







一、绪论
基本术语
数据集(data set)、示例instance、样本sample、属性attribute、特征feature、属性值attribute value、属性空间attribute space、样本空间sample space、特征向量feature vector。
从数据中学得模型的过程称为“学习”(learning)或“训练”(training),这个过程通过执行某个学习算法来完成.训练过程中使用的数据称为“训练数据”(training data),其中每个样本称为一个“训练样本”(training sample),训练样本组成的集合称为“训练集”(training set).学得模型对应了关于数据的某种潜在的规律,因此亦称“假设”(hypothesis);这种潜在规律自身,则称为“真相”或“真实”(ground-truth),学习过程就是为了找出或逼近真相.有时将模型称为“学习器”(learner),可看作学习算法在给定数据和参数空间上的实例化。拥有了标记信息的示例,则称为“样例”(example)。
若我们欲预测的是离散值,此类学习任务称为“分类”(classification);若欲预测的是连续值,此类学习任务称为“回归”(regression).对只涉及两个类别的“二分类”(binary classification)任务,通常称其中一个类为“正类”(positive class),另一个类为“反类”(negative class);涉及多个类别时,则称为“多分类”(multi-class classification)任务。
学得模型后,使用其进行预测的过程称为“测试”(testing),被预测的样本称为“测试样本”(testing sample)。我们还可以对西瓜做“聚类”(clustering),即将训练集中的西瓜分成若干组,每组称为一个“簇”(cluster);这些自动形成的簇可能对应一些潜在的概念划分,例如“浅色瓜”“深色瓜”,甚至“本地瓜”“外地瓜”.这样的学习过程有助于我们了解数据内在的规律,能为更深入地分析数据建立基础.需说明的是,在聚类学习中,“浅色瓜”“本地瓜”这样的概念我们事先是不知道的,而且学习过程中使用的训练样本通常不拥有标记信息.
根据训练数据是否拥有标记信息,学习任务可大致划分为两大类:“监督学习”(supervised learning)和“无监督学习”(unsupervised learning),分类和回归是前者的代表,而聚类则是后者的代表.
学得模型适用于新样本的能力,称为“泛化”(generalization)能力
二、模型评估与选择
三、线性模型
在属性空间中拟合出一条满足所有样本的曲线。
四、决策树
决策树(decision tree)是一类常见的机器学习方法.以二分类任务为例,我们希望从给定训练数据集学得一个模型用以对新示例进行分类,这个把样本分类的任务,可看作对“当前样本属于正类吗?”这个问题的“决策”或“判定”过程.顾名思义,决策树是基于树结构来进行决策的,这恰是人类在面临决策问题时一种很自然的处理机制,剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段.
五、神经网络
1、神经元模型
1943年提出的M-P神经元模型:(此结构只能解决线性可分的问题,无法解决异或等非线性可分问题)
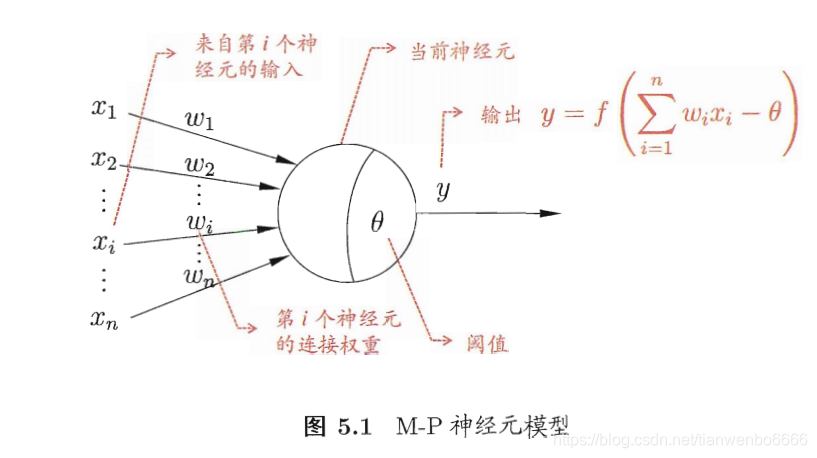
理想的激活函数是阶跃函数,但其数学性质不好,实际上多用sigmoid函数。

把许多个这样的神经元按一定的层次结构连接起来,就得到了神经网络.
2、感知机与多层网络
要解决非线性可分问题,需考虑使用多层功能神经元。例如图5.5中这个简单的两层感知机就能解决异或问题.在图5.5(a)中,输出层与输入层之间的一层神经元,被称为隐层或隐含层(hidden layer),隐含层和输出层神经元都是拥有激活函数的功能神经元。

更一般的,常见的神经网络是形如图5.6所示的层级结构,每层神经元与下一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接.这样的神经网络结构通常称为“多层前馈神经网络”(multi-layer feedforward neural networks),其中输入层神经元接收外界输入,隐层与输出层神经元对信号进行加工,最终结果由输出层神经元输出;换言之,输入层神经元仅是接受输入,不进行函数处理,隐层与输出层包含功能神经元。因此,图5.6(a)通常被称为“两层网络”.为避免歧义,本书称其为“单隐层网络”.只需包含隐层,即可称为多层网络.神经网络的学习过程,就是根据训练数据来调整神经元之间的“连接权”(connection weight)以及每个功能神经元的阀值;换言之,神经网络“学”到的东西,蕴涵在连接权与阀值中.

3、误差逆传播算法
多层网络的学习能力比单层感知机强得多.欲训练多层网络,式(5.1)的简单感知机学习规则显然不够了,需要更强大的学习算法.误差逆传播(error BackPropagation,简称BP)算法就是其中最杰出的代表,它是迄今最成功的神经网络学习算法.现实任务中使用神经网络时,大多是在使用BP算法进行训练.值得指出的是,BP算法不仅可用于多层前馈神经网络,还可用于其他类型的神经网络,例如训练递归神经网络[Pineda,1987].但通常说“BP网络”时,一般是指用BP算法训练的多层前馈神经网络.

图5.8给出了BP算法的工作流程.对每个训练样例,BP算法执行以下操作:先将输入示例提供给输入层神经元,然后逐层将信号前传,直到产生输出层的结果;然后计算输出层的误差(第4-5行),再将误差逆向传播至隐层神经元(第6行),最后根据隐层神经元的误差来对连接权和阈值进行调整(第7行).该迭代过程循环进行,直到达到某些停止条件为止,例如训练误差已达到一个很小的值.

4、深度学习
典型的深度学习模型就是很深层的神经网络(深度学习模型通常有八九层甚至更多隐层).显然,对神经网络模型,提高容量的办法是增加隐层的数目和通过单纯增加隐层神经元的数目,增加隐层的数目显然比增加隐层神经元的数目更有效,然而,多隐层神经网络难以直接用经典算法(例如标准BP算法)进行训练,因为误差在多隐层内逆传播时,往往会“发散”(diverge)而不能收敛到稳定状态.
无监督逐层训练(unsupervised layer-wise training)是多隐层网络训练的有效手段,其基本思想是每次训练一层隐结点,训练时将上一层隐结点的输出作为输入,而本层隐结点的输出作为下一层隐结点的输入,这称为“预训练”(pre-training);在预训练全部完成后,再对整个网络进行“微调”(fine-tuning)训练.
事实上,“预训练+微调”的做法可视为将大量参数分组,对每组先找到局部看来比较好的设置,然后再基于这些局部较优的结果联合起来进行全局寻优.这样就在利用了模型大量参数所提供的自由度的同时,有效地节省了训练开销.
另一种节省训练开销的策略是“权共享”(weight sharing),即让一组神经元使用相同的连接权.这个策略在卷积神经网络(Convolutional Neural Network,简称 CNN)[LeCun and Bengio,1995;LeCun et al.,1998]中发挥了重要作用.
六、支持向量机


如图6.2所示,距离超平面最近的这几个训练样本点使式(6.3)的等号成立,它们被称为“支持向量”(support vector),两个异类支持向量到超平面的距离之和为

它被称为“间隔”(margin).
七、贝叶斯分类
八、集成学习
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等.
图8.1显示出集成学习的一般结构:先产生一组“个体学习器”(individual learner),再用某种策略将它们结合起来.个体学习器通常由一个现有的学习算法从训练数据产生,例如C4.5决策树算法、BP神经网络算法等,此时集成中只包含同种类型的个体学习器,例如“决策树集成”中全是决策树,“神经网络集成”中全是神经网络,这样的集成是“同质”的(homogeneous).同质集成中的个体学习器亦称“基学习器”(base learner),相应的学习算法称为“基学习算法”(base learning algorithm).集成也可包含不同类型的个体学习器,例如同时包含决策树和神经网络,这样的集成是“异质”的(heterogenous).异质集成中的个体学习器由不同的学习算法生成,这时就不再有基学习算法;相应的,个体学习器一般不称为基学习器,常称为“组件学习器”(component learner)或直接称为个体学习器.

根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器间存在强依赖关系、必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者的代表是Boosting,后者的代表是Bagging和“随机森林”(Random Forest).
Boosting是一族可将弱学习器提升为强学习器的算法.这族算法的工作机制类似:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值T,最终将这个基学习器进行加权结合.
Bagging[Breiman,1996a]是并行式集成学习方法最著名的代表.从名字即可看出,它直接基于我们在2.2.3节介绍过的自助采样法(bootstrap sampling).给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过m次随机采样操作,我们得到含m个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现.
随机森林(Random Forest,简称RF)[Breiman,2001a]是Bagging的一个扩展变体.RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择.具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有d个属性)中选择一个最优属性;而在RF中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分.这里的参数k控制了随机性的引入程度:若令k=d,则基决策树的构建与传统决策树相同;若令k=1,则是随机选择一个属性用于划分;一般情况下,推荐值k=log2d.
九、聚类
在“无监督学习”(unsupervised learning)中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础.此类学习任务中研究最多、应用最广的是“聚类”(clustering).
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”(cluster).通过这样的划分,每个簇可能对应于一些潜在的概念(类别);需说明的是,这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,簇所对应的概念语义需由使用者来把握和命名.
十、降维与度量学习
十一、特征选择与稀疏学习
我们将属性称为“特征”(feature),对当前学习任务有用的属性称为“相关特征”(relevant feature)、没什么用的属性称为“无关特征”(irrelevant feature).从给定的特征集合中选择出相关特征子集的过程,称为“特征选择”(feature selection).
特征选择是一个重要的“数据预处理”(data preprocessing)过程,在现实机器学习任务中,获得数据之后通常先进行特征选择,此后再训练学习器.那么,为什么要进行特征选择呢?
有两个很重要的原因:首先,我们在现实任务中经常会遇到维数灾难问题,这是由于属性过多而造成的,若能从中选择出重要的特征,使得后续学习过程仅需在一部分特征上构建模型,则维数灾难问题会大为减轻.从这个意义上说,特征选择与第10章介绍的降维有相似的动机;事实上,它们是处理高维数据的两大主流技术.第二个原因是,去除不相关特征往往会降低学习任务的难度,这就像侦探破案一样,若将纷繁复杂的因素抽丝剥茧,只留下关键因素,则真相往往更易看清
十二、计算学习理论
顾名思义,计算学习理论(computational learning theory)研究的是关于通过“计算”来进行“学习”的理论,即关于机器学习的理论基础,其目的是分析学习任务的困难本质,为学习算法提供理论保证,并根据分析结果指导算法设计.
十三、半监督学习
事实上,未标记样本虽未直接包含标记信息,但若它们与有标记样本是从同样的数据源独立同分布采样而来,则它们所包含的关于数据分布的信息对建立模型将大有裨益.图13.1给出了一个直观的例示.若仅基于图中的一个正例和一个反例,则由于待判别样本恰位于两者正中间,大体上只能随机猜测;若能观察到图中的未标记样本,则将很有把握地判别为正例.

让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能,就是半监督学习(semi-supervised learning).半监督学习的现实需求非常强烈,因为在现实应用中往往能容易地收集到大量未标记样本,而获取“标记”却需耗费人力、物力.例如,在进行计算机辅助医学影像分析时,可以从医院获得大量医学影像,但若希望医学专家把影像中的病灶全都标识出来则是不现实的.“有标记数据少,未标记数据多”半监督学习恰是提供了一条利用“廉价”的未标记样本的途径.
要利用未标记样本,必然要做一些将未标记样本所揭示的数据分布信息与类别标记相联系的假设.最常见的是“聚类假设”(cluster assumption),即假设数据存在簇结构,同一个簇的样本属于同一个类别.图13.1就是基于聚类假设来利用未标记样本,由于待预测样本与正例样本通过未标记样本的“撮合”聚在一起,与相对分离的反例样本相比,待判别样本更可能属于正类.半监督学习中另一种常见的假设是“流形假设”(manifold assumption),即假设数据分布在一个流形结构上,邻近的样本拥有相似的输出值.“邻近”程度常用“相似”程度来刻画,因此,流形假设可看作聚类假设的推广,但流形假设对输出值没有限制,因此比聚类假设的适用范围更广,可用于更多类型的学习任务.事实上,无论聚类假设还是流形假设,其本质都是“相似的样本拥有相似的输出”这个基本假设.
十四、概率图模型
机器学习最重要的任务,是根据一些已观察到的证据(例如训练样本)来对感兴趣的未知变量(例如类别标记)进行估计和推测.概率模型(probabilistic model)提供了一种描述框架,将学习任务归结于计算变量的概率分布.在概率模型中,利用已知变量推测未知变量的分布称为“推断”(inference),其核心是如何基于可观测变量推测出未知变量的条件分布.
概率图模型(probabilistic graphical model)是一类用图来表达变量相关关系的概率模型.它以图为表示工具,最常见的是用一个结点表示一个或一组随机变量,结点之间的边表示变量间的概率相关关系,即“变量关系图”.根据边的性质不同,概率图模型可大致分为两类:第一类是使用有向无环图表示变量间的依赖关系,称为有向图模型或贝叶斯网(Bayesian network);第二类是使用无向图表示变量间的相关关系,称为无向图模型或马尔可夫网(Markov network).
隐马尔可夫模型(Hidden Markov Model,简称HMM)是结构最简单的动态贝叶斯网(dynamic Bayesian network),这是一种著名的有向图模型,主要用于时序数据建模,在语音识别、自然语言处理等领域有广泛应用.

十五、规则学习
机器学习中的“规则”(rule)通常是指语义明确、能描述数据分布所隐含的客观规律或领域概念、可写成“若……,则……”形式的逻辑规则
[Firnkranz et al.,2012].“规则学习”(rule learning)是从训练数据中学习出一组能用于对未见示例进行判别的规则.
与神经网络、支持向量机这样的“黑箱模型”相比,规则学习具有更好的可解释性,能使用户更直观地对判别过程有所了解.另一方面,数理逻辑具有极强的表达能力,绝大多数人类知识都能通过数理逻辑进行简洁的刻画和表达.规则学习能更自然地在学习过程中引入领域知识.此外,逻辑规则的抽象描述能力在处理一些高度复杂的AI任务时具有显著的优势,例如在问答系统中有时可能遇到非常多、甚至无穷种可能的答案,此时若能基于逻辑规则进行抽象表述或者推理,则将带来极大的便利.
十六、强化学习
我们考虑一下如何种西瓜.种瓜有许多步骤,从一开始的选种,到定期浇水、施肥、除草、杀虫,经过一段时间才能收获西瓜.通常要等到收获后,我们才知道种出的瓜好不好.若将得到好瓜作为辛勤种瓜劳动的奖赏,则在种瓜过程中当我们执行某个操作(例如,施肥)时,并不能立即获得这个最终奖赏,甚至难以判断当前操作对最终奖赏的影响,仅能得到一个当前反馈(例如,瓜苗看起来更健壮了).我们需多次种瓜,在种瓜过程中不断摸索,然后才能总结出较好的种瓜策略.这个过程抽象出来,就是“强化学习”(reinforcement learning).
机器要做的是通过在环境中不断地尝试而学得一个“策略”(policy)π,根据这个策略,在状态x下就能得知要执行的动作a=π(x),例如看到瓜苗状态是缺水时,能返回动作“浇水”.
策略的优劣取决于长期执行这一策略后得到的累积奖赏,例如某个策略使得瓜苗枯死,它的累积奖赏会很小,另一个策略种出了好瓜,它的累积奖赏会很大.在强化学习任务中,学习的目的就是要找到能使长期累积奖赏最大化的策略长期累积奖赏有多种计算方式
读者也许已经感觉到强化学习与监督学习的差别.若将这里的“状态”对应为监督学习中的“示例”、“动作”对应为“标记”,则可看出,强化学习中的“策略”实际上就相当于监督学习中的“分类器”(当动作是离散的)或“回归器”(当动作是连续的),模型的形式并无差别.但不同的是,在强化学习中并没有监督学习中的有标记样本(即“示例-标记”对),换言之,没有人直接告诉机器在什么状态下应该做什么动作,只有等到最终结果揭晓,才能通过“反思”之前的动作是否正确来进行学习.因此,强化学习在某种意义上可看作具有“延迟标记信息”的监督学习问题















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









