






大自然的搬运工又又又又又来啦!!!,实验课实在是不知道该干嘛了,那就做一个合格的搬运工吧!(手动狗头)
Hive初识
Hive 简介
Hive官方网址
Hive是基于Hadoop(HDFS, MapReduce)的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。本质上是把HQL语句转换成MapReduce程序。
Hive本身是建立在 Hadoop体系结构上的数据仓库基础构架,可以将结构化的数据文件映射为一张数据库表,并提供完整的QL语句,把QL语句转化成MapReduce程序提交给Hadoop集群完成相关任务。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop中的大规模数据处理的机制。Hive 定义了简单的类SQL查询语言,称为 QL ,它允许熟悉SQL的用户查询数据。同时,这个语言也允许熟悉 MapReduce开发者的开发自定义的 mapper和 reducer来处理内建的 mapper 和 reducer无法完成的复杂的分析工作。

Hive的特点
1、Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
2、Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
3、Hive的设计目的是让精通SQL技能的(java编程能力相对较弱)分析师能够对放在HDFS上的海量数据集能够进行查询。目前企业都把它当做一个通用,可伸缩的数据处理平台。
4、学习hive的前提条件:熟悉SQL和数据库体系结构。
5、Hive执行原理:把SQL查询转换为一系列在Hadoop集群上运行的MapReduce作业。Hive把数据组织能表,通过这种方式为存储在HDFS的数据赋予结构。
Hive的基本组件

1、 用户接口,包括 CLI,JDBC/ODBC,WebUI;
2、 元数据存储,通常是存储在关系数据库如 MySQL, derby 中;
3、解释器、编译器、优化器、执行器。
Hive的数据存储
Hive 将元数据存储在数据库中(metastore),目前只支持MySQL、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
Hive的SQL方言称为HiveQL,它并不完全支持SQL-92标准。例如:HiveSQL并不支持Having子句,但支持子查询。
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)。
Hive与Hadoop之间的关系
1、Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
2、Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内置的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive的安装与使用
Hive安装前准备
Hive依赖于Hadoop,而Hadoop依赖于java。用户需要确认使用的操作系统中安装有V1.7.*或者V1.8.*版本的JVM(java虚拟机)。在第一章中我们搭建好了Hadoop环境。在此我们就在第一章搭建的Hadoop环境上,安装和配置Hive
安装Hive的注意事项
1、安装Hive时,首先确保Hadoop已经安装完毕并且能正确使用
2、 因为Hive是基于Hadoop平台,安装Hive之后需要进行相关配置,相关文件:hive-evn.sh和hive-site.xml
3、建议配置Hive的path环境:HIVE_HOME在/etc/profile
Hive有自带的一个关系型数据库derby,如果使用自带的数据库,需要进行数据库的相关配置。如果开发者想更换数据库,例如更换MySQL数据库,则需要进行配置文件的修改并且需要提供MySQL数据库驱动放到Hive_home/lib下。目前Hive主要是支持derby和MySQL数据库。
Hive安装步骤(基于自带数据库derby)
1、解压hive-0.13.1-cdh5.3.6.tar.gz,命令如下:
tar -zxvf hive-0.13.1-cdh5.3.6.tar.gz -C /iflytek
将hive-0.13.1-cdh5.3.6修改为hive-0.13.1,命令如下:
mv hive-0.13.1-cdh5.3.6 hive-0.13.1
2、配置hive-evn.sh
在Hive的安装目录下的conf文件中修改hive-env.sh文件,如果该目录不存在该文件,可使用如下命令复制:
cp hive-env.sh.template hive-env.sh (hive-evn.sh文件名是固定的,不得随意修改)
复制完毕之后 vim hive-evn.sh,增加hadoop的安装目录 如:HADOOP_HOME=/iflytek/hadoop-2.5.0
3、修改环境变量:vim /etc/profile .添加hive的安装目录和path路径
export HIVE_HOME=/iflytek/hive-0.13.1(新添加)
export PATH=$JAVA_HOME/bin:$HIVE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

4、刷新/etc/profile文件,命令如下:
source /etc/profile
5、测试Hive的使用,需首先将hadoop进程开启。
6、Hadoop进程成功开启后,使用如下命令进入Hive:hive
Hive的文件管理
bin:可执行文件(二进制),例如:hive hiveserver2 hive-config.sh等;
conf:hive的配置文件,里面的配置文件都是默认的配置文件,它是缺省配置服务的。如果需要自定义,配置文件需要创建一个hive-site.xml;
docs:hive的参考文档;
lib:存放jar的地方;
metastore_db:该目录是启动hive的时候,自动生成的一个目录,是用来存放hive的元数据信息。
元数据信息metastore
Hive中metastore(元数据存储)的三种方式:
1、内嵌Derby方式
2、Local方式
3、Remote方式
Metastor是hive元数据的集中存放地。Metastore包括两部分:服务和后台数据的存储。
内置默认的metastore即使用derby作为元数据库存在问题:
1、换执行路径后,原来的表不存在了。
2、只能有一个用户访问同一个表。
因此derby只支持单连接,如果采用多连接的话需要进行切换目录。在生产环境中一般不使用derby作为我们的元数据库,采用MySQL的居多,能够多用户同时访问
Metastor常见配置项:
Ø hive.metastore.warehouse.dir 存储表格数据的目录
Ø hive.metastore.local 使用内嵌的metastore服务(默认为true)
Ø hive.metastore.uris 如果不使用内嵌的metastore服务,需指定远端服务的uri
Ø javax.jdo.option.ConnectionURL 所使用数据库的url
Ø javax.jdo.option.ConnectionDriverName 数据库驱动类
Ø javax.jdo.option.ConnectionUserName 连接用户名
Ø javax.jdo.option.ConnectionPassword 连接密码
说明:derby数据库默认创建在当前目录下。 在做hive操作命令时,先把hadoop服务启动起来,否则,操作dml语句时,报错。
Hive的基本操作
#创建数据库
create database tabletest;

#创建一个新表,创建表的同时,指定数据字段之间的分割符:

#导入数据
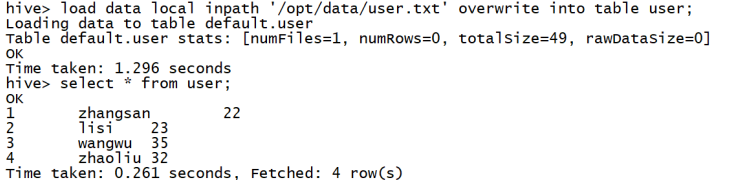
在/opt/data下准备user.txt。如:

load data local inpath '/opt/data/user.txt' overwrite into table user;
#增加一个字段:

#将HDFS上的文件加载到hive中
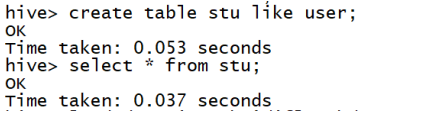
复制一个表结构不导数据:
在/opt/data下创建数据文件:stu.txt。如下:

将stu.txt导入HDFS,命令如下:
hdfs dfs -put /opt/data/stu.txt /
文件导入数据
load data inpath '/stu.txt' overwrite into table stu;

#导出到本地文件系统

在本地可以查看导出的文件内容:

#删除表
drop table if exists 表名
离开hive环境
exit;
Hive的数据类型

复杂数据类型:
== ARRAY:== ARRAY类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问。比如有一个ARRAY类型的变量fruits,它是由[‘apple’,‘orange’,‘mango’]组成,那么我们可以通过fruits[1]来访问元素orange,因为ARRAY类型的下标是从0开始的;
== MAP:== MAP包含key->value键值对,可以通过key来访问元素。比如“userlist”是一个map类型,其中username是key,password是value;那么我们可以通过userlist[‘username’]来得到这个用户对应的password;
STRUCT: STRUCT可以包含不同数据类型的元素。这些元素可以通过“点语法”的方式来得到所需要的元素,比如user是一个STRUCT类型,那么可以通过user.address得到这个用户的地址。
UNION: UNIONTYPE,他是从Hive 0.7.0开始支持的。
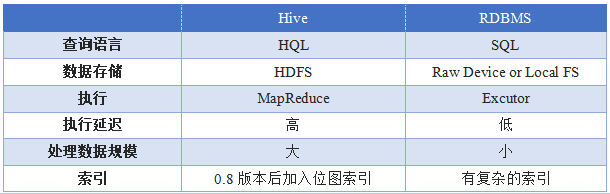
Hive与传统数据库的区别

常见的数据库查询
1、基本查询
1)select * from stu;
2)where子句
select * from stu where 字段=值;
3)Limit查询
select * from stu limit 3;//查询所有数据的前三条
说明:limit的使用和MySQL稍微有点区别。hive中的limit只有一个参数
4)区间查询between and
select * from stu s where s.age between s.age=20 and s.age =25;
5)集合查询in
select * from stu s where s.name in ('lisi','zhaoliu');
2、函数查询
select count(*) from stu; //总人数
select sum(字段1) from stu; //总和
select max(字段1) from stu; //最大值
select min(字段1) from stu; //最小值
select avg(字段1) from stu; //平均值
3、高级查询
1)分组group by
select * from stu group by addr;
2)having
where:是针对单条记录进行筛选。
having是针对分组数据进行筛选
select name,sum(score) from stu group by name having sum(score)>90;
3)order by查询
select * from stu order by name asc[desc];
4) join
两个表进行连接,例如有两个表m n ,m表中的一条记录和n表中的一条记录组成一条记录。
内连接
select b.name,a.* from stu a join score b on(a.id=b. id) limit 10;
左外连接
select b.name,a.* from stu a left outer join score b on a. id =b. id limit 10;
右外连接
select b.name,a.* from stu a right outer join score b on a. id =b. id limit 10;
5)Like模糊查询
select * from stu where name like '%ang%';
数据库
1、类似传统数据库的DataBase;
2、默认数据库"default";
3、使用#hive命令后,不使用hive>use <数据库名>,系统默认的数据库。可以显式使用hive> use default
表
Hive表逻辑上由存储的数据和描述表格形式的相关元数据组成。数据一般放在HDFS上。Hive把元数据放在关系型数据库中,并不是放在HDFS上。
1、Table内部表(托管表):当删除内部表时,HDFS上的数据以及元数据都会被删除。
create table student(id int,name string);
2、Partition分区表:Hive把表组织成分区,分区可以加快分片的查询速度。将一批数据分成多个目录来存储。
Create table day_table (id int, content string)
partitioned by (dt string) //指定分区
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
以分区的常用情况为例。考虑日志文件,其中每条记录包含一个时间戳。如果我们根据日期进行分区,那么同一天的记录就会被存放在同一个分区中。这样对于限定某个条件的查询,效率会非常高,因为它只需要扫描查询范围内的文件。
3、External Table外部表
Create external table student(id int,name string)location ‘路径’;//创建外部表时指定位置。
创建表时使用external关键字时,hive知道数据并不属于自己管理,不会把数据移到自己的数据仓库中。当删除外部表的时候,HDFS上的数据不会被删除,但是元数据会被删除。
说明:在创建外部表时,要先在路径下准备数据,然后再创建表。
4、Bucket Table 桶表:分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储,一个文件对应一个桶,由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中,对于hive中每一个表、分区都可以进一步进行分桶。
好处:提高了join的效率;提高了随机抽样的效率。
使用分桶表要修改set hive.enforce.bucketing=true;
桶表会为数据提供额外的结构以获得更高效的查询处理。
内表
内部表与数据库中的表在概念上是类似的,每一个表在Hive中都有一个相应的目录存储数据。例如,一个表 test,它在 HDFS 中的路径为:/ warehouse/test。 warehouse是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录。所有的表数据(不包括外部表)都保存在这个目录中。删除表时,元数据与数据都会被删除
示例如下:
1、创建表
CREATE TABLE inner_table( //table前没有修饰符,说明创建的是一个内部表
id INT,
name STRING,
age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' //字段间的分隔符
COLLECTION ITEMS TERMINATED BY ',' //集合元素之间的分隔符
MAP KEYS TERMINATED BY ':' //map中key和value之间的分隔符
LINES TERMINATED BY '\n'; //行与行之间的分隔符
LOCATION "/test" //可以设置源数据的位置,若不设置默认就在Hive的工作目录区
2、导入数据
load data local inpath '/opt/data/user.txt' overwrite into table inner_table;
3、查询表中字段的值
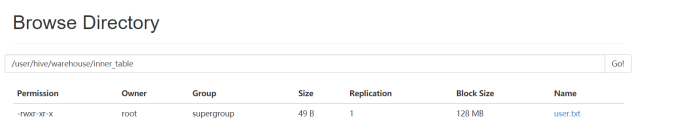
select * from inner_table;
在HDFS目录查看:
4、删除表 drop table inner_table;
删除后HDFS目录:
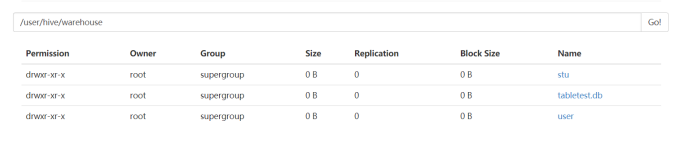
由此,可以看出当删除内部表后,HDFS上的数据和元数据都会被删除。
外部表
外部表指向已经在 HDFS 中存在的数据,可以创建 Partition。它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。内部表的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。外部表只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅删除该链接
示例如下:
1、创建表
create external table external_table(
id int,
name string,
age int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location '/iflytek/';
在HDFS创建目录/iflytek
hdfs dfs -mkdir /iflytek
2、加载数据
load data local inpath '/opt/data/user.txt' overwrite into table external_table;
3、查看数据
select * from external_table;
在HDFS中查看数据:

4、删除表
drop table external_table;

由此,可以看出当删除外部表时,仅会删除元数据,但并不会删除HDFS上的数据。
分区表
Partition对应于数据库的Partition列的密集索引,在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中。
语法:
CREATE TABLE tmp_table #表名
(
title string, # 字段名称 字段类型
minimum_bid double,
quantity bigint,
have_invoice bigint
)COMMENT '注释:XXX' #表注释
PARTITIONED BY(pt STRING) #分区表字段(如果你文件非常之大的话,采用分区表可以快过滤出按分区字段划分的数据)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001' # 字段是用什么分割开的
STORED AS SEQUENCEFILE; #用哪种方式存储数据,SEQUENCEFILE是hadoop自带的文件压缩格式
一些相关命令:
SHOW TABLES; # 查看所有的表
SHOW TABLES '*TMP*'; #支持模糊查询
SHOW PARTITIONS TMP_TABLE; #查看表有哪些分区
DESCRIBE TMP_TABLE; #查看表结构
实例如下:创建数据文件partition_table.txt
1、创建表
create table partition_table(
id int,
name string,
age int
)
partitioned by(addr string)
row format delimited fields terminated by '\t' stored as TEXTFILE;
2、加载数据到分区
load data local inpath '/opt/data/partition_table.txt' into table partition_table partition (addr='beijing');
3、查看数据
select * from partition_table;
4、添加分区
alter table partition_table add partition (addr='shanghai');
5、删除分区:元数据,数据文件删除,但目录还在
alter table partition_table drop partition (addr='beijing');\
6、查看HDFS:

7、删除表
drop table partition_table;
桶表
桶表是对数据进行哈希取值,然后放到不同文件中存储。
1、创建表
create table bucket_table(id string) clustered by(id) into 4 buckets;
2、加载数据
set hive.enforce.bucketing = true;
insert into table bucket_table select name from stu;
insert overwrite table bucket_table select name from stu;
3、数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。
4、抽样查询
select * from bucket_table tablesample(bucket 1 out of 4 on id);
基于Mysql的Hive环境部署
Hive配置(本地模式)
1、解压hive-0.13.1-cdh5.3.6.tar.gz,命令如下:
tar -zxvf hive-0.13.1-cdh5.3.6.tar.gz -C /iflytek
将hive-0.13.1-cdh5.3.6修改为hive-0.13.1,命令如下:
mv hive-0.13.1-cdh5.3.6 hive-0.13.1
2、配置hive-evn.sh
在Hive的安装目录下的conf文件中修改hive-env.sh文件,如果该目录不存在该文件,可使用如下命令复制:
cp hive-env.sh.template hive-env.sh (hive-evn.sh文件名是固定的,不得随意修改)
复制完毕之后 vim hive-evn.sh,增加hadoop的安装目录 如:HADOOP_HOME=/iflytek/hadoop-2.5.0
3、修改环境变量:vim /etc/profile .添加hive的安装目录和path路径
export HIVE_HOME=/iflytek/hive-0.13.1(新添加)
export PATH=$JAVA_HOME/bin:$HIVE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
如下图:

4、刷新/etc/profile文件,命令如下:source /etc/profile
MySQL的卸载与安装
1、rpm -qa |grep -i MySQL //查看是否存在安装MySQL
如果存在,则需要卸载:
rpm -e MySQL-libs-5.1.71-1.el6.x86_64
rpm -e MySQL-server-5.1.73-1.glibc23.x86_64
rpm -e MySQL-client-5.1.73-1.glibc23.x86_64
如果在安装过程出现包的冲突或者包的依赖
rpm -e MySQL-libs-5.1.71-1.el6.x86_64--nodeps
rpm -e MySQL-server-5.1.73-1.glibc23.x86_64--nodeps
rpm -e MySQL-client-5.1.73-1.glibc23.x86_64--nodeps
2、一般情况下Linux在写入完毕之后,有些文件需要手动删除,找到相关MySQL文件
一般(centos)/usr/lib/MySQL or /var/lib/MySQL or /usr/lib/MySQL/MySQL
如果找MySQL相关文件,执行命令 find /-name MySQL.
通过以上命令找到的MySQL进行手工删除
rm -rf /usr/lib/MySQL
rm -rf /var/lib/MySQL
3、安装MySQL
rpm -ivh MySQL-server-5.1.73-1.glibc23.x86_64
rpm -ivh MySQL-client-5.1.73-1.glibc23.x86_64
在安装过程中,有可能碰到权限问题或者用户所属问题,文件用户所属和文件权限修改chmod -R 777 /xxx
4、安装完MySQL服务端和客户端之后,需要进行配置,执行命令:
/usr/bin/MySQL_secure_installation
#验证MySQL是否安装成功
service MySQL status | start |stop
chkconfig MySQL --list
#测试安装的数据库
5、测>MySQL
1)建库建表来测试
2)测试我们MySQL-front客服端有没链接上我们的linux
6、如果远程连接数据库时,出现不允许访问的时候,需要对连接用户赋予权限
进入MySQL命令:
MySQL -uroot -psimple
grant all privileges on *.* to 'root'@'%' identified by 'simple' with grant option;
flush privileges;
7、权限刷新之后,重启MySQL服务
service MySQL restart(推荐)
Hive环境变量配置
#解压、重命名、设置环境变量(上面已经配置了,本地模式)
#在目录 $HIVE_HOME/conf 下,执行命令 mv hive-default.xml hive-site.xml重命名
并修改 $HIVE_HOME/conf/hive-site.xml
#vim /iflytek/hive-0.13.1/conf/hive.site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
< !-- 所使用的数据库的url -- >
<value>jdbc:mysql://localhost:3306/hivemeta?
createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
< !-- 数据库驱动类-- >
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
< !-- 连接用户名-- >
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
< !-- 连接密码-- >
<value>123456</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
Hive环境配置说明
1、hive-0.13.1/conf目录下hive-default.xml.template文件,在不修改文件名的情况下,该文件中的默认配置是不能改变的,即使该文件的内容改变,但是不会起到任何作用 ;除非修改还文件命名才有效,如果希望自动是该文件有效,命名必须为hive-site.xml。
#配置MySQL url路径时,metastore的数据库名尽量不要包含特殊字符(例如:-_ .等),在目录$HIVE_HOME/conf 下,执行命令mv hive-env.sh.template hive-env.sh重命名
2、修改hadoop的配置文件hadoop-env.sh,修改内容如下:
HADOOP_HOME=/usr/local/hadoop
3、在目录下$HIVE_HOME/bin下面,修改文件hive-config.sh,增加以下内容:
export JAVA_HOME=/iflytek/jdk1.8.0_11
export HIVE_HOME=/iflytek/hive-0.13.1
export HADOOP_HOME=/iflytek/Hadoop-2.5.0
4、MySQL的驱动MySQL-connector-java-5.1.28.jar加到/usr/local/hive-0.13.0/lib/
#测试是否配置成功(测试之前一定不要忘记启动hadoop)
hive //在任何目录下都可以直接启动hive,因为hive配置环境变量
./hive //在没有配置环境变量的情况下,必须在/usr/local/hive-0.13.0/bin目录下执行
5、在测试的过程中有可能文件权限的问题,对应目录主要有两个:
hdfs://192.168.203.100:9000/tmp
/tmp
hdfs dfs -chmod -R 1777 /tmp //hdfs上的文件权限
chmod -R 1777 /tmp //linux文件权限
Hive 测试
使用数据库客户端连接数据库结果查看到(此处使用的是My-front)

启动hive
hive
创建数据库
hive> create database test_db;
显示所有数据库
show databases;
使用数据库test_db
hive> use test_db;
创建学生表
hive> create table student(id int,name string);
查看是否在HDFS中存有下面文件夹
http://namenode:50070/user/hive/warehouse/test_db.db/student
Hive UDF编程
Hive内置函数
在编写自定义UDF函数之前,我们先熟悉下Hive中自带的那些UDF。需要注意的是在Hive中通用使用“UDF”来表示任意的函数,包括用户自定义的或者内置的。
Show functions命名可以例举出当前Hive会话中所加载的所有函数名称,其中包括内置和用户加载进来的函数,加载方式稍后会进行介绍:

函数通常都有其自身的使用文档。使用desribe function 命名可以展示对应函数简短的介绍,例如:

函数也可能包含更多的详细文档,可以通过增加extended 关键字进行查看,如下:

UDF编程
编程步骤:
1、继承org.apache.hadoop.hive.ql.UDF;
2、需要实现evaluat函数,evaluate函数支持重载。
注意事项:
1、UDF必须要有返回值类型,可以返回null,但是不能为void;
2、UDF中常用Text/LongWritable等类型,不推荐使用Java类型;
下面我们开始编写自己的UDF。假设我们要实现一个自己的小写转换函数lowerUDF,可以这样实现:
#下面是一个样本数据集,我们将其放到/opt/data/下一个名为person.txt的文件:
1 ZHANGSAN 16
2 LISI 28
3 WANGWU 17
4 ZHAOLIU 29
#创建表
create table person(id int,name string ,age int) row format delimited fields terminated by '\t';
#导入数据
load data local inpath '/opt/data/person.txt' overwrite into table person;
#创建java文件把hive中lib包下面的jar包导入到项目中并把hadoop的通用包导入到项目中
/iflytek/hive-0.13.1/lib/xxx.jar /iflytek/hadoop-2.5.0/share/hadoop/common/xxx.jar
public class LowerUDF extends UDF{
public Text evaluate(Text str) {
//validate
if(null==str.toString()) {
return null;
}
//lower
return new Text(str.toString().toLowerCase()) ;
}
public static void main(String[] args) {
System.out.println(new LowerUDF().evaluate(new Text( )));
}
}
1、把创建的类导出LowerUDF.jar
2、把打包的jar通过hive命令 添加到path中
hive>add jar /iflytek/LowerUDF.jar;
3、临时函数
create temporary function LowerUDF as 'com.iflytek.udf. LowerUDF';
4、测试查询:
select LowerUDF(name) from person;

UDF与GenericUDF编程
前面介绍计算UDF的例子中,我们继承的是UDF类。Hive还提供了一个对应的称为GenericUDF的类。GenericUDF是更为复杂的抽象概念,但是其支持更好的null值处理同时可以处理一些UDF无法支持的编码操作。GenericUDF的一个例子就是Hive中的cass…when语句,其会根据语句中输入的参数二产生复杂的处理逻辑。下面我们将展示如何通过继承GenericUDF类来编写一个用户自定义函数我们称之为nvl(),这个函数传入的值如果是null,那么就会返回一个默认值。
函数nvl要求有2个参数。如果第一个参数就是非null值,那么就会返回这个值,如果第一个参数是null,那么将返回第二个参数的值。GenericUDF框架知识和处理这类问题。通过继承标准的UDF确实是一个解决方案,不过那样就需要针对如此多的输入类型重载众多的evaluate方法,这样显得非常麻烦。而GenericUDF将会以编辑的方式检查输入的数据类型,然后做出合适的反馈。
我们以普通import语句的细目列表开始这个代码:
package org.apache.hadoop.hive.q1.udf.generic;
import org.apache.hadoop.hive.q1.exec.Description;
import org.apache.hadoop.hive.q1.exec.UDFArgumentException;
import org.apache.hadoop.hive.q1.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.q1.exec.UDFArgumenTypeException;
import org.apache.hadoop.hive.q1.metadata.HiveException;
import org.apache.hadoop.hive.q1.udf.generic.GenericUDF;
import org.apache.hadoop.hive.q1.udf.generic.GenericUDFUtils;
import org.apache.hadoop.hive.serde2.objectinspector.objectInspector;
现在需要这个类继承GenericUDF,然后开发这个类通常需要实现的方法。其中initialize()方法会被输入的每个参数调用,并最终传入方法的类型是不合法的,这时用户同样可以向控制抛出一个Exception异常信息。returnOIResolver是一个内置的类,其通过获取非null的变量的类型并使用这个数据类型来确定返回值类型:
public class GenericUDFNv1 extended GenericUDF{
private GenericUDFUtils.ReturnObjectInspectorResolver returnOIRsolver;
private ObjectInspector[] argumentOIs;
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException{
arhumentOIs =arguments;
if(arguments.length !=2){
throw new UDFArgumenLengthException("The operator 'NVL' accepts 2 arguments.");
}
returnOIRsolver=new GenericUDFUtils.ReturnObjectInspectorResolver(true);
if(!(returnOIRsolver.update(arguments[0])&&returnOIRsolver.update(arguments[1]))){
throw new UDFArgumenTypeException(2,"The 1st and 2nd args of function NVL"
+"should have the same type,but they are differet:\""+arguments[0].getTypeName()
+"\"and \""+arguments[1].getTypeName()+"\"");
}
return returnOIRsolver.get();
}
.....
}
方法evaluate的输入是一个DeferredObject对象数组,而initialize方法中创建的returnOIResolver对象就是用于从DeferredObjects对象中获取到值。在这种情况下,这个函数将会返回第一个非null值:
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException{
Object retVal=returnOIRsolver.convertIfNecessary(arguments[0].get(),argumentOIs[0]);
if(retVal == null){
retVal = returnOIRsolver.convertIfNecessary(arguments[1].get(),argumentOIs[1]);
}
return retVal;
}
......
最后一个实现的方法就是getDisplayString(),其中于Hadoop task内部,在使用到这个函数来展示调试信息:
@Override
public String getDisplayString(string[] childred){
StringBuilder sb = new StringBuilder();
sb.append("if");
sb.append(children[0]);
sb.append("is null");
sb.append("returns");
sb.append(children[1]);
return sb.toString();
}
}
为了展示这个UDF的通用处理特性,下面的查询中对其调用了多次,每次都传入不同类型的参数,正如下面例子所展示的:
hive>ADD JAR /path/to/jar.jar
hive>create temporary function nvl
>as ‘org.apache.hadoop.hive.q1.udf.generic.GenericUDFNvl’;
hive>select nvl (1,2) as col1,nvl(null,5) as col2,nvl(null,”stuff”) as col3 from src limit 1;
1 5 stuff
【Nginx】日志格式
















 5645
5645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











