







在实际应用中,一般会采用事件时间语义。而水位线,就是基于事件时间提出的概念。一个数据产生的时刻,就是流处理中事件触发的时间点,这就是“事件时间”,一般都会以时间戳的形式作为一个字段记录在数据里。这个时间就像商品的“生产日期”一样,一旦产生就是固定的,印在包装袋上,不会因为运输辗转而变化。如果我们想要统计一段时间内的数据,需要划分时间窗口,这时只要判断一下时间戳就可以知道数据属于哪个窗口了。
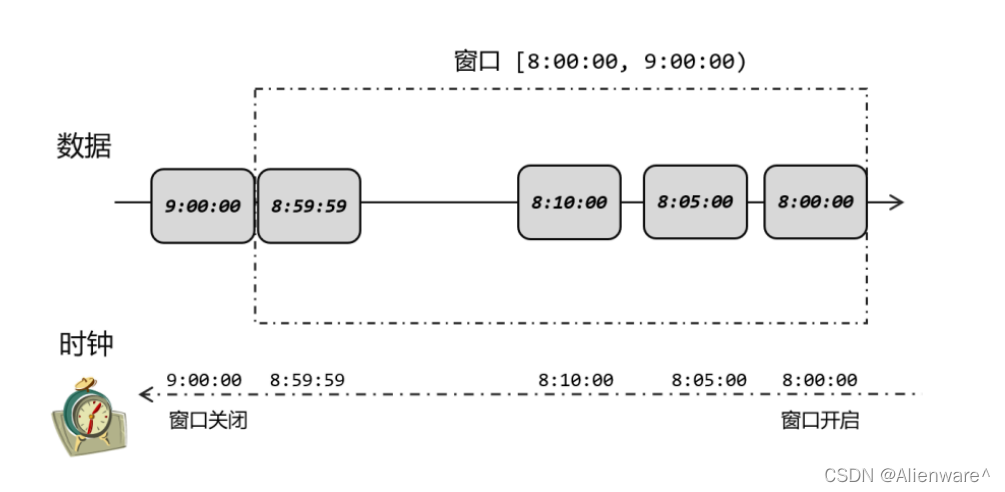
在这个处理过程中,我们其实是基于数据的时间戳,自定义了一个“逻辑时钟”。这个时钟的时间不会自动流逝;它的时间进展,就是靠着新到数据的时间戳来推动的。这样的好处在于,计算的过程可以完全不依赖处理时间(系统时间),不论什么时候进行统计处理,得到的结果都是正确的。比如双十一的时候系统处理压力大,我们可能会把大量数据缓存在 Kafka中;过了高峰时段之后再读取出来,在几秒之内就可以处理完几个小时甚至几天的数据,而且依然可以按照数据产生的时间段进行统计,所有窗口都能收集到正确的数据。而一般实时流处理的场景中,事件时间可以基本与处理时间保持同步,只是略微有一点延迟,同时保证了窗口计算的正确性。
什么是水位线
一种简单的想法是,在数据流中加入一个时钟标记,记录当前的事件时间;这个标记可以直接广播到下游,当下游任务收到这个标记,就可以更新自己的时钟了。由于类似于水流中用来做标志的记号,在 Flink 中,这种用来衡量事件时间(Event Time)进展的标记,就被称作“水位线”(Watermark)。
水位线的特性
水位线就代表了当前的事件时间时钟,而且可以在数据的时间戳基础上加一些延迟来保证不丢数据,这一点对于乱序流的正确处理非常重要。
总结一下水位线的特性:
-
水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据
-
水位线主要的内容是一个时间戳,用来表示当前事件时间的进展
-
水位线是基于数据的时间戳生成的
-
水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进
-
水位线可以通过设置延迟,来保证正确处理乱序数据
-
一个水位线 Watermark(t),表示在当前流中事件时间已经达到了时间戳 t, 这代表 t 之前的所有数据都到齐了,之后流中不会出现时间戳 t’ ≤ t 的数据
如何生成水位线
在 Flink 的 DataStream API 中 , 有 一 个 单 独 用 于 生 成 水 位 线 的 方法:.assignTimestampsAndWatermarks(),它主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间:
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(
WatermarkStrategy<T> watermarkStrategy)
具体使用时,直接用 DataStream 调用该方法即可,与普通的 transform 方法完全一样。
DataStream<Event> stream = env.addSource(new ClickSource());
DataStream<Event> withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks(<watermark strategy>);
这里读者可能有疑惑:不是说数据里已经有时间戳了吗,为什么这里还要“分配”呢?这是因为原始的时间戳只是写入日志数据的一个字段,如果不提取出来并明确把它分配给数据,
Flink 是无法知道数据真正产生的时间的。当然,有些时候数据源本身就提供了时间戳信息,比如读取 Kafka 时,我们就可以从 Kafka 数据中直接获取时间戳,而不需要单独提取字段分配了。
.assignTimestampsAndWatermarks() 方法需要传入一个 WatermarkStrategy 作为参数,这就是 所 谓 的 “ 水 位 线 生 成 策 略 ” 。 WatermarkStrategy 中 包 含 了 一 个 “ 时 间 戳 分 配器” TimestampAssigner 和一个“水位线生成器”WatermarkGenerator。
@Public
public interface WatermarkStrategy<T>
extends TimestampAssignerSupplier<T>, WatermarkGeneratorSupplier<T> {
// ------------------------------------------------------------------------
// Methods that implementors need to implement.
// 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









