







版本对应

Spark版本3以上不再支持scala2.11
环境:
jdk:1.8.0_181

maven:3.6.3

scala2.12.0

配置环境变量
#jdk
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
#maven
export MAVEN_HOME=/usr/local/apache-maven-3.6.3
export MAVEN_HOME
export PATH=$PATH:$MAVEN_HOME/bin
#scala
export SCALA_HOME=/usr/local/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin下载spark源码包
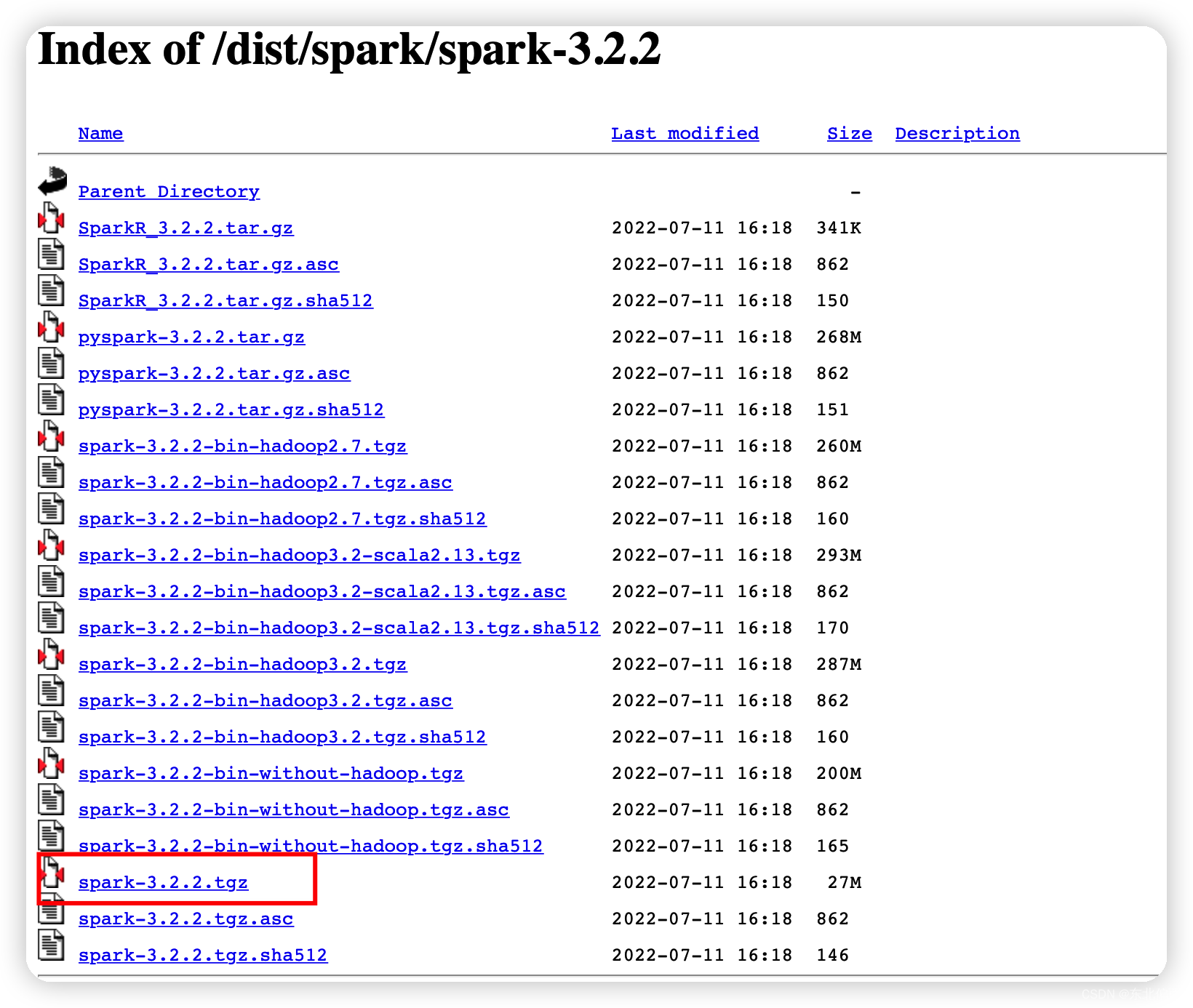
修改pom.xml文件
增加cloudera的mvn镜像
第303行
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<name>Cloudera Repositories</name>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
第342行
<pluginRepository>
<id>cloudera</id>
<name>Cloudera Repositories</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</pluginRepository>
修改hadoop版本
第123行
<hadoop.version>3.0.0-cdh6.3.2</hadoop.version>修改编辑脚本中的mvn仓库指向
vi /opt/spark-3.2.2/dev/make-distribution.sh
MVN='/usr/local/apache-maven-3.6.3/bin/mvn'在脚本中,根据自己的资源确定内存大小,防止内存溢出
export MAVEN_OPTS="${MAVEN_OPTS:--Xmx1g -XX:ReservedCodeCacheSize=512m编译命令
./dev/make-distribution.sh \
--name 3.0.0-cdh6.3.2 --tgz -Pyarn -Phadoop-3.0 \
-Phive -Phive-thriftserver -Dhadoop.version=3.0.0-cdh6.3.2 -X编译完成
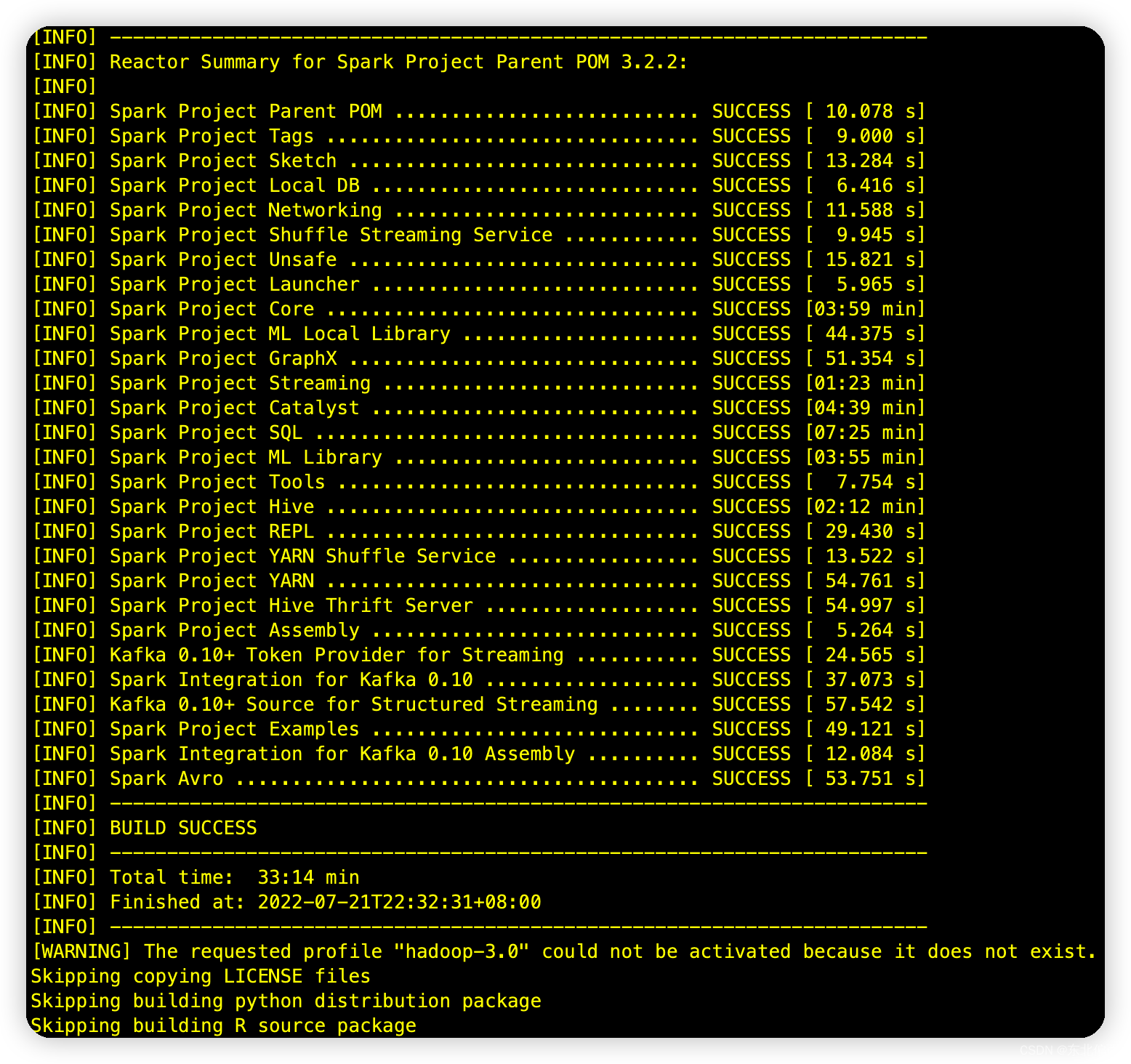
报错
jar包没有,下载失败。。。
修改pom
1、
<parent>
<groupId>org.apache</groupId>
<artifactId>apache</artifactId>
<version>18</version>
<relativePath></relativePath>
</parent>
org.apache增加
<relativePath></relativePath>
2、
<scalaVersion>${scala.version}</scalaVersion>
<checkMultipleScalaVersions>true</checkMultipleScalaVersions>
<failOnMultipleScalaVersions>true</failOnMultipleScalaVersions>
<recompileMode>incremental</recompileMode>
<useZincServer>false</useZincServer>
scala.version增加
<useZincServer>false</useZincServer>
3、
修改net.alchim31.maven版本(全部)为3.2.2
<dependency>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>使用mvn打包命令先测试(把一些jar包下载下来)
build/mvn -Pyarn -Phadoop-3.0.0 -Dhadoop.version=3.0.0-cdh6.3.2 -DskipTests clean package















 4868
4868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











