







周志华机器学习–模型评估与选择
第一章 绪论
第二章 模型评估与选择
第三章 线性模型
第四章 决策树
第五章 支持向量机
第六章 神经网络
第七章 贝叶斯分类器
第八章 集成学习和聚类
一、泛化能力
泛化能力强:能很好适用于unseen instance
e.g., 错误率低、精度高、召回能力强(以上指标视具体任务和使用者需求而异)
二、过拟合和欠拟合
-
泛化误差:在“未来”样本上的误差
-
经验误差:在训练集上的误差,亦称为“训练误差”
Q:是否泛化or经验误差越小越好?
A:不是! -
过拟合(overfitting):经验误差过小,模型学习到了训练数据满足的特有性质,但这些性质不是一般规律
-
欠拟合(underfitting):经验误差过大,模型没有学习到足够的一般规律
SO 机器学习重要的问题:用什么方法缓解overfitting?什么情况下此方法会失效?
三、三大问题
模型选择三大关键问题:
- 如何获得测试结果?–评估方法
- 如何评估性能优劣?–性能度量
- 如何判断实质差别?–比较检验
四、评估方法
** 留出法(hold-out)**

- 存在问题:尽管随机取多次,可能仍会遗漏某些数据
k-折交叉验证法可避免这个问题
交叉验证法(cross validation)

-
但因为切分可能存在偏差,可以做10次不同的切分,就成了10*10 CV, 也是做100次试验
-
留一法 (leave-one-out):M99逼近M100是否比M90逼近M100更准确呢? NO! 因为no free lunch
自助法(bootstrp)
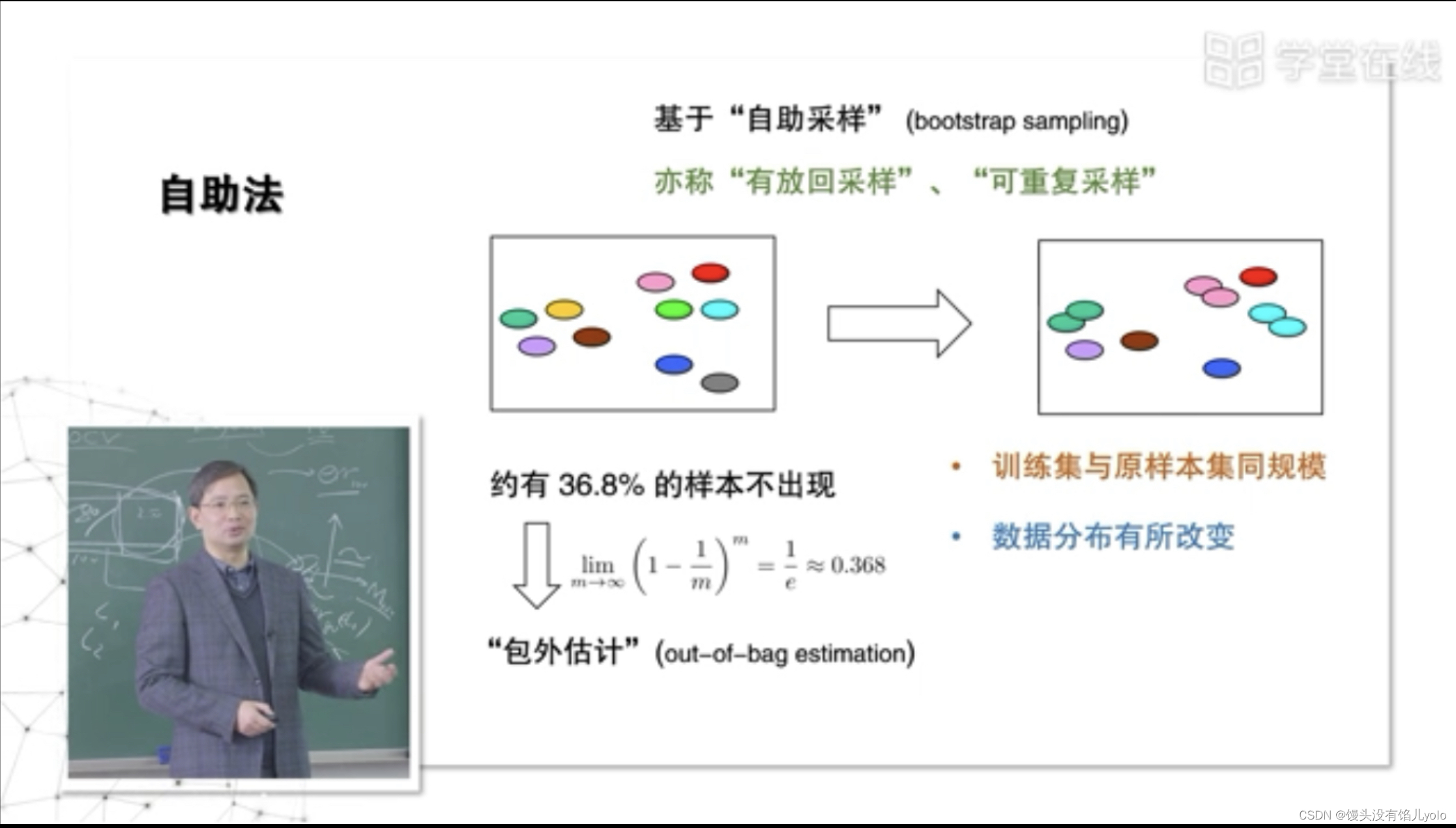
- 不出现的样本当作测试集
- 优点:既能逼近M100,还能留出样本做测试
- 最大的缺陷:数据分别有所改变(适用于数据分布不重要,或数据量不够的情况
五、调参与验证集

- 验证集–从训练集分出一部分用以调整参数
- 调参数的过程也是训练的过程,不能用测试集进行调参,因为测试集里的数据一定要是训练时没有出现的数据
六、性能度量
性能度量反映了任务需求



查准率:当西瓜收购公司去瓜摊收购西瓜时希望保证收到的瓜中坏瓜尽可能的少
查全率:当西瓜收购公司去瓜摊收购西瓜时希望把好瓜都收走

F1度量结合了P和R:当西瓜收购公司去瓜摊收购西瓜时既希望把好瓜都收走又保证收到的瓜中坏瓜尽可能的少
F1度量使较小的值不被忽视
七、比较检验
在某种度量下取得的评估结果不能直接比较以评判优劣,因为:
- 测试性能不等于泛化应能
- 测试性能随着测试集的变化而变化
- 很多机器学习算法本身具有一定的随机性
机器学习–“概率近似正确”

- 比较两模型在每次测试error的差值,配对t检验(适用于模型采用k折交叉验证的评估方法,需要用到模型评估时k折交叉验证的k个结果)
- 基于列联表,卡方检验















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









