





本文原始代码链接
PettingZoo的github链接
注意:本文代码是【并行】环境。
原始代码遗漏了对环境的state赋值,我在本文代码加上了。
自定义【并行】环境:
Example_Parallel_Environment.py
''''''
'''
并行环境。PettingZoo石头剪刀布。
'''
import functools
import gymnasium
from gymnasium.spaces import Discrete
from pettingzoo import ParallelEnv
from pettingzoo.utils import parallel_to_aec, wrappers
ROCK = 0
PAPER = 1
SCISSORS = 2
NONE = 3
MOVES = ["ROCK", "PAPER", "SCISSORS", "None"]
NUM_ITERS = 10 # 最大时间步。原为100
REWARD_MAP = {
(ROCK, ROCK): (0, 0),
(ROCK, PAPER): (-1, 1),
(ROCK, SCISSORS): (1, -1),
(PAPER, ROCK): (1, -1),
(PAPER, PAPER): (0, 0),
(PAPER, SCISSORS): (-1, 1),
(SCISSORS, ROCK): (-1, 1),
(SCISSORS, PAPER): (1, -1),
(SCISSORS, SCISSORS): (0, 0),
}
def env(render_mode=None):
''''''
"""
The env function often wraps the environment in wrappers by default.
You can find full documentation for these methods
elsewhere in the developer documentation.
默认情况下,env函数通常将环境包装在包装器中。
您可以找到这些方法的完整文档
在开发人员文档的其他地方。
"""
internal_render_mode = render_mode if render_mode != "ansi" else "human"
env = raw_env(render_mode=internal_render_mode)
# This wrapper is only for environments which print results to the terminal
# 此包装器仅适用于将结果打印到终端的环境
if render_mode == "ansi":
env = wrappers.CaptureStdoutWrapper(env)
# this wrapper helps error handling for discrete action spaces
# 该包装器有助于离散操作空间的错误处理
env = wrappers.AssertOutOfBoundsWrapper(env)
# Provides a wide vareity of helpful user errors
# 提供各种有用的用户错误
# Strongly recommended
# 强烈推荐
env = wrappers.OrderEnforcingWrapper(env)
return env
def raw_env(render_mode=None):
''''''
"""
To support the AEC API, the raw_env() function just uses the from_parallel
function to convert from a ParallelEnv to an AEC env
为了支持AEC API,raw_env()函数只使用from_parallel
用于从ParallelEnv转换为AEC环境的函数
"""
env = parallel_env(render_mode=render_mode)
env = parallel_to_aec(env)
return env
class parallel_env(ParallelEnv):
metadata = {"render_modes": ["human"], "name": "rps_v2"}
def __init__(self, render_mode=None):
''''''
"""
The init method takes in environment arguments and should define the following attributes:
- possible_agents
- action_spaces
- observation_spaces
These attributes should not be changed after initialization.
init方法接受环境参数,并且应该定义以下属性:
-可能的智能体
-操作空间(_S)
-观测_空间
初始化后不应更改这些属性。
"""
self.possible_agents = ["player_" + str(r) for r in range(2)]
self.agent_name_mapping = dict(
zip(self.possible_agents, list(range(len(self.possible_agents))))
)
self.render_mode = render_mode
# this cache ensures that same space object is returned for the same agent
# 该缓存确保为同一代理返回相同的空间对象
# allows action space seeding to work as expected
# 允许操作空间种子按预期工作
@functools.lru_cache(maxsize=None)
def observation_space(self, agent):
# gymnasium spaces are defined and documented here: https://gymnasium.farama.org/api/spaces/
return Discrete(4)
@functools.lru_cache(maxsize=None)
def action_space(self, agent):
return Discrete(3)
def render(self):
''''''
"""
Renders the environment. In human mode, it can print to terminal, open
up a graphical window, or open up some other display that a human can see and understand.
渲染环境。在人工模式下,它可以打印到终端,打开
打开一个图形窗口,或者打开一些人类可以看到和理解的其他显示。
"""
if self.render_mode is None:
gymnasium.logger.warn(
"You are calling render method without specifying any render mode."
)
return
if len(self.agents) == 2: # 这篇代码漏了定义self.state,以及给它赋值
string = "Current state: Agent1: {} , Agent2: {}".format(
MOVES[self.state[self.agents[0]]], MOVES[self.state[self.agents[1]]]
)
else:
string = "Game over" # 这里只是打印了“游戏结束”,并没有关闭游戏呀。如何退出智能体迭代器?
# 退出智能体迭代器的方法应该是:将智能体列表中的智能体全部删除。
# 而能够把某智能体删除,当且仅当它截断或终止。
# 所以当你希望游戏结束时,请把所有智能体的终止状态设为True。
print(string)
def close(self):
"""
Close should release any graphical displays, subprocesses, network connections
or any other environment data which should not be kept around after the
user is no longer using the environment.
"""
pass
def reset(self, seed=None, return_info=False, options=None):
''''''
"""
Reset needs to initialize the `agents` attribute and must set up the
environment so that render(), and step() can be called without issues.
Here it initializes the `num_moves` variable which counts the number of
hands that are played.
Returns the observations for each agent
Reset需要初始化“agents”属性,并且必须设置环境,
以便可以毫无问题地调用render()和step()。
在这里,它初始化“num_moves”变量,该变量计算玩的手的数量(指的是时间步计数)。
返回每个代理的观察结果
"""
self.agents = self.possible_agents[:]
self.num_moves = 0
observations = {agent: NONE for agent in self.agents}
# 这篇代码漏了state。现在给它加上:
self.state = {agent: NONE for agent in self.agents}
if not return_info:
return observations
else:
infos = {agent: {} for agent in self.agents}
return observations, infos
def step(self, actions):
''''''
"""
step(action) takes in an action for each agent and should return the
- observations
- rewards
- terminations
- truncations
- infos
dicts where each dict looks like {agent_1: item_1, agent_2: item_2}
步骤(操作)为每个代理执行一个操作,并应返回
-观察
-奖励
-终止
-截断
-信息
dicts,其中每个dict看起来像{agent_1:item_1,agent_2:item_2}
"""
# If a user passes in actions with no agents, then just return empty observations, etc.
# 如果用户在没有智能体的情况下传入操作,那么只返回空的观察结果,等等。
if not actions:
self.agents = []
return {}, {}, {}, {}, {}
# 这篇代码漏了state,要加上:
self.state=actions
# rewards for all agents are placed in the rewards dictionary to be returned
# 所有代理的奖励都会放在要返回的奖励字典中
rewards = {}
rewards[self.agents[0]], rewards[self.agents[1]] = REWARD_MAP[
(actions[self.agents[0]], actions[self.agents[1]])
]
terminations = {agent: False for agent in self.agents}
self.num_moves += 1
env_truncation = self.num_moves >= NUM_ITERS
truncations = {agent: env_truncation for agent in self.agents}
# current observation is just the other player's most recent action
# 目前的观察只是其他玩家最近的动作
observations = {
self.agents[i]: int(actions[self.agents[1 - i]])
for i in range(len(self.agents))
}
# typically there won't be any information in the infos, but there must
# still be an entry for each agent
# 通常情况下,信息(infos)中不会有任何信息,但每个代理都必须有一个条目
infos = {agent: {} for agent in self.agents}
if env_truncation:
self.agents = []
if self.render_mode == "human":
self.render()
return observations, rewards, terminations, truncations, infos
使用自定义环境:(此代码要和Example_Parallel_Environment.py位于同一个文件夹中)
t_epe.py
# 测试并行环境 Example_Parallel_Environment
import Example_Parallel_Environment as epe
parallel_env = epe.parallel_env(render_mode='human')
observations = parallel_env.reset()
while parallel_env.agents:
actions = {agent: parallel_env.action_space(agent).sample() for agent in parallel_env.agents} # this is where you would insert your policy
observations, rewards, terminations, truncations, infos = parallel_env.step(actions)
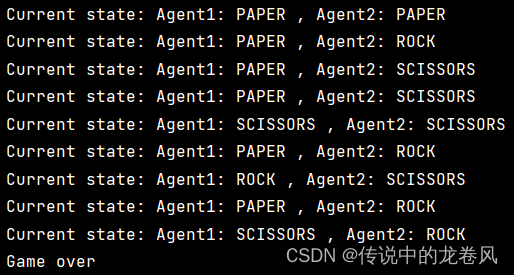
运行结果如下:

















 4130
4130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









