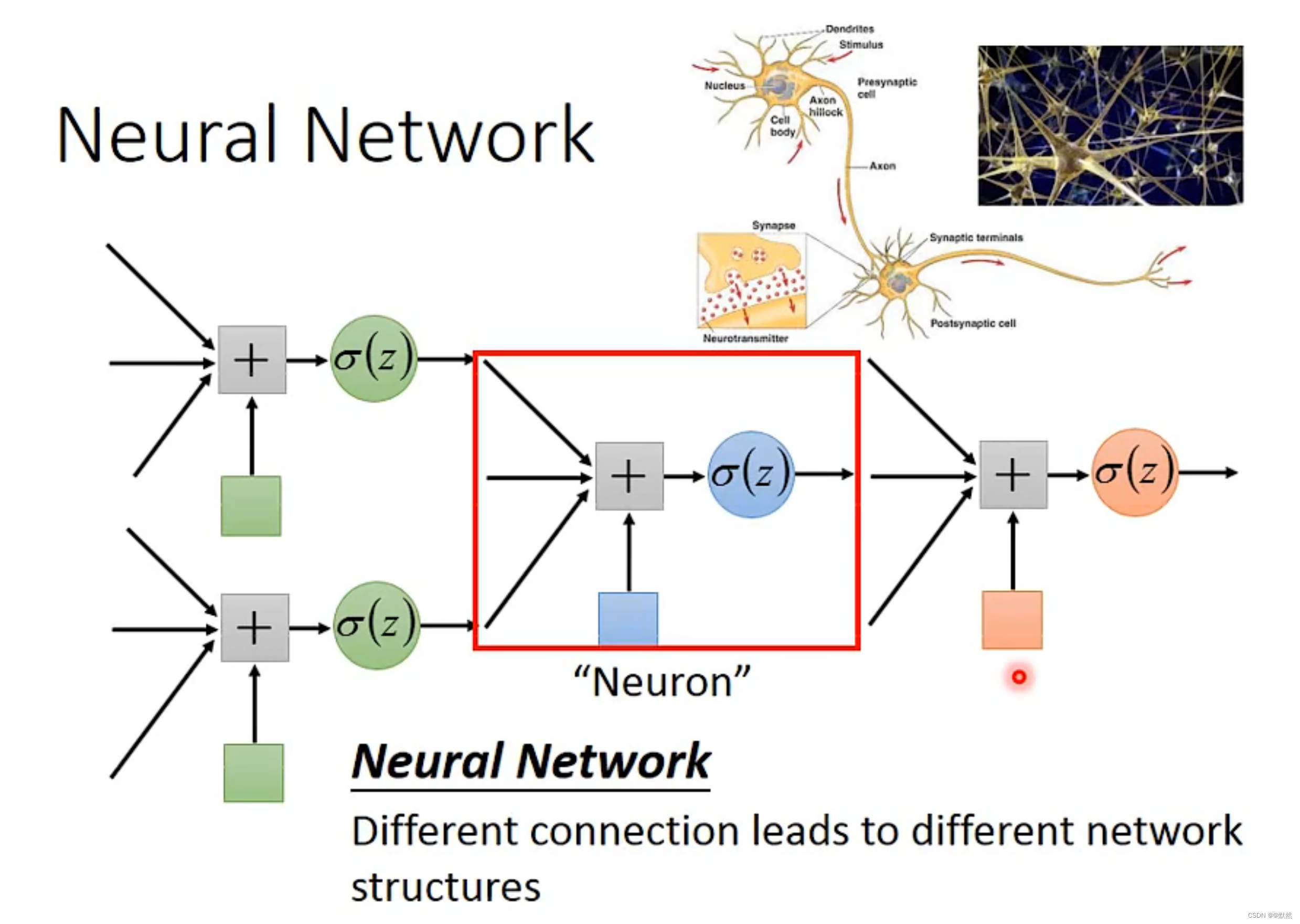
【注】all the weights and biases in the “neuron”。
1. 全连接前馈网络(Fully Connect Feedforward Network)
如下图,每一个 Neural 都有一组 weight 和 biase。weight 是根据 training data 找出来的

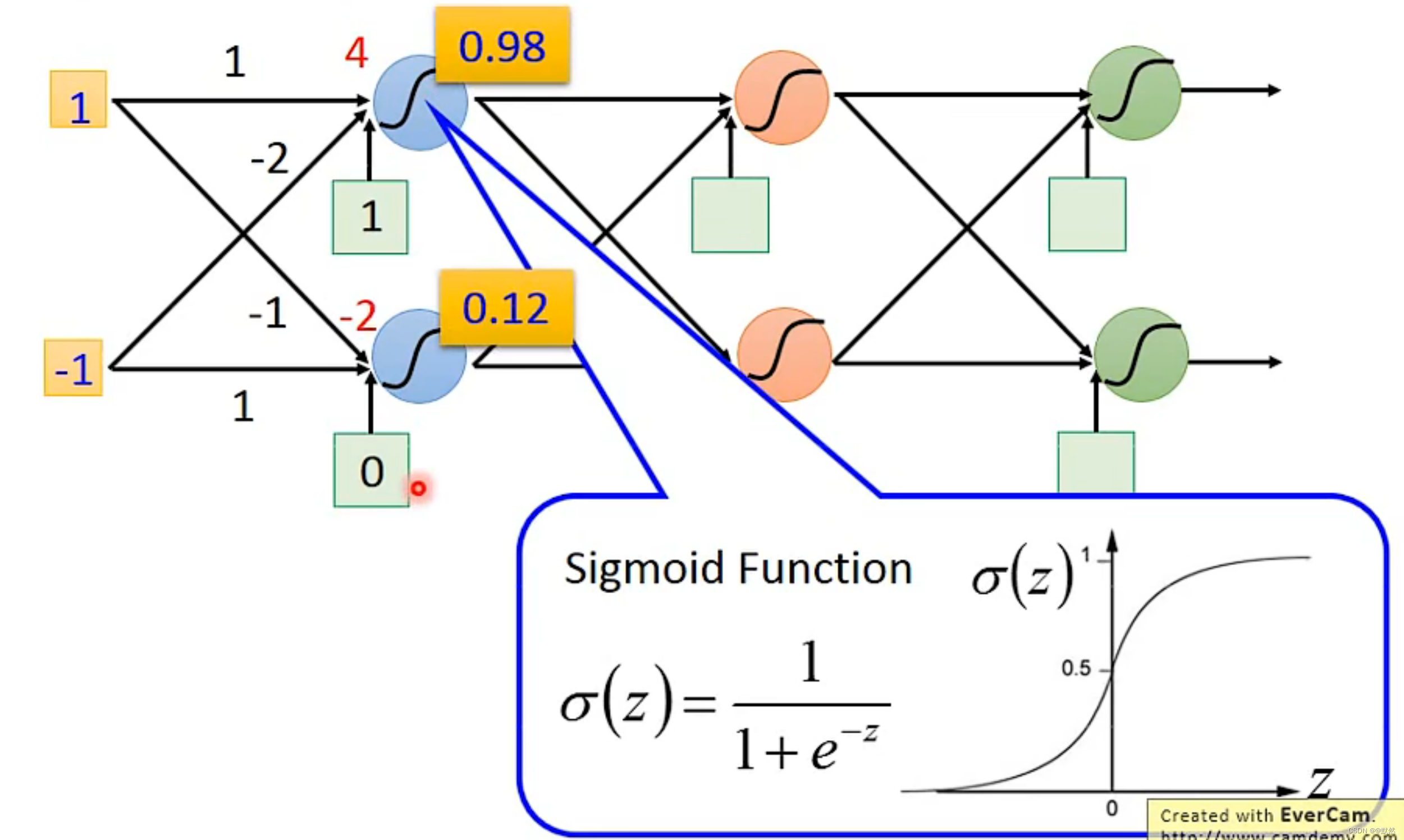
起始输入分别为1、-1,输出分别为0.62、0.83,第一组 Neural计算完成后,第二组Neural根据第一组Neural计算的结果,再次进行计算,以此类推…
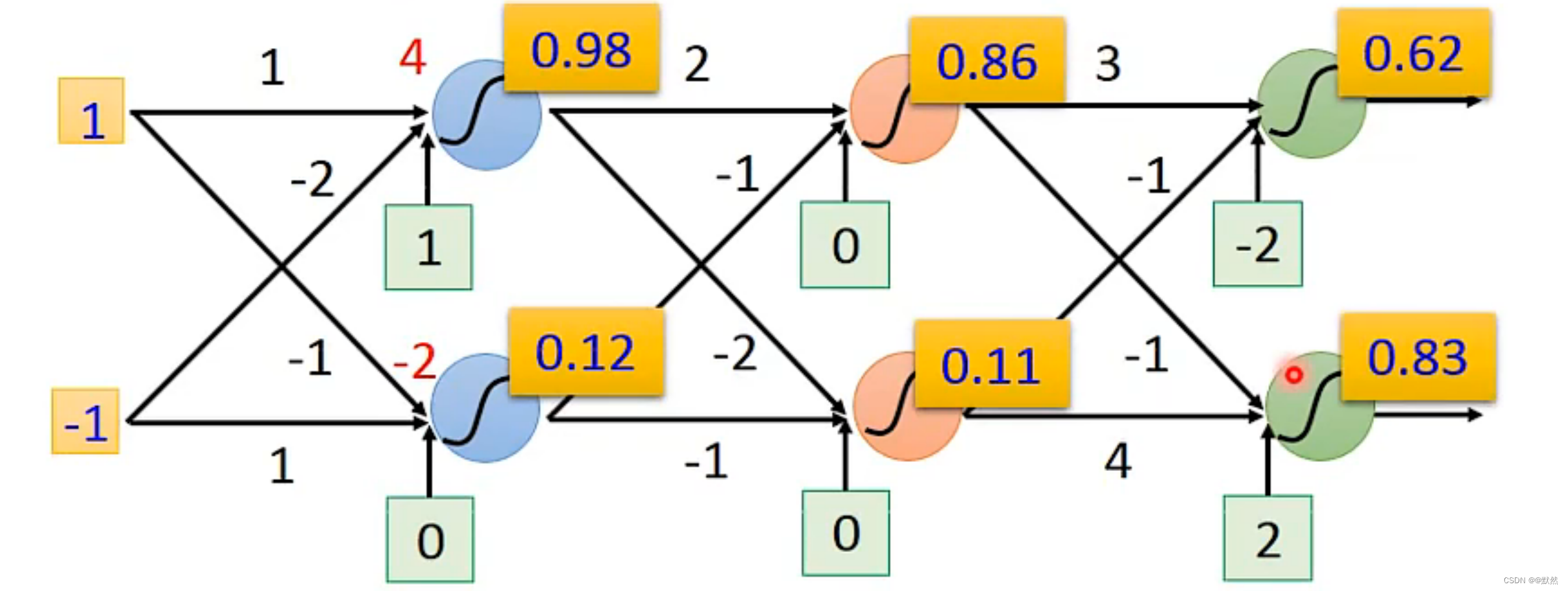
起始输入0、0, 输出为0.51、0.85

一个 Network 就可以看作是 一个函数,输入是一个向量,输出也是一个向量
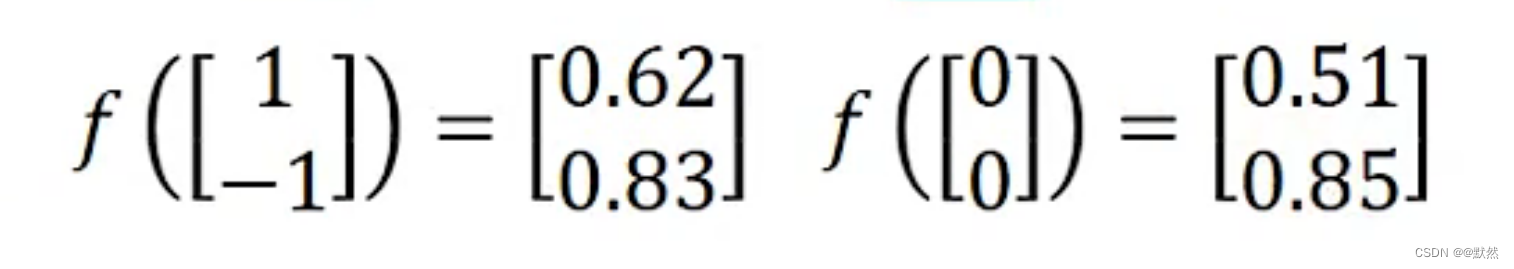
上述是一个简单的网络结构例子
如下图,由于 Layer 与 Layer 之间完全连接,并且都是从前到后,正向传播。因此这种网络结构被称之为全连接前馈网络
- Input Layer(输入层)
- Hidden Layers(隐藏层)
- Output Layer(输出层)
- Output(输出)

那么,所谓的深度学习就是指有很多层 Hidden Layers。
2. Matrix Operation(矩阵操作)
使用矩阵操作,可以用GPU进行加速,提高计算效率。

当输入层输入x1、x2、… 、xn后,将第一层的 w(权重参数)集合起来,用w1表示,将第一层的 b(偏差)集合起来,用b1表示。然后再通过 Sigmoid function 求出第一层所有的 Neural 的值,称为a1。将 a1 代入到第二层的运算中,以此类推…最终求出输出层 y


下图红色框起来的部分被称为特征抽取(Feature extractor),取代了我们之前机器学习中手动做特征工程(feature engineering),特征变换的过程(feature transformation)。

Softmax 前向计算

Softmax 反向传播求导(推导)


3. 手写数字辨识
对于一个16*16=256的图片来说,它的输入就是256维,输出就是10维,至于中间的网络结构一共有多少层,每层需要多少个神经元就需要自行设计了,而这些经验就来源于:试错+直觉。

4. goodness of function(模型/函数的好坏)
假设给定一组参数,现在根据下图中的手写 “1”,可知要达到的 target vector为粉红色区域部分。输入手写 “1”,根据神经网络得到输出,然后计算 y 和 ^y 之间的 Cross Entropy。调整神经网络参数,让 Cross Entropy 越小越好。

Cross-Entropy 前向计算

5. pick the best function (选择最佳函数)
将下图中所有的 Cross Entropy 加起来,得到 Total Loss。然后找一组 神经网络的参数,求出最小的 Total Loss。

而我们要找一组神经网络的参数使得Total Loss最小,往往采用 Gradient Descent(梯度下降)方法

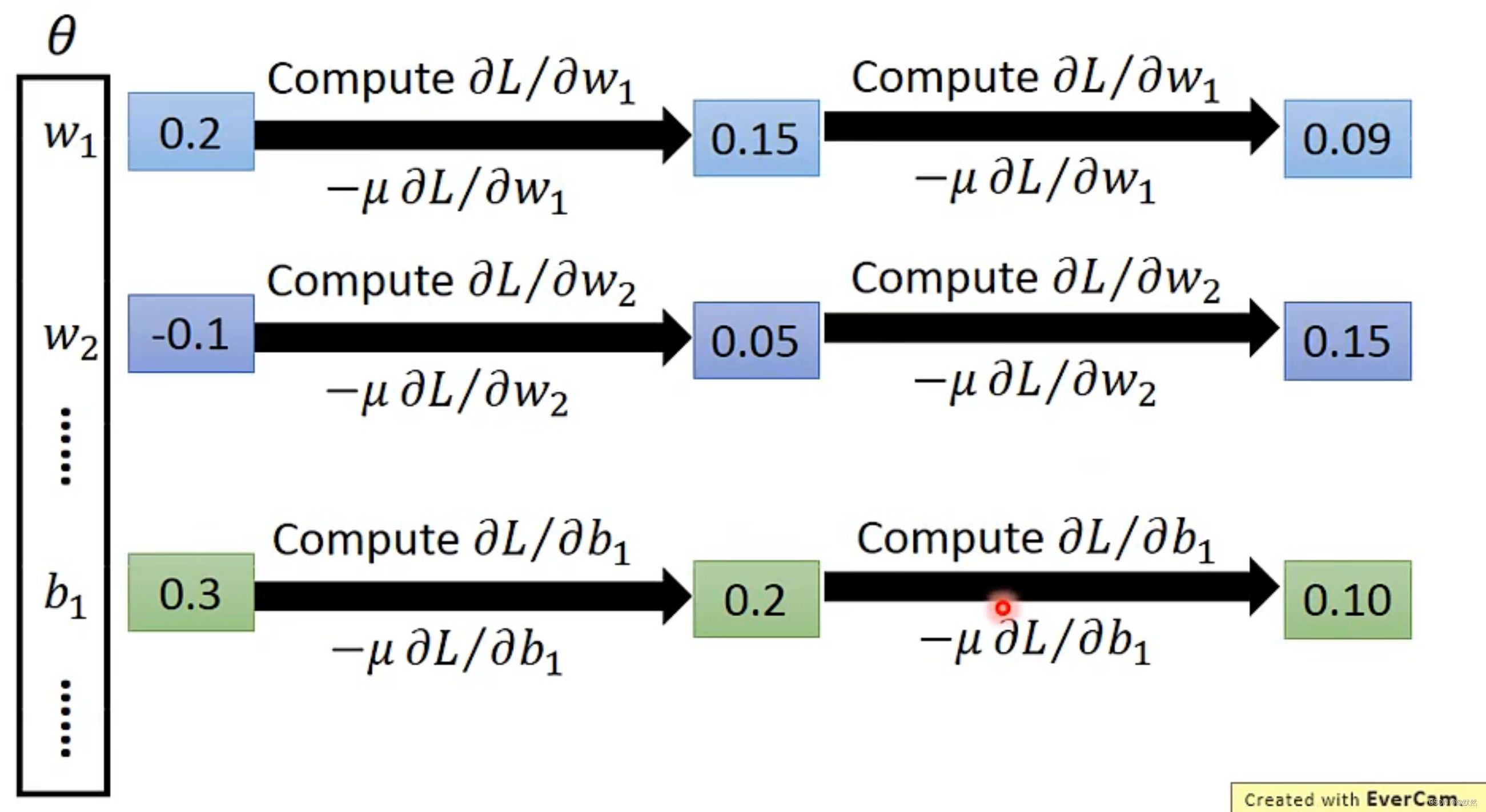
6. 反向传播
我们在前面每次 Training data 都采用了 Gradient Descent(梯度下降)方法来最佳化我们的模型,不断降低 Loss。但是在有些 Neural Network 中有非常多的参数(上百万的参数),就比如我们如果要做语音辨识系统,那Neural Network就会有7层或8层,上百万个参数。而对于如此多的参数,采用梯度下降方法优化,则需要求上百万次微分,即 Gradient ventor 是上百万维的向量。
那么,为了更加有效的计算上百万次微分,我们需要采用反向传播的方法来解决这个问题

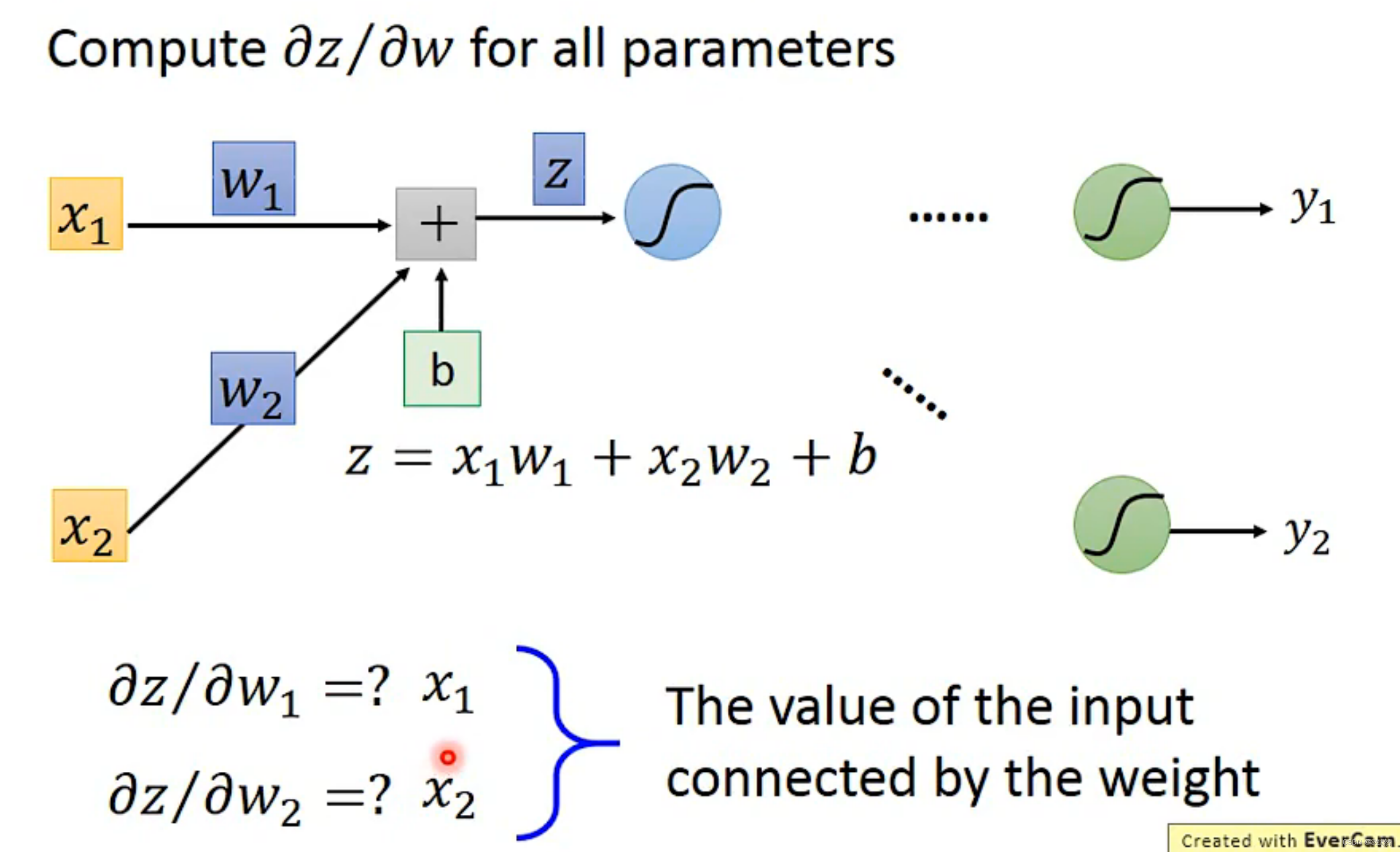
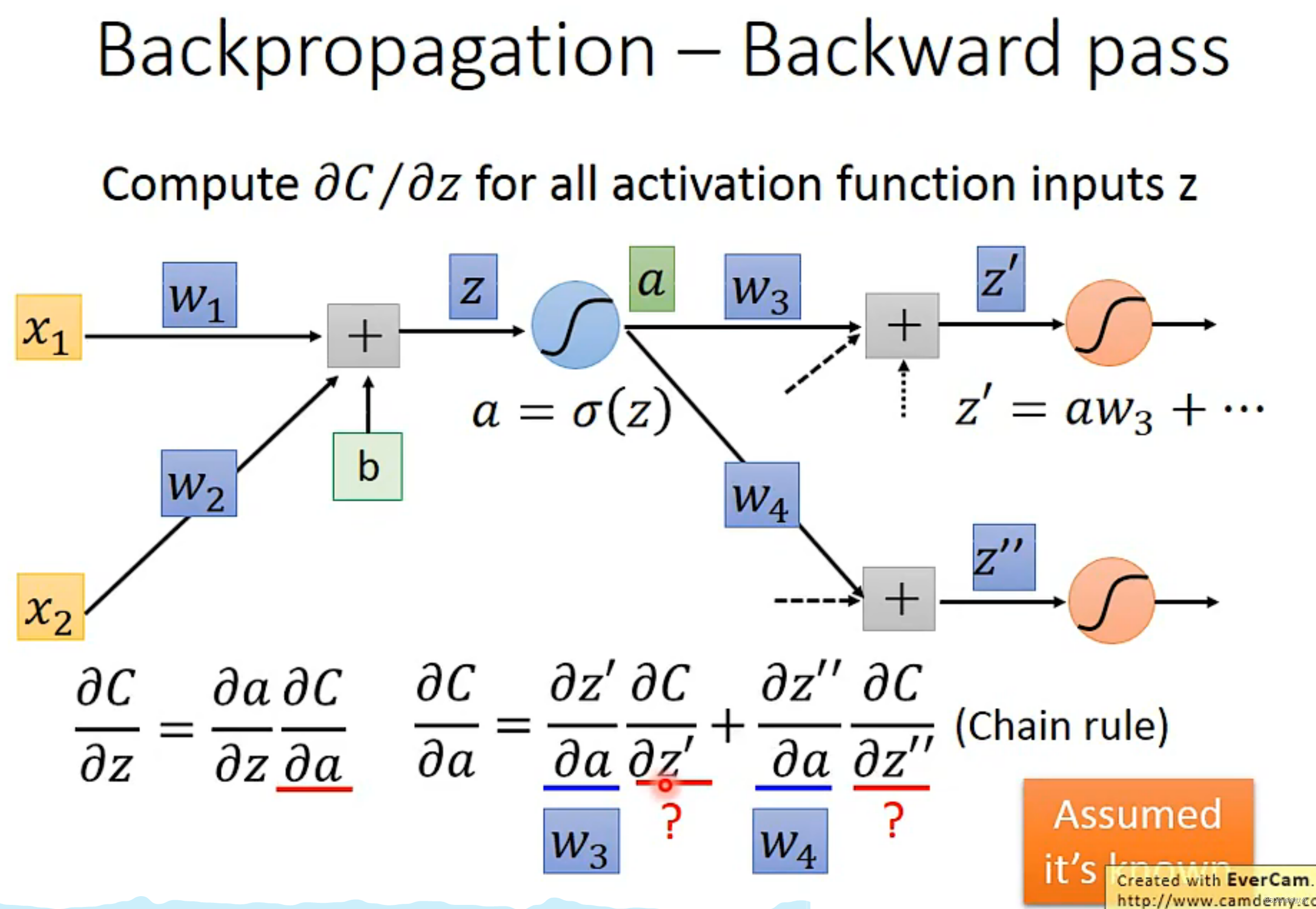
Chain Rule(链式法则)

反向传播(Backpropagation)是一种训练人工神经网络的方法,用于计算神经网络中每个权重的误差梯度。它是一种基于梯度下降的优化算法,通过调整神经网络中每个权重的值来最小化网络的误差。


在反向传播过程中,我们通过不断求取损失函数对每个参数的偏导数,来确定应该如何更新神经网络的参数,这样就能让神经网络在更多的数据上表现得更加准确,并提高模型的预测能力。




Cross-Entropy + Softmax 反向传播推导



总结
简单模型训练采用线性函式 y = b + wx,然后计算Loss误差值,最后梯度下降的方法优化模型,更新参数,降低误差值,简单模型训练仅限于解决线性问题。复杂模型训练会解决非线性问题,通常用Piecewise Linear去逼近非线性函数。而sigmoid函数用来处理非线性分类问题,调整sigmoid函数的参数,产生不同的sigmoid函数,将不同的 Sigmoid Function 相互叠加起来,用来近似地逼近 Piecewise Linear 的 Function。从而逼近各种不同的 Continuous 的 Function。
对于反向传播计算思路总结:
















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











