





原始代码:https://pettingzoo.farama.org/tutorials/tianshou/advanced/
我在原始代码中加了一点注释,其他的都没变。
这篇代码主要是示例天授的参数解析和日志记录如何使用。
''''''
"""This is a full example of using Tianshou with MARL to train agents, complete with argument parsing (CLI) and logging.
这是将天授与MARL一起用于训练智能体的完整示例,包括参数解析(CLI)和日志记录。
Author: Will (https://github.com/WillDudley)
Python version used: 3.8.10
Requirements:
pettingzoo == 1.22.0
git+https://github.com/thu-ml/tianshou
"""
import argparse
import os
from copy import deepcopy
from typing import Optional, Tuple
import gym
import numpy as np
import torch
from tianshou.data import Collector, VectorReplayBuffer
from tianshou.env import DummyVectorEnv
from tianshou.env.pettingzoo_env import PettingZooEnv
from tianshou.policy import BasePolicy, DQNPolicy, MultiAgentPolicyManager, RandomPolicy
from tianshou.trainer import offpolicy_trainer
from tianshou.utils import TensorboardLogger
from tianshou.utils.net.common import Net
from torch.utils.tensorboard import SummaryWriter
from pettingzoo.classic import tictactoe_v3
def get_parser() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser()
parser.add_argument("--seed", type=int, default=1626)
parser.add_argument("--eps-test", type=float, default=0.05)
parser.add_argument("--eps-train", type=float, default=0.1)
parser.add_argument("--buffer-size", type=int, default=20000)
parser.add_argument("--lr", type=float, default=1e-4)
parser.add_argument(
"--gamma", type=float, default=0.9, help="a smaller gamma favors earlier win"
)
parser.add_argument("--n-step", type=int, default=3)
parser.add_argument("--target-update-freq", type=int, default=320)
parser.add_argument("--epoch", type=int, default=50)
parser.add_argument("--step-per-epoch", type=int, default=1000)
parser.add_argument("--step-per-collect", type=int, default=10)
parser.add_argument("--update-per-step", type=float, default=0.1)
parser.add_argument("--batch-size", type=int, default=64)
parser.add_argument(
"--hidden-sizes", type=int, nargs="*", default=[128, 128, 128, 128]
)
parser.add_argument("--training-num", type=int, default=10)
parser.add_argument("--test-num", type=int, default=10)
parser.add_argument("--logdir", type=str, default="log")
parser.add_argument("--render", type=float, default=0.1) # 渲染时,每帧渲染的秒数(相当于FPS的倒数)
parser.add_argument(
"--win-rate",
type=float,
default=0.6,
help="the expected winning rate: Optimal policy can get 0.7",
)
parser.add_argument(
"--watch",
default=False,
action="store_true",
help="no training, " "watch the play of pre-trained models",
)
parser.add_argument(
"--agent-id",
type=int,
default=2,
help="the learned agent plays as the"
" agent_id-th player. Choices are 1 and 2.", # 已训练的智能体作为第几个玩家,可以选择1或2。
)
parser.add_argument(
"--resume-path",
type=str,
default="",
help="the path of agent pth file " "for resuming from a pre-trained agent", # “agent pth”文件的路径,用于从预训练智能体中恢复。
)
parser.add_argument(
"--opponent-path",
type=str,
default="",
help="the path of opponent agent pth file " # 对手智能体pth文件的路径
"for resuming from a pre-trained agent", # 用于从预训练智能体中恢复。
)
parser.add_argument(
"--device", type=str, default="cuda" if torch.cuda.is_available() else "cpu"
)
return parser
def get_args() -> argparse.Namespace:
parser = get_parser()
return parser.parse_known_args()[0]
def get_agents(
args: argparse.Namespace = get_args(),
agent_learn: Optional[BasePolicy] = None,
agent_opponent: Optional[BasePolicy] = None,
optim: Optional[torch.optim.Optimizer] = None,
) -> Tuple[BasePolicy, torch.optim.Optimizer, list]:
env = get_env()
observation_space = (
env.observation_space["observation"]
if isinstance(env.observation_space, gym.spaces.Dict)
else env.observation_space
)
args.state_shape = (
observation_space["observation"].shape or observation_space["observation"].n
)
args.action_shape = env.action_space.shape or env.action_space.n
if agent_learn is None: # 学习器默认使用DQN算法
# model
net = Net(
args.state_shape,
args.action_shape,
hidden_sizes=args.hidden_sizes,
device=args.device,
).to(args.device)
if optim is None:
optim = torch.optim.Adam(net.parameters(), lr=args.lr)
agent_learn = DQNPolicy(
net,
optim,
args.gamma,
args.n_step,
target_update_freq=args.target_update_freq,
)
if args.resume_path:
agent_learn.load_state_dict(torch.load(args.resume_path))
if agent_opponent is None: # 对手智能体默认为随机策略。
if args.opponent_path:
agent_opponent = deepcopy(agent_learn)
agent_opponent.load_state_dict(torch.load(args.opponent_path))
else:
agent_opponent = RandomPolicy()
if args.agent_id == 1:
agents = [agent_learn, agent_opponent]
else:
agents = [agent_opponent, agent_learn]
policy = MultiAgentPolicyManager(agents, env)
return policy, optim, env.agents
def get_env(render_mode=None):
return PettingZooEnv(tictactoe_v3.env(render_mode=render_mode))
def train_agent(
args: argparse.Namespace = get_args(),
agent_learn: Optional[BasePolicy] = None,
agent_opponent: Optional[BasePolicy] = None,
optim: Optional[torch.optim.Optimizer] = None,
) -> Tuple[dict, BasePolicy]:
# ======== environment setup =========
# ======== 环境测试 =========
train_envs = DummyVectorEnv([get_env for _ in range(args.training_num)])
test_envs = DummyVectorEnv([get_env for _ in range(args.test_num)])
# seed
np.random.seed(args.seed)
torch.manual_seed(args.seed)
train_envs.seed(args.seed)
test_envs.seed(args.seed)
# ======== agent setup =========
# ======== 智能体设置 =========
policy, optim, agents = get_agents(
args, agent_learn=agent_learn, agent_opponent=agent_opponent, optim=optim
)
# ======== collector setup =========
# ======== 采集器设置 =========
train_collector = Collector(
policy,
train_envs,
VectorReplayBuffer(args.buffer_size, len(train_envs)),
exploration_noise=True,
)
test_collector = Collector(policy, test_envs, exploration_noise=True)
# policy.set_eps(1)
train_collector.collect(n_step=args.batch_size * args.training_num)
# ======== tensorboard logging setup =========
# ======== tensorboard日志记录设置 =========
log_path = os.path.join(args.logdir, "tic_tac_toe", "dqn")
writer = SummaryWriter(log_path)
writer.add_text("args", str(args))
logger = TensorboardLogger(writer)
# ======== callback functions used during training =========
# ======== 在训练期间使用的回调函数
def save_best_fn(policy):
if hasattr(args, "model_save_path"):
model_save_path = args.model_save_path
else:
model_save_path = os.path.join(
args.logdir, "tic_tac_toe", "dqn", "policy.pth"
)
torch.save(
policy.policies[agents[args.agent_id - 1]].state_dict(), model_save_path
)
def stop_fn(mean_rewards):
return mean_rewards >= args.win_rate
def train_fn(epoch, env_step):
policy.policies[agents[args.agent_id - 1]].set_eps(args.eps_train)
def test_fn(epoch, env_step):
policy.policies[agents[args.agent_id - 1]].set_eps(args.eps_test)
def reward_metric(rews):
return rews[:, args.agent_id - 1]
# trainer
result = offpolicy_trainer(
policy,
train_collector,
test_collector,
args.epoch,
args.step_per_epoch,
args.step_per_collect,
args.test_num,
args.batch_size,
train_fn=train_fn,
test_fn=test_fn,
stop_fn=stop_fn,
save_best_fn=save_best_fn,
update_per_step=args.update_per_step,
logger=logger,
test_in_train=False,
reward_metric=reward_metric,
)
return result, policy.policies[agents[args.agent_id - 1]]
# ======== a test function that tests a pre-trained agent ======
def watch(
args: argparse.Namespace = get_args(),
agent_learn: Optional[BasePolicy] = None,
agent_opponent: Optional[BasePolicy] = None,
) -> None:
env = DummyVectorEnv([lambda: get_env(render_mode="human")])
policy, optim, agents = get_agents(
args, agent_learn=agent_learn, agent_opponent=agent_opponent
)
policy.eval()
policy.policies[agents[args.agent_id - 1]].set_eps(args.eps_test)
collector = Collector(policy, env, exploration_noise=True)
result = collector.collect(n_episode=1, render=args.render)
rews, lens = result["rews"], result["lens"]
print(f"Final reward: {rews[:, args.agent_id - 1].mean()}, length: {lens.mean()}")
if __name__ == "__main__":
# train the agent and watch its performance in a match!
# 训练智能体并观看其在比赛中的表现!
args = get_args()
result, agent = train_agent(args)
watch(args, agent)
这里已训练的智能体作为第2个玩家(后手,下的棋用O表示)。
输出如下(截图不完全):
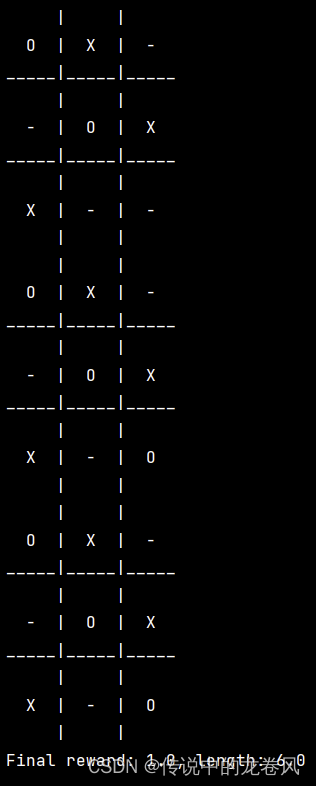
而且运行结束后,会在当前目录中创建文件夹(log/tic_tac_toe/dqn)并生成两个文件:















 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









