






为什么要使用Kaggle API?这个问题约等于为什么要使用git clone命令而不是手动下载github项目。它并不是必要的,但会让你的数据下载过程更丝滑(同时更迎合极客们的心理需求)
一次配置,终身轻松。
pip install kaggle即可,API 相当于安了一个天线接收器,可以接收到kaggle发来的数据包。
-
获取kaggle token:
安好天线之后,需要添加一把钥匙来识别是谁向kaggle请求数据,你加入了这个竞赛,有数据请求权限才会给你发数据。token的作用就是识别你是谁。
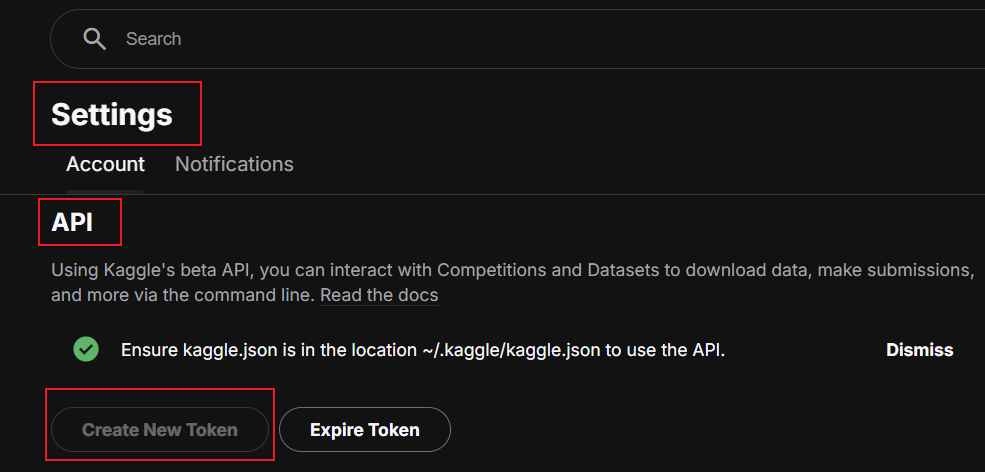
设置-API-创建新token,如果以前在旧设备上创建过,就expire再创建新的token
自动会下载kaggle.json文件,其实就是一个存了你账号名和密钥的键值对:

-
把json文件放到kaggle文件夹下。
不知道.kaggle文件夹在哪里没关系,先在terminal里面输入一次命令行,比如我请求的是一个nlp入门竞赛(地址:(https://www.kaggle.com/competitions/nlp-getting-started)):
kaggle competitions download -c nlp-getting-started
很容易看出任意竞赛的数据请求方式:
竞赛地址:https://www.kaggle.com/competitions/竞赛名称
命令应为:kaggle competitions download -c 竞赛名称
此时肯定会报错的,因为读不到你的token,在报错信息里面可以找到你的.kaggle文件地址:

把json文件粘贴进去就可以啦
- 运行数据请求命令
在terminal运行命令即可。想要在jupyter notebook的块里运行就加个!:
!kaggle competitions download -c nlp-getting-started
下载后要手动给zip包解压,这点很不智能……
下次拉取别的数据集只用执行第四步即可。

















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









