






1.tesseract下载安装
下载地址:Index of /tesseract
tesseract软件对应的是下载列表中的.exe文件,版本号已经更新到5.0,其中文件名中带有dev的代表是开发版,没有带的是稳定版,建议下载稳定版的,至于版本号可以根据需要选择,我使用的是5.0版本的:tesseract-ocr-w64-setup-v5.0.0-alpha.20210506.exe.
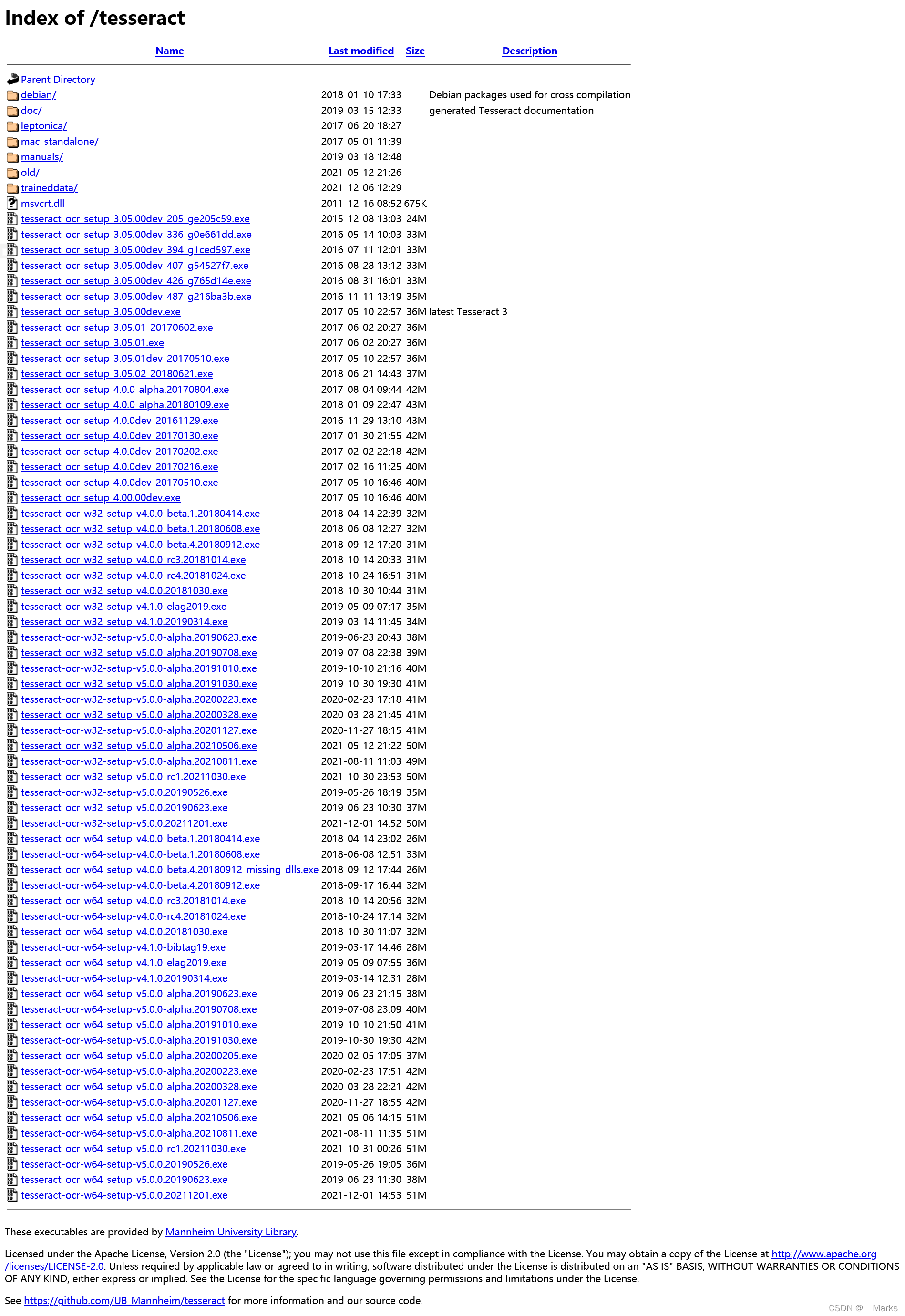
下载完成后双击软件进行安装 ,可以自定义安装路径,安装到下面一步时,可以选择下载附加语言包,默认是支持英文的,这一步之后安装步骤只需要一直点击next即可完成安装。
安装完成后,需要将tesseract软件的安装路径添加到环境变量中,如安装路径为:D:\图片识别,则打开环境变量把该路径添加进去即可。

验证tesseract软件是否安装成功以及是否添加到了环境变量中,打开cmd窗口,输入命令:
tesseract -v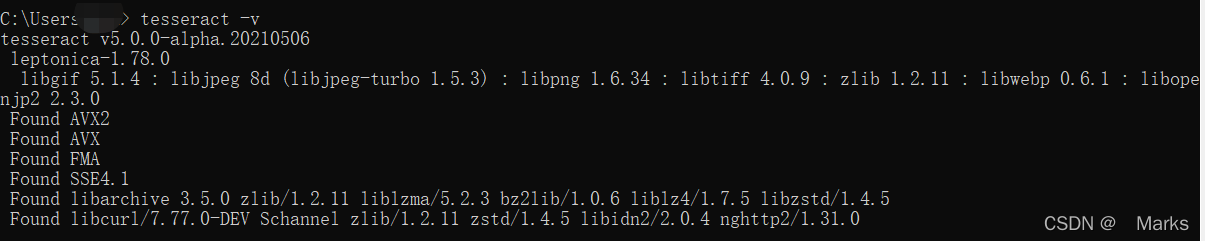
2.安装pytesseract库和Pillow库
在python中使用tesseract软件,还需要安装一个pytesseract库,以及一个图片处理的Pillow库打开cmd窗口依次输入下面两个命令:(我的是已经安装过了)
pip install pytesseract
pip install Pillow

# 导入相关库
import pytesseract
from PIL import Image
安装完成pytesseract库后,我们接着找到自己python的安装路径,假如我自己的python安装在 D:\Python 路径下,那么我按这个路径打开:D:\Python\Lib\site-packages\pytesseract,在pytesseract目录下找到pytesseract.py文件。
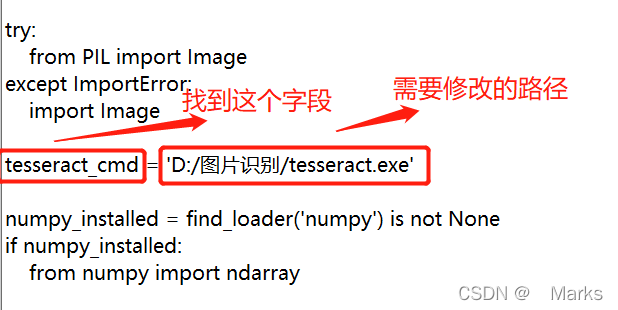
接着,用记事本或其它编辑软件打开它,找到 tesseract_cmd 这个字段,将它后面的路径改为tesseract软件的实际安装路径,就是上面你添加到环境变量中的路径,修改完成之后保存。
3.安装中文识别字库
因为前面说了tesseract软件默认是识别英文和阿拉伯数字的,为了更好的识别中文,我们还需要安装一个中文字库。字库下载地址: 中文字库

下载完成后将字库chi_sim.traineddata文件,复制到tesseract软件安装目录的tessdata目录下(D:\图片识别\tessdata)。
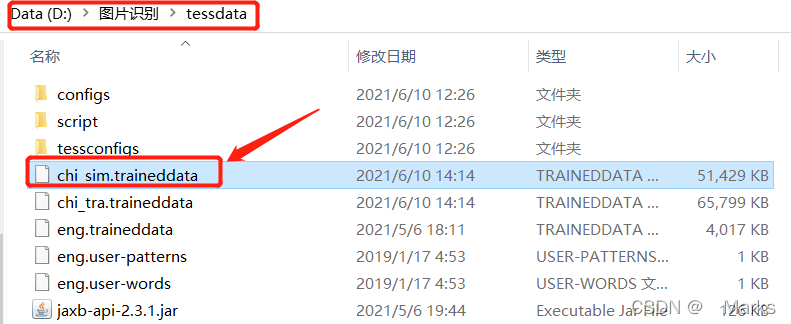
这一步完成之后就具备了识别图片文字的环境了,下面开始使用python程序识别文字。
4.Python图片文字识别程序
4.1 待识别的图片


4.2 识别程序
import pytesseract
from PIL import Image
img = Image.open('pic1.jpg') # 获取图片句柄
img = img.convert("L") # 图像转灰度
# 定义灰度界限(阈值),大于这个值为黑色(1),小于这个值为白色(0)
threshold = 200 # 可手动调整阈值,以达到更好识别效果,范围是(0-255)
# 图像二值化处理
table = []
for n in range(256):
if n < 150:
table.append(0)
else:
table.append(1)
img = img.point(table, '1')
# img.show() # 显示处理后图像
# img.save("pic.jpg") # 保存图像
# 识别图片文字
string = pytesseract.image_to_string(img, lang='chi_sim')
print(string.replace(" ", "")) # 打印识别信息,去掉识别内容中的空格字符4.3 识别结果
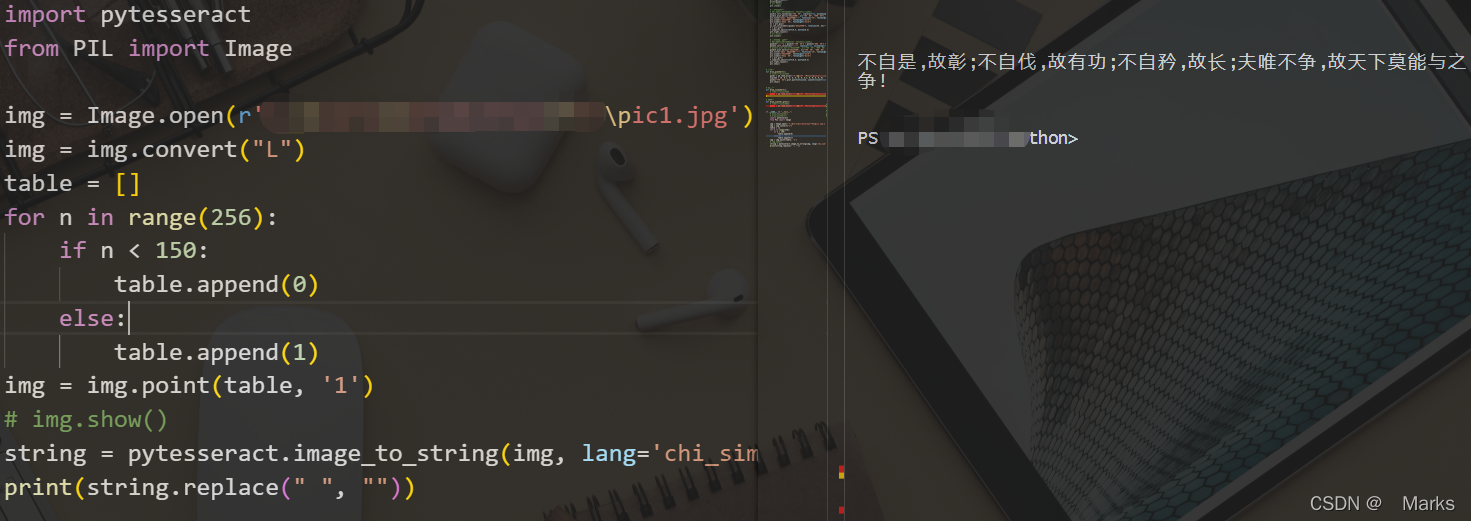
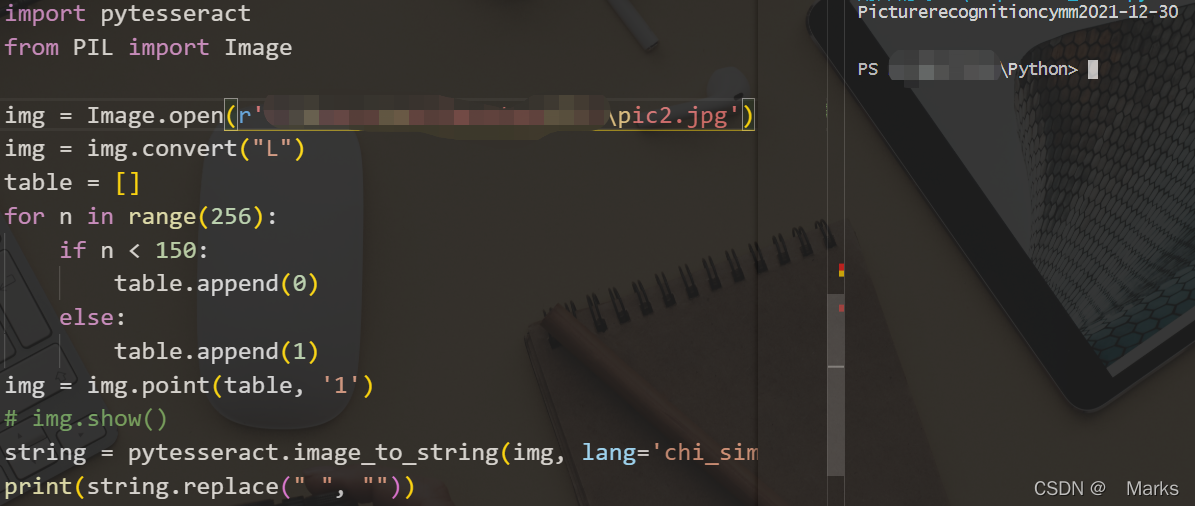 到这里,我们已经实现了用python识别图片基本的文字内容信息了,对于背景与文字有比较清晰轮廓的图片,识别起来不会有很大问题。但是对于一些内容比较丰富的图片,需要识别上面的文字,还需要对图片作多的处理。希望从这个文章开始,可以让你去了解学习更多处理图像的方法。记得点赞噢
到这里,我们已经实现了用python识别图片基本的文字内容信息了,对于背景与文字有比较清晰轮廓的图片,识别起来不会有很大问题。但是对于一些内容比较丰富的图片,需要识别上面的文字,还需要对图片作多的处理。希望从这个文章开始,可以让你去了解学习更多处理图像的方法。记得点赞噢

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









