







Flink 为这种场景专门提供了一个窗口联结(window join)算子,可以定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理。类似于SQL中的Join
窗口联结的调用
窗口联结在代码中的实现,首先需要调用 DataStream 的.join()方法来合并两条流,得到一个 JoinedStreams;接着通过.where()和.equalTo()方法指定两条流中联结的 key;然后通过.window()开窗口,并调用.apply()传入联结窗口函数进行处理计算。通用调用形式如下:
stream1.join(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
上面代码中.where()的参数是键选择器(KeySelector),用来指定第一条流中的 key; 而.equalTo()传入的 KeySelector 则指定了第二条流中的 key。两者相同的元素,如果在同一窗口中,就可以匹配起来,并通过一个“联结函数”(JoinFunction)进行处理了。这里.window()传入的就是窗口分配器,之前讲到的三种时间窗口都可以用在这里:滚动窗口(tumbling window)、滑动窗口(sliding window)和会话窗口(session window)。而后面调用.apply()可以看作实现了一个特殊的窗口函数。注意这里只能调用.apply(),没有其他替代的方法。
传入的 JoinFunction 也是一个函数类接口,使用时需要实现内部的.join()方法。这个方法有两个参数,分别表示两条流中成对匹配的数据。JoinFunction 在源码中的定义如下:
public interface JoinFunction<IN1, IN2, OUT> extends Function, Serializable {
OUT join(IN1 first, IN2 second) throws Exception;
}
这里需要注意,JoinFunciton 并不是真正的“窗口函数”,它只是定义了窗口函数在调用时对匹配数据的具体处理逻辑。
当然,既然是窗口计算,在.window()和.apply()之间也可以调用可选 API 去做一些自定义,比如用.trigger()定义触发器,用.allowedLateness()定义允许延迟时间,等等。
除了 JoinFunction,在.apply()方法中还可以传入 FlatJoinFunction,用法非常类似,只是内部需要实现的.join()方法没有返回值。结果的输出是通过收集器(Collector)来实现的,所以对于一对匹配数据可以输出任意条结果。
其实仔细观察可以发现,窗口 join 的调用语法和我们熟悉的 SQL 中表的 join 非常相似:
SELECT * FROM table1 t1, table2 t2 WHERE t1.id = t2.id;
这句 SQL 中 where 子句的表达,等价于 inner join … on,所以本身表示的是两张表基于 id的“内连接”(inner join)。而 Flink 中的 window join,同样类似于 inner join。也就是说,最后处理输出的,只有两条流中数据按 key 配对成功的那些;如果某个窗口中一条流的数据没有任何另一条流的数据匹配,那么就不会调用 JoinFunction 的.join()方法,也就没有任何输出了。
窗口联结实例
在电商网站中,往往需要统计用户不同行为之间的转化,这就需要对不同的行为数据流,按照用户 ID 进行分组后再合并,以分析它们之间的关联。如果这些是以固定时间周期(比如1 小时)来统计的,那我们就可以使用窗口 join 来实现这样的需求。
下面是一段示例代码:Gitee中的实例
public class WindowJoinTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//定义两条流
DataStream<Tuple2<String, Long>> stream1 = env.fromElements(
Tuple2.of("a", 1000L),
Tuple2.of("b", 1000L),
Tuple2.of("a", 2000L),
Tuple2.of("b", 2000L)
)
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
}
)
);
DataStream<Tuple2<String, Long>> stream2 = env.fromElements(
Tuple2.of("a", 3000L),
Tuple2.of("b", 3000L),
Tuple2.of("a", 4000L),
Tuple2.of("b", 4000L)
)
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
}
)
);
stream1
.join(stream2)
.where(data -> data.f0)
.equalTo(data -> data.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public String join(Tuple2<String, Long> left, Tuple2<String, Long> right) throws Exception {
return left + "=>" + right;
}
})
.print();
env.execute();
}
}
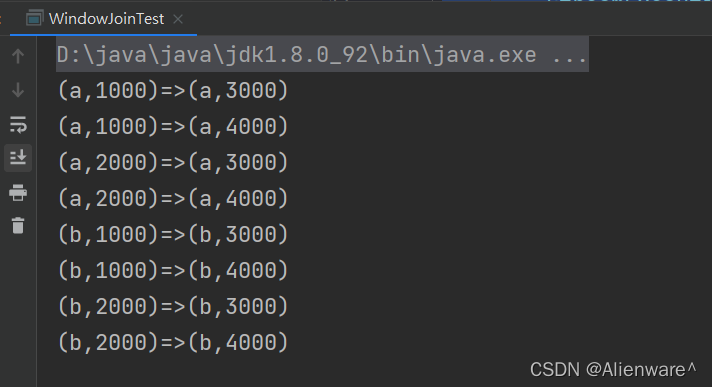
运行的结果是一个笛卡尔积














 5121
5121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









